计算机视觉之目标检测(object detection)《1》
在计算机视觉领域,除了识别图像并分类之外,我们很多时候想关注图像里面一些感兴趣的目标,比如视频监控中寻找一个或多个嫌疑犯;无人驾驶时需要识别路上的车辆、行人、红绿灯以及路障等等很多目标,对这些都是需要及时去掌握画面中的不同目标,我们将这类任务叫做目标检测(object detection)或物体检测。
本人在网上下载了一张“狗与猫”的图片,将狗和猫当作是目标,然后对狗和猫进行标注。我们通常使用边界框(bounding box)来描述目标的位置,一般是一个矩形框。

画边界框(bounding box)
import d2lzh as d2l
from mxnet import contrib,gluon,image,nd
import numpy as np
d2l.set_figsize(figsize=(5, 5))
img=image.imread('dogcat.png').asnumpy()#高、宽、通道数(596, 605, 3)
dog_bbox,cat_bbox=[20,5,330,570],[333,200,590,590]#[Xmin,Ymin,Xmax,Ymax],分别是左上角与右下角的坐标
#画矩形框的辅助函数
#d2l包中已有
def bbox_to_rect(bbox,color):
return d2l.plt.Rectangle(xy=(bbox[0],bbox[1]),width=bbox[2]-bbox[0],height=bbox[3]-bbox[1],fill=False,edgecolor=color,linewidth=1)
fig=d2l.plt.imshow(img)
fig.axes.add_patch(bbox_to_rect(dog_bbox,'blue'))
fig.axes.add_patch(bbox_to_rect(cat_bbox,'red'))
d2l.plt.show() 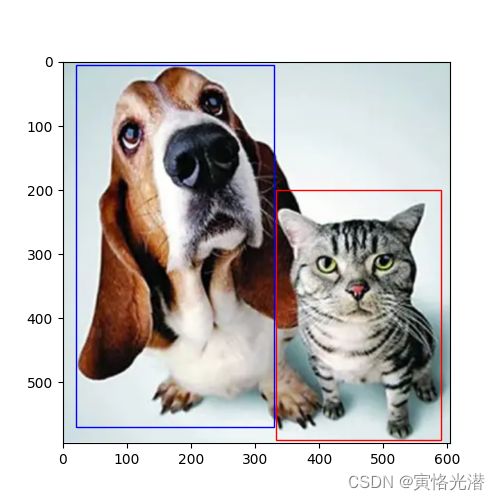
对于上面画目标的矩形框,有两个方法需要熟悉下,如下:
1、d2l.plt.Rectangle的用法
d2l.plt.Rectangle(xy=(400,30),width=100,height=150,fill=True,edgecolor='green',linewidth=2)
这个函数的作用是画矩形框,通过坐标与宽高。
xy=(400,30):左上角的坐标,有了左上角坐标,然后就可以开始画了,横向往右画宽度,纵向向下画高度
fill=True或False:表示是否填充
edgecolor='green':边框的颜色
linewidth=2:画笔的大小
2、fig.axes.add_patch的用法
将上面画好的矩形框,添加到画布上面,从字面意思来看,就相当于是在画布中加一块补丁
fig.axes.add_patch(d2l.plt.Rectangle(xy=(20,50),width=100,height=150,fill=True,edgecolor='green',linewidth=2))我们看下出来的效果图,猫上面一块补丁哈哈

目标检测算法通常会在输入图像中采样大量的区域,然后判断这些区域中是否包含我们感兴趣的目标,并调整区域边缘从而更准确地预测目标的真实边界框(ground-truth bounding box)。不同模型使用的区域采样方法可能不同,这里介绍一种方法:以每个像素为中心生成多个大小(scales)和宽高比(aspect ration)不同的边界框,这些边界框我们叫做锚框(anchor box)
画锚框(anchor box)
import d2lzh as d2l
from mxnet import contrib, gluon, image, nd
import numpy as np
d2l.set_figsize(figsize=(8, 8))
img = image.imread('dogcat.png').asnumpy() # 高、宽、通道数(596, 605, 3)
h, w = img.shape[0:2]
X = nd.random.uniform(shape=(1, 3, h, w))
# 生成锚框的方法
Y = contrib.nd.MultiBoxPrior(X, sizes=[0.75, 0.5, 0.25], ratios=[1, 1.2, 0.65])
# (批量大小,锚框个数,4)
print(596*605*5, Y.shape) # 1802900 (1, 1802900, 4)
boxes = Y.reshape((h, w, 5, 4))
print(boxes.shape) # (596, 605, 5, 4)
# 画出某个像素为中心的所有锚框
# d2lzh包中已有
def show_bboxes(axes, bboxes, labels=None, colors=None):
def _make_list(obj, default_values=None):
if obj is None:
obj = default_values
elif not isinstance(obj, (list, tuple)):
obj = [obj]
return obj
labels = _make_list(labels)
colors = _make_list(colors, ['b', 'g', 'r', 'm', 'w'])
for i, bbox in enumerate(bboxes):
color = colors[i % len(colors)]
rect = d2l.bbox_to_rect(bbox.asnumpy(), color)
axes.add_patch(rect)
if labels and len(labels) > i:
text_color = 'r' if color == 'w' else 'w'
axes.text(rect.xy[0], rect.xy[1], labels[i], va='center', ha='center',
fontsize=9, color=text_color, bbox=dict(facecolor=color, lw=0))
bbox_scale = nd.array((w, h, w, h)) # 用来还原坐标值
fig = d2l.plt.imshow(img)
show_bboxes(fig.axes, boxes[300, 250, :, :]*bbox_scale, ['s=0.75,r=1','s=0.5,r=1', 's=0.25,r=1', 's=0.75,r=1.2', 's=0.75,r=0.65'])
d2l.plt.show()
其中的每个像素为中心产生的锚框数为5,这个5是怎么来的呢?
boxes=Y.reshape((h,w,5,4))如果是按照每个像素都画锚框的话,那就会产生h*w*sizes*ratios个锚框,计算复杂度容易过高。我们通常只需要包含sizes第一个元素或ratios第一个元素之间的组合即可
sizes=[0.75,0.5,0.25],ratios=[1,1.2,0.65] 会有六种组合:[0.75,1],[0.75,1.2],[0.75,0.65]以及[0.75,1],[0.5,1],[0.25,1],其中[0.75,1]重复了,所以就是5,也就是生成的锚框数公式为:sizes+ratios-1(这里的sizes和ratios指的是元素个数)
标注训练集的锚框
import d2lzh as d2l
from mxnet import contrib, gluon, image, nd
import numpy as np
d2l.set_figsize(figsize=(8, 8))
img = image.imread('dogcat.png').asnumpy() # 高、宽、通道数(596, 605, 3)
h, w = img.shape[0:2]
X = nd.random.uniform(shape=(1, 3, h, w))
# 生成锚框的方法
Y = contrib.nd.MultiBoxPrior(X, sizes=[0.75, 0.5, 0.25], ratios=[1, 1.2, 0.65])
boxes = Y.reshape((h, w, 5, 4))
# 画出某个像素为中心的所有锚框
# d2lzh包中已有
def show_bboxes(axes, bboxes, labels=None, colors=None):
def _make_list(obj, default_values=None):
if obj is None:
obj = default_values
elif not isinstance(obj, (list, tuple)):
obj = [obj]
return obj
labels = _make_list(labels)
colors = _make_list(colors, ['b', 'g', 'r', 'm', 'w'])
for i, bbox in enumerate(bboxes):
color = colors[i % len(colors)]
rect = d2l.bbox_to_rect(bbox.asnumpy(), color)
axes.add_patch(rect)
if labels and len(labels) > i:
text_color = 'r' if color == 'w' else 'w'
axes.text(rect.xy[0], rect.xy[1], labels[i], va='center', ha='center',
fontsize=9, color=text_color, bbox=dict(facecolor=color, lw=0))
ground_truth = nd.array([[0, 0.05, 0.02, 0.55, 0.95], [1, 0.56, 0.37, 0.97, 0.97]])
anchors = nd.array([[0, 0.1, 0.2, 0.3], [0.15, 0.2, 0.4, 0.4],
[0.63, 0.05, 0.88, 0.98], [0.66, 0.45, 0.8, 0.8], [0.57, 0.3, 0.92, 0.9]])
bbox_scale = nd.array((w, h, w, h)) # 用来还原坐标值
fig = d2l.plt.imshow(img)
#真实边界框
show_bboxes(fig.axes, ground_truth[:,1:]*bbox_scale, ['dog','cat'],'k')
#MultiBoxTarget函数为锚框标注类别和偏移量,形状(批量大小,包括背景的类别数,锚框数)
labels=contrib.nd.MultiBoxTarget(anchors.expand_dims(axis=0),ground_truth.expand_dims(axis=0),nd.zeros((1,3,5)))
print(labels[2][0][0],len(labels[2][0]))
tnames=[]
for i in labels[2][0]:
if i==0:
tnames.append('background')
elif i==1:
tnames.append('dog')
else:
tnames.append('cat')
print(tnames)#['background', 'dog', 'background', 'background', 'cat']
#锚框
show_bboxes(fig.axes,anchors*bbox_scale,tnames)
d2l.plt.show() 其中MultiBoxTarget函数是为锚框标注类别和偏移量的,形状(批量大小,包括背景的类别数,锚框数)
其中MultiBoxTarget函数是为锚框标注类别和偏移量的,形状(批量大小,包括背景的类别数,锚框数)
labels=contrib.nd.MultiBoxTarget(anchors.expand_dims(axis=0),ground_truth.expand_dims(axis=0),nd.zeros((1,3,5)))
print(labels)
'''
[
[[0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00 1.0000002e+00
9.2499981e+00 3.4657359e+00 7.6843362e+00 0.0000000e+00 0.0000000e+00
0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00
0.0000000e+00 5.7142794e-01 1.1666666e+00 7.9111999e-01 5.9604639e-07]]
,
[[0. 0. 0. 0. 1. 1. 1. 1. 0. 0. 0. 0. 0. 0. 0. 0. 1. 1. 1. 1.]]
,
[[0. 1. 0. 0. 2.]]
]
''' labels[0]:锚框的4个偏移量,其中负类锚框的偏移量为0
labels[1]:掩码变量,形状(批量大小,锚框个数*4),掩码变量中的元素跟每个锚框的4个偏移量一一对应。由于我们不关心对背景的检测,有关负类的偏移量不应影响目标函数。通过按元素乘法,掩码变量中的0可以在计算目标函数之前过滤掉负类的偏移量。
labels[2]:锚框标注的类别,0为背景,并令从0开始的目标类别的整数索引自加1(1狗2猫)
其中expand_dims表示增加一维,位置取决于axis指定的维度
print(anchors.expand_dims(axis=0).shape)#就从(5,4)变成了(1,5,4)
预测边界框(非极大值抑制)
上面的介绍,我们知道在模型预测阶段,将先为图像生成多个锚框,并为这些锚框一一预测类别和偏移量,当锚框数量较多时,同一目标可能会输出较多相似的预测边界框,为了使结果更简洁,我们移除相似的预测边界框,常用方法就是非极大值抑制(non-maximum suppression,NMS)
为了简单起见,我们假设预测偏移量全是0,预测边界框即锚框,最后,构造每个类别的预测概率:
import d2lzh as d2l
from mxnet import contrib, gluon, image, nd
import numpy as np
d2l.set_figsize(figsize=(8, 8))
img = image.imread('dogcat.png').asnumpy() # 高、宽、通道数(596, 605, 3)
h, w = img.shape[0:2]
anchors = nd.array([[0.05, 0.02, 0.55, 0.95], [0.06, 0.1, 0.56, 0.95], [0.15, 0.22, 0.64, 0.95], [0.56, 0.37, 0.97, 0.97]])#四个锚框
offset_preds = nd.array([0]*anchors.size)# 偏移量
cls_prods = nd.array([[0]*4, [0.94, 0.8, 0.75, 0.04],[0.06, 0.2, 0.25, 0.96]]) # 分别是背景、狗、猫的预测概率
bbox_scale = nd.array((w, h, w, h)) # 用来还原坐标值
fig = d2l.plt.imshow(img)
d2l.show_bboxes(fig.axes, anchors*bbox_scale,['dog=0.94', 'dog=0.8', 'dog=0.75', 'cat=0.96'])
d2l.plt.show() 图中标注了每个框的预测概率,然后我们使用MultiBoxDetection函数来执行非极大值抑制并设置阈值为0.5,这样就会让结果显得更加简洁。代码如下:
图中标注了每个框的预测概率,然后我们使用MultiBoxDetection函数来执行非极大值抑制并设置阈值为0.5,这样就会让结果显得更加简洁。代码如下:
output=contrib.nd.MultiBoxDetection(cls_prods.expand_dims(axis=0),offset_preds.expand_dims(axis=0),anchors.expand_dims(axis=0),nms_threshold=0.5)
print(output)
[[[ 1. 0.96 0.55999994 0.37 0.97 0.97 ]
[ 0. 0.94 0.05000001 0.01999998 0.55 0.95 ]
[-1. 0.8 0.06 0.09999999 0.56 0.9499999 ]
[-1. 0.75 0.14999999 0.21999997 0.64 0.95 ]]]
我们可以看到[返回结果的形状是(批量大小,锚框的数量,6)。 最内层维度中的六个元素提供了同一预测边界框的输出信息。
第一个元素是预测的类索引,从0开始(0代表狗,1代表猫),值-1表示背景或在非极大值抑制中被移除了。
第二个元素是预测的边界框的置信度。
其余四个元素分别是预测边界框左上角和右下角的 (x,y)(x,y) 轴坐标(范围介于0和1之间)。
最后将背景为-1的移除掉:
for i in output[0].asnumpy():
if i[0]==-1:
continue
label=('dog=','cat=')[int(i[0])]+str(i[1])
d2l.show_bboxes(fig.axes,[nd.array(i[2:])*bbox_scale],label) 实践中,在执行非极大值抑制前,我们甚至可以将置信度较低的预测边界框移除,从而减少此算法中的计算量。 我们也可以对非极大值抑制的输出结果进行后处理。例如,只保留置信度更高的结果作为最终输出。
实践中,在执行非极大值抑制前,我们甚至可以将置信度较低的预测边界框移除,从而减少此算法中的计算量。 我们也可以对非极大值抑制的输出结果进行后处理。例如,只保留置信度更高的结果作为最终输出。
错误出现:
如果那个MultiBoxDetection函数里面不增加一维的话,将会报错:
Check failed: cshape.ndim() == 3U (2 vs. 3) : Provided: [3,4]
维度不匹配了,所以需要对类别预测、偏移量、锚框都做一个维度扩展:expand_dims(axis=0)