《基于Tensorflow的知识图谱实战》 --- CIFAR-10、CIFAR-100数据集解析和可视化
⚽开发平台:jupyter lab
运行环境:python3、tensorflow2.x
第6章 ResNet实现神经网络的飞跃 | CIFAR-10、CIFAR-100数据集解析及可视化
- 1. 数据集获取
- 2.数据及文件目录结构
- 3.数据集存储数据结构
- 4.提取数据
-
- 4.1 提取类别信息
- 4.2 提取图像、标签、文件名
- 5.将图片数组转换为图片
- 6. 可视化每个类别的样本
- 7. 完整代码及其可视化结果
说明:CIFAR-10、CIFAR-100是两个常用的图像分类数据集。
(1)原因:因为其经常被使用,很多库都有该数据集的加载方法,一般直接调用即可直接构造训练、测试数据集。
(2)问题:然而,这两个数据集到底长什么样子,我们如何用自己的方法把它提取出来呢?
(3)该文章目的:今天,就尝试用我们自定义的方法来提取数据集中的图片、标签、文件名等信息,并进行一个可视化。
1. 数据集获取
下载地址:
CIFAR-10:http://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz
CIFAR-100:http://www.cs.toronto.edu/~kriz/cifar-100-python.tar.gz
2.数据及文件目录结构
CIFAR-10以及CIFAR-100均是通过将图片数据拉伸到3072维,然后堆叠起来,与其对应的label和文件名以字典形式存储起来,然后序列化到文件中的。
序列化之后的文件目录结构分别如下所示:

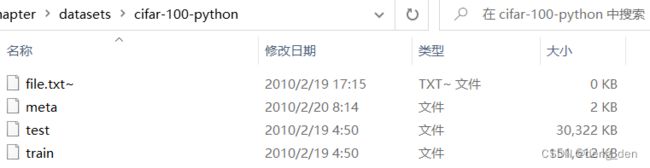
可见:
(1)CIFAR-10是把训练集分为5个batch,测试集单独一个batch;
(2)CIFAR-100是训练集、测试集分别一个batch;batchs.meta、meta分别存储的是CIFAR-100、CIFAR-100的类别数据。
3.数据集存储数据结构
(1)我们可以利用pickle对文件进行反序列化,以查看其数据结构:
import pickle
filename = '../cifar10/cifar-10-batches-py/test_batch'
with open(filename,'rb') as f:
dataset = pickle.load(f, encoding='bytes')
print(type(dataset))
# out: (2)运行上述代码即可打印出数据结构。可以发现是dict类型的,然后即可打印出其keys:
print(dataset.keys())
# out: dict_keys([b'batch_label', b'labels', b'data', b'filenames'])
(3)根据key即可提取相应的数据.
data = dataset[b'data']
labels = dataset[b'labels']
img_names = dataset[b'filenames']
其他的文件类似,可以通过这种方式提取数据结构及其内容。现给出我得到的信息:
- CIFAR-10有10个类别,CIFAR-100有20个大类别、100个小类别;
- 两个数据集的训练、测试集均分别为:50000、10000;
- 图像数据均为拉伸到3072位的数组,需要reshape到33232,3个通道的顺序为:RGB;
4.提取数据
4.1 提取类别信息
def load_labels_name(filename):
"""使用pickle反序列化labels文件,得到存储内容
cifar10的label文件为“batches.meta”,cifar100则为“meta”
反序列化之后得到字典对象,可根据key取出相应内容
"""
with open(filename, 'rb') as f:
obj = pickle.load(f)
return obj
file_name ='./datasets/cifar-10-python/cifar-10-batches-py/batches.meta'
file_data = load_labels_name(file_name)
file_data
- 以该文件为例,使用上述方法提取的信息为:
{'num_cases_per_batch': 10000,
'label_names': ['airplane',
'automobile',
'bird',
'cat',
'deer',
'dog',
'frog',
'horse',
'ship',
'truck'],
'num_vis': 3072}
4.2 提取图像、标签、文件名
def load_data_cifar(filename, mode='cifar10'):
""" load data and labels information from cifar10 and cifar100
cifar10 keys(): dict_keys([b'batch_label', b'labels', b'data', b'filenames'])
cifar100 keys(): dict_keys([b'filenames', b'batch_label', b'fine_labels', b'coarse_labels', b'data'])
"""
with open(filename,'rb') as f:
dataset = pickle.load(f, encoding='bytes')
if mode == 'cifar10':
data = dataset[b'data']
labels = dataset[b'labels']
img_names = dataset[b'filenames']
elif mode == 'cifar100':
data = dataset[b'data']
labels = dataset[b'fine_labels']
img_names = dataset[b'filenames']
else:
print("mode should be in ['cifar10', 'cifar100']")
return None, None, None
return data, labels, img_names
该方法可以提取一个batch文件中的图像、标签、文件名信息并返回。
其中:
(1)返回的data是N*3072维的,每一行代表一张图片;
(2)label为类别标签,如果是CIFAR-100,返回的是数值范围在0~99之间的一个列表,为100类的小类别
(3)可修改“labels = dataset[b’fine_labels’]”这行代码为“labels = dataset[b’coarse_labels’]”来提取大类别。
5.将图片数组转换为图片
- 通过4.2节中的代码,可以提取图像的数据,对该数据进行reshape,可以得到[channel, width, height]格式的数组:
imgs_cifar10_train = data_cifar10_train.reshape(data_cifar10_train.shape[0],3,32,32)
- 对每个这样的数组可分别转换为一张图片:
def to_pil(data):
r = Image.fromarray(data[0])
g = Image.fromarray(data[1])
b = Image.fromarray(data[2])
pil_img = Image.merge('RGB', (r,g,b))
return pil_img
6. 可视化每个类别的样本
### 可视化代码
def random_visualize(imgs, labels, label_names):
figure = plt.figure(figsize=(len(label_names),10))
idxs = list(range(len(imgs)))
np.random.shuffle(idxs)
count = [0]*len(label_names)
for idx in idxs:
label = labels[idx]
if count[label]>=10:
continue
if sum(count)>10 * len(label_names):
break
img = to_pil(imgs[idx])
label_name = label_names[label]
subplot_idx = count[label] * len(label_names) + label + 1
print(label, subplot_idx)
plt.subplot(10,len(label_names), subplot_idx)
plt.imshow(img)
plt.xticks([])
plt.yticks([])
if count[label] == 0:
plt.title(label_name)
count[label] += 1
plt.show()
上述方法中,每个类别随机选取10个样本,按列排列,每一列代表一个类。
可将从两个数据集提取的图片、标签以及对应类别送入其中,即可画出可视化的图片。
7. 完整代码及其可视化结果
# -*- coding: utf-8 -*-
"""
Created on Wed Aug 12 16:23:45 2020
@author: LWS
从cifar10以及cifar100的序列化文件中,提取图片以及标签、文件名等信息
"""
import os
import pickle
#import cv2
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
def load_labels_name(filename):
"""使用pickle反序列化labels文件,得到存储内容
cifar10的label文件为“batches.meta”,cifar100则为“meta”
反序列化之后得到字典对象,可根据key取出相应内容
"""
with open(filename, 'rb') as f:
obj = pickle.load(f)
return obj
def load_data_cifar(filename, mode='cifar10'):
""" load data and labels information from cifar10 and cifar100
cifar10 keys(): dict_keys([b'batch_label', b'labels', b'data', b'filenames'])
cifar100 keys(): dict_keys([b'filenames', b'batch_label', b'fine_labels', b'coarse_labels', b'data'])
"""
with open(filename,'rb') as f:
dataset = pickle.load(f, encoding='bytes')
if mode == 'cifar10':
data = dataset[b'data']
labels = dataset[b'labels']
img_names = dataset[b'filenames']
elif mode == 'cifar100':
data = dataset[b'data']
labels = dataset[b'fine_labels']
img_names = dataset[b'filenames']
else:
print("mode should be in ['cifar10', 'cifar100']")
return None, None, None
return data, labels, img_names
def load_cifar10(cifar10_path, mode = 'train'):
if mode == "train":
data_all = np.empty(shape=[0, 3072],dtype=np.uint8)
labels_all = []
img_names_all = []
for i in range(1,6):
filename = os.path.join(cifar10_path, 'data_batch_'+str(i)).replace('\\','/')
print("Loading {}".format(filename))
data, labels, img_names = load_data_cifar(filename, mode='cifar10')
data_all = np.vstack((data_all, data))
labels_all += labels
img_names_all += img_names
return data_all,labels_all,img_names_all
elif mode == "test":
filename = os.path.join(cifar10_path, 'test_batch').replace('\\','/')
print("Loading {}".format(filename))
return load_data_cifar(filename, mode='cifar10')
def load_cifar100(cifar100_path, mode = 'train'):
if mode == "train":
filename = os.path.join(cifar100_path, 'train')
print("Loading {}".format(filename))
data, labels, img_names = load_data_cifar(filename, mode='cifar100')
elif mode == "test":
filename = os.path.join(cifar100_path, 'test')
print("Loading {}".format(filename))
data, labels, img_names = load_data_cifar(filename, mode='cifar100')
else:
print("mode should be in ['train', 'test']")
return None, None, None
return data, labels, img_names
def to_pil(data):
r = Image.fromarray(data[0])
g = Image.fromarray(data[1])
b = Image.fromarray(data[2])
pil_img = Image.merge('RGB', (r,g,b))
return pil_img
def random_visualize(imgs, labels, label_names):
figure = plt.figure(figsize=(len(label_names),10))
idxs = list(range(len(imgs)))
np.random.shuffle(idxs)
count = [0]*len(label_names)
for idx in idxs:
label = labels[idx]
if count[label]>=10:
continue
if sum(count)>10 * len(label_names):
break
img = to_pil(imgs[idx])
label_name = label_names[label]
subplot_idx = count[label] * len(label_names) + label + 1
print(label, subplot_idx)
plt.subplot(10,len(label_names), subplot_idx)
plt.imshow(img)
plt.xticks([])
plt.yticks([])
if count[label] == 0:
plt.title(label_name)
count[label] += 1
plt.show()
### 主函数
if __name__ == "__main__":
# 修改为你的数据集存放路径
cifar10_path = "../cifar10/cifar-10-batches-py"
cifar100_path = "../cifar100/cifar-100-python"
obj_cifar10 = load_labels_name(os.path.join(cifar10_path, 'batches.meta')) # label_names、num_cases_per_batch、num_vis
obj_cifar100 = load_labels_name(os.path.join(cifar100_path, 'meta')) # coarse_label_names、fine_label_names
# 提取cifar10、cifar100的图片数据、标签、文件名
data_cifar10_train,labels_cifar10_train,img_names_cifar10_train = \
load_cifar10(cifar10_path, mode='train')
data_cifar10_test,labels_cifar10_test,img_names_cifar10_test = \
load_cifar10(cifar10_path, mode='test')
imgs_cifar10_train = data_cifar10_train.reshape(data_cifar10_train.shape[0],3,32,32)
imgs_cifar10_test = data_cifar10_test.reshape(data_cifar10_test.shape[0],3,32,32)
data_cifar100_train,labels_cifar100_train,img_names_cifar100_train = \
load_cifar100(cifar100_path, mode = 'train')
data_cifar100_test,labels_cifar100_test,img_names_cifar100_test = \
load_cifar100(cifar100_path, mode = 'test')
imgs_cifar100_train = data_cifar100_train.reshape(data_cifar100_train.shape[0],3,32,32)
imgs_cifar100_test = data_cifar100_test.reshape(data_cifar100_test.shape[0],3,32,32)
# visualize fro cifar10
label_names_cifar10 = obj_cifar10['label_names']
random_visualize(imgs=imgs_cifar10_train,
labels=labels_cifar10_train,
label_names=label_names_cifar10)
# visualize fro cifar100
label_names_cifar100 = obj_cifar100['fine_label_names']
random_visualize(imgs=imgs_cifar100_train,
labels=labels_cifar100_train,
label_names=label_names_cifar100)
- 可视化结果如下(每类只可视化十个样本):

————————————————
版权声明:本文为CSDN博主「叶舟」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/oYeZhou/article/details/107999081