多智能体强化学习思路整理
多智能体强化学习算法思路整理
目录
- 摘要
- 背景和意义
-
- 研究背景
-
- 强化学习
- 多智能体强化学习与博弈论基础
- 研究意义
- 问题与挑战
-
- 问题分类
- 问题分析
-
- 环境的不稳定性与可扩展性的平衡
- 部分可观测的马尔可夫决策过程
- 研究现状
-
- 基于值函数的方法
-
- Q-Learning, DQN & DRQN
- VDN (Value-Decomposition Network)
- QMIX
- QTRAN
- 基于策略的方法
-
- Policy Gradient
- Actor-Critic
- TRPO & PPO
- MAPPO
- HATRPO & HAPPO
- 多智能体强化学习的应用
- 参考文献
摘要
本篇将首先简要地介绍多智能体强化学习(Multi-agent Reinforcement Learning, MARL)的相关理论基础,包括问题的定义、问题的建模,以及涉及到的核心思想和概念等。然后,简要阐述解决各类多智能体问题的经典算法。最后,对目前多智能体强化学习技术的应用进行总结。
背景和意义
研究背景
强化学习
人工智能领域的主要目标之一是产生与环境相互作用的完全自主的智能体,以学习最佳行为,并通过反复试验不断改进。在强化学习领域,待解决的问题通常被描述为马尔科夫决策过程(Markov Decision Process, MDP)。 一个典型的马尔科夫决策过程通常有以下几个部分组成:
- 一组状态 S S S,以及初始状态p的分布 p ( S 0 ) p(S_0) p(S0)
- 一组行动A 转移概率 T ( s t + 1 ∣ s t , a t ) T(s_{t+1}|s_t,a_t) T(st+1∣st,at),其将时间t处的状态State和动作Action对映射到时间t+1处的状态分布。
- 奖励函数 R ( s t + 1 , s t , a t ) R\left(s_{t+1},s_t,a_t\right) R(st+1,st,at)折损系数 γ ∈ [ 0 , 1 ] \gamma\in[0,1] γ∈[0,1],其中较低的值更强调即时奖励。
强化学习的基本框架如图1所示。在强化学习设置中,由机器学习算法控制的智能体Agent在时间t处从其环境观察状态 s t s_t st。智能体通过在状态 s t s_t st处采取动作 a t a_t at来与环境进行交互。基于已选择的动作 a t a_t at和当前状态 s t s_t st,环境会转移成为状态 s t + 1 s_{t+1} st+1并生成奖励 r t + 1 r_{t+1} rt+1。在这个过程中,智能体将会学习策略 π \pi π来产生最佳的行动以获得最大的累积奖励。
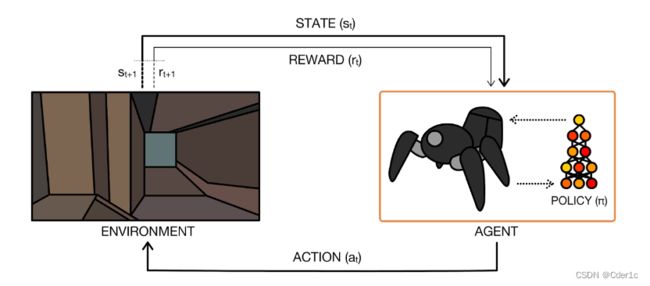
通常,策略 π \pi π是一个从状态空间到动作空间上的概率分布的映射 π : S → p ( A = a ∣ S ) \pi:S\rightarrow p(Α=a|S) π:S→p(A=a∣S)。如果一个马尔科夫决策过程的长度是一整个事件(episode),即在长度为T的每个事件之后都重置状态为原始状态,则事件中的状态、动作和奖励的序列构成策略的序列。每一个序列都通过累积环境返回的奖励,得到总的序列奖励 R = ∑ t = 0 T − 1 γ t r t + 1 R=\sum_{t=0}^{T-1}{\gamma^tr_{t+1}} R=∑t=0T−1γtrt+1。强化学习的最终目的,是学习到一个最佳的策略 π ∗ \pi\ast π∗,使得可以在任何状态下都得到期望的最大奖励回报,即:
![]()
多智能体强化学习与博弈论基础
随着强化学习在多个应用领域取得了令人瞩目的成果,并且考虑到在现实场景中通常会同时存在多个决策个体(智能体),部分研究者逐渐将眼光从单智能体领域延伸到多智能体。单个智能体与单个环境交互的强化学习被称之为单智能体强化学习。当同时存在多个智能体与环境交互时,整个系统就变成一个多智能体系统。其中,每个智能体仍然是遵循着强化学习的目标,也就是是最大化能够获得的累积回报,而此时环境全局状态的改变和所有智能体的联合动作(Joint Action)相关。与单智能体相比,多智能体系统中每个智能体的性能不只取决于自身的策略和环境的反馈,同时还受到其他智能体行为的影响。

如图2所示,当马尔科夫决策过程拓展到多智能体系统,被定义为马尔科夫博弈(又称为随机博弈,Markov Stochastic Game)。我们可以通过博弈论的相关理论,对多智能体强化学习问题进行建模,并找到求解问题的方法。
在一个马尔科夫博弈中,所有智能体根据当前的环境状态,或者是环境观测值来同时选择并执行各自的动作,该各自动作带来的联合动作影响了环境状态的转移和更新,并决定了智能体获得的奖励反馈。一般来讲,它可以通过元组 < S , T , γ , A 1 , A 2 , … , A n , R 1 , R 2 , … , R n >

同时,对于一个马尔科夫博弈,博弈论中的概念——纳什均衡(Nash Equilibrium)十分重要。在通用的博弈框架下,每个玩家只考虑自身期望收益的最大化,无需考虑他人或者整体的收益。均衡则描述了多人博弈过程的一种稳态,反映了玩家理性的概念。
纳什均衡是在多个智能体的动作合集中达成的一个最优点,对于其中任意一个智能体来说,无法通过采取其他的策略来获得更高的累积回报,使用数学形式,多智能体环境下纳什均衡可以表达为:
![]()
均衡求解方法是多智能体强化学习的基本方法,它对于多智能体学习的问题,结合了强化学习的经典方法(如 Q-learning)和博弈论中的均衡概念,通过强化学习的方法来求解该均衡目标,从而完成多智能体的相关任务。
研究意义
自20世纪50年代著名的达特茅斯会议首次提出人工智能的概念以来,人工智能就在不断的发展,目前已经从运算智能、感知智能向认知智能迈进。深度强化学习 (Deep Reinforcement Learning, DRL)技术,将强化学习(Reinforcement Learning, RL)和深度学习(Deep Learning, DL)结合,成为了解决众多决策难题的关键技术,将人工智能向前推进了一大步。
多智能体系统之间广泛存在的合作和非合作对抗博弈关系,是描述现实世界个体与个体、系统与系统之间复杂关系的重要手段。与深度强化学习结合后形成的多智能体强化学习,成为当前人工智能领域最为火热的方向之一,形成了多学科交叉的热门研究领域,受到数学、经济学、金融学、计算机科学、国际关系、军事战略和其他众多学科研究者的重视。现有多智能体对抗博弈理论与方法研究在虚拟游戏场景取得了丰富且瞩目的研究突破,如在棋类和即时策略游戏上挑战并战胜人类顶尖玩家,推动了相关博弈理论、学习算法、高性能计算等领域的蓬勃发展。
问题与挑战
问题分类
相比于单智能体系统,强化学习应用在多智能体系统中,遇到了很多问题与挑战,主要可以分为以下几类[3]:
-
环境的不稳定性
智能体在做决策的同时,其他智能体也在采取动作。因此环境状态的变化与所有智能体的联合动作相关。由于同时学习的其他智能体的策略不断变化,因此在多智能体系统中,环境本质上是非静态的。 算法的收敛性质是在静态环境(大多数单智能体环境)中可以保证的,但不适用于非静态环境,因为在非静态环境中马尔可夫性质不成立。同时,在非静态环境中学习也意味着,过去收集的数据是基于其他智能体过去策略的环境的。因此,会影响所有使用经验回放区(Replay Buffer)以从过去数据中学习的算法的性能。 -
可拓展性
在较小多智能体系统中接受培训的智能体可能很难将他们的策略推广到较大的多智能体系统。在大规模的多智能体系统中,会涉及到高维度的状态空间和动作空间,对于模型表达能力和真实场景中的硬件算力有很高的要求。可扩展性在现实世界中都是至关重要的,因为在现实世界中机器人被部署在不同规模的任务上是很常见的,而由于团队规模的变化,机器人重新训练的成本很高。 -
智能体获取信息的局限性
单个智能体,不一定能够获得全局的信息,可能仅能获取局部的观测信息,且无法得知其他智能体的观测信息、动作和奖励等信息。智能体可能会被共享奖励所迷惑,而总体奖励往往取决于智能体在其感知范围之外的行动。这个问题在现实世界的应用中更加突出,因为机器人传感器的成本和特性会在很大程度上限制机器人可获得的信息。 -
智能体的目标一致性
各智能体的目标可能是最优的全局回报,也可能是各自局部回报的最优。
问题分析
环境的不稳定性与可扩展性的平衡
大多数算法都面临着环境的不稳定性和可扩展性之间的权衡。而多智能体强化学习算法大致上可以分为两类,中心式学习(centralized Learning)和分散式(Independent Learning)。
中心式的思想是考虑一个合作式的环境,直接将单智能体算法扩展,让其直接学习一个联合动作的输出,但是并不好给出单个智能体该如何进行决策。环境的不稳定性可以通过中心式学习来缓解,但中心式学习面临着可扩展性挑战,比如,随着智能体数目的增长,呈指数级增长的状态和动作空间以及中心化信息的高昂成本。
分散式是每个智能体独立学习自己的奖励函数,对于每个智能体来说,其它智能体就是环境的一部分,因此往往需要去考虑环境的非平稳态。分散式学习可以较轻松的扩大系统规模。但随着系统中加入更多的智能体,分散式学习面临着更严重的环境不稳定问题。而且,分散式学习到的并不是全局的策略。
中心化训练去中心化执行方法(Centralized Training with Decentralized Execution, CTDE)方法相当好地平衡了这两个性质。中心化训练去中心化执行方法在训练时构建关于全局状态信息针对联合值函数的集中式评价器,在执行时智能体保持关于局部观测输入的分布式策略,是目前多智能体强化学习最为常用的算法框架。然而,中心化训练去中心化执行方法依然存在相当的问题,例如极大的网络可能很难优化。同时,这种框架也带来了环境的非平稳性以及信誉分配等问题,为此研究者们提出了各种值函数分解的方式来解决这些问题。
在三种学习方法中,基于中心化训练去中心化执行的算法最有潜力通过结合参数共享等技术来得到更优性能的。
部分可观测的马尔可夫决策过程
马尔可夫性质在现实世界环境下很少成立。部分可观测的马尔可夫决策过程(Partially Observable Markov Decision Process, POMDP)通过明确定义多智能体系统中的智能体接收的信息只是环境及系统状态的部分是可观测的,有效的地保留了许多现实世界环境的动态特性。 在部分可观测的马尔可夫决策过程中,可以将多智能体系统描述为元组 < S , A , P , R , Ω , O , n , γ >
研究现状
目前,解决强化学习问题的方法主要有两大方向:基于值函数的方法(Value-based)和基于策略搜索的方法(Policy-based)。在考虑多智能体问题时,主要的方式是在值函数的定义或者是策略的定义中引入多智能体的相关因素,并设计相应的网络结构作为值函数模型和策略模型,最终训练得到的模型能够适应(直接或者是潜在地学习到智能体相互之间的复杂关系),在具体任务上获得不错的效果。
基于值函数的方法
Q-Learning, DQN & DRQN
Q-Learning[4]是一种无模型的off-policy算法,用于估计从给定的状态执行行动的长期预期回报。这些估计奖励被称为 Q Q Q值,通过将当前 Q Q Q值估计更新为所观察到的奖励加上在结果状态s中的所有动作 a ′ a\prime a′中的最大 Q Q Q值,迭代地学习 Q Q Q值:
![]()
为了解决在更复杂的环境如Atari游戏中的状态与动作空间问题,在DQN[5]算法中,模型被定义成一个由权值和偏差参数表示的神经网络,记为 θ \theta θ。DQN中不再是更新各个 Q Q Q值,而是更新网络参数 θ \theta θ以最小化损失函数:

同时,为了解决环境的部分可观测性,提出了DRQN[6]方法。即在最小化改变DQN网络的前提下,在DQN网络中加入LSTM层以允许Q网络更好地估计真实环境状态,缩小 Q ( o , a ∣ θ ) Q(o,a|\theta) Q(o,a∣θ)和 Q ( s , a ∣ θ ) Q(s,a|\theta) Q(s,a∣θ)之间的差距。DRQN的网络如图3所示。

VDN (Value-Decomposition Network)
在合作式多智能体强化学习问题中,每个智能体基于自己的局部观测做出反应来选择动作,来最大化团队奖励。对于一些简单的合作式多智能体问题,可以用中心式训练的方法来解决,将状态空间和动作空间做一个拼接,从而将问题转换成一个单智能体的问题。而在多智能体强化学习的任务中,遇到了如下几个问题:
- “懒惰”智能体问题
在中心式训练的框架下,某些智能体在其中滥竽充数,比如,当一个智能体学习了一个有用的策略,但第二个智能体不愿意学习时,就会发生这种情况,因为第二个智能体的探索会阻碍第一个智能体的学习,并导致更差的团队奖励。 - 虚假奖励问题
智能体可能会收到来自其队友行为的虚假奖励信号。比如,当一个智能体发现了一个较差的策略,但是由于其他智能体学习到了好的策略导致团队奖励变好了。那么在第一个智能体看来,就会去学习较差的策略。 - 环境的非稳定性问题
对于每个智能体来说,其它智能体都是环境的一部分,在训练过程中,其他智能体的策略在不断变化,因此对于单个智能体来讲,环境是非平稳态的。
于是,为了解决上述的三个问题,提出了VDN[7]的方法。在VDN中,提出了一种通过反向传播将团队的奖励信号分解到各个智能体上的方法,即:

整个团队的联合动作值函数 Q t o t Q_{tot} Qtot可以被加性的分解为各个智能体的只依赖于每个智能体的局部观察值函数 Q i ~ \widetilde{Q_i} Qi 。尽管学习需要中心化,但是学习过的智能体可以独立优化。每个智能体基于贪婪算法执行其局部值 Q i ~ ( h i , a i ) \widetilde{Q_i}\left(h^i,a^i\right) Qi (hi,ai),相当于一个中央控制器通过最大化 ∑ i = 1 d Q i ~ ( h i , a i ) \sum_{i=1}^{d}{\widetilde{Q_i}\left(h^i,a^i\right)} ∑i=1dQi (hi,ai)来选择联合动作。
图4阐释了一个简单的双智能体系统下的VDN框架。单智能体各自的观察随着时间的推移进入两个智能体的网络,经过线性层(linear layer)到递归层(recurrent layer),然后通过dueling层产生单独的 Q i ~ \widetilde{Q_i} Qi ,这些值被加到一个联合 Q t o t Q_{tot} Qtot用于训练,而智能体各自的行动是由各自的网络独立生成的。
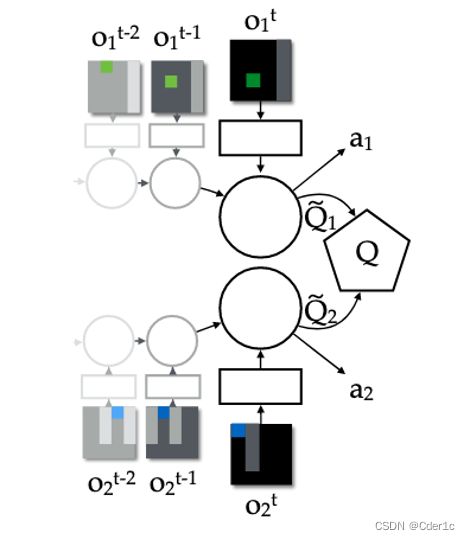
QMIX
在VDN网络中,得到了联合动作的值 Q t o t Q_{tot} Qtot之后,就可以直接取能够获取最大的所对应的联合动作。这种方式能够实现中心式学习,但是得到分布式策略。但是,通过将 Q t o t Q_{tot} Qtot加性的分解为一系列单独的值函数 Q i ~ \widetilde{Q_i} Qi 的线性之和,而且 Q i ~ \widetilde{Q_i} Qi 的计算仅仅依靠单智能体的观察和动作。因此,VDN限制了中心化训练的动作值函数的复杂性,并忽略了训练过程中可用的任何额外的状态信息。
为了解决上述问题,在QMIX[8]算法中,提出了一种通过更复杂的非线性方式合成的 Q t o t Q_{tot} Qtot网络。与VDN的核心原理相同,QMIX方法提出对全局值函数做argmax与对单个智能体地值函数做argmax能够得到相同的结果:

这样的话,每个智能体 Q i Q_i Qi都可以基于以贪婪策略选择动作。由于每个智能体都采用贪婪策略,因此这个算法是off-policy的算法,并且样本的利用率会比较高。在VDN中采用的是线性加权,因此上述等式会成立,而如果是采用一个神经网络来学习融合各个智能体的函数的话,上述等式未必成立。为了保证值函数的单调性来使得上述等式能够成立,QMIX对联合动作值函数 Q t o t Q_{tot} Qtot和单个智能体动作值函数 Q i Q_i Qi之间做了一个单调性约束:


QMIX具体的网络结构如图5所示。QMIX网络主要由三部分构成:
- 代表单智能体的价值函数的网络 Q a ( τ a , u a ) Q_a\left(\tau^a,u^a\right) Qa(τa,ua),单个智能体的网络结构采用DRQN的网络结构,在每个时间步,接收当前的独立观测 o t a 和 上 一 个 动 作 u t − 1 a o_t^a和上一个动作u_{t-1}^a ota和上一个动作ut−1a,如图中的 ( c ) (c) (c)所示。
- 一个全连接网络(mixing network),接收每个智能体 Q a ( τ a , u a ) Q_a\left(\tau^a,u^a\right) Qa(τa,ua)的输出作为输入,输出联合动作值函数 Q t o t ( τ , u ) Q_{tot}(\tau,u) Qtot(τ,u)。网络对每个智能体的动作值函数做非线性映射,并且保证单调性约束。如图中的 ( a ) (a) (a)所示。
- 一个超参数网络(hypernetworks),用来产生全连接网络。超参数网络输入状态,输出全连接网络的每一层的超参数向量。
QMIX的训练方式是端到端的训练:

其中表示从经验池中采样的样本数量,DQN的目标由 y t o t = r + γ m a x u ′ ( τ ′ , u ′ , s ′ ; θ − ) y^{tot}=r+\gamma{max}_{u^\prime}\left(\tau^\prime,u^\prime,s^\prime;\theta^-\right) ytot=r+γmaxu′(τ′,u′,s′;θ−)给出, θ − \theta^- θ−为目标网络参数。
在QMIX算法中,单纯考虑前向传播的话,智能体之间其实是没有配合的,因为算法仅仅是取每个智能体能够获得的最大的值函数。但是,对于单个智能体来说,它的最优动作是基于队友智能体的动作下得到的,在基于单个智能体的动作值函数下得到联合动作值函数的过程中,也就是在全连接网络中有考虑整体的状态,所以相当于是在考虑全局的信息下去得到一个联合动作值函数。
使用QMIX表示的值函数类包括任何值函数,这些值函数可以在完全可观察的设置中分解为个体值函数的非线性单调组合,即满足:
![]()
但是在分散式部分可观察马尔可夫决策过程(Decentralized partially observable Markov decision process, Dec-POMDP)中,每个智能体的观测都不是完整的状态,因此它们可能无法根据局部观测来区分真实的状态,即:
![]()
QTRAN
VDN和QMIX是值分解领域的两大标杆性文章,并且在一般的工程项目实践上VDN和QMIX的效果都很不错。这两个方法其实就是在保证联合动作取argmax的时候能够是对各个智能体的值函数取argmax。VDN中采用的是线性求和的方式,QMIX中采用的是保证单调性。对于一些任务,比如像联合动作的最优就是各个智能体的单独的最优的值函数,这样的问题可以采用这种方式,对于不是这类型的问题,这种限制太强,导致模型不匹配。因此,QTRAN[9]提出了一种新的值分解的算法。
在QTRAN中,定义了IGM条件 (Individual-Global-Max):对于一个联合动作值函数 Q j t : T N × U N → R Q_{jt}:\mathcal{T}^N\times\mathcal{U}^N\rightarrow\mathcal{R} Qjt:TN×UN→R,其中 τ ∈ T N \tau\in\mathcal{T}^N τ∈TN为一个联合动作观测的历史轨迹。如果对于独立的智能体存在一个动作值函数 [ Q i : T × U → R ] i = 1 N [Qi:T×U→R]_{i=1}^{N} [Qi:T×U→R]i=1N,满足如下关系式的话:

就称在轨迹 τ \tau τ下, [ Q i ] [Q_i] [Qi]对 Q j t Q_{jt} Qjt满足IGM条件。 Q j t ( τ , u ) Q_{jt}\left(\tau,u\right) Qjt(τ,u)是能够被 Q i ( τ i , u i ) Q_i\left(\tau^i,u^i\right) Qi(τi,ui)分解的, [ Q i ] [Q_i] [Qi]是 Q j t Q_{jt} Qjt的分解因子。
当满足IGM条件时,存在一个仿射函数 ϕ ( Q ) = A Q + B \phi\left(Q\right)=AQ+B ϕ(Q)=AQ+B对 Q Q Q进行一个映射,其中 A A A为一个对角矩阵,且 a i i > 0 a_{ii}>0 aii>0。本质上看与VDN的分解方法很相似,但QTRAN进行了缩放,并增加了一个修正项,即:
![]()
并定义:

QTRAN的网络结构如图6所示。网络结构中主要有三部分:
- 单智能体独立的动作值网络 Q i ( τ i , u i ) Q_i(\tau_i,u_i) Qi(τi,ui)。对于每个动作值网络,输入是他自己的动作观测历史 τ i \tau_i τi,输出动作值函数 Q i ( τ i , ⋅ ) Q_i(\tau_i,·) Qi(τi,⋅)。各个子智能体的动作值函数累加得到。每个智能体单独决定自己的行动。
- 联合动作值网络 Q j t ( τ , u ) Q_{jt}(\tau,u) Qjt(τ,u)。它将单智能体所选动作作为输入,并将所选动作的 Q Q Q值作为输出。如图6所示,网络的前面几层参数是共享的,用所有的独立智能体的动作值函数向量来采样样本,更新联合动作值函数。
- 状态值网络 V j t ( τ ) V_{jt}(\tau) Vjt(τ)。状态值函数类似dueling网络,并且这里可以引入全局的状态信息,它是独立于动作轨迹的,但是可以用来辅助动作值函数的训练,计算 Q ′ j t ( τ , u ) {Q\prime}_{jt}(\tau,u) Q′jt(τ,u)和 Q j t ( τ , u ) Q_{jt}(\tau,u) Qjt(τ,u)的差异。
此时损失函数可以表达成如下形式:
![]()
其中, r r r是选取动作 u u u后观测历史从 τ \tau τ变成 τ ′ \tau\prime τ′的奖励; L t d L_{td} Ltd是 Q j t ( τ , u ) Q_{jt}(\tau,u) Qjt(τ,u)的损失函数; L o p t L_{opt} Lopt和 L n o p t L_{nopt} Lnopt是 Q ′ j t ( τ , u ) {Q\prime}_{jt}(\tau,u) Q′jt(τ,u)的损失函数,且:

第一个 L t d L_{td} Ltd用来近似最优的联合动作值函数,下面两个 L o p t L_{opt} Lopt和 L n o p t L_{nopt} Lnopt用来满足可分解值函数地充分必要条件。

基于策略的方法
Policy Gradient
Policy Gradient[11]方法的工作原理是计算策略梯度的估计,并使用随机梯度上升算法。它通过观测信息选出一个行为直接进行反向传播,利用奖励直接对选择行为的可能性进行增强和减弱,好的行为会被增加下一次被选中的概率,不好的行为会被减弱下次被选中的概率。最常用的策略梯度估计的形式为:
![]()
其中, π θ \pi_\theta πθ是随机选择策略, A ^ t {\hat{A}}_t A^t是在 t t t时刻对价值函数的估计。
Actor-Critic
策略梯度算法主要包括策略模型以及值函数两个部分。在学习策略的基础上额外学习值函数是有意义的,因为值函数可以辅助策略更新,例如在策略梯度算法中利用值函数来进行方差缩减,而这也是Actor-Critic算法[12]在做的事情。Actor-Critic模型由两个模型组成,可以选择是否共享参数:
- Critic更新值函数的参数w并且根据算法的不同值函数可以为动作-值 Q w ( a | s ) Q_w\left(a\middle|s\right) Qw(a∣s)或者状态-值 V w ( s ) V_w(s) Vw(s)
- Actor根据Critic“建议”的方向更新策略 π θ ( a ∣ s ) \pi_\theta(a|s) πθ(a∣s)参数 θ \theta θ
Policy Gradient算法以及上述简单版本的Actor-Critic算法都是在线(On-policy)的,即训练样本是通过目标策略(target policy)收集的。然而离线(Off-policy)方法[13]拥有以下额外的优势:
3. 离线方法不需要完整的轨迹样本并且可以复用任何历史轨迹的样本。即使用经验回放(Replay buffer),从而具有更高效的使用样本。
4. 训练样本根据行为策略(behavior policy)而不是目标策略收集而来,给算法带来更好的探索性。 离线的方法使用了重要性采样定理,得以使用给定根据行为策略采样得到的动作产生的训练样本:

要求f(x)的期望,其中x服从p(x)分布,即目标策略,我们可以通过变换,x从另外一个分布q(x),即行为策略中采样,这时通过给f(x)乘上一个重要性权重 p ( x ) q ( x ) \frac{p(x)}{q(x)} q(x)p(x),就可以得到对目标策略的评估。
TRPO & PPO
在离线的方法中,使用了重要性采样去使用行为策略的结果去训练目标策略。如果采样的行为策略分布与真实的目标策略分布差得很多,那么肯定会导致两个期望不一致。为了提升训练的稳定性,我们应该避免更新一步就使得策略发生剧烈变化的参数更新。TRPO(Trust region policy optimization)[14]方法通过在每次迭代时对策略更新的幅度强制施加KL散度约束来解决这个问题,即强制旧策略与新策略之间的KL散度小于某个参数 δ \delta δ:
![]()
而TRPO的函数为:

鉴于TRPO相对复杂但是我们仍然想要去实现一个类似的约束,PPO(proximal policy optimization)[15]方法通过使用一个截断的替代目标函数来简化TRPO,同时实现了相似的性能。定义:

则有:
![]()
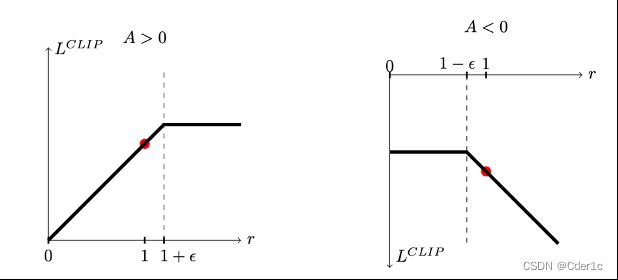
而PPO方法使用如图7所示的CLIP函数,使得 r ( θ ) r(\theta) r(θ)保持在1附近的邻域中,即 [ 1 − ε , 1 + ε ] [1-\varepsilon,1+\varepsilon] [1−ε,1+ε]。即:
![]()
MAPPO
MAPPO(Multi Agent PPO)方法[16]是PPO算法应用于多智能体任务的变种,同样采用Actor-Critic架构,不同之处在于此时Critic学习的是一个中心价值函数(Centralized Value Function),即此时Critic能够观测到全局信息(Global State),包括其他智能体的信息和环境的信息。
HATRPO & HAPPO
在MAPPO中,每个智能体都遵循自己的梯度,策略提督能告诉智能体可以怎样来改善联合性能。在单智能体中,置信域(Trust Region)学习可以实现更新和策略改进的稳定性;在第 k k k次迭代时,新策略 π k + 1 \pi_{k+1} πk+1都会增加收益,即:
![]()
但是,当所有智能体各自尝试做同样的事情时,联合更新可能会让结果适得其反。因此,为了做出对整个团队有益的决策,智能体必须协作。因此,提出了HATRPO和HAPPO[17]方法,实现了智能体间的合作,使得联合策略能够提升。
在HATRPO和HAPPO中,对于任意有序的智能体子集 i 1 : m = ( i 1 , i 2 , . . . , i m ) i_{1:m}=(i_1,i_2,...,i_m) i1:m=(i1,i2,...,im),多智能体系统的状态动作值函数定义如下:
![]()
Q π ( s , a i 1 : m ) Q_\pi(s,a^{i_{1:m}}) Qπ(s,ai1:m)表示在智能体子集 i 1 : m i_{1:m} i1:m采取联合行动 a i 1 : m a^{i_{1:m}} ai1:m的情况下的期望奖励回报。进一步,定义多智能体系统的优势函数:
![]()
该函数将表示在智能体子集 i 1 : m i_{1:m} i1:m采取联合行动 a i 1 : m a^{i_{1:m}} ai1:m的期望奖励回报与表示在智能体子集 j 1 : k j_{1:k} j1:k采取联合行动 j 1 : k j_{1:k} j1:k的期望奖励回报进行了比较。基于此,HAPPO提出了多智能体系统优势函数的分解定理:

整个多智能体系统的优化方向,即梯度方向,可以被分解为每个智能体i_j基于智能体子集 i 1 : j − 1 i_{1:j-1} i1:j−1的联合行动 a i 1 : j − 1 a^{i_{1:j-1}} ai1:j−1,选择自己的最佳行动 a i j , ∗ a^{i_j,\ast} aij,∗,且满足 A π i j ( s , a i 1 : j − 1 , a i j , ∗ ) > 0 A_\pi^{i_j}(s,a^{i_{1:j-1}},a^{i_j,\ast})>0 Aπij(s,ai1:j−1,aij,∗)>0。再进一步,在已有联合策略 π = ( π 1 , π 2 , . . . , π n ) \pi=(\pi^1,\pi^2,...,\pi^n) π=(π1,π2,...,πn)且按照一定顺序 i 1 : n i_{1:n} i1:n进行学习时,假设已经更新到新的策略:
![]()
对于候选策略 π ^ i m {\hat{\pi}}^{i_m} π^im,有:
![]()
基于此,并使用重要性采样,有HATRPO的目标函数:

其中:

同时,有HAPPO的目标函数:

多智能体强化学习的应用
游戏与人工智能技术一直有着非常紧密的关系。自电子游戏诞生之后,人工智能研究者就把电子游戏作为测试人工智能算法的一个理想的环境。原因之一是很多电子游戏,尤其是棋牌类的游戏,都是被明确化的规则定义的。同时,面向虚拟环境的游戏平台因具有安全、快速、低成本、可复现以及对抗性等特点,是人工智能领域在多智能体对抗博弈研究方面的重要验证及测试平台。
根据决策行为的执行方式不同,虚拟游戏可以大致划分为轮流决策的回合制游戏和同步 决策的即时制游戏两种类型。
大多数棋牌类游戏属于典型的回合制游戏,而以深度强化学习和博弈树搜索为代表的智能决策方法,比如完全信息环境下的围棋(AlphaGo[18]与 AlphaGo Zero[19]),以及在非完全信息环境下的德州扑克 (Pluribus[20]),都取得了备受瞩目的成果。例如,AlphaGo[18]结合了深度强化学习的方法:
- 针对巨大状态空间的问题,使用网络结构CNN来提取和表示状态信息;
- 在训练的第一个阶段,使用人类玩家的数据进行有监督训练,得到预训练的网络;
- 在训练的第二个阶段,通过强化学习方法和自我博弈进一步更新网络;
- 在实际参与游戏时,结合价值网络和策略网络,使用蒙特卡洛树搜索(MCTS)方法得到真正执行的动作。 而另一种类型——即时制游戏,比如星际争霸,DOTA,王者荣耀,吃鸡等。
相比于前面提到的国际象棋、围棋等回合制类型的游戏,游戏AI训练的难度更大,不仅因为游戏时长更长、对于未来预期回报的估计涉及到的步数更多,还包括了多方同时参与游戏时造成的复杂空间维度增大,在一些游戏设定中可能无法获取完整的信息以及全局的形势,在考虑队内合作的同时也要考虑对外的竞争。突出的研究成果包括王者荣耀(绝悟[21])、星际争霸II (AlphaStar[22])均已达到甚至超越人类顶尖职业玩家水平。
在虚拟游戏领域之外,真实的工业应用场景涉及到更加复杂和不确定的多域多个体的博弈对抗,多智能体强化学习的技术发展前景广阔。尽管在虚拟游戏上取得了革命性的进展,但是由于虚拟环境与现实环境存在巨大差异,包括理想与真实的系统模型的差异、封闭与开放的测试环境的影响等,虚拟游戏上取得成功的技术方案目前仍然很难直接应用在实际物理系统上,目前仍有大量的问题等待解决。
参考文献
[1]. Arulkumaran, K., Deisenroth, M. P., Brundage, M., & Bharath, A. A. (2017). A brief survey of deep reinforcement learning. arXiv preprint arXiv:1708.05866.
[2]. Zhang, K., Yang, Z., & Başar, T. (2021). Multi-agent reinforcement learning: A selective overview of theories and algorithms. Handbook of Reinforcement Learning and Control, 321-384.
[3]. Wang, Y., Damani, M., Wang, P., Cao, Y., & Sartoretti, G. (2022). Distributed Reinforcement Learning for Robot Teams: A Review. arXiv preprint arXiv:2204.03516.
[4]. Watkins, C. J., & Dayan, P. (1992). Q-learning. Machine learning, 8(3), 279-292.
[5]. Mnih, V., Kavukcuoglu, K., Silver, D., Rusu, A. A., Veness, J., Bellemare, M. G., … & Hassabis, D. (2015). Human-level control through deep reinforcement learning. nature, 518(7540), 529-533.
[6]. Hausknecht, M., & Stone, P. (2015, September). Deep recurrent q-learning for partially observable mdps. In 2015 aaai fall symposium series.
[7]. Sunehag, P., Lever, G., Gruslys, A., Czarnecki, W. M., Zambaldi, V., Jaderberg, M., … & Graepel, T. (2017). Value-decomposition networks for cooperative multi-agent learning. arXiv preprint arXiv:1706.05296.
[8]. Rashid, T., Samvelyan, M., Schroeder, C., Farquhar, G., Foerster, J., & Whiteson, S. (2018, July). Qmix: Monotonic value function factorisation for deep multi-agent reinforcement learning. In International conference on machine learning (pp. 4295-4304). PMLR.
[9]. Son, K., Kim, D., Kang, W. J., Hostallero, D. E., & Yi, Y. (2019, May). Qtran: Learning to factorize with transformation for cooperative multi-agent reinforcement learning. In International conference on machine learning (pp. 5887-5896). PMLR.
[10]. Sutton, R. S., McAllester, D., Singh, S., & Mansour, Y. (1999). Policy gradient methods for reinforcement learning with function approximation. Advances in neural information processing systems, 12.
[11]. Sutton, R. S., McAllester, D., Singh, S., & Mansour, Y. (1999). Policy gradient methods for reinforcement learning with function approximation. Advances in neural information processing systems, 12.
[12]. Barto, A. G., Sutton, R. S., & Anderson, C. W. (1983). Neuronlike adaptive elements that can solve difficult learning control problems. IEEE transactions on systems, man, and cybernetics, (5), 834-846.
[13]. Munos, R., Stepleton, T., Harutyunyan, A., & Bellemare, M. (2016). Safe and efficient off-policy reinforcement learning. Advances in neural information processing systems, 29.
[14]. Schulman, J., Levine, S., Abbeel, P., Jordan, M., & Moritz, P. (2015, June). Trust region policy optimization. In International conference on machine learning (pp. 1889-1897). PMLR.
[15]. Schulman, J., Wolski, F., Dhariwal, P., Radford, A., & Klimov, O. (2017). Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347.
[16]. Yu, C., Velu, A., Vinitsky, E., Wang, Y., Bayen, A., & Wu, Y. (2021). The surprising effectiveness of ppo in cooperative, multi-agent games. arXiv preprint arXiv:2103.01955.
[17]. Kuba, J. G., Chen, R., Wen, M., Wen, Y., Sun, F., Wang, J., & Yang, Y. (2021). Trust region policy optimisation in multi-agent reinforcement learning. arXiv preprint arXiv:2109.11251.
[18]. Silver, D., Huang, A., Maddison, C. J., Guez, A., Sifre, L., Van Den Driessche, G., … & Hassabis, D. (2016). Mastering the game of Go with deep neural networks and tree search. nature, 529(7587), 484-489.
[19]. Silver, D., Schrittwieser, J., Simonyan, K., Antonoglou, I., Huang, A., Guez, A., … & Hassabis, D. (2017). Mastering the game of go without human knowledge. nature, 550(7676), 354-359.
[20]. Brown, N., & Sandholm, T. (2019). Superhuman AI for multiplayer poker. Science, 365(6456), 885-890.
[21]. Ye, D., Liu, Z., Sun, M., Shi, B., Zhao, P., Wu, H., … & Huang, L. (2020, April). Mastering complex control in moba games with deep reinforcement learning. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 34, No. 04, pp. 6672-6679).
[22]. Vinyals, O., Babuschkin, I., Czarnecki, W. M., Mathieu, M., Dudzik, A., Chung, J., … & Silver, D. (2019). Grandmaster level in StarCraft II using multi-agent reinforcement learning. Nature, 575(7782), 350-354.