U-Net: Convolutional Networks for BiomedicalImage Segmentation(含翻译及Github代码实现)
文章题目:U-Net: Convolutional Networks for Biomedical Image Segmentation
发布时间:2015
文章原文:https://arxiv.org/abs/1505.04597
一、问题:
1.网络结构?

网络由压缩路径(contracting path)和扩大路径(expansive path)组成。压缩路径中包含4个blocks,每个block包含2个3*3的valid卷积,stride为1和1个2*2的max-pooling层,stride为2。每向下一个block其通道数都会加倍。扩大路径同样包括了4个blocks,每个block包含了2个3*3valid卷积和1个反卷积,反卷积后feature map的尺寸乘2,通道数减半。需要注意的是,反卷积后得到的图像需要与对应的压缩路径中的图像组合在一起后再进行卷积操作。
2.为什么数据集图片为512*512而输入图片为572*572?
作者为了保留边界的上下文信息,采用了镜像padding的方法。具体做法是将边缘的图像进行镜像对称进行padding,如下图:

那么为何是512->572呢?代表上下左右每一侧都padding了30个pixel,其实根据感受野的计算准则,在压缩路径的最后一个pooling后的像素感受野并非30个pixel,但是可以根据作者的padding30反推计算感受野的位置:30->29->28->14->13->12->6->5->4->2->1->0,也就是说作者根据最后一个pooling前的feature map来计算感受野所推出的30pixel。具体原因不太懂,后续还需要理解。
3.重叠切片(overlap-tile)策略?
通常情况下,医学图像的尺寸较大,而限制于GPU的显存大小,所以我们只能对图片进行切片处理。然而普通的切片会使边缘的信息丢失,所以在需要分割上图黄色框中的图片时,我们需要输入蓝色框大小的图片。如果按照图示的结构分析,即黄色框为512*512,蓝色框为572*572。对大图片进行平移重叠的操作就可以对整个图片进行无缝分割。
4.损失函数中对于细胞边界的识别?
使用了权重特征图,由下列公式可知,离两细胞的边界越近,该点的权重就越大。
![]()
5.数据增强?
应该就是平移旋转和弹性形变。
6.输出图片分辨率为388*388,原图片分辨率为512*512,如何设置loss函数?
存疑......
二、代码实现
代码来源:原作者milesial
数据集下载:Carvana Image Masking (PNG) | Kaggle
ps:针对Windows运行环境进行了部分修改
1.模型搭建部分
model.py
DoubleConv类为双卷积层操作,且每个卷积层后均带有一个BatchNorm和一个ReLU。注意,与论文不同,此处卷积使用了padding,所以上述的问题6也未解决。
Down类为压缩路径的block。
Up类为扩充路径的block,注意扩充操作,先对输入进行反卷积然后再将压缩路径中对应的feature map进行pad后合在一起,而非文章中的将压缩路径中的feature map复制裁剪后合在一起。
OutConv类为1*1的卷积,目的是将64个channel变为num_classes。
UNet类为整体UNet结构。
""" Full assembly of the parts to form the complete network """
import torch
import torch.nn as nn
import torch.nn.functional as F
class DoubleConv(nn.Module):
"""(convolution => [BN] => ReLU) * 2"""
def __init__(self, in_channels, out_channels, mid_channels=None):
super().__init__()
if not mid_channels:
mid_channels = out_channels
self.double_conv = nn.Sequential(
nn.Conv2d(in_channels, mid_channels, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(mid_channels),
nn.ReLU(inplace=True),
nn.Conv2d(mid_channels, out_channels, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
def forward(self, x):
return self.double_conv(x)
class Down(nn.Module):
"""Downscaling with maxpool then double conv"""
def __init__(self, in_channels, out_channels):
super().__init__()
self.maxpool_conv = nn.Sequential(
nn.MaxPool2d(2),
DoubleConv(in_channels, out_channels)
)
def forward(self, x):
return self.maxpool_conv(x)
class Up(nn.Module):
"""Upscaling then double conv"""
def __init__(self, in_channels, out_channels, bilinear=True):
super().__init__()
# if bilinear, use the normal convolutions to reduce the number of channels
if bilinear:
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
self.conv = DoubleConv(in_channels, out_channels, in_channels // 2)
else:
self.up = nn.ConvTranspose2d(in_channels, in_channels // 2, kernel_size=2, stride=2)
self.conv = DoubleConv(in_channels, out_channels)
def forward(self, x1, x2):
x1 = self.up(x1)
# input is CHW
diffY = x2.size()[2] - x1.size()[2]
diffX = x2.size()[3] - x1.size()[3]
x1 = F.pad(x1, [diffX // 2, diffX - diffX // 2,
diffY // 2, diffY - diffY // 2])
# if you have padding issues, see
# https://github.com/HaiyongJiang/U-Net-Pytorch-Unstructured-Buggy/commit/0e854509c2cea854e247a9c615f175f76fbb2e3a
# https://github.com/xiaopeng-liao/Pytorch-UNet/commit/8ebac70e633bac59fc22bb5195e513d5832fb3bd
x = torch.cat([x2, x1], dim=1)
return self.conv(x)
class OutConv(nn.Module):
def __init__(self, in_channels, out_channels):
super(OutConv, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=1)
def forward(self, x):
return self.conv(x)
class UNet(nn.Module):
def __init__(self, n_channels, n_classes, bilinear=False):
super(UNet, self).__init__()
self.n_channels = n_channels
self.n_classes = n_classes
self.bilinear = bilinear
self.inc = DoubleConv(n_channels, 64)
self.down1 = Down(64, 128)
self.down2 = Down(128, 256)
self.down3 = Down(256, 512)
factor = 2 if bilinear else 1
self.down4 = Down(512, 1024 // factor)
self.up1 = Up(1024, 512 // factor, bilinear)
self.up2 = Up(512, 256 // factor, bilinear)
self.up3 = Up(256, 128 // factor, bilinear)
self.up4 = Up(128, 64, bilinear)
self.outc = OutConv(64, n_classes)
def forward(self, x):
x1 = self.inc(x)
x2 = self.down1(x1)
x3 = self.down2(x2)
x4 = self.down3(x3)
x5 = self.down4(x4)
x = self.up1(x5, x4)
x = self.up2(x, x3)
x = self.up3(x, x2)
x = self.up4(x, x1)
logits = self.outc(x)
return logits
2.数据集搭建部分
data_loading.py
import logging
from os import listdir
from os.path import splitext
from pathlib import Path
import numpy as np
import torch
from PIL import Image
from torch.utils.data import Dataset
class BasicDataset(Dataset):
def __init__(self, images_dir: str, masks_dir: str, scale: float = 0.1, mask_suffix: str = ''):
self.images_dir = Path(images_dir)
self.masks_dir = Path(masks_dir)
assert 0 < scale <= 1, 'Scale must be between 0 and 1'
self.scale = scale
self.mask_suffix = mask_suffix
self.ids = [splitext(file)[0] for file in listdir(images_dir) if not file.startswith('.')]
if not self.ids:
raise RuntimeError(f'No input file found in {images_dir}, make sure you put your images there')
logging.info(f'Creating dataset with {len(self.ids)} examples')
def __len__(self):
return len(self.ids)
def preprocess(self,pil_img, scale, is_mask):
w, h = pil_img.size
newW, newH = int(scale * w), int(scale * h)
assert newW > 0 and newH > 0, 'Scale is too small, resized images would have no pixel'
pil_img = pil_img.resize((newW, newH), resample=Image.NEAREST if is_mask else Image.BICUBIC)
img_ndarray = np.asarray(pil_img)
if not is_mask:
if img_ndarray.ndim == 2:
img_ndarray = img_ndarray[np.newaxis, ...]
else:
img_ndarray = img_ndarray.transpose((2, 0, 1))
img_ndarray = img_ndarray / 255
return img_ndarray
def load(filename):
ext = splitext(filename)[1]
if ext == '.npy':
return Image.fromarray(np.load(filename))
elif ext in ['.pt', '.pth']:
return Image.fromarray(torch.load(filename).numpy())
else:
return Image.open(filename)
def __getitem__(self, idx):
name = self.ids[idx]
mask_file = list(self.masks_dir.glob(name + self.mask_suffix + '.*'))
img_file = list(self.images_dir.glob(name + '.*'))
assert len(img_file) == 1, f'Either no image or multiple images found for the ID {name}: {img_file}'
assert len(mask_file) == 1, f'Either no mask or multiple masks found for the ID {name}: {mask_file}'
mask = Image.open(mask_file[0])
img = Image.open(img_file[0])
assert img.size == mask.size, \
f'Image and mask {name} should be the same size, but are {img.size} and {mask.size}'
img = self.preprocess(img, self.scale, is_mask=False)
mask = self.preprocess(mask, self.scale, is_mask=True)
return {
'image': torch.as_tensor(img.copy()).float().contiguous(),
'mask': torch.as_tensor(mask.copy()).long().contiguous()
}
class CarvanaDataset(BasicDataset):
def __init__(self, images_dir, masks_dir, scale=1):
super().__init__(images_dir, masks_dir, scale, mask_suffix='_mask')
3.loss函数部分
dice_score.py
注意,该程序使用的loss综合了CrossEntropy Loss和Dice Loss。
import torch
from torch import Tensor
def dice_coeff(input: Tensor, target: Tensor, reduce_batch_first: bool = False, epsilon=1e-6):
# Average of Dice coefficient for all batches, or for a single mask
assert input.size() == target.size()
if input.dim() == 2 and reduce_batch_first:
raise ValueError(f'Dice: asked to reduce batch but got tensor without batch dimension (shape {input.shape})')
if input.dim() == 2 or reduce_batch_first:
inter = torch.dot(input.reshape(-1), target.reshape(-1))
sets_sum = torch.sum(input) + torch.sum(target)
if sets_sum.item() == 0:
sets_sum = 2 * inter
return (2 * inter + epsilon) / (sets_sum + epsilon)
else:
# compute and average metric for each batch element
dice = 0
for i in range(input.shape[0]):
dice += dice_coeff(input[i, ...], target[i, ...])
return dice / input.shape[0]
def multiclass_dice_coeff(input: Tensor, target: Tensor, reduce_batch_first: bool = False, epsilon=1e-6):
# Average of Dice coefficient for all classes
assert input.size() == target.size()
dice = 0
for channel in range(input.shape[1]):
dice += dice_coeff(input[:, channel, ...], target[:, channel, ...], reduce_batch_first, epsilon)
return dice / input.shape[1]
def dice_loss(input: Tensor, target: Tensor, multiclass: bool = False):
# Dice loss (objective to minimize) between 0 and 1
assert input.size() == target.size()
fn = multiclass_dice_coeff if multiclass else dice_coeff
return 1 - fn(input, target, reduce_batch_first=True)
4.主程序(包含train函数)
train.py
import argparse
import logging
from pathlib import Path
import torch
import torch.nn as nn
import torch.nn.functional as F
import wandb
from torch import optim
from torch.utils.data import DataLoader, random_split
from tqdm import tqdm
from utils.data_loading import BasicDataset, CarvanaDataset
from utils.dice_score import dice_loss
from evaluate import evaluate
from model import UNet
dir_img = Path('E:/数据集/archive/train_images')
dir_mask = Path('E:/数据集/archive/train_masks')
dir_checkpoint = Path('./checkpoints/')
def train_net(net,
device,
epochs: int = 5,
batch_size: int = 1,
learning_rate: float = 1e-5,
val_percent: float = 0.1,
save_checkpoint: bool = True,
img_scale: float = 0.5,
amp: bool = False):
# 1. Create dataset
'''
try:
dataset = CarvanaDataset(dir_img, dir_mask, img_scale)
except (AssertionError, RuntimeError):
dataset = BasicDataset(dir_img, dir_mask, img_scale)
'''
dataset = BasicDataset(dir_img, dir_mask, img_scale)
# 2. Split into train / validation partitions
n_val = int(len(dataset) * val_percent)
n_train = len(dataset) - n_val
train_set, val_set = random_split(dataset, [n_train, n_val], generator=torch.Generator().manual_seed(0))
# 3. Create data loaders
loader_args = dict(batch_size=batch_size, num_workers=0, pin_memory=True)
train_loader = DataLoader(train_set, shuffle=True, **loader_args)
val_loader = DataLoader(val_set, shuffle=False, drop_last=True, **loader_args)
# (Initialize logging)
experiment = wandb.init(project='U-Net', resume='allow', anonymous='must')
experiment.config.update(dict(epochs=epochs, batch_size=batch_size, learning_rate=learning_rate,
val_percent=val_percent, save_checkpoint=save_checkpoint, img_scale=img_scale,
amp=amp))
logging.info(f'''Starting training:
Epochs: {epochs}
Batch size: {batch_size}
Learning rate: {learning_rate}
Training size: {n_train}
Validation size: {n_val}
Checkpoints: {save_checkpoint}
Device: {device.type}
Images scaling: {img_scale}
Mixed Precision: {amp}
''')
# 4. Set up the optimizer, the loss, the learning rate scheduler and the loss scaling for AMP
optimizer = optim.RMSprop(net.parameters(), lr=learning_rate, weight_decay=1e-8, momentum=0.9)
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, 'max', patience=2) # goal: maximize Dice score
grad_scaler = torch.cuda.amp.GradScaler(enabled=amp)
criterion = nn.CrossEntropyLoss()
global_step = 0
# 5. Begin training
for epoch in range(1, epochs+1):
net.train()
epoch_loss = 0
with tqdm(total=n_train, desc=f'Epoch {epoch}/{epochs}', unit='img') as pbar:
for batch in train_loader:
images = batch['image']
true_masks = batch['mask']
assert images.shape[1] == net.n_channels, \
f'Network has been defined with {net.n_channels} input channels, ' \
f'but loaded images have {images.shape[1]} channels. Please check that ' \
'the images are loaded correctly.'
images = images.to(device=device, dtype=torch.float32)
true_masks = true_masks.to(device=device, dtype=torch.long)
with torch.cuda.amp.autocast(enabled=amp):
masks_pred = net(images)
loss = criterion(masks_pred, true_masks) \
+ dice_loss(F.softmax(masks_pred, dim=1).float(),
F.one_hot(true_masks, net.n_classes).permute(0, 3, 1, 2).float(),
multiclass=True)
optimizer.zero_grad(set_to_none=True)
grad_scaler.scale(loss).backward()
grad_scaler.step(optimizer)
grad_scaler.update()
pbar.update(images.shape[0])
global_step += 1
epoch_loss += loss.item()
experiment.log({
'train loss': loss.item(),
'step': global_step,
'epoch': epoch
})
pbar.set_postfix(**{'loss (batch)': loss.item()})
# Evaluation round
division_step = (n_train // (10 * batch_size))
if division_step > 0:
if global_step % division_step == 0:
histograms = {}
for tag, value in net.named_parameters():
tag = tag.replace('/', '.')
histograms['Weights/' + tag] = wandb.Histogram(value.data.cpu())
histograms['Gradients/' + tag] = wandb.Histogram(value.grad.data.cpu())
val_score = evaluate(net, val_loader, device)
scheduler.step(val_score)
logging.info('Validation Dice score: {}'.format(val_score))
experiment.log({
'learning rate': optimizer.param_groups[0]['lr'],
'validation Dice': val_score,
'images': wandb.Image(images[0].cpu()),
'masks': {
'true': wandb.Image(true_masks[0].float().cpu()),
'pred': wandb.Image(masks_pred.argmax(dim=1)[0].float().cpu()),
},
'step': global_step,
'epoch': epoch,
**histograms
})
if save_checkpoint:
Path(dir_checkpoint).mkdir(parents=True, exist_ok=True)
torch.save(net.state_dict(), str(dir_checkpoint / 'checkpoint_epoch{}.pth'.format(epoch)))
logging.info(f'Checkpoint {epoch} saved!')
def get_args():
parser = argparse.ArgumentParser(description='Train the UNet on images and target masks')
parser.add_argument('--epochs', '-e', metavar='E', type=int, default=5, help='Number of epochs')
parser.add_argument('--batch-size', '-b', dest='batch_size', metavar='B', type=int, default=1, help='Batch size')
parser.add_argument('--learning-rate', '-l', metavar='LR', type=float, default=1e-5,
help='Learning rate', dest='lr')
parser.add_argument('--load', '-f', type=str, default=False, help='Load model from a .pth file')
parser.add_argument('--scale', '-s', type=float, default=0.5, help='Downscaling factor of the images')
parser.add_argument('--validation', '-v', dest='val', type=float, default=10.0,
help='Percent of the data that is used as validation (0-100)')
parser.add_argument('--amp', action='store_true', default=False, help='Use mixed precision')
parser.add_argument('--bilinear', action='store_true', default=False, help='Use bilinear upsampling')
parser.add_argument('--classes', '-c', type=int, default=2, help='Number of classes')
return parser.parse_args()
if __name__ == '__main__':
args = get_args()
logging.basicConfig(level=logging.INFO, format='%(levelname)s: %(message)s')
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
logging.info(f'Using device {device}')
# Change here to adapt to your data
# n_channels=3 for RGB images
# n_classes is the number of probabilities you want to get per pixel
net = UNet(n_channels=3, n_classes=args.classes, bilinear=args.bilinear)
logging.info(f'Network:\n'
f'\t{net.n_channels} input channels\n'
f'\t{net.n_classes} output channels (classes)\n'
f'\t{"Bilinear" if net.bilinear else "Transposed conv"} upscaling')
if args.load:
net.load_state_dict(torch.load(args.load, map_location=device))
logging.info(f'Model loaded from {args.load}')
net.to(device=device)
try:
train_net(net=net,
epochs=args.epochs,
batch_size=args.batch_size,
learning_rate=args.lr,
device=device,
img_scale=args.scale,
val_percent=args.val / 100,
amp=args.amp)
except KeyboardInterrupt:
torch.save(net.state_dict(), 'INTERRUPTED.pth')
logging.info('Saved interrupt')
raise三、翻译:
0.摘要 Abstract:
人们普遍认为,成功训练一个深度网络需要数千个标注的训练样本。在本文中,我们提出了通过使用数据增强技术来更加有效地利用带标注样本的网络和训练策略。这个网络包含了一个用来获取上下文的压缩路径(contracting path)和一个实现精确定位的对称的扩大路径(expanding path)。我们已经证明这个网络可以使用非常少的数据进行端到端的训练,而且在电子显微镜堆栈中神经元结构分割的ISBI挑战赛中,它优于之前最先进的方法(滑动窗口卷积网络-a sliding-window convolutional network)。在透射光显微镜图像上使用同种网络,我们以较大的优势赢得了2015年ISBI细胞追踪挑战赛。另外,这个网络非常快。在最新的GPU上面,只需要不到一秒钟便可完成一张512*512像素图像的分割。完整的实现过程(基于 caffe)和训练好的网络可以在链接获得。
1.介绍 Introduction
在过去的两年中,深度卷积网络在许多视觉识别任务中的表现已经比现有技术要更好。虽然卷积网络已经存在了很长时间,但可用训练集和网络的大小限制了它的成功。Krizhevsky等人的巨大突破归功于在100万张训练图片的ImageNet上对具有八个层和数百万个参数的网络进行有监督的训练。此后,更大更深的网络也被训练了出来。
对于卷积神经网络的典型应用是类被识别任务,这种任务的输出是单个的种类标签。然而,以生物图像处理为代表的许多视觉任务所需要的输出还包括了位置信息,也就是应该给每个像素点分配一个类别标签。此外,成千上万的训练图像通常在生物医学任务中是遥不可及的。因此, Ciresan等人提出使用滑动窗口来训练,通过提供预测类型的像素周围一个区域的信息(patches)作为输入。首先,这个网络可以定位像素点位置。第二,一个patches的训练数据远大于训练图像的数量。结果是这个网络在2012年ISBI的EM segmentation challenge以较大的优势赢得了冠军。
显然,Ciresan等人的训练策略有两个不足点。第一,由于这个网络必须为每个patch分别运行,所以它非常的慢,并且由于重叠的patch的存在,它有非常多的冗余计算。第二,这个网络需要在位置精确度和上下文关系的使用之中做折中。越大的patches需要越多的max-pooling层,但是max-pooling层会降低位置信息的精确度,虽然较小的patches会增加位置信息准确的,但是又会使上下文信息减少。许多最近的方法提出了考虑多个层特征的分类器输出。这使得同时拥有好的位置信息和尽可能多地参考上下文信息变得可能。
在本文中,我们构建了一个更加巧妙精致的架构,也即全卷积网络。我们对此网络进行修改和扩充,使它能够通过少量的训练图像产生更加精确的分割。图一是网络架构图。
图一:U-net结构图(以最低分辨率为32*32为例)每个蓝框对应一个多通道特征图。box的顶部是通道数。box左下方是图像的长宽尺寸。白色框表示复制的特征图(feature map)。箭头表示了不同的操作。
全卷积神经网络的中心思想是通过连续的层来补充通常的压缩网络,即使用上采样操作来代替池化操作。因此,这些层提升了输出的分辨率。为了定位像素位置,FCN将从压缩路径中提取出来的高分辨率图像和下采样(unsampled)输出结合了起来。随后基于这个信息,一个连续的卷积层可以得到更加精确的输出。
我们模型的一个很大的改进就是在下采样层同样有较大数目的图像通道(feature channels),这允许我们的网络将上下文信息传递到分辨率更高的层中,并且产生了U型结构。这个网络没有任何全连接层并且它仅使用每个卷积网络的有效部分,也就是说,这些像素点的完整上下文都出现在输入图像中。这一策略通过重叠切片(overlap-tile)法对任意大的图片进行无缝分割(见下图)。
图二:在任意大的图像上的重叠切片策略(这里是对EM stacks中的神经元结构进行分割)。需要输入图像的蓝色框中的图像数据来预测黄色框中的分割。缺少的数据通过镜像(mirroring)进行推断。
在预测图像边界区域的像素时,缺失的上下文信息通过输入图像的镜像操作得到。这种策略在次网络应用到大型图像时非常重要,否则分辨率会被GPU内存所限制。
由于在我们的任务中仅有非常少的训练数据可以使用,我们通过对现有的可用图像施加弹性变形(elastic deformations)来达到过度数据增强的目的。这允许网路学习对这种变形的不变性,而无需在标注的图像库中观察到这些变换。这在生物学分割中尤为重要,因为组织的变形是非常常见的并且计算机可以很逼真地模仿组织的变形。在无监督特征学习中,Dosovitskiy等人已经证明了数据增强对于学习不变性是非常重要的。
在许多细胞分割任务中,另一个挑战便是对于紧挨着的同类物体的分割识别,如下图所示:
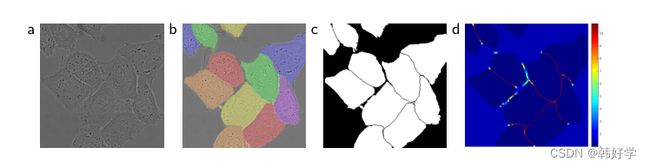 图3:被DIC显微镜记录下来的玻璃片上的HeLa细胞。(a)原图。(b)真实的分割图像。(c)生成的分割掩码。(d)以像素为单位的权重映射,迫使网络学习边界像素
图3:被DIC显微镜记录下来的玻璃片上的HeLa细胞。(a)原图。(b)真实的分割图像。(c)生成的分割掩码。(d)以像素为单位的权重映射,迫使网络学习边界像素
为此,我们使用加权损失来进行训练,在两紧挨着的细胞中间的背景标签的权重在损失函数之中很大。
我们的网络可以解决许多生物学上的分割问题。在本文中,我们展示了在EM stacks中对神经元细胞进行分割的结果,我们网络的表现超过了Ciresan等人搭建的网络。另外,我们还展示了在2015年ISBI 细胞追踪挑战中对于光学显微镜细胞图像的分割结果。在这个挑战赛中,我们在两个最具有挑战性的二维透射光数据集上以较大的优势拿到了冠军。
2.网络结构 Network Architecture
网络结构已经在图1中进行了展现。该网络由压缩路径(contracting path)和扩大路径(expansive path)组成,网络的压缩路径与典型的卷积网络结构相同。压缩路径重复使用了两个3*3卷积(没有padding的卷积),每个卷积层后都跟着一个非线性层(ReLU)和一个stride为2的2*2的max-pooling层,该pooling层起到下采样的作用。在每次下采样的同时,我们让特征通道(feature channels)的数目变为原来的两倍,在扩大路径中每一步首先进行反卷积,每次反卷积都将使图像的特征通道数减半,特征图大小加倍。反卷积完成后,将特征图与压缩路径中对应的特征图结合起来,并紧跟着两个3*3的卷积层,每个卷积层后都有一个ReLU层。由于在每次卷积时边界的像素都会有损失,所以我们很有必要对图像进行裁剪。在最后一层中,我们使用1*1的卷积将每一个64分量的特征向量映射到所需数量的类之中去。
为了无缝拼接输出的分割图像,输入图像的尺寸选择就变得十分重要。我们需要选择适当的输入图像的分辨率以使得每个2*2的max-pooling层都可以作用在双数的长宽尺寸上。
3.训练 Training
我们将输入的图像和他们对应的分割图像在Caffe上使用随机梯度下降的方法进行训练。由于我们的卷积层不还padding操作,输出的图像大小要小于输入图像的大小。为了尽量减少计算开销并且尽可能高效地使用GPU内存,相比于大的batch size我们更喜欢输入大的切片,因此我们设置batch size为1。由此,我们设置了一个很大的momentum(0.99),这样,大量先前训练样本决定了当前步骤中的更新。
损失函数由交叉损失函数和与最终的feature map相比的像素级别的soft-max来计算决定的。soft-max函数定义如下:
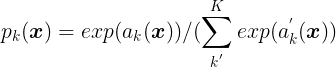
其中,![]() 指在像素位置
指在像素位置![]() ,且在特征通道k中的activation;K为类别的数量;
,且在特征通道k中的activation;K为类别的数量;![]() 为近似最大函数。比如,K具有最大activation的
为近似最大函数。比如,K具有最大activation的![]() 则
则![]() 。
。
交叉熵损失函数:
![]()
其中,![]() 为每个像素的真实标签,
为每个像素的真实标签,![]() 为我们规定的哪些像素在训练过程中更加重要。
为我们规定的哪些像素在训练过程中更加重要。
我们预先计算每个真实的分割图像的权重图,以此来补偿训练数据集中某类像素出现频率不同的缺点,使网络更注重学习相互接触的细胞之间的小的分割边界。
我们使用形态学操作来计算分离边界,特征图的计算公式如下:
![]()
其中![]() 是用来平衡类别频率的权重值,
是用来平衡类别频率的权重值,![]() 是该像素距离最近的细胞边界的距离,
是该像素距离最近的细胞边界的距离,![]() 是该像素到距离第二进的细胞边界的距离。在我们的实验之中,我们设置
是该像素到距离第二进的细胞边界的距离。在我们的实验之中,我们设置![]() ,
,![]() 像素。
像素。
深层网络具有许多层,而且网络之中有许多不同的链接路径,这样一来一个好的权重初始化就变得非常重要。否则,网络中的某些部分可能会被过多的激活而其他部分从未对训练起到作用。理想情况下,初始的权重应该使得网络中的每个特征图都具有近似的单位方差。对于拥有我们的架构的网络,这可以通过从标准差为![]() 的高斯分布中抽取初始权重来实现,其中N表示一个神经元的传入节点数。比如对于一个具有 64个特征通道的3*3的卷积,
的高斯分布中抽取初始权重来实现,其中N表示一个神经元的传入节点数。比如对于一个具有 64个特征通道的3*3的卷积,![]() 。
。
3.1 数据增强 Data Augmentation
当我们能够使用的训练例子很少时,数据增强对于网络所需要的不变性和鲁棒性是必不可少的。对于显微镜下的图像,我们需要他们有平移旋转不变性并且对形变和灰度变化鲁棒。将训练样本进行随机弹性变形,是训练带有很少标注图像的分割网络的关键。我们在一个粗略的3*3网格上使用随机位移产生平滑的变形。位移从高斯分布中取样,便准差为10个像素。然后使用双三次插值计算每个像素的位移。在收缩路径末端的Drop-out层更进一步地对数据进行隐增强。
4.实验 Experiments
我们使用了三个不同的分割任务来展示U-net的应用。第一个任务是电子显微镜下的神经元结构分割。数据集中的一个例子和我们分割的结果已经在上文图2中展示出来了。我们在补充材料中提供了完整的结果。数据集来自于EM分割挑战,此挑战开始于ISBI 2012,并且他现在仍然对新的挑战者开放。训练数据是一组果蝇一龄幼虫的腹神经索的连续切片投射电子显微镜图片,图片共计30张,每张为512*512像素。每张图片都有其对应的注释真实分割图,图中白色表示细胞,黑色表示细胞膜。测试集是公开资料,不过其注释好的真实分割图没有公开。将预测出来的膜概率图发送给组织者便可得到对我们的评价。评估通过在10个不同级别的地图上进行阈值处理和计算“warping error”、“Rand error”和“pixel error”来得到的。U-net网络在不经过更进一步的预处理和后处理的情况下,warping error为0.0003529,rand error为0.0382.我们的U-net在warping error上取得了有史以来的最好成绩,如下表:

这个结果明显好于Ciresan等人提出的滑动窗口卷积网络,他们的网络的warping error为0.000420,rand error为0.0504。就rand error来说,在这个数据集中唯一一个表现比我们好的算法在膜概率图上应用了高度的后处理方法。
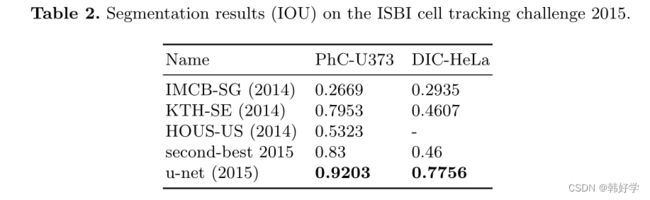
我们也将U-net应用到了光学显微镜下的细胞分割任务。这个细胞分割任务是2014年和2015年的ISBI细胞追踪挑战赛的一部分。第一个“PhC-U373”数据集包含了由相衬显微镜记录下的在聚丙烯酰亚胺基材上的胶质母细胞瘤星形细胞瘤 U373细胞(见图4和补充材料)。它包含了35张部分注释的训练图像。在这个数据集中,我们平均的IOU为92%,这远远好于第二名的83%。第二个“DIC-HeLa”数据集是由微分干涉对比显微镜记录下的在平面玻璃上的HeLa细胞(见图3,图4以及补充材料)。这个数据集包含了20张部分标注的训练图像。在这个数据集中,我们的平均IOU为77.5%,同样远远好于第二名的46%。

5.结论 Conclusion
在不同的生物分割应用之中,我们的U-net都有非常好的表现。由于弹性形变的数据增强方法,我们仅仅需要非常少的标注图像便可对模型进行训练,同时训练时间也非常合理:仅需要在NVidia Titan GPU (6 GB)上训练10个小时。我们提供了基于Caffe的完整实现和已经训练好的网络。我们确信U-net架构可以很轻松的应用在许多其他的任务中。