推荐系统简介--转载
(13条消息) 推荐系统常用算法_一文带你了解推荐系统——常用召回和排序技术_weixin_39932300的博客-CSDN博客
现代移动互联网充斥着各种各样的信息,如购物、新闻,短视频,直播等等,经常使用户迷失在海量的信息中,无法找到真正感兴趣的内容。
因此推荐算法应运而生,应用于各大领域:“吃”有美团、饿了么等;“穿”有淘宝等;“住”有蛋壳、自如等;“行”有汽车之家等;“娱乐”有抖音、快手等;“旅行”有携程、去哪儿等。
当你打开App,就会有各种的推荐场景映入眼帘,例如:猜你喜欢、为你推荐等。推荐主要是根据用户的历史行为、相似用户、及相似物品等信息,进一步分析用户的消费点进而触达用户。
在工业推荐系统中,推荐系统包含两个步骤:召回和排序。
(1)召回环节:主要根据用户部分特征,从海量的物品库里,快速找回一小部分用户潜在感兴趣的物品。此环节要求速度快。
(2)排序环节:排序环节可以融入较多特征,使用复杂的模型,精准地做个性化推荐。此环节要求精度高。
图1展示了推荐系统的整体架构。
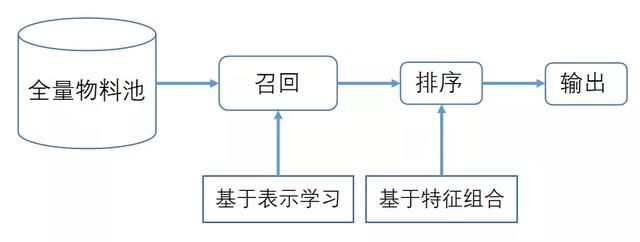
图1 推荐系统框架图
二、召回算法介绍
召回环节是推荐系统中很关键的一个环节,但是大多数召回环节偏向策略型导向,技术含量不高。召回环节一般采用多路召回,随便想到一个策略就可以当做一路召回。图2展示了召回环节的多路召回策略。
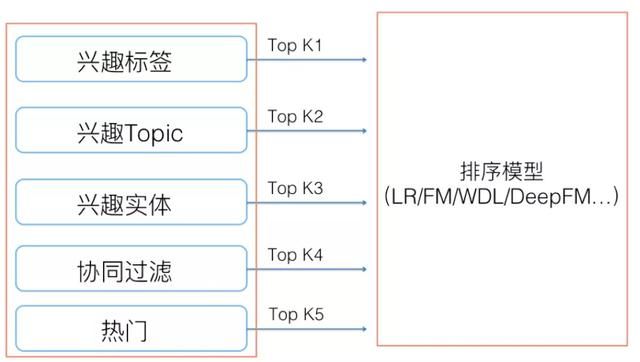
图2 召回环节:多路召回策略
召回内容可分为非个性化召回和个性化召回。例如:热门召回、高点击或高转化召回、新物料召回等召回方式是非个性化召回;用户的兴趣标签或物品的标签、及协同过滤等召回方式是个性化的召回。接下来主要介绍一下有点技术含量的个性化召回。
2.1基于内容的协同过滤
以电影推荐为例,我们知道用户对于历史观看过的电影的评分,将原始数据格式转化为评分矩阵,如图3下所示:
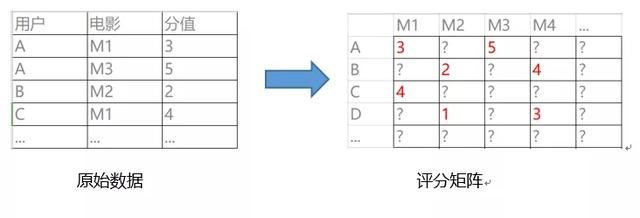
图3 原始数据转化为评分矩阵
用户只看过少部分电影,我们想要知道对于未看过的电影,用户可能对其的喜爱程度(打分)是多高。建模的过程就是填充空白项的过程,这样就得到了所有用户对所有电影的评分(喜好程度),然后就可进行个性化推荐。这种协同过滤方法基于场景一般采用UserCF或者ItemCF。
UserCF基于用户的相似度进行推荐,特点是具有较强的社交特性,用户能够快速得知与自己兴趣相似的人最近喜欢的是什么。例如用户A和用户B的兴趣类似,如果用户A对周星驰的电影《功夫》比较感兴趣,则系统更倾向于向用户B推荐该电影。
ItemCF 更适用于兴趣变化比较稳定的应用,用户在一段时间内更倾向于寻找一类物品,这时利用物品相似度为其推荐相关物品是契合用户动机的。例如X电影和Y电影为相关程度较高的搞笑类电影,如果用户A对X电影比较感兴趣,则系统更倾向于向用户A推荐Y电影。
2.2基于模型的协同过滤
基于模型的协同过滤算法是目前最主流的协同过滤类型,所包含算法非常之多,如矩阵分解、聚类算法、深度模型、图神经网络、知识图谱等。
该方式最终将用户和物品的信息通过Embedding的形式来表征,即生成User Embedding和Item Embedding供线上召回环节实时使用。Embedding向量的生成方式一般分为两类:
2.2.1基于矩阵分解生成隐向量
矩阵分解属于标准的MF(Matrix Factorization)方法,通过评分矩阵分解出代表用户的隐向量矩阵和代表物品的隐向量矩阵。矩阵分解过程如图4所示:
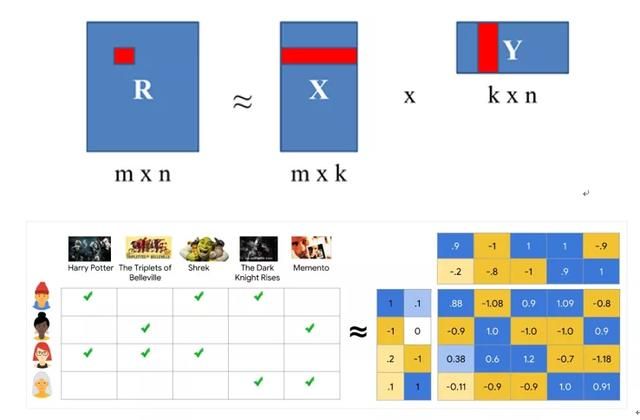
图4 矩阵分解图解
其中:R矩阵表示打分矩阵,X矩阵表示用户信息,Y矩阵表示物品信息;m表示用户个数,n表示物品个数,k表示表征用户或物品的向量长度。
通过矩阵分解,将得到用户的Embedding(X)和物品的Embedding(Y),该Embedding使得的乘积是R矩阵的近似表示。上述例子可以得到用户的Embedding表示为[1, 0.1],物品的Embedding表示为[0.9, -0.2]。
2.2.2 基于深度学习生成隐向量
随着深度学习的兴起,有学者提出了新的模型:即借鉴深度学习中的方法,使用深度神经网络(DNN)从数据中自动学习用户/物品隐向量的交互函数,在增强效果的同时也可以引入一定的泛化能力。
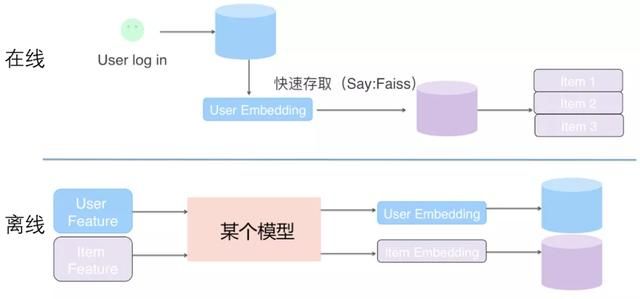
图5 深度召回模型离线及在线流程图
图5展示了一个抽象的深度召回模型的离线和在线的通用架构,核心思想是:将用户特征和物品特征分离,各自通过某个具体的模型,分别表征出用户Embedding以及物品Embedding。在线上,可以根据用户兴趣Embedding,采用类似ANN或Faiss等高效检索工具,快速找出和用户兴趣匹配的物品。理论上任何有监督“双塔结构”模型(见图6),都可以用来做这个召回模型,比如DSSM,YouTubeNet等。
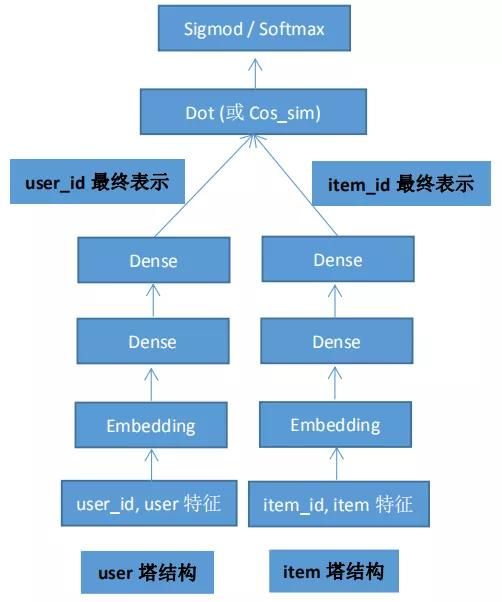
图6 “双塔”结构召回模型示意图
其中:User特征可以是画像特征、统计特征、多类型行为序列特征等;Item特征可以是画像特征、统计特征、文本特征、图片特征等。
下面介绍2个经典的深度召回模型。
(1)DSSM模型
DSSM模型是由微软提出的应用于文本相似度匹配场景下的一个算法,后来经过改良后应用于推荐场景下的召回环节。DSSM模型结构如图7所示。可以看出DSSM模型是个标准的“双塔”结构的模型。Q表示Query,即用户端的信息;D表示Document,即候选物品集端的信息。Query 和 Document 的语义相似性可以用这两个语义Embedding向量的 cos 距离来表示:
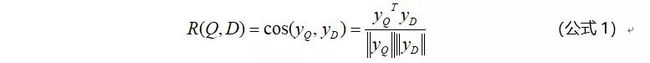
然后通过Softmax 函数可以把Query 与正样本 Doc 的语义相似性转化为一个后验概率:
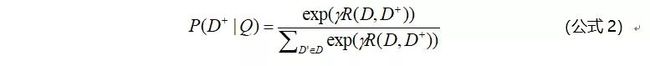
然而应用于推荐召回时,这里不再使用Softmax模型(即公式2),而是对每对预测一个cos值(即只应用公式1)。
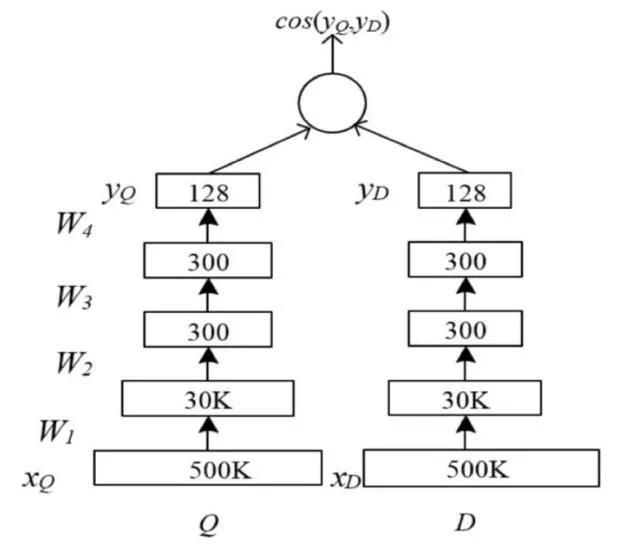
图7 DSSM模型结构图
(2)YouTubeNet模型
YouTubeNet模型是推荐系统领域中最为经典的论文之一“Deep Neural Networks for YouTube Recommendations”,这篇视频推荐模型框架基本上奠定了后面推荐系统的主要步骤。主要框架如图8所示:
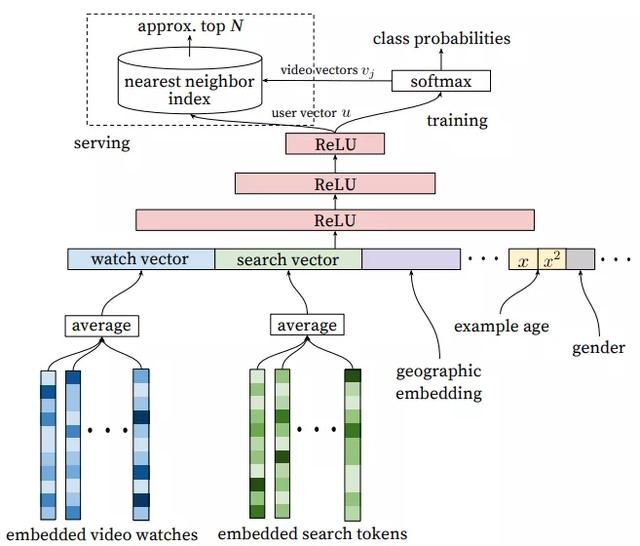
图8 YouTubeNet召回模型结构
特征:用户观看过视频的Embedding向量、用户搜索词的Embedding向量、用户画像特征、context上下文特征等。
训练模型:三层ReLU神经网络之后接Softmax层,去预测用户下一个感兴趣的视频,输出是在所有候选视频集合上的概率分布。训练完成之后,最后一层Relu的输出作为User Embedding,Softmax的权重可当做当前预测Item的Embedding表示。
线上预测:通过UserId找到相应的User Embedding,然后使用NN方法(比如Faiss)找到相似度最高的topN条候选结果返回。
除了上述提到的2个常用的召回模型外,现在的召回模型逐渐趋向于复杂化,当然效果还是很可观的。例如:
(3)结合用户行为建模方向的算法
(a)阿里算法团队提出的用户多兴趣表达的Embedding向量召回(Multi-Interest Network with Dynamic Routing for Recommendation at Tmall)
(b)阿里算法团队提出的长短期兴趣表达的Embedding向量召回(SDM: Sequential Deep Matching Model for Online Large-scale Recommender System)
(4)图神经网络方向的算法
图模型的最终目的是要通过一定技术手段,获得图中节点的embedding向量。
(a)阿里算法团队提出的基于Side Information的图嵌入学习算法(Billion-scale Commodity Embedding for E-commerce Recommendation in Alibaba)
(b)斯坦福大学提出的聚合节点信息的算法(GraphSAGE:Inductive representation learning on large graphs)
(5)知识图谱方向的算法
知识图谱是一种三元组结构,通过传播的模式拓展信息及丰富节点信息。
(a)推荐系统领域专家何向南团队提出的知识图谱和注意力机制的算法(KGAT: Knowledge Graph Attention Network for Recommendation)
(b)上海交通大学团队提出的基于知识图谱传播用户兴趣的算法(RippleNet: Propagating User Preferences on the Knowledge Graph for Recommender Systems)
上述提到的算法皆为经典算法,在工业界有着较为广泛的应用,感兴趣的同学可以自行研究,也可以一起讨论和学习。
三、排序算法介绍
排序环节是推荐系统最关键,也是最具有技术含量的部分,目前大多数推荐技术其实都聚焦在这块。排序环节主要包含两部分:特征工程和模型。
3.1 特征工程
特征是模型的核心内容,在排序模型中所采用的特征比召回模型的特征更细致化。在工业界不会轻易地展示出具体的特征,即不传之秘。但是主要包含以下几个方面:
(1)用户端特征:画像特征,偏好特征,统计特征,行为序列特征等;
(2)物品端特征:画像特征,统计特征,文本特征,图像特征等;
(3)上下文特征:时间,地点,天气,网络,设备,召回源等;
3.2 点击预估模型
3.2.1 机器学习点击预估模型
在深度学习之前,早期的排序模型采用的是传统的机器学习模型,如LR、FM、GBDT+LR等。
(1)LR一般代指逻辑回归模型,是广义线性模型,一般用于解决二分类问题。优点就是模型简单,训练速度快,消耗资源少;缺点也很明显,缺少非线性的特征交叉,泛化性较低。
(2)为了将特征交叉考虑进去,FM模型被广泛使用。FM模型在LR模型的基础上增加了自动二阶特征交叉的部分。不同于只有用户、物品Id两类特征的CF模型(即MF模型),FM可以添加任意多的特征。隐向量的引入也使得模型可以泛化到未曾出现过的特征组合中,兼顾了模型的记忆性和泛化性。
(3)为了寻找不同特征之间的组合,FaceBook公司率先提出用GBDT进行特征组合,自上而下每条路径代表一种高阶特征交叉,然后叶子节点编号作为LR的输入。但是这种方法的缺点是可能导致过拟合高维稀疏数据,GBDT不能将数据batch输入,无法并行,因此速度慢、泛化性差。
3.2.2 深度学习点击预估模型
目前大部分科技公司都在应用深度学习模型进行Feed流推荐,图9是推荐系统领域的一位大牛 @王喆 总结的深度学习CTR模型最全演化图谱。该演进图详细了描述在技术层面的改进点。
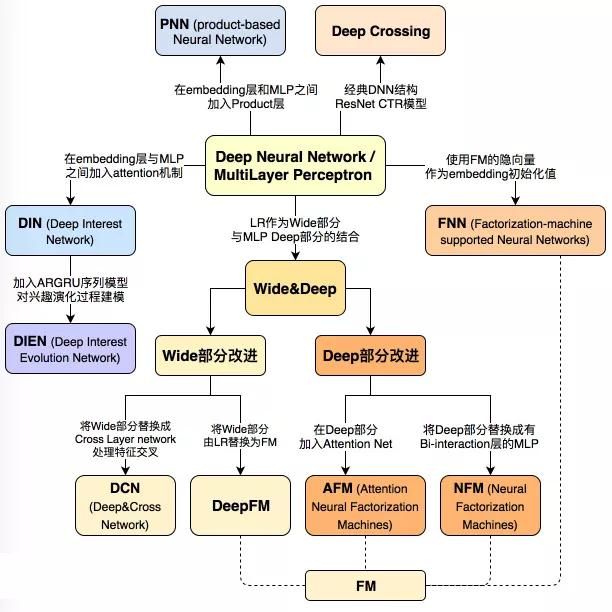
图9 深度学习CTR模型演化图谱
主要是以多层感知机为核心,通过改变神经网络的结构,构建特点各异的深度学习推荐模型。
(1)改变神经网络的复杂结构
从最简单的单层神经网络模型AutoRec(自编码器推荐)到经典的深度神经网络结构Deep Crossing(深度特征交叉),其主要在于增加了模型的层级和结构复杂度。
(2)改变特征的交叉方式
这类模型的主要改变在于丰富了深度学习网络中特征交叉的方式。例如改变了用户向量和物品向量互操作方式的NeuralCF(Neural Collaborative Filtering,神经网络协同过滤),定义了多种特征向量交叉操作的PNN(Product-based Neural Network, 即操作神经网络)模型。
(3)模型组合
这类模型主要是指Wide & Deep 模型及其后续变种的 Deep & Cross、DeepFM等,其思路主要是通过组合两种或多种不同特点、优势互补的深度学习网络,提升模型的预测能力;
(4)FM算法的深度模型演进
传统的推荐算法FM在深度学习时代有了更广阔的发展势头,其中包括NFM(Neural Factorization Machine, 神经网络因子分解机)、FNN(Factorization-machine supported Neural Network,基于因子分解机支持的神经网络)、AFM(Attention Neural Factorization Machine,注意力因子分解机)等,它们对FM的改进方向各不相同。例如:NFM组要使用神经网络提升FM二阶部分的特征交叉能力,AFM是引入了注意力机制的FM模型,FNN利用FM的结果进行网络的初始化。
(5)注意力机制和推荐模型的结合
此类模型主要是将“注意力机制(Attention)”应用于深度学习模型中,主要包括结合FM和注意力机制的AFM模型、引入注意力机制的CTR预估模型DIN(Deep Interest Network,深度兴趣模型)。
(6)序列模型与推荐模型的结合
这类模型主要特点是使用序列模型模拟用户行为或用户兴趣的演变趋势,代表作有阿里算法团队的DIEN(Deep Interest Evolution Network,深度兴趣进化网络)及DSIN(Deep Session Interest Network,深度会话兴趣网络)。
(7)强化学习与推荐算法模型的结合
这类算法是将强化学习的思想应用于推荐系统领域,强调模型的在线学习和实时更新,代表作模型为DRN(Deep Reinforcement Learning Network,深度强化学习网络)。
除了模型的创新改进,在“多任务学习”和“多模态融合”角度也能增加模型的表达能力。
(8)多任务模型
在优化推荐效果的时候,很多时候不仅仅需要关注 CTR 指标,同时还需要优化例如 CVR ( 转化率 )、视频播放时长、用户停留时长、用户翻页深度、关注率、点赞率这些指标。那么能不能使用一个模型来同时优化两个或多个任务呢?这就属于多任务学习(Multi-Task Learning)。业界比较有名的是:
(a)阿里算法团队提出的ESMM(Entire Space Multi-Task Model: An Effective Approach for Estimating Post-Click Conversion Rate),有效解决了真实场景中CVR预估面临的数据稀疏以及样本选择偏差这两个关键问题。
(b)谷歌算法团队提出的YouTube多目标排序系统(Recommending What Video to Watch Next: A Multitask Ranking System)。
(9)多模态信息融合
所谓模态,指的是不同类型的或者模态形式的信息存在形式,即异构数据,比如文本、图片、视频、音频、互动行为、社交关系等。让模型能够接受不同模态类型的信息,并做知识和信息互补,更全面理解实体或者行为。这不仅仅是推荐领域的技术趋势,也是人工智能领域都面临的重大发展方向,所以这个方向特别值得重视。
作者:王多鱼 京东推荐算法攻城狮。主要负责商品推荐的召回和排序模型的优化工作。