Python爬虫入门(纯记录)
1、request库入门
1-1 request库的使用
import requests
r = requests.get("http://www.baidu.com")
print(r.status_code) #200是成功 #404失败
r.encoding = 'utf-8'
print(type(r))
#resuests库主要方法
| resuests库主要方法 | 说明 |
|---|---|
| *request(method,url, **kwargs) | 构造一个请求,是以下方法的基础方法 |
| *get(url,params=None, **kwargs) | 获取html信息,相当HTTP的GET(请求URL位置的资源)** |
| head(url,**kwargs) | 获取html头信息,相当HTTP的HEAD**(请求获取URL位置资源的响应信息报告(头部信息))** |
| post(url,data=None, json=None,**kwargs) | 向html提交post请求,相当HTTP的POST(在请求URL位置的资源后添加新的资源)** |
| put(url,data=None,**kwargs) | 向html提交put请求,相当HTTP的PUT 存储并覆盖URL原位置的资源)–全部字段(包括修改和不被修改)提交** |
| patch(url,data=None,kwargs) | 向html提交局部修改请求,相当HTTP的PATCH**(覆盖URL位置的资源)–只提交修改字段** |
| delete(url,**kwargs) | 向html提交删除请求,相当HTTP的DELETE**(删除URL处的资源)** |
request(method,url, **kwargs)
method:请求方式,对应7种方法’GET’,‘HEAD’,‘POST’,‘PUT’,‘PATCH’,‘DELETE’,‘OPTIONS’
kwargs:13个控制访问的参数(以下为可选项)
params:字典或字节序列,作为参数增加到URL中,让服务器能筛选资源
data:字典、字节序或文件对象,均可作为Request内容
json:json格式的数据,作为Request的内容。
headers:字典,HTTP定制头
cookies:字典或CookieJar,Request中的cookie
auth:元组,支持HTTP认证功能
files:字典类型,传输文件
timeout:设定超时时间,秒为单位,超时有timeout异常
proxies:字典类型,设定访问代理服务器,可以增加登录认证
allow_redirects:True/False,默认为True,重定向开关
stream:True/False,默认为False,获取内容立即下载开关
verify:True/False,默认为True,认证SSL证书开关
cert:本地SSL证书路径
1-2 方法使用
get
r= requests.get(url)
#返回一个包含服务器资源的Response对象
#构造一个向服务器请求资源的Request对象
一些小demo
import requests
r = requests.get('https://www.shanghairanking.cn/rankings/bcur/2020')
print(r.status_code) #200
print(r.request.url)
print(r.text)
#https://www.so.com/s?q=Python
# -------------------
import requests
r = requests.get("http://www.baidu.com")
print(r.status_code) #200成功
r.encoding = 'utf-8'
print(r.text)
#-----------------------
import requests
def getHTMLText(url):
try:
r = requests.get(url)
r.raise_for_status()#如果状态不是200,引发HTTPError异常
r.encoding = r.apparent_encoding
return r.text
except:
return "产生异常"
if __name__ == "__main__":
url = "http://www.baidu.com"
print(getHTMLText(url))
post
import requests
#post和put方法类似
payload = {'key1':'value1','key2':'value2'}
#向URL post一个字典,自动编码为form(表单)
r = requests.post("http://httpbin.org/post",data = payload)
print(r.text)
#向URL post一个字符串,自动编码为data
r = requests.post("http://httpbin.org/post",data = "abc")
print(r.text)
来post一个文件吧,乖!
import requests
fs = {'file':open('data.xls','rb')}
r = requests.request('POST','http://python123.io/w',files=fs)
print(r.text)
requests
requests库一些方法的使用
#requests方法parms的实例
import requests
kv = {'key1':'value1','key2':'value2'}
r = requests.request('GET','http://python123.io/ws', params=kv)
print(r.url)
#https://python123.io/ws?key1=value1&key2=value2
#requests方法headers的实例
import requests
hd = {'user-agent':'Chrome/10'}
r = requests.request('POST','http://python123.io/w',headers=hd)
#requests方法files的实例
import requests
fs = {'file':open('data.xls','rb')}
r = requests.request('POST','http://python123.io/w',files=fs)
#requests方法timeout的实例
import requests
r = requests.request('GET','http://baidu.com', timeout=10)
#requests方法proxiest的实例
import requests
pxs = {'http':'http://user:[email protected]:1234',
'https':'https://10.10.10.1:4321'}
r = requests.request('GET','http://www.baidu.com', proxies=pxs)
Response
Response 对象的属性
| 属性 | 说明 |
|---|---|
| r.status_code | HTTP请求的返回值,200表示连接成功,404表示失败 |
| r.text | HTTP响应内容的字符串形式 |
| r.encoding | 从HTTP header 中猜测的响应内容编码方式(容易出错)注:如果header中不存在charset,则认为编码为ISO-8859-1 |
| r.apparent_encoding | 从内容中分析出的响应内容编码方式(备选编码方式) |
| r.content | HTTP响应内容的二进制形式(比如一个图片的还原) |
1-3 requests库的异常
| 异常 | 说明 |
|---|---|
| ConnectionError | 网络连接异常,如DNS查询失败,拒绝连接等 |
| HTTPError | HTTP错误异常 |
| URLRequired | URL缺失异常 |
| TooManyRedirects | 超过最大重定向次数,产生重定向异常 |
| ConnectTimeout | 连接远程服务器超时异常 |
| Timeout | 请求URL超时,产生超时异常 |
| 查询异常方法 | 说明 |
|---|---|
| r.raise_for_status() | 如果不是200,产生异常requests.HTTPError |
1-4 爬取网页的通用代码框架
import requests
def getHTMLText(url):
try:
r = requests.get(url)
r.raise_for_status()#如果状态不是200,引发HTTPError异常(很重要)
r.encoding = r.apparent_encoding
return r.text
except:
return "产生异常"
if __name__ == "__main__":
url = "http://www.baidu.com"
print(getHTMLText(url))
2、事项
2-1 HTTP协议
Hypertext Transfer Protocol,超文本传输协议
- HTTP是一个基于“请求与响应”模式的、无状态的应用层协议。
- HTTP协议和Requests库是一一对应的。
- HTTP协议采用URL作为定位网络资源的标识。
- URL是通过HTTP协议存取资源的Internet路径,一个URL对应一个数据资源。
URL格式: http://host[:port][path]
host:合法的Internet主机域名或IP地址
port:端口号,缺省名为80
2-2 网络爬虫
网络爬虫的尺寸
小规模(网页):数据量小、爬取速度不敏感,Requests库
中规模(网站):数据规模较大,爬取速度较慢。Scrapy库
大规模(全网):搜索引擎
网络爬虫的限制
-
来源审查:判断User-Agent进行限制
-
检查来访HTTP协议头的User-Agent域,只响应浏览器或友好爬虫的访问。
-
发布公告:Robots协议
Robots Exclusion Standard 网络爬虫排除标准。
- 形式: 在网站根目录下的robots.txt文件也不是所有网站都有。没有就是默认可以随便爬。
- 告知所有爬虫网站的爬取策略,要求爬虫遵守。
案例:京东的Robots协议:
https://www.jd.com/robots.txt
User-agent: * —无论什么类型的网络爬虫
Disallow: /?* ----任何爬虫不允许访问以?开头的路径
Disallow: /pop/.html
Disallow: /pinpai/.html?*
User-agent: EtaoSpider —下面四种爬虫不允许爬取京东的任何数据资源
Disallow: /
User-agent: HuihuiSpider
Disallow: /
User-agent: GwdangSpider
Disallow: /
User-agent: WochachaSpider
Disallow: /
Robots协议的基本语法
# 注释, *代表所有, /代表根目录
Robots协议的使用
- 网络爬虫:自动或人工识别robots.txt,再进行内容爬取
- 约束性:Robots协议是建议性非约束性的。
- 类人的爬虫行为可不参考Robots协议。
3、requests库网络爬虫实战
3-1京东商品页面的爬取
import requests
url = "https://item.jd.com/100010079900.html"
try:
r = requests.get(url)
r.raise_for_status()
r.encoding = r.apparent_encoding
print(r.text[:1000])
except:
print("爬取失败")
3-2 亚马逊商品页面的爬取
import requests
r = requests.get("https://www.amazon.cn/dp/B07RB134KX/ref=sr_1_1?brr=1&qid=1585304390&rd=1&s=digital-text&sr=1-1")
print(r.status_code) #200
print(r.encoding)#ISO-8859-1
r.encoding = r.apparent_encoding
print(r.text) #出现验证信息,不能爬取
print(r.headers)
{‘Server’: ‘Server’, ‘Date’: ‘Fri, 27 Mar 2020 10:30:54 GMT’, ‘Content-Type’: ‘text/html’, ‘Content-Length’: ‘2369’, ‘Connection’: ‘keep-alive’, ‘Vary’: ‘Content-Type,Accept-Encoding,X-Amzn-CDN-Cache,X-Amzn-AX-Treatment,User-Agent’, ‘Content-Encoding’: ‘gzip’, ‘x-amz-rid’: ‘ARC0DKYHE23WNMPJAJRZ’}
url ="https://www.amazon.cn/dp/B07RB134KX/ref=sr_1_1?brr=1&qid=1585304390&rd=1&s=digital-text&sr=1-1"
kv = {'user-agent':'Mozilla/5.0'}
r = requests.get(url,headers=kv)
print(r.status_code) #200
import requests
url ="https://www.amazon.cn/dp/B01BTX8DIC/ref=s9_acsd_hps_bw_r2_r0_1_i?pf_rd_m=A1U5RCOVU0NYF2&pf_rd_s=merchandised-search-3&pf_rd_r=ZE4P6V56J3W1KE8EG7NR&pf_rd_t=101&pf_rd_p=0632bfee-8e34-483d-855b-5d8adcfeac89&pf_rd_i=813108051"
try:
kv = {'user-agent':'Mozilla/5.0'}
r = requests.get(url,headers=kv)
r.raise_for_status()
r.encoding = r.apparent_encoding
print(r.text[1000:2000])
except:
print("爬取失败")
有验证码(反爬了)QAQ
3-3 360、必应搜索关键字提交
搜索引擎关键字交接口
- 百度( 反爬了):http://www.baidu.com/s?wd=keyword
- 360: http://www.so.com/s?q=keyword
- 必应:https://cn.bing.com/search?q=keyword
import requests
kv = {'q':'Python'}
r = requests.get("http://www.so.com/s", params=kv)
print(r.status_code) #200
print(r.request.url)
#https://www.so.com/s?q=Python
import requests
keyword = "Python"
try:
kv = {'q':keyword}
r = requests.get("http://www.so.com/s", params=kv)
print(r.request.url)
r.raise_for_status()
print(len(r.text))
except:
print("爬取失败")
'''
https://www.so.com/s?q=Python
278348
'''
3-4 网络图片的爬取和存储
可以改为gif、视频(二进制)的获取模板
网络图片链接的格式:http://www.example.com/picture.jpg
import requests
path = "D:/abc.jpeg"
url = 'https://images.pexels.com/photos/462030/pexels-photo-462030.jpeg'
r = requests.get(url)
print(r.status_code)
with open(path, "wb") as f: #wb二进制
f.write(r.content)
f.close()
全代码
import requests
import os
url = 'https://images.pexels.com/photos/462030/pexels-photo-462030.jpeg'
root = 'D://pics//'
path = root + url.split('/')[-1]
try:
if not os.path.exists(root):
os.mkdir(root)
if not os.path.exists(path):
r = requests.get(url)
with open(path, 'wb') as f:
f.write(r.content)
f.close()
print("文件保存成功")
else:
print("文件已存在")
except:
print("爬取失败")
3-5 IP地址归属地的自动查询
查询IP地址的网站: https://m.ip138.com/
查询端口:https://m.ip138.com/iplookup.asp?ip=ipadress
import requests
text="202.204.80.112"
headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.100 Safari/537.36",
}
url="https://m.ip138.com/iplookup.asp?ip={}".format(text)
html=requests.get(url,headers=headers)
html.encoding=html.apparent_encoding
print(html.text[-500:])
3-6 查询虎牙某120前的播放人数的主播
这个是我在慕课上的python入门中敲的,2020年敲的,现在已经忘了怎么实现的了,记录一下,发现这个还能跑。
from urllib import request
import re
class Spider():
url = 'https://www.huya.com/g/lol'
root_pattern = '([\s\S]*?[\s\S]*?)'
name_pattern = '([\s\S]*?)'
number_pattern = '([\s\S]*?)'
def __fetch_content(self):
r = request.urlopen(Spider.url)
htmls = r.read()
htmls = str(htmls,encoding='utf-8')
return htmls
#数据提取
def __analysis(self,htmls):
root_html=re.findall(Spider.root_pattern,htmls)
anchors = []
for html in root_html:
name = re.findall(Spider.name_pattern,html)
number = re.findall(Spider.number_pattern,html)
anchor = {'name':name,'number':number}
anchors.append(anchor)
# print(root_html[0])
# print(anchors)
return anchors
def __sort_seed(self, anchors):
r = re.findall('[1-9]\d*\.?\d*',anchors['number'])
number = float(r[0])
print(number)
if '万' in anchors['number']:
number *= 10000
return number
def __sorted(self, anchors):
anchors = sorted(anchors,key=self.__sort_seed,reverse=True)
return anchors
def __show(self,anchors):
for rank in range(0,len(anchors)):
print('rank' +str(rank+1)+' : '+anchors[rank]['name']+' '+anchors[rank]['number'])
#精炼数据
def __refine(self,anchors):
l = lambda anchor: {
'name':anchor['name'][0],
'number':anchor['number'][0]
}
return map(l,anchors)
# 总控方法
def go(self):
htmls = self.__fetch_content()
anchors = self.__analysis(htmls)
anchors = self.__refine(anchors)
anchors = self.__sorted(anchors)
self.__show(anchors)
spider = Spider()
spider.go()
4、BeautifulSoup库入门
pip install beautifulsoup4
4-1 BeautifulSoup库的基本元素
BeautifulSoup库的理解:
BeautifulSoup库是解析、遍历维护“标签树”的功能库
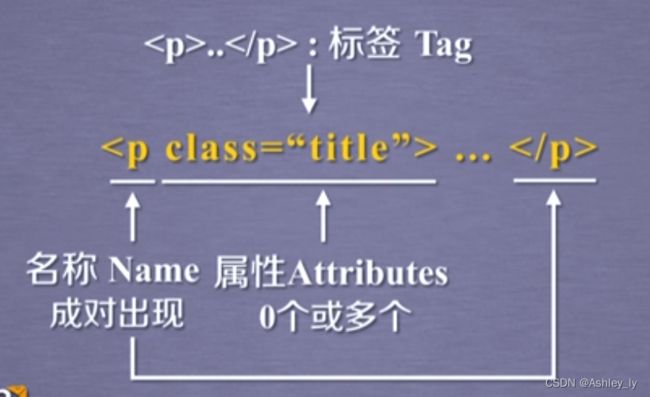
属性是由键和值构成的。
BeautifulSoup的引用
from bs4 import BeautifulSoup
import bs4
from bs4 import BeautifulSoup
soup = BeautifulSoup('data',"html.parser")
soup2 = BeautifulSoup(open("D://demo.html"),"html.parser")
BeautifulSoup库解析器
| 解析器 | 使用方法 | 条件 |
|---|---|---|
| bs4的HTML解析器 | BeautifulSoup(mk,‘html.parser’) | 安装bs4库 |
| Ixml的HTML解析器 | BeautifulSoup(mk,‘Ixml’) | pip install Ixml |
| Ixml的XML解析器 | BeautifulSoup(mk,‘xml’) | pip install Ixml |
| html5lib的解析器 | BeautifulSoup(mk,‘html5lib’) | pip install html5lib |
BeautifulSoup类的基本元素
| 基本元素 | 说明 |
|---|---|
| Tag | 标签,分别用<>和标明开头和结尾 |
| Name | 标签的名字, … 的名字是p,格式:.name |
| Attributes | 标签的属性,字典形式组织,格式:.attrs |
| NavigableString | 标签内的非属性字符串,<>…中的字符串,格式:.string |
| Comment | 标签内字符串的注释部分,一种特殊的Comment类型 |
import requests
r = requests.get("http://python123.io/ws/demo.html")
demo = r.text
from bs4 import BeautifulSoup
soup = BeautifulSoup(demo,"html.parser")
print(soup.title) #title标签
#This is a python demo page
print(soup.a)
#a标签,有多个只能返回第一个标签
##Basic Python
print(soup.a.string)
#Basic Python
print(type(soup.a.string))
#This is not a comment
","html.parser")
print(newsoup.b.string)
#This is a comment
print(type(newsoup.b.string))
#4-2 基于bs4库的HTML内容遍历方法
BeautifulSoup对应一个HTML/XML文档的全部内容
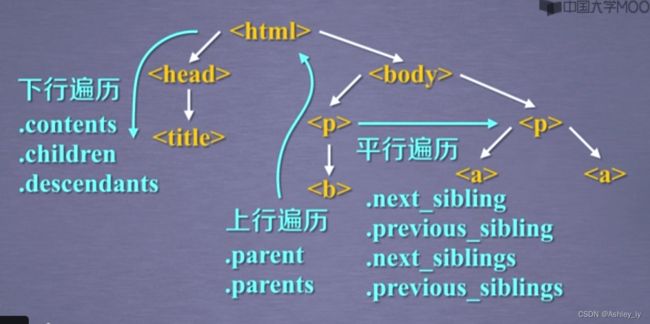
标签树的下行遍历
| 下行遍历属性 | 说明 |
|---|---|
| .content | 子节点的列表,将所有儿子节点存入列表 |
| .chirdren | 子节点的迭代类型,用于循环遍历儿子节点 |
| .descendants | 子孙节点的迭代类型,包含所有子孙节点,用于循环遍历 |
4-3、中国大学爬虫
程序的结构设计:
- 从网络上获取大学排名网页内容
getHTML.Text()
- 提取网页内容中信息到合适的数据结构
fillUnivList()
- 利用数据结构展示并输出
printUnivList()
import requests
from bs4 import BeautifulSoup
import bs4
def getHTMLText(url):
try:
r=requests.get(url,timeout=30) #30s
r.raise_for_status()
#它能够判断返回的Response类型状态是不是200。如果是200,他将表示返回的内容是正确的,如果不是200,他就会产生一个HttpError的异常。
r.encoding = r.apparent_encoding
return r.text
except:
return ""
#核心部分
def fillUnivList(ulist, html):
soup=BeautifulSoup(html,"html.parser")
for tr in soup.find('tbody').children:
if isinstance(tr,bs4.element.Tag): #检测tr标签的类型
tds = tr('td') #将所有的td标签存了一个列表类型tds
ulist.append([tds[0].string,tds[1].string,tds[2].string])
#加入排名、大学名称、分数
'''你希望打印多少个num个学校的信息'''
def printUnivList(ulist,num):
print("{:^10}\t{:^6}\t{:^10}".format("排名","学校名称","总分"))
for i in range(num):
u=ulist[i]
print("{:^10}\t{:^6}\t{:^10}".format(u[0],u[1],u[2]))
print("Suc"+str(num))
def main():
uinfo = []
url='https://www.shanghairanking.cn/rankings/bcur/2020'
html=getHTMLText(url)
fillUnivList(uinfo,html)
printUnivList(uinfo,20) #20个学校
main()
5、Scrapy
pip install scrapy
5-1 爬虫框架
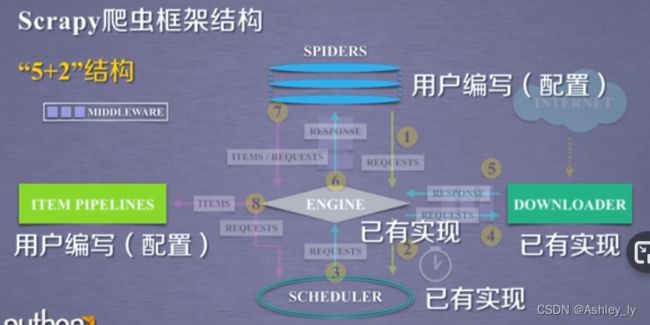
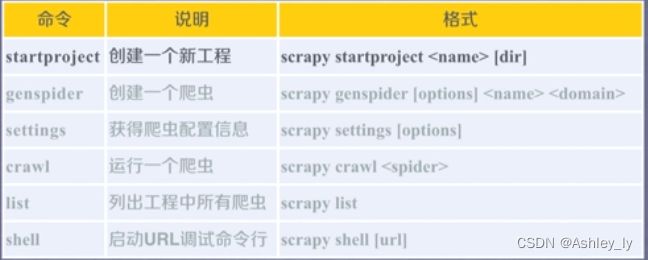
scrapy命令行
- 命令行更容易自动化,适合脚本控制
5-2 基本使用
在特定的目录下
scrapy startproject python123demo
cd python123demo
scrapy genspider demo python123.io
//Created spider 'demo' using template 'basic'
scrapy crawl demo


下面是输入:scrapy genspider demo python123.io生成的demo.py
import scrapy
class DemoSpider(scrapy.Spider):
name = 'demo'
allowed_domains = ['python123.io']
start_urls = ['http://python123.io/']
#parse()用于处理响应,解析内容形成字典,发现新的URL爬去请求
def parse(self, response):
pass
import scrapy
class DemoSpider(scrapy.Spider):
name = 'demo'
#allowed_domains = ['python123.io']
start_urls = ['http://python123.io/ws/demo.html']
def parse(self, response):
fname=response.url.split('/')[-1]
with open(fname,'wb') as f:
f.write(response.body)
self.log('Saved file %s.' % name)
捕获页面存到demo.html中
在这里插入图片描述

生成器的优势:
- 更节省存储空间,当n很大很大时
- 响应更迅速
- 使用更灵活
生成器写法(!!!)
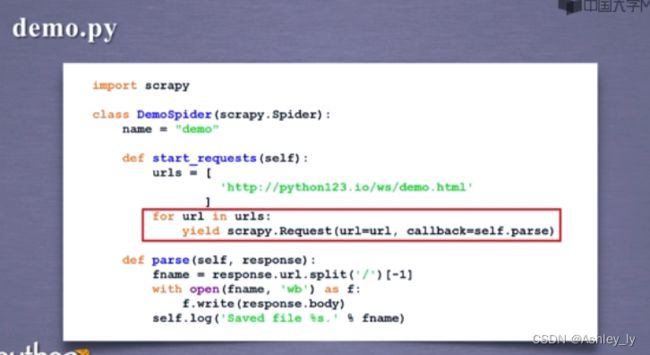
5-3 基本类
Request类:

Response类:

Item类
class scrapy.item.Item()
- Item对象表示一个从HTML页面中提取的信息内容。
- 由Spider生成,由ItemPipeline处理。
- Item类似字典类型,可以按照字典类型操作。
Scrapy爬虫提取信息时万法
Scrapy爬虫支持多种HTML信息提取方法
- Beautiful Soup
- lxml
- re
- XPath SelectorCSs
- Selector
CSS Selector的基本使用
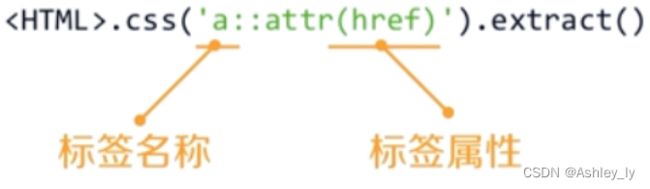
CSS Selector由W3C组织维护并规范