智能计算系统实验(2) 实时风格迁移在线推理与离线部署
2.1 模型量化
执行量化脚本python fppb_to_intpb.py udnie_int8.ini。量化过程主要对卷积算子进行量化。
2.2 在线推理
2.2.1 CPU原始模型
通过已有的run_ori_pb函数可以发现,主要任务是向图中的输入节点填入图像,在获取输出节点的结果。将这个任务做完后直接运行会报错,提示PowerDifference_z节点没有数据。所以将udnie_power_diff模型转换成TF Events文件,用Tensorboard打开可以看到(图2-1),PowerDifference_z节点是一个Placeholder,没有Inputs节点。然后完成代码,将该位置填2.0即可。
代码2-1 CPU版run_ori_power_diff_pb函数(部分)
with tf.compat.v1.Session(config=config) as sess:
# 完成PowerDifference Pb模型的推理
sess.graph.as_default()
sess.run(tf.compat.v1.global_variables_initializer())
input_tensor = sess.graph.get_tensor_by_name('X_content:0')
pow_tensor = sess.graph.get_tensor_by_name('moments_15/PowerDifference_z:0')
output_tensor = sess.graph.get_tensor_by_name('add_37:0')
start_time = time.time()
ret = sess.run(output_tensor, feed_dict={input_tensor:[X], pow_tensor:2.0})
end_time = time.time()
print("C++ inference(CPU) time is: ",end_time-start_time)
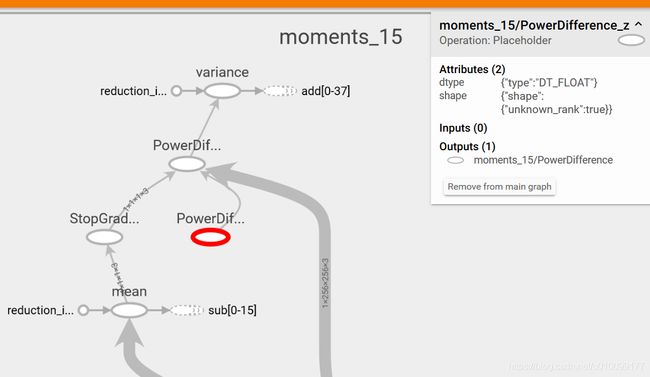
图2-1 udnie_power_diff模型(部分)
2.2.2 CPU模型与Numpy
首先只向输入节点填入图像,运行后会提示PowerDifference节点没有数据。然后用TensorBoard显示模型,会发现PowerDifference模型没有输入数据。所以可以推测出来,需要用Numpy计算PowerDifference的值,并填进去。任务确定之后,就要找被计算的数据。从上面的模型可以发现,需要取出Conv2D_13和StopGradient的值。

图2-2 udnie_power_diff_numpy模型(部分)
任务和数据都明确之后就可以写代码了。首先只运行图的一部分:输入图像,取出Conv2D_13和StopGradient。然后再次运行完整的图,输入图像和计算后的PowerDifference,取出运行结果add_37。用Numpy计算PowerDifference的过程是,直接将两个Tensor相减,然后平方。
代码2-2 CPU版run_numpy_pb(部分)
with tf.compat.v1.Session(config=config) as sess:
# 完成Numpy版本 Pb模型的推理
sess.graph.as_default()
sess.run(tf.compat.v1.global_variables_initializer())
start_time = time.time()
input_tensor = sess.graph.get_tensor_by_name('X_content:0')
conv2d_13 = sess.graph.get_tensor_by_name('Conv2D_13:0')
stop_gradient = sess.graph.get_tensor_by_name('moments_15/StopGradient:0')
[ret1, ret2]=sess.run([conv2d_13, stop_gradient], feed_dict={input_tensor:[X]})
pd_result_tensor=sess.graph.get_tensor_by_name('moments_15/PowerDifference:0')
output_tensor = sess.graph.get_tensor_by_name('add_37:0')
ret = sess.run(output_tensor,
feed_dict={input_tensor:[X], pd_result_tensor:(ret1-ret2)**2})
end_time = time.time()
print("Numpy inference(CPU) time is: ",end_time-start_time)
2.2.3 CPU模型运行结果
执行source run.sh,得到运行结果。使用os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'屏蔽Log信息。可以看出,图像基本没有差别。

图2-3 CPU模型的运行过程

图2-4 CPU模型的运行结果
2.2.4 MLU模型与运行结果
MLU要完成的两个模型与CPU要完成的两个模型大部分修改是一样的,唯一的区别是,后者要完成MLU Config配置。既然要改配置,就要了解有哪些配置可以改。Python的dir函数可以列出对象的所有成员。所以通过在run_ori_power_diff_pb函数中添加一行代码print(dir(config.mlu_options))会列出所有的选项,然后就发现save_offline_model最有可能是要修改的配置,因为本实验的下一步要使用离线模型。
运行结果如下。可以看出生成的三张图片差别不大,但是由于INT8的精度损失,与CPU模型相比,图片的对比度增加了。
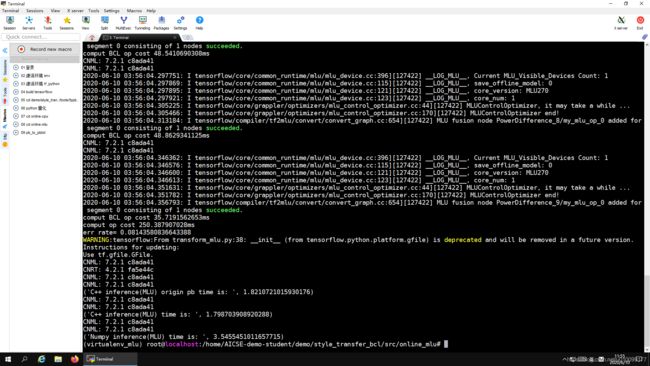
图2-5 MLU模型的运行过程
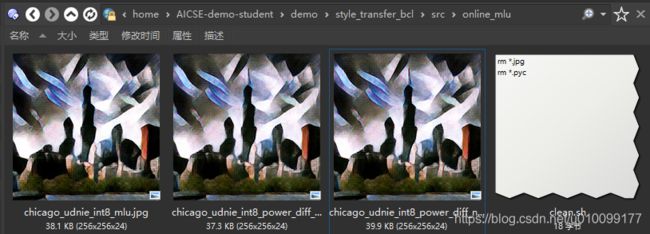
图2-6 MLU模型的运行结果
2.3 离线推理
2.3.1 代码修改
这一部分需要补全inference.cpp,整体架构参考文档“离线模型示例程序”。需要进行的改动如下。
(1) 模型路径。主要是根据DataT->model_name拼接出模型的完整路径。
代码2-3 加载模型
cnrtModel_t model;
char fname[100] = "/home/AICSE-demo-student/demo/style_transfer_bcl/models/offline_models/";
strcat(fname, DataT->model_name.c_str());
strcat(fname, ".cambricon");
printf("file_path\t%s\n", fname);
cnrtLoadModel(&model, fname);
(2) 获得函数名。刚开始我以为DataT->model_name就是函数名,不过在运行的时候发现,inputNum和outputNum都不能正常获取,所以我怀疑函数名写错了。根据之前PB模型可以转成文本文件的经验,我推测离线模型也能转成文本文件。然后打开离线模型的存放目录(图2-7),发现cambricon文件大小是5.38M,应该模型的主要文件,同时还有一个配对的cambricon_twins文件,只有不到1KB,所以推测这个小文件应该是可以用文本编辑器打开的。打开之后发现里面写着“Name: subnet0”、“Data type: CNRT_FLOAT16”、“Dim Order: CNRT_NHWC”等信息,并且两个cambricon_twins文件的name都是一样的。

图2-7 离线模型文件夹
代码2-4 提取函数
cnrtFunction_t function;
cnrtCreateFunction(&function);
cnrtExtractFunction(&function, model, "subnet0");
(3) 输入数据处理。OpenCV采用的格式NCHW,也就是通道在前,而cambricon_twins中要求输入数据是NHWC格式,即通道在后。所以需要通过cnrtReshapeNCHWToNHWC对数据格式进行修改。为了进行这个修改,必须再单独建一个缓冲区,也就是下面代码中的uint16_t *input_half。同时还需要将单精度浮点数转换成半精度浮点数。然后将数据拷贝到设备内存中。
代码2-8 输入数据处理
// prepare input buffer
uint16_t *input_half; // NCWH格式的中间变量
for (int i = 0; i < inputNum; i++)
{
// converts data format when using new interface model
inputCpuPtrS[i] = (uint16_t *)malloc(inputSizeS[i] * 1);
// malloc cpu memory
input_half = (uint16_t *)malloc(inputSizeS[i] * 1);
int length = inputSizeS[i] / 2;
for (int j = 0; j < length; j++)
cnrtConvertFloatToHalf(input_half + j, DataT->input_data[j]);
cnrtReshapeNCHWToNHWC(inputCpuPtrS[i], input_half, 1, 256, 256, 3,
cnrtDataType_t(0x12 /*FLOAT16*/));
// malloc mlu memory
cnrtMalloc(&(inputMluPtrS[i]), inputSizeS[i]);
cnrtMemcpy(inputMluPtrS[i], inputCpuPtrS[i], inputSizeS[i],
CNRT_MEM_TRANS_DIR_HOST2DEV);
}
......
free(input_half);
(4) 输出数据处理。输入数据和输出数据的处理是类似的,只是要把NHWC转成NCHW,以便OpenCV进行处理。
代码2-9 输出数据处理
// prepare output buffer
float *output_temp;
for (int i = 0; i < outputNum; i++)
output_temp = new float[256 * 256 * 3];
......
for (int i = 0; i < outputNum; i++)
{
// copy to cpu
cnrtMemcpy(outputCpuPtrS[i], outputMluPtrS[i], outputSizeS[i],
CNRT_MEM_TRANS_DIR_DEV2HOST);
// convert to float
int length = outputSizeS[i] / 2;
uint16_t *outputCpu = ((uint16_t **)outputCpuPtrS)[0];
DataT->output_data = new float[256 * 256 * 3];
for (int j = 0; j < length; j++)
cnrtConvertHalfToFloat(output_temp + j, outputCpu[j]);
cnrtReshapeNHWCToNCHW(DataT->output_data, output_temp, 1, 256, 256, 3,
cnrtDataType_t(0x13 /*FLOAT32*/));
}
......
delete output_temp;
(5) 计时。因为评分标准要求计时,所以添加了计时的函数。
代码2-10 计时语句
std::cout << "The run time is: "
<<(double)clock() / CLOCKS_PER_SEC
<< "s"
<< std::endl;
2.3.2 运行结果
图2-8是模型的运行结果,图片是正常的。图2-9是模型的运行过程截图,在离线模型中,不用PowerDifference算子消耗183.595毫秒,使用PowerDifference算子消耗174.008毫秒;而MLU在线模型中,不用PowerDifference算子的消耗1821.072毫秒,使用PowerDifference算子消耗1798.704毫秒(图2-5)。

图2-8 离线模型运行结果

图2-9 离线模型运行过程