densenet代码解读
densenet代码解读
目录
- 概述
- densenet网络结构图
- densenet网络架构参数
- densenet代码细节分析
概述
densenet是一篇受到了resnet启发的文章,它将resnet跳跃连接的思想发扬光大,在输出层不仅会加上输入层的信息,而且将“连接”做到极致,在每一个block里面,每一层的输出都会连接到后一层的输入,充分利用前面得到的特征图。
densenet网络结构图
单个denseblock的结构图

一个具有3个dense block的densenet网络的结构图如下所示:

densenet网络架构参数
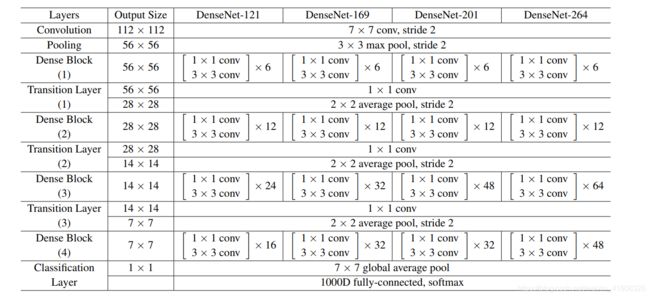
densenet代码细节分析
import re
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.checkpoint as cp
from collections import OrderedDict
# from .utils import load_state_dict_from_url
from torch import Tensor
from typing import Any, List, Tuple
from torchsummary import summary
# 可选择的densenet模型
__all__ = ['DenseNet', 'densenet121', 'densenet169', 'densenet201', 'densenet161']
# 可下载的densenet预训练权重
model_urls = {
'densenet121': 'https://download.pytorch.org/models/densenet121-a639ec97.pth',
'densenet169': 'https://download.pytorch.org/models/densenet169-b2777c0a.pth',
'densenet201': 'https://download.pytorch.org/models/densenet201-c1103571.pth',
'densenet161': 'https://download.pytorch.org/models/densenet161-8d451a50.pth',
}
# 定义一个denseblock(dense layer),其中growth_rate的意思是一层产生多少个特征图
class _DenseLayer(nn.Module):
def __init__(
self,
num_input_features: int,
growth_rate: int,
bn_size: int,
drop_rate: float,
memory_efficient: bool = False
) -> None:
super(_DenseLayer, self).__init__()
# 首先对输入做一次bn、激活、卷积
self.norm1: nn.BatchNorm2d
self.add_module('norm1', nn.BatchNorm2d(num_input_features))
self.relu1: nn.ReLU
self.add_module('relu1', nn.ReLU(inplace=True))
self.conv1: nn.Conv2d
# 输出特征图的数量为bn_size*growth_rate,卷积、bn、激活
self.add_module('conv1', nn.Conv2d(num_input_features, bn_size *growth_rate, kernel_size=1, stride=1,bias=False))
self.norm2: nn.BatchNorm2d
self.add_module('norm2', nn.BatchNorm2d(bn_size * growth_rate))
self.relu2: nn.ReLU
self.add_module('relu2', nn.ReLU(inplace=True))
self.conv2: nn.Conv2d
self.add_module('conv2', nn.Conv2d(bn_size * growth_rate, growth_rate,kernel_size=3, stride=1, padding=1,bias=False))
self.drop_rate = float(drop_rate)
self.memory_efficient = memory_efficient
def bn_function(self, inputs: List[Tensor]) -> Tensor:
concated_features = torch.cat(inputs, 1)
bottleneck_output = self.conv1(self.relu1(self.norm1(concated_features))) # noqa: T484
return bottleneck_output
# 判断当前tensor是否参与梯度传播
def any_requires_grad(self, input: List[Tensor]) -> bool:
for tensor in input:
if tensor.requires_grad:
return True
return False
# @torch.jit.unused # noqa: T484
def call_checkpoint_bottleneck(self, input: List[Tensor]) -> Tensor:
def closure(*inputs):
return self.bn_function(inputs)
return cp.checkpoint(closure, *input)
# @torch.jit._overload_method # noqa: F811
def forward(self, input: List[Tensor]) -> Tensor:
pass
# @torch.jit._overload_method # noqa: F811
def forward(self, input: Tensor) -> Tensor:
pass
# torchscript does not yet support *args, so we overload method
# allowing it to take either a List[Tensor] or single Tensor
def forward(self, input: Tensor) -> Tensor: # noqa: F811
if isinstance(input, Tensor):
prev_features = [input]
else:
prev_features = input
if self.memory_efficient and self.any_requires_grad(prev_features):
if torch.jit.is_scripting():
raise Exception("Memory Efficient not supported in JIT")
bottleneck_output = self.call_checkpoint_bottleneck(prev_features)
else:
bottleneck_output = self.bn_function(prev_features)
new_features = self.conv2(self.relu2(self.norm2(bottleneck_output)))
# 加上dropout
if self.drop_rate > 0:
new_features = F.dropout(new_features, p=self.drop_rate,training=self.training)
return new_features
class _DenseBlock(nn.ModuleDict):
_version = 2
def __init__(
self,
num_layers: int,
num_input_features: int,
bn_size: int,
growth_rate: int,
drop_rate: float,
memory_efficient: bool = False
) -> None:
super(_DenseBlock, self).__init__()
# 随着layer层数的增加,每增加一层,输入的特征图就增加一倍growth_rate
for i in range(num_layers):
layer = _DenseLayer(
num_input_features + i * growth_rate,
growth_rate=growth_rate,
bn_size=bn_size,
drop_rate=drop_rate,
memory_efficient=memory_efficient,
)
# 添加一层layer
self.add_module('denselayer%d' % (i + 1), layer)
def forward(self, init_features: Tensor) -> Tensor:
# 提取特征
features = [init_features]
for name, layer in self.items():
new_features = layer(features)
features.append(new_features)
# 将特征图concat在一起
return torch.cat(features, 1)
class _Transition(nn.Sequential):
def __init__(self, num_input_features: int, num_output_features: int) -> None:
super(_Transition, self).__init__()
# transition层使用的是1 x 1卷积核,作用是用来改变通道数
self.add_module('norm', nn.BatchNorm2d(num_input_features))
self.add_module('relu', nn.ReLU(inplace=True))
self.add_module('conv', nn.Conv2d(num_input_features, num_output_features,kernel_size=1, stride=1, bias=False))
self.add_module('pool', nn.AvgPool2d(kernel_size=2, stride=2))
class DenseNet(nn.Module):
def __init__(
self,
growth_rate: int = 32,
block_config: Tuple[int, int, int, int] = (6, 12, 24, 16),
num_init_features: int = 64,
bn_size: int = 4,
drop_rate: float = 0,
num_classes: int = 1000,
memory_efficient: bool = False
) -> None:
super(DenseNet, self).__init__()
# 第一层卷积
self.features = nn.Sequential(OrderedDict([
('conv0', nn.Conv2d(3, num_init_features, kernel_size=7, stride=2,
padding=3, bias=False)),
('norm0', nn.BatchNorm2d(num_init_features)),
('relu0', nn.ReLU(inplace=True)),
('pool0', nn.MaxPool2d(kernel_size=3, stride=2, padding=1)),
]))
# 构建每一个denseblock
num_features = num_init_features
for i, num_layers in enumerate(block_config):
block = _DenseBlock(
num_layers=num_layers,
num_input_features=num_features,
bn_size=bn_size,
growth_rate=growth_rate,
drop_rate=drop_rate,
memory_efficient=memory_efficient
)
self.features.add_module('denseblock%d' % (i + 1), block)
num_features = num_features + num_layers * growth_rate
if i != len(block_config) - 1:
trans = _Transition(num_input_features=num_features,
num_output_features=num_features // 2)
self.features.add_module('transition%d' % (i + 1), trans)
num_features = num_features // 2
# 最后一个bn层
self.features.add_module('norm5', nn.BatchNorm2d(num_features))
# 分类器
self.classifier = nn.Linear(num_features, num_classes)
# 参数初始化
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.constant_(m.bias, 0)
def forward(self, x: Tensor) -> Tensor:
# 提取特征、激活、池化、摊平、分类
features = self.features(x)
out = F.relu(features, inplace=True)
out = F.adaptive_avg_pool2d(out, (1, 1))
out = torch.flatten(out, 1)
out = self.classifier(out)
return out
# 加载训练权重
def _load_state_dict(model: nn.Module, model_url: str, progress: bool) -> None:
# '.'s are no longer allowed in module names, but previous _DenseLayer
# has keys 'norm.1', 'relu.1', 'conv.1', 'norm.2', 'relu.2', 'conv.2'.
# They are also in the checkpoints in model_urls. This pattern is used
# to find such keys.
pattern = re.compile(
r'^(.*denselayer\d+\.(?:norm|relu|conv))\.((?:[12])\.(?:weight|bias|running_mean|running_var))$')
state_dict = load_state_dict_from_url(model_url, progress=progress)
for key in list(state_dict.keys()):
res = pattern.match(key)
if res:
new_key = res.group(1) + res.group(2)
state_dict[new_key] = state_dict[key]
del state_dict[key]
model.load_state_dict(state_dict)
def _densenet(
arch: str,
growth_rate: int,
block_config: Tuple[int, int, int, int],
num_init_features: int,
pretrained: bool,
progress: bool,
**kwargs: Any
) -> DenseNet:
model = DenseNet(growth_rate, block_config, num_init_features, **kwargs)
if pretrained:
_load_state_dict(model, model_urls[arch], progress)
return model
# 预训练权重,其中第一个参数'densenet121'代表densenet的模型名称,32代表每一层添加32个特征图,(6, 12, 24, 16)表示4个denselayer重复的次数,64表示初始特征数
def densenet121(pretrained: bool = False, progress: bool = True, **kwargs: Any) -> DenseNet:
return _densenet('densenet121', 32, (6, 12, 24, 16), 64, pretrained, progress,
**kwargs)
def densenet161(pretrained: bool = False, progress: bool = True, **kwargs: Any) -> DenseNet:
return _densenet('densenet161', 48, (6, 12, 36, 24), 96, pretrained, progress,
**kwargs)
def densenet169(pretrained: bool = False, progress: bool = True, **kwargs: Any) -> DenseNet:
return _densenet('densenet169', 32, (6, 12, 32, 32), 64, pretrained, progress,
**kwargs)
def densenet201(pretrained: bool = False, progress: bool = True, **kwargs: Any) -> DenseNet:
return _densenet('densenet201', 32, (6, 12, 48, 32), 64, pretrained, progress,
**kwargs)