Pycharm生成决策树
Pycharm生成决策树
- Pycharm生成文字化的决策树
- 实现生成决策树图
-
- 安装Graphviz并配置环境变量
- 解决中文乱码
-
- 部分解决
- 保存为pdf文件
- 保存为图片
红酒数据集下载地址:https://archive.ics.uci.edu/ml/datasets/Wine
Pycharm生成文字化的决策树
以下代码在jupyter中可以直接生成,但是在Pyharm中生成的结果是用文字形式表示的树模型。
import pandas as pd
from sklearn import tree
from sklearn.model_selection import train_test_split
import graphviz
#[178 rows x 14 columns] 1~13都是特征列 0列才是标签
wine = pd.read_table('F:\Temp\img\wine.data',sep = ',',header=None)
# 将列名修改为中文
names = ['类型','酒精','苹果酸','灰','灰的碱度','镁','总酚类化合物',
'类黄酮','Nonflavanoid酚类','原花青素','颜色强度' ,'色调',
'稀释葡萄酒的OD280/OD315','脯氨酸']
wine.columns = names
Xtrain, Xtest, Ytrain, Ytest = train_test_split(wine.iloc[:,1:],wine.iloc[:,0],test_size=0.3)
clf = tree.DecisionTreeClassifier(criterion="entropy")
clf = clf.fit(Xtrain,Ytrain)
score = clf.score(Xtest,Ytest)
# print(score)
# 绘制树
dot_data = tree.export_graphviz(clf,
feature_names=names[1:], # 特征名
class_names=["琴酒","雪莉","贝尔摩德"], # 为三个类别起个名(可随意)
filled=True,
rounded=True)
graph = graphviz.Source(dot_data)
print(graph) # 直接打印
graph.save('tree.dot') # 保存为文件
实现生成决策树图
import pandas as pd
import numpy as np
from sklearn import tree
from sklearn.model_selection import train_test_split
import pydotplus
from IPython.display import Image
#[178 rows x 14 columns] 1~13都是特征列 0列才是标签
wine = pd.read_table('F:\Temp\img\wine.data',sep = ',',header=None)
# 将列名修改为中文
names = ['类型','酒精','苹果酸','灰','灰的碱度','镁','总酚类化合物',
'类黄酮','Nonflavanoid酚类','原花青素','颜色强度' ,'色调',
'稀释葡萄酒的OD280/OD315','脯氨酸']
wine.columns = names
Xtrain, Xtest, Ytrain, Ytest = train_test_split(wine.iloc[:,1:],wine.iloc[:,0],test_size=0.3)
clf = tree.DecisionTreeClassifier(criterion="entropy")
clf = clf.fit(Xtrain,Ytrain)
score = clf.score(Xtest,Ytest)
# print(score)
# 绘制树
dot_data = tree.export_graphviz(clf,
feature_names=names[1:], # 特征名
class_names=["琴酒","雪莉","贝尔摩德"], # 为三个类别起个名(可随意)
filled=True,
rounded=True)
graph = pydotplus.graph_from_dot_data(dot_data)
img = Image(graph.create_png())
graph.write_png('F:\Temp\img\wine.png')
一般来说,没有安装Graphviz,或者没有配置环境变量的,都会报这么一个错:
GraphViz’s executables not found
安装Graphviz并配置环境变量
第一步,安装。除了路径,其他的全都默认
Graphviz下载地址:http://www.graphviz.org/download/
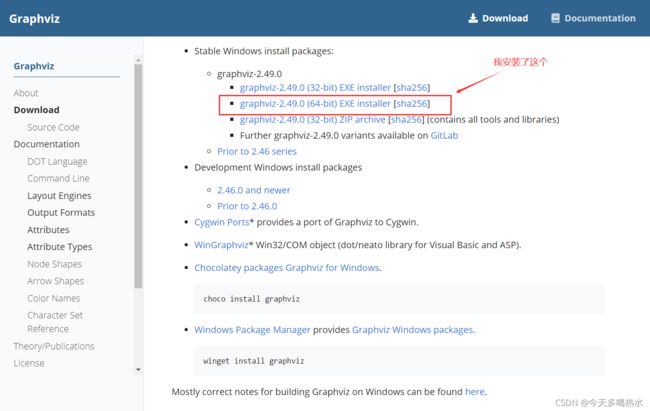
第二步,配置环境变量(将安装路径的路径添加到系统变量里的Path中)

我是手工在环境变量中添加了bin路径,但有的人喜欢运行这个语句。
import os
os.environ["PATH"] += os.pathsep + r'D:\Programming Software\Pycharm\GraphViz\bin'
第三步,检查。进入cmd界面,输入dot -version 或 dot -V 。如出现版本信息就说明成功了。
到了现在,就可以去执行刚才的代码了,然后就可以去对应路径中查看新生成的决策树了,只不过有中文乱码。
如果运行之后还是报 GraphViz’s executables not found 错,那就重启电脑。我也出现过这种情况,前三步都没问题,但就是报错。
解决中文乱码
部分解决
运行之后,控制台报警告,但这些警告都是黑体,我还是能接受的。
参考博客:https://blog.csdn.net/yeshang_lady/article/details/120220778
import pandas as pd
import numpy as np
from sklearn import tree
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
import graphviz
import pydotplus
from IPython.display import Image
#[178 rows x 14 columns] 1~13都是特征列 0列才是标签
wine = pd.read_table('../../DataSet/01 决策树/wine.data',sep = ',',header=None)
# 将列名修改为中文
names = ['类型','酒精','苹果酸','灰','灰的碱度','镁','总酚类化合物',
'类黄酮','Nonflavanoid酚类','原花青素','颜色强度' ,'色调',
'稀释葡萄酒的OD280/OD315','脯氨酸']
wine.columns = names
Xtrain, Xtest, Ytrain, Ytest = train_test_split(wine.iloc[:,1:],wine.iloc[:,0],test_size=0.3)
clf = tree.DecisionTreeClassifier(criterion="entropy")
clf = clf.fit(Xtrain,Ytrain)
score = clf.score(Xtest,Ytest)
# print(score)
# 绘制树
dot_data = tree.export_graphviz(clf,
feature_names=names[1:], # 特征名
class_names=["琴酒","雪莉","贝尔摩德"], # 为三个类别起个名(可随意)
filled=True,
rounded=True)
graph=pydotplus.graph_from_dot_data(dot_data)
#在原有的可视化代码后面添加如下代码,人为修改每个节点的fontname属性值
for node in graph.get_nodes():
node.set_fontname(lambda x:'SimHei')
Image(graph.create_png())
graph.write_png('F:\Temp\img\wine.png')
保存为pdf文件
用了自带的render方法,没用save。感觉像是回到了第一个代码,不过安装Graphviz是真重点。
Microsoft YaHei 这个微软雅黑可以换成其他的,只要自己电脑里有就行。
import pandas as pd
import numpy as np
from sklearn import tree
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
import graphviz
import pydotplus
from IPython.display import Image
#[178 rows x 14 columns] 1~13都是特征列 0列才是标签
wine = pd.read_table('../../DataSet/01 决策树/wine.data',sep = ',',header=None)
# 将列名修改为中文
names = ['类型','酒精','苹果酸','灰','灰的碱度','镁','总酚类化合物',
'类黄酮','Nonflavanoid酚类','原花青素','颜色强度' ,'色调',
'稀释葡萄酒的OD280/OD315','脯氨酸']
wine.columns = names
Xtrain, Xtest, Ytrain, Ytest = train_test_split(wine.iloc[:,1:],wine.iloc[:,0],test_size=0.3)
clf = tree.DecisionTreeClassifier(criterion="entropy")
clf = clf.fit(Xtrain,Ytrain)
score = clf.score(Xtest,Ytest)
# print(score)
# dot -Tpng tree.dot -o test.png
# 绘制树
dot_data = tree.export_graphviz(clf,
feature_names=names[1:], # 特征名
class_names=["琴酒","雪莉","贝尔摩德"], # 为三个类别起个名(可随意)
filled=True,
rounded=True)
graph = graphviz.Source(dot_data.replace('helvetica','"Microsoft YaHei"'), encoding='utf-8')
# 在同级目录下生成两文件,一个无后缀,一个是pdf。而且加了jpg npg 等后缀生成的文件是没法用的
graph.render("tree")
# graph.view() 跟graph.render()类似,只不过自动帮你把pdf打开了
dot -Tpng tree.dot -o test.png dot -Tpdf tree.txt -o test.pdf
在cmd界面中,可以用这两条指令将文字形式的决策树转为相应文件。
生成文件乱码的,需要改 tree.dot(tree,txt) 文件中的helvetica ,在第二行和第三行,设置为:helvetica=‘想要设置的字体’
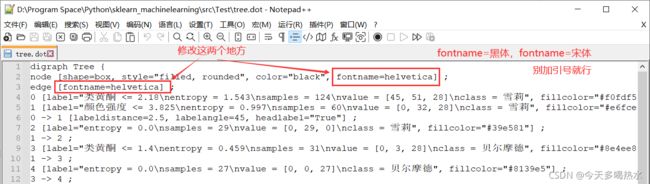
总结一下就是,在安装了Graphviz的前提下。
用第一个代码,将结果保存成一个文件,然后修改文件里的字体属性(上图给了两个修改模本)。最后就是在cmd界面,进入文件所在文件夹,用指令将文字转为图片或转为pdf。
用最后一个代码,运行之后会生成两个文件。一个没有后缀,一个是pdf。pdf可直接打开。
保存为图片
研究出来的一个新玩法。
核心代码是:dot_data.replace(‘helvetica’,’“Microsoft YaHei”’)。也是替换文字属性,在【保存为pdf】那一节中就用过。
import pandas as pd
import numpy as np
from sklearn import tree
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
import graphviz
import pydotplus
from IPython.display import Image
import codecs
#[178 rows x 14 columns] 1~13都是特征列 0列才是标签
wine = pd.read_table('../../DataSet/01 决策树/wine.data',sep = ',',header=None)
# 将列名修改为中文
names = ['类型','酒精','苹果酸','灰','灰的碱度','镁','总酚类化合物',
'类黄酮','Nonflavanoid酚类','原花青素','颜色强度' ,'色调',
'稀释葡萄酒的OD280/OD315','脯氨酸']
wine.columns = names
X = wine.iloc[:,1:]
Y = wine.iloc[:,0]
Xtrain, Xtest, Ytrain, Ytest = train_test_split(X,Y,test_size=0.3)
clf = tree.DecisionTreeClassifier(criterion="entropy")
clf = clf.fit(Xtrain,Ytrain)
score = clf.score(Xtest,Ytest)
# print(score)
# 绘制树
dot_data = tree.export_graphviz(clf,
feature_names=names[1:], # 特征名
class_names=["琴酒","雪莉","贝尔摩德"], # 为三个类别起个名(可随意)
filled=True,
rounded=True)
graph = pydotplus.graph_from_dot_data(dot_data.replace('helvetica','"Microsoft YaHei"'))
img = Image(graph.create_png())
graph.write_png('F:\Temp\img\wine.png')