双目立体匹配_StereoNet网络
双目立体匹配_StereoNet网络
端到端立体匹配网络:通常以左右视图作为输入,经卷积模块提取特征后,按相关性操作(Correlation)或拼接操作(Concat)构建代价体,最后根据代价体的维度进行不同的卷积操作,回归出视差图。
根据代价体维度的不同,可分为基于 3D 代价体和基于 4D 代价体的两种方法, 2D 编码器-解码器和 3D 卷积正则化模块是分别用来处理 3D 和 4D 代价体的两种结构。2D 编码器-解码器由一系列堆叠的 2D CNN 组成,并带有跳跃连接。而 3D 正则化模块是在构建代价体时将提取的左右图特征沿视差维度拼接以得到一个 4D 的代价体,而后使用 3D CNN 处理 4D 代价体,充分利用了视差维度的信息。
文章目录
- 双目立体匹配_StereoNet网络
- 前言
- 1、GCNet网络架构
- 2、StereoNet网络架构
- 3、双目立体匹配数据集
- 4、实验过程
-
- 实验1:只在Sceneflow数据集上训练
- 实验2:只在KITTI2012数据集上训练
- 实验3:先在Sceneflow数据集上pretrain,再在KITTI2012数据集上finetune
- 实验4:先在Sceneflow数据集上pretrain,再在KITTI2012+2015数据集上finetune
- 五、细节与想法
- 六、源代码
前言
传统立体匹配算法通常选取立体校正后的左视图作为参考图像,通过在目标图像上进行行搜索寻找同名点并计算视差,将每个像素的视差进行保存,得到单通道的视差图。距离相机越近的空间点,在视差图中灰度值越大。传统立体匹配算法将双目立体匹配问题转化寻找最小化能量函数的图D问题,此处的D可以时深度图或视差图,因此在深度学习领域立体匹配又被成为视差估计、深度估计。
随着神经网络、深度学习技术的不断发展,学者认识到双目立体匹配问题接近于传统的密集回归问题(如语义分割、光流估计等),受U-Net模型的启发,Mayer等人基于光流估计网络FlowNet提出DispNet,成为第一个非常经典的端到端视差估计网络。与U-Net网络结构类似,DispNet先在收缩路径进行特征提取与空间压缩,然后在扩张路径进行尺度恢复与视差预测,并通过长距离跳跃连接实现多层次特征融合,保留更多的网络层信息。
与受传统神经网络模型启发的架构不同,基于4D代价体的端到端立体匹配网络架构是专门为立体匹配任务而设计,这一架构下的网络不再对特征进行降维操作,从而使代价体能保留更多的图像几何和上下文信息。StereoNet网络是在GC-Net网络的基础上改进而来。
1、GCNet网络架构
GC-Net是由Kendall等人提出的一种新型深度视差学习网络架构,作者创造性地引入了4D代价体,并在正则化模块中首次利用3D卷积来融合4D代价体的上下文信息,开创了专门用于立体匹配的3D网络结构。

GC-Net包含四个步骤:1、利用权值共享的2D卷积层分别提取左右图像的高维特征,并在此阶段进行下采样将原始分辨率减半以减少内存需求;2、将左特征图和对应通道的右特征图沿视差维度逐像素错位串联得到4D代价体;3、利用由多尺度的3D卷积和反卷积组成的编码、解码模块对代价体进行正则化操作,得到大小为1的代价体张量;4、对代价体应用可微的SoftArgMax操作回归得到视差图。GC-Net创造性的使用3D卷积构建3D代价体,通过downsampling构造多尺度的3D卷积,并不像传统方法一样使用特征的差值或者距离来计算代价体,而是使用3D卷积,从而学到更多的语义信息,优化了最终的视差图质量。
尽管上述基于4D代价体的端到端网络展示了出色的匹配效果,但由于3D卷积结构本身的计算复杂度,导致网络在存储资源和计算时间上成本高昂,以GC-Net为例,处理分辨率为1216、352尺寸的图像对大约需要10.4G的GPU内存。为了解决此问题,压缩代价体、构建更低分辨率的代价体或减少3D卷积层个数等多种思路被提出。Khamis等人采取设计低分辨率代价体的思路,提出了实时轻量立体匹配网络StereoNet,算法直接在得到低分辨率的视差图后通过2D卷积网络进行上采样和视差优化,以此降低网络的复杂性。
2、StereoNet网络架构
StereoNet使用Siamese网络从左右图像中提取特征,在非常低分辨率的cost volume中计算视差估计,然后分层进行上采样并重新引入高频细节,利用颜色输入作为指导生成高质量的边缘结果。在整体思路上,StereoNet网络将cost volume设计的比较小,但是仍然可以包含了较多的特征信息,只会有较少的精度损失,这样网络可以先得到一个粗糙的视差图,之后再设计了一种层次化的、边缘敏感的精修网络,实际上是利用卷积网络估计残差,利用残差和粗糙的视差图分层优化,最终可以得到更加细致、保留边缘的视差图。
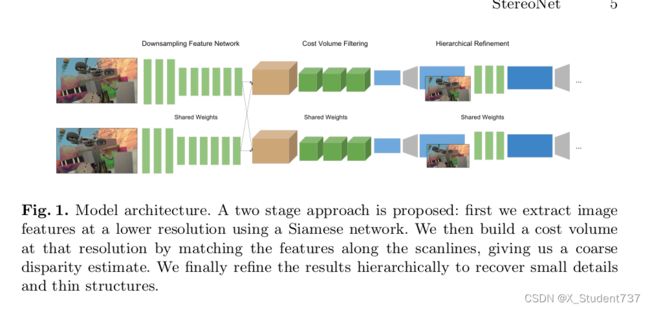
StereoNet网络大致可分为四个部分。第一部分是特征提取模块,网络采用了一个简单的结构,先利用大小为5、步长为2的卷积进行降采样,然后利用一系列大小为3、步长为1的卷积进行特征提取,重复3到4次。第二部分是匹配代价计算模块,为提高运算效率,网络直接通过错位相减,从而构建匹配代价体。第三部分是代价聚合模块,网络利用一系列3D卷积进行滤波,对代价体进行正则化。第四部分是视差计算和优化模块,网络利用当前尺度的图像对当前尺度的视差图进行导向滤波,即首先利用双线性插值上采样视差图,提高一倍其分辨率,然后将当前尺度的影像和插值得到的视差图一起放到一系列的空洞卷积里优化,得到当前尺度的结果。
3、双目立体匹配数据集
SceneFlow数据集是目前规模最大的双目立体视觉公开数据集,所有场景都是利用3D模型人工合成的虚拟数据,包括三个子数据集:FlyingThings3D、Monkaa和Driving。FlyingThings3D中主要包括静态背景中沿3D轨迹随机飞行的日常物体。Monkaa是基于动画短片创建,其中包含了非刚性和柔和的关节运动,以及视觉上极具挑战性的皮毛问题。Driving模拟的是驾驶场景下的动态街景,与KITTI数据集相似。SceneFlow数据集中共包含35454对立体图像对作为训练集,4370对立体图像对作为测试集,图片大小均为960、540,训练集和测试集均提供了稠密而精细(100%)的真实视差值。该数据集是专门为训练和测试基于深度学习的立体匹配算法设计的。

KITTI Stereo数据集是使用经过校准的双目相机与车载激光雷达在真实室外场景中采集的一个小型数据集,可以测试算法针对室外真实场景的匹配精度与实时性,广泛应用于视差估计、目标检测、语义分割等领域。由于室外场景中包含大量车辆、行人、路标以及周围的房屋和树木等,极具挑战性和多样性。

KITTI Stereo数据集中包含KITTI 2012和KITTI2015两个子数据集。KITTI2012数据集中包含194对具有稀疏真实视差图的立体图像作为训练集,195对没有真实视差图的立体图像作为测试集,图片大小为1240、375,且同时给出了灰度和彩色图像。KITTI2015数据集扩充了车辆玻璃高光反射时的判断以及车辆在运动时拍摄的情况,训练集和测试集都包含200对立体图像,图片大小均为1242、375。其中训练集的真实视差图中只提供了不到50%的稀疏真实视差,测试集没有提供真实视差图。
4、实验过程
实验1:只在Sceneflow数据集上训练
Sceneflow数据集比较大,差不多200G,必须得借助服务器训练。此外FlyingThings3D、Monkaa和Driving不同文件夹的标签分布差异较大,训练起来会比较困难,甚至会出现loss跳跃现象。我在8张RTX3090上联合训练了5天,跑了差不多500个epoch,权重才逐渐收敛。前200个epoch学习率设为1e-4,后面调整至1e-5,采用的是 optim.Adam优化器,batchsize选择4、16、32、64或128都行。

由于Sceneflow数据集标签是稠密视差图,训练起来的效果会好很多。加载Sceneflow数据集预训练得到的模型权重,选取Sceneflow测试集中的双目图像进行测试,计算得到平均视差精度为92.69%,即视差偏差在3像素以内(包括3像素)的像素占所有有效像素的比例。预测视差效果如下图所示,左图代表StereoNet网络预测视差图,右图代表真实视差图。

通常情况下,Sceneflow数据集训练出来的网络权重,可以作为其他数据集的预训练加载权重。
实验2:只在KITTI2012数据集上训练
KITTI2012数据集只有200对双目图像,我划分180对为训练集,20对为测试集。此外KITTI Stereo数据集的视差图为稀疏视差图,只在视差大于0的像素位置提供真值,计算损失时采用L1_smooth回归损失,但仅对y_true大于0的像素部分进行处理,其余像素位置的损失值忽略。如果不加载Sceneflow数据集的预训练权重,其实也能训练出效果。
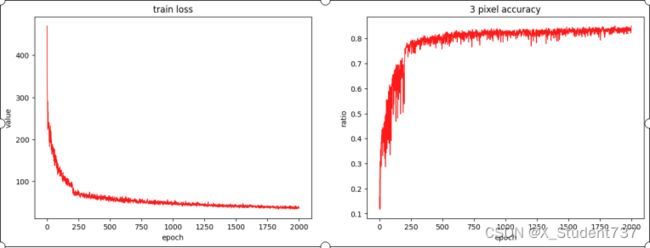
我在KITTI2012数据集上训练了2000个epoch,前200个epoch学习率为1e-3,后面调整至1e-4,优化器设置为Adam,batch_size设置为4,训练会逐渐收敛,并且可以获得一个还能接受视差预测效果。

计算测试集20对双目图像的计算耗时和视差精度,视差精度表示为视差偏差在3像素以内(包括3像素)的像素占所有有效像素的比例,20对双目图像的平均视差精度为81.85%。
实验3:先在Sceneflow数据集上pretrain,再在KITTI2012数据集上finetune
采用和实验2一样的处理步骤,不过不是从零开始训练,而是加载Sceneflow数据集上的预训练权重,训练效果果然能够提升。此外我尝试了不同学习率下的训练效果,发现在前200轮学习率1e-3,第200轮到第2000轮学习率1e-4,第2000轮后学习率1e-5此时收敛精度最好。而如果采用1e-4+1e-5的设置,训练效果略有欠缺。

加载KITTI Stereo数据集Finetune得到的模型权重,选取测试集中的20对双目图像进行测试,计算得到平均视差精度为86.14%,即视差偏差在3像素以内(包括3像素)的像素占所有有效像素的比例。

实验4:先在Sceneflow数据集上pretrain,再在KITTI2012+2015数据集上finetune
我利用实验3预测出的视差图进行三维重建,重建效果还是不太满意,想进一步提高KITTI数据集的双目重建精度。考虑到KITTI2012数据量还是太少了,于是尝试在实验3的基础上,进一步融合KITTI2012+KITTI2015数据集一起训练。
前200轮学习率1e-3,第200轮到第2000轮学习率1e-4,第2000轮后学习率1e-5,采用Adam优化器,batch_size取4。
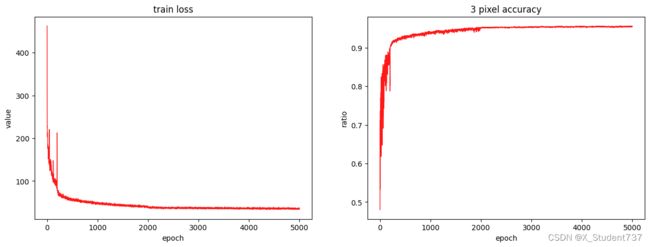
加载KITTI Stereo数据集Finetune得到的模型权重,选取测试集中的20对双目图像进行测试,计算得到平均视差精度为90.09%。






利用训练出来的视差图进行三维重建,输入为左目和右目RGB图像:


StereoNet预测得到左目视差图为:

三维重建效果如下:
五、细节与想法
1、Sceneflow数据集的视差标签,直接读取即可,不需做额外处理;KITTI Stereo数据集的视差标签,数值需要额外除以256。
2、StereoNet训练时使用数据增强,不是直接对图像做resize缩放,这样会导致图像形变,源码采用在原图中先随机选定256、512区域,再裁减,这时不光增加了样本多样性,而且也不会导致图像形变,视差数值也不用等比例缩放了。
3、StereoNet是真的学习到了视差匹配,而不是强行拟合数据。网络训练时输入图像对使用的是256、512尺寸,但测试时直接输入的是368、1232,照样能准确输出视差值。
4、StereoNet推理速度比较快,368、1232图像尺寸,单张RTX2070推理时间0.05s,而且模型保存权重很小,大概占5M的空间。
5、不同pytorch版本保存的权重是有差异的,1.6.0版本后的模型无法加载1.6.0版本前保存的权重。
六、源代码
如果需要源代码,或者想直接使用数据集,可以去我的主页寻找项目链接,以上代码和实验结果都由本人亲自实验得到:
https://blog.csdn.net/Twilight737