图像分割任务数据集处理
图像分割任务数据集处理
-
-
- 1.分割任务的输入输出
-
- 1.1 模型的输入输出shape
- 1.2 数据集中的标签图像处理
- 2.Pytroch Dataloader与Dataset
- 3.图像分割任务常用数据增强
-
1.分割任务的输入输出
1.1 模型的输入输出shape
对于分类任务来说,模型的输入通常是BCHW的,其中:
- B是batch_szie;
- C是输入图像的通道数,一般为3;
- H就是图像的高;
- W是图像的宽。
而输出一般就是一个维度为类别数量的分布向量,其中每一个元素为这个张图片属于对应类别的概率。
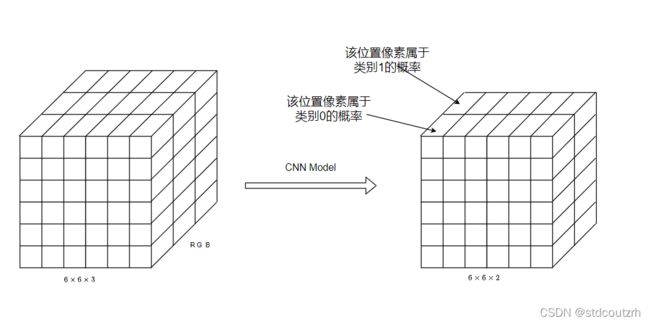
而对于分割任务来说,模型的输入是跟分类任务一样的,但是输出是有区别的。对于一个shape为CHW的输入图片,其输出是一个num_classes H W的张量,如下图,假设输入为6x6x3,其中3表示RGB三通道,类别数为2,则输出为6x6x2,其中2表示该位置像素点分别属于两个类的概率。
1.2 数据集中的标签图像处理
对于数据集给到的输入图像,一般是输入图片是RGB三通道的,这个一般读取图片后不用在去调整。
对于标签图片的处理主要包含两个方面:
- 一般数据集给出的的标签文件往往是一个单通道的,其中每个位置的值是输入图像上对应位置像素点所属的类别。举个例子,假设是三分类的分割任务,输入图像大小为
3x2x2,则它的标签文件可能就是1x2x2,标签图片每个位置的值就是类别,为了使得在训练时可以进行交叉熵损失函数的计算,需要将标签图片的每个位置的元素进行one-hot编码,从而使得模型的输出shape和标签shape一致。 - 有时候数据集给出的时候,里面的元素并不是0,1这样的类别,而是方便人眼查看的可视化图像,比如2分类的WHU数据集,给出的时候是0和255组成的二值图像,这个时候我们就需要手动将里面的像素值转换为类别值。
2.Pytroch Dataloader与Dataset
PyTorch将数据集的处理过程标准化,对于数据集的处理,PyTorch提供了torch.utils.data.Dataset这个抽象类,在使用时只需要继承该类,并重写__len__()和
__getitem()__方法,即可以方便地进行数据集的迭代。
其中:
__len__()方法返回数据集样本数;__getitem()__中定义获取单个样本的方法,其中可以添加图像预处理方法。
由于文件名只是一个字符串,占用内存较小,因此可以先遍历训练集目录,将所有的图片名存放在内存中的一个列表里,也就是下面代码中的self.image_names,则数据集中样本的数量就是这个列表的长度。
class WHU(Dataset):
def __init__(self, data_root: str, mode: str, mean=(0.43526827, 0.44523223, 0.41307612), std=(0.2043603, 0.19237618, 0.20128716)):
"""
data_path:path of dataset
"""
super(WHU, self).__init__()
assert os.path.exists(data_root), f"path '{data_root}' does not exist."
self.imgs_dir = os.path.join(data_root, "image/") # image path
self.masks_dir = os.path.join(data_root+"mask/") # label path
# save all image names
self.image_names = [file for file in os.listdir(self.imgs_dir)]
print(f'{mode}:Creating dataset with {len(self.image_names)} examples.')
self.label_map = {0: 0, 255: 1}
self.num_classes = 2
self.mean = mean
self.std = std
self.mode = mode
def __len__(self):
return len(self.image_names)
# convert mask from 0 and 255 to 0 and 1
def convert_mask(self, mask, reverse=False):
temp = mask.copy()
if reverse:
for v, k in self.label_map.items():
mask[temp == k] = v
else:
for k, v in self.label_map.items():
mask[temp == k] = v
return mask
def preprocess(self, image, mask):
# mask
mask = self.convert_mask(mask, False) #(512*512,2)
# one-hot to each pixel
mask = np.eye(self.num_classes)[mask.reshape([-1])]
mask = mask.reshape(512, 512, 2) # (512,512,2)
if self.mode == "train":
tfs = [
d.RandomHorizontalFlip(0.5), d.RandomVerticalFlip(0.5),
d.ToTensor(), d.Normalize(self.mean, self.std)
]
else:
tfs = [d.ToTensor(), d.Normalize(self.mean, self.std)]
image, mask = d.Compose(tfs)(image, mask)
return image, mask
def __getitem__(self, index):
# 获取image和mask的路径
image_name = self.image_names[index]
image_path = os.path.join(self.imgs_dir, image_name)
mask_path = os.path.join(self.masks_dir, image_name)
assert os.path.exists(
image_path), f"file '{image_path}' does not exist."
assert os.path.exists(mask_path), f"file '{mask_path}' does not exist."
# 读取image和mask
image = cv2.imread(image_path, 1) # BGR [512,512,3]
mask = cv2.imread(mask_path, 0) # GRAY [512,512]
image, mask = self.preprocess(image, mask)
# After process
# image:[-1, 3, 512, 512]
# mask:[-1, 2, 512, 512]
return image, mask
经过上面的步骤已经可以获取每一个预处理后的样本,但是仍然无法进行批量处理、随机选取等操作,因此还需要torch.utils.data.Dataloader类进一步进行封装,使用方法如下:
from torch.utils.data import DataLoader
dataset = WHU('../datasets/WHU/train/', mode="train")
dataloader = DataLoader(dataset, batch_size=1,shuffle=True, pin_memory=True)
print(len(dataset), len(dataloader))
for (image, label) in dataloader:
print(image.size(), label.size())# torch.Size([1,3,512,512]) torch.Size([1,2,512,512])
break
该类需要4个参数,第1个参数是之前继承了Dataset的实例,第2个参数是批量batch的大小,第3个参数是是否打乱数据参数,第4个参数是使用几个线程来加载数据。
dataloader是一个可迭代对象,对该实例进行迭代即可取出批次的图片和标签,分别作为模型的输入和用于和模型的输出进行损失函数的计算。