使用gensim.models.word2vec.LineSentence之前的语料预处理
nlp小白摸爬滚打的叨叨叨记录
在进行自然语言处理工作时,不可避免使用大型语料库。在这里记录并分享做自己实验的时候读函数文档,以及参考各路大神,终于明白LinSentence如何使用的历程。
函数文档链接:models.word2vec – Word2vec embeddings — gensim
(课题师兄说使用库的时候尽量看库文档)
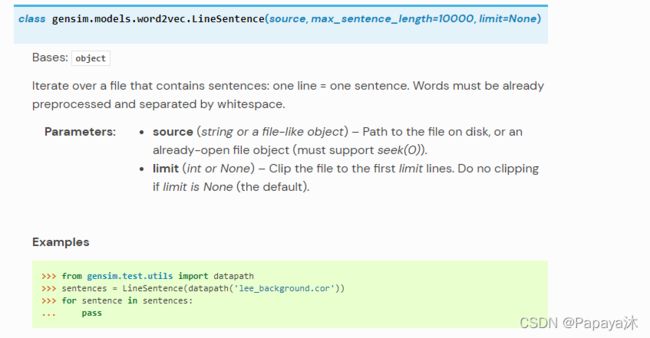
LinSentence 函数在使用之前需要对待处理的文本数据进行分词,并以空格分隔;函数在运行时,按行读取已经以空格分隔的文档。
以下是实验代码
导入即将使用到的库
# -*- coding: utf-8 -*-
import math
import jieba
import jieba.posseg as psg
from gensim import corpora, models
from jieba import analyse
import functools原始语料展示

可以看到原始语料如果经过分词后,会有一些无效词汇以及标点符号的出现,所以将对原始预料进行去停用词、干扰词处理。(停用词文件可自行选取,我用的是哈工大版本)
去除干扰词函数
# 去除干扰词
def word_filter(seg_list, pos=False):
stopword_list = get_stopword_list()
filter_list = []
# 根据POS参数选择是否词性过滤
## 不进行词性过滤,则将词性都标记为n,表示全部保留
for seg in seg_list:
if not pos:
word = seg
flag = 'n'
else:
word = seg.word
flag = seg.flag
if not flag.startswith('n'):
continue
# 过滤停用词表中的词,以及长度为<2的词
if not word in stopword_list and len(word) > 1:
filter_list.append(word)
return filter_list去除停用词函数
# 停用词表加载方法
def get_stopword_list():
# 停用词表存储路径,每一行为一个词,按行读取进行加载
# 进行编码转换确保匹配准确率
stop_word_path = './data/stopword.txt'
stopword_list = [sw.replace('\n', '') for sw in open(stop_word_path,encoding='utf-8').readlines()]
return stopword_list
# # ---停用词补充,视具体情况而定---
# stopword.append('---')
# stopword.append('----')
# i = 0
# for i in range(19):
# stopword.append(str(10+i))文本预处理:对语料集精确模式分词、去停用词、以空格分割词汇
import jieba
#对数据分词,去除停用词,并以空格作为分隔
def data_pre_process(corpus_path,reduse_name):
file_read = open(corpus_path, 'rb') #打开语料数据
raw_corpus = file_read.read() #读取未分词语料
#以精确模式分词,存为列表
seg_corpus = jieba.lcut(raw_corpus,cut_all = False) #对数据进行分词
print(seg_corpus) #查看分词结果
#去除停用词
pos = False
filter_list = word_filter(seg_corpus, pos)
file_write = open(reduse_name,'w+')
file_write.write(" ".join(filter_list)) #用空格将分词结果分开并写入到分词后语料文件中
file_read.close()
file_write.close()
return
#try
corpus_path = "./data/corpus.txt"
reduse_path = "./data/reduse_corpus"
data_pre_process(corpus_path,reduse_path)查看结果

然后就可以在Word2Vec中直接使用LineSentence进行词向量训练了
# -*- coding: utf-8 -*-
from gensim.models import Word2Vec
from gensim.models.word2vec import LineSentence #大型语料库可使用linesentence和text8corpus处理
import logging
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
def training():
#使用LineSentence函数处理语料,可避免前期构建语料的复杂性。
model = Word2Vec(LineSentence(open('./data/reduse_corpus.txt', 'r',encoding = 'utf8')),
sg=0,
vector_size=100,
window=5,
min_count=1,
workers=8
)
#词向量保存
model.wv.save_word2vec_format('corpus_embedding.vector', binary=False)
#模型保存
model.save('model_corpus_w2v.word2vec')
if __name__ == '__main__':
training()原创不易,引用请注明出处~【笔芯】