Opencv及常用方法示例代码
包括一些Opencv的基本示例代码,方便以后查阅。
这里写目录标题
- 一
-
- 1.1在Pycharm中运行tensorflow出现的问题
- 1.2案例1:图片的读取和展示
- 1.3案例2:图片写入
- 1.4案例3:不同图片质量保存
- 1.5像素操作基础
- 1.6案例4:像素读取写入
- 1.8tensorflow常量变量定义
- 1.9tensorflow运算原理
- 1.10常量变量四则运算
- 1.11矩阵基础1
- 1.12矩阵基础2
- 1.13矩阵基础3
- 1.14numpy模块使用
- 1.15matplotlib模块的使用
- 二
-
- 2.1图片缩放1
- 2.2图片缩放2
- 2.3图片缩放3
- 2.4图片剪切
- 2.5图片位移
- 2.6图片镜像
- 2.7图片缩放
- 2.8图片仿射变换
- 2.9图片旋转
- 三
-
- 3.1图像灰度处理1
- 3.2图像灰度处理2
- 3.3颜色反转
- 3.4马赛克
- 3.5毛玻璃
- 3.6图片融合
- 3.7边缘检测1
- 3.8边缘检测2
- 3.9浮雕效果
- 3.10颜色映射
- 3.11油画特效
- 3.12线段绘制
- 3.13矩形圆形任意多边形绘制
- 3.14文字图片绘制
- 四
-
- 4.1彩色图片直方图
- 4.2直方图均衡化
- 4.3图片修补
- 4.4灰度直方图源码
- 4.5彩色直方图源码
- 3.15灰度直方图均衡化源码分析
- 3.16彩色图像直方图均衡化源码分析
- 3.17亮度增强
- 3.18磨皮美白
- 3.19高斯均值滤波
- 3.20中值滤波
一
1.1在Pycharm中运行tensorflow出现的问题
解决python调用TensorFlow时出现FutureWarning: Passing (type, 1) or ‘1type’ as a synonym of type is deprecate
https://blog.csdn.net/bigdream123/article/details/99467316
python Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
https://blog.csdn.net/wukai0909/article/details/97306316
#注意tensorflow的输出格式和平常不同
import tensorflow as tf
hello = tf.constant("hello tf!")
sess = tf.Session()
print(sess.run(hello))
1.2案例1:图片的读取和展示
import cv2
srcImage = cv2.imread("E:\\pictures\\12.jpg",1)
cv2.imshow("srcImage",srcImage)
cv2.waitKey(0)
# PS:在Python中图片的名称、输出窗口等都不能有中文,这点和C++不同
1.3案例2:图片写入
import cv2
srcImage = cv2.imread("E:\\pictures\\12.jpg",1)
cv2.imwrite("srcImage.jpg",srcImage)#第一个参数是图像名,第二个参数是图片的数据
1.4案例3:不同图片质量保存
①JPG的压缩:有损压缩
import cv2
srcImage = cv2.imread("E:\\pictures\\12.jpg",1)
cv2.imwrite("srcImage.jpg",srcImage,[cv2.IMWRITE_JPEG_QUALITY,0])
#数字0表示压缩的比例,范围是0-100,0是最高的压缩比,图像效果最差
②PNG的压缩:无损压缩且具有透明度属性
import cv2
srcImage = cv2.imread("E:\\pictures\\12.jpg",1)
cv2.imwrite("srcImage.png",srcImage,[cv2.IMWRITE_PNG_COMPRESSION,0])
#数字0表示压缩的比例,范围是0-9,0是最低的压缩比,图像效果最好
1.5像素操作基础
①对于RGB图像
eg.一个图像1.14M = 7205473*8 bit/8 (B)
含义:宽×高×三个像素通道×每个颜色变量是八位的 / 8(转化为字节要除8)
②对于PNG图像
除了RGB三个通道,还要加上透明度alpha 通道
1.6案例4:像素读取写入
import cv2
srcImage = cv2.imread("E:\\pictures\\12.jpg",1)
#像素的读取
(b,g,r) = srcImage[400,400]
#Opencv中的像素排布是BGR的格式 [400,400]表示该坐标的像素值
print("b="+str(b)+",g="+str(g)+",r="+str(r))
#像素的写入,画出一条第10行第100至第110行第110列的直线
#10 100 ----- 110 100
for i in range(1,100):
srcImage[10+i,100] = (255,0,0)
cv2.imshow("srcImage",srcImage)
cv2.waitKey(0)
1.8tensorflow常量变量定义
import tensorflow as tf
data1 = tf.constant(2.5) #定义常量
data2 = tf.constant(2,dtype=tf.int32)
data3 = tf.Variable(10,name='var') #定义变量
print(data1)
print(data3) #直接输出的是数据的信息
#打印常量
sess = tf.Session()
print(sess.run(data1))
print(sess.run(data2))
#打印变量
init = tf.global_variables_initializer()
sess.run(init)
print(sess.run(data3))
# 输出:
# Tensor("Const:0", shape=(), dtype=float32)
# 1.9tensorflow运算原理
1.tensorflow的本质是 = tensor + graphs
(tensor是张量、数据的意思,op即option操作运算,graphs是计算图、数据操作的意思,)
2.Session是计算的核心,可以理解为一个运算的交互环境
3.在上一节中,我们Session之后没有进行其他的操作,正常情况下是要close的:sess.close()
若不想这么麻烦,可以这样操作:
import tensorflow as tf
data1 = tf.Variable(10,name='var')
init = tf.global_variables_initializer()
sess = tf.Session()
with sess:
sess.run(init)
print(sess.run(data1))
1.10常量变量四则运算
①常量的四则运算
import tensorflow as tf
data1 = tf.constant(6)
data2 = tf.constant(2)
dataAdd = tf.add(data1,data2) #加
dataMul = tf.multiply(data1,data2) #乘
dataSub = tf.subtract(data1,data2) #减
dataDiv = tf.divide(data1,data2) #除
with tf.Session() as sess:
print(sess.run(dataAdd))
print(sess.run(dataMul))
print(sess.run(dataSub))
print(sess.run(dataDiv))
print('end!')
# 输出:
# 8
# 12
# 4
# 3.0
# end!
②常量与变量的四则运算
eval()方法:用于直接输出,相当于获取了一个默认的session,然后执行run的操作
import tensorflow as tf
data1 = tf.constant(6)
data2 = tf.Variable(2)
dataAdd = tf.add(data1,data2) #加
dataCopy = tf.assign(data2,dataAdd) # dataAdd赋值给data2
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
print('sess.run(dateCopy)',sess.run(dataCopy)) #将8赋给data2
print('dataCopy.eval()',dataCopy.eval()) #data2+dataAdd:8+6=14
print('tf.get_default_session',tf.get_default_session().run(dataCopy))#14+6=20
print('end!')
1.11矩阵基础1
①tf.placeholder(dtype, shape=None, name=None)
TensorFlow中的占位符,用于传入外部数据。
参数:dtype:数据类型;shape:数据的维度,默认为None,表示没有限制;name:名称
示例:
import tensorflow as tf
data1 = tf.placeholder(tf.float32)
data2 = tf.placeholder(tf.float32)
dataAdd = tf.add(data1,data2)
with tf.Session() as sess:
print(sess.run(dataAdd,feed_dict={data1:6,data2:2}))
#1.张量dataAdd 2.语法:data(feed_dict={参数1:6,参数2:2})
②tensorflow中的矩阵运算
矩阵的定义:[[ 6,6 ]]表示一行两列的数据,外层的[ ]表示行,里层的[ ]表示列
import tensorflow as tf
data1 = tf.constant([[6,6]])
data2 = tf.constant([[2],[2]])
data3 = tf.constant([[3,3]])
data4 = tf.constant([[1,2],[3,4],[5,6]])
print(data4.shape) #打印该矩阵的维度 3行两列
with tf.Session() as sess:
print(sess.run(data4)) #打印整个矩阵
print(sess.run(data4[0])) #打印矩阵第一行
print(sess.run(data4[:,0])) #打印矩阵第一列
print(sess.run(data4[0,1])) #打印矩阵第一行第二列的元素
# 输出:
# 输出:
# (3, 2)
# [[1 2]
# [3 4]
# [5 6]]
# [1 2]
# [1 3 5]
1.12矩阵基础2
注意矩阵乘法matmul()和multiply()两种方法的不同
import tensorflow as tf
data1 = tf.constant([[6,6]])
data2 = tf.constant([[2],[2]])
data3 = tf.constant([[3,3]])
data4 = tf.constant([[1,2],[3,4],[5,6]])
matMul = tf.matmul(data1,data2)
matMul2 = tf.multiply(data1,data2)
matAdd = tf.add(data1,data3)
with tf.Session() as sess:
print(sess.run(matMul)) #矩阵相乘1*2 * 2*1 = 1*1
print(sess.run(matMul2)) # 矩阵相乘1*2 * 2*1 = 2*2
print(sess.run(matAdd)) #矩阵相加
#通过中括号的方式可以一次打印多个值
print(sess.run([matMul,matAdd]))
# 输出:
# [[24]]
#[[12 12]
# [12 12]]
# [[9 9]]
# [array([[24]]), array([[9, 9]])]
1.13矩阵基础3
①特殊矩阵的初始化
import tensorflow as tf
mat1 = tf.zeros([2,3]) #设2*3的矩阵元素全为0
mat2 = tf.ones([3,2]) #设3*2的矩阵元素全为1
mat3 = tf.fill([2,3],15) #填充2*3的矩阵元素全为15
with tf.Session() as sess:
print(sess.run(mat1))
print(sess.run(mat2))
print(sess.run(mat3))
②linspace方法将区间取等分,zeros_like表示矩阵取相同的维度
mat1 = tf.constant([[2],[3],[4]])
mat2 = tf.zeros_like(mat1) #表示mat2矩阵和mat1矩阵的维度一样
mat3 = tf.linspace(0.0,2.0,11) #矩阵的元素在0-2之间等分
mat4 = tf.random_uniform([2,3],-1,2) #表示定义一个2*3的矩阵,元素在-1到2区间随机取
1.14numpy模块使用
import numpy as np
data1 = np.array([1,2,3,4,5])
print(data1)
data2 = np.array(([1,2],[3,4]))
print(data2)
print(data1.shape,data2.shape) #打印矩阵的维度
print(np.zeros([2,3]),np.ones([2,2])) #zeros和ones
data2[1,0] = 5 #将data2矩阵中第二行第一列的元素赋值为5
print(data2)
#矩阵的基本运算
data3 = np.ones([2,3])
print(data3*2) #对应元素相乘
print(data3/3) #对应元素相除
print(data3+2) #对应元素相加
#矩阵+ *
data4 = np.array([[1,2,3],[4,5,6]])
print(data3+data4)
print(data3*data4)
1.15matplotlib模块的使用
import numpy as np
import matplotlib.pyplot as plt
x = np.array([1,2,3,4,5,6,7,8])
y = np.array([3,5,7,6,2,6,10,15])
plt.plot(x,y,'red') #绘制折线,参数:x轴,y轴,颜色
plt.plot(x,y,'g',lw=10) #'g'表示绿色,lw是折现的宽度
#三种图像:折线,饼状,柱状
x = np.array([1,2,3,4,5,6,7,8])
y = np.array([3,5,7,6,2,6,10,15])
plt.bar(x,y,0.5,alpha=1,color='b')
#0.5表示柱状的宽度,alpha表示透明度,color表示颜色
plt.show()
输出:

二
2.1图片缩放1
resize()函数,第一个参数为源图,第二个参数为要缩放的宽和高,插值的类型。
import cv2
img = cv2.imread("E:\\pictures\\4.jpg",1)
imgInfo = img.shape
print(imgInfo)
height = imgInfo[0]
width = imgInfo[1]
mode = imgInfo[2] #存放方式,即通道数
dstHeight = int(height*0.5)
dstWidth = int(width*0.5)
dst = cv2.resize(img,(dstWidth,dstHeight))
cv2.imshow("dst",dst)
print(dst.shape)
cv2.waitKey(0)
# 输出:
# (434, 650, 3)
# (217, 325, 3)
输出格式:高度(行)、宽度(列)、通道数
2.2图片缩放2
https://blog.csdn.net/csdnforyou/article/details/82315683
①最近邻域插值法
说明:假设原图src:1020 效果图dst:510,则效果图由原图缩放而来,dst上的一点(1,2)对应于src上的(2,4),设dst上的像素点x2,y2,src上的像素点x1,y1,计算公式为:
x1 = x2 (src 行 / 目标行)即:x1 = x2(10/5)= 12 = 2
y1 = y2 (src 列 / 目标列)即:y1 = y2(20/10)= 22 = 4
若计算得一像素点为12.3,则自动取12
②双线性插值法

上图中原图中只有(15,22),(15,23),(16,22),(16,23)四个点,目标图像中新增了(15.2,22.3)这个点,双线性差值法则是根据这个新的点的周围四个点来确定这个点的值,
A1=20%上 + 80%下;B1 = 30%左 + 70%右
最终点的确定:A130%+A270% B120% + B280%
2.3图片缩放3
前面已经掌握了算法的原理和图片缩放得API:resize函数,这里看下算法得源码
import cv2
import numpy as np
img = cv2.imread("E:\\pictures\\4.jpg",1)
imgInfo = img.shape
height = imgInfo[0]
width = imgInfo[1]
dstHeight = int(height/2)
dstWidth = int(width/2)
dst = np.zeros((dstHeight,dstWidth,3),np.uint8) #初始化,以便下面像素赋值
for i in range(0,dstHeight): #行
for j in range(0,dstHeight): #列
iNew = int(i*(height*1.0/dstHeight))
jNew = int(j*(width*1.0)/dstWidth)
dst[i,j] = img[iNew,jNew]
cv2.imshow("dst",dst)
print(dst.shape)
cv2.waitKey(0)
# 输出:
# (217, 325, 3)
2.4图片剪切

举例:剪切图像x轴100-200,y轴100-300
import cv2
img = cv2.imread("E:\\pictures\\4.jpg",1)
imgInfo = img.shape
dst = img[100:200,100:300]
cv2.imshow("dst",dst)
print(dst.shape)
cv2.waitKey(0)
# 输出:(100, 200, 3)
2.5图片位移
①示例程序
import cv2
import numpy as np
img = cv2.imread("E:\\pictures\\4.jpg",1)
imgInfo = img.shape
height = imgInfo[0]
width = imgInfo[1]
matShift = np.float32([[1,0,100],[0,1,200]]) #2*3的偏移矩阵
dst = cv2.warpAffine(img,matShift,(height,width))
cv2.imshow("dst",dst)
cv2.waitKey(0)
②API介绍:warpAffine()
就拿上面的程序为例:[[1,0,100],[0,1,200]]是23的矩阵,拆分成22和21的两个矩阵,假设A是22的矩阵,即[[1,0], [0,1]],B是21的矩阵,即[[100],[200]],C是x和y。根据公式:AC+B = [[1x+0y],[0x+1y]]+[[100],[200]] = [[x+100],[y+200]]
③用算法原理编程:将原图往右移动100个像素
PS:先将dst初始化为黑色,因为是将图像右移100个像素,所以行不变,列改变,即先将dst的列先加100,再将原图dst的(列-100)再赋值给dst
import cv2
import numpy as np
img = cv2.imread("E:\\pictures\\4.jpg",1)
imgInfo = img.shape
height = imgInfo[0]
width = imgInfo[1]
dst = np.zeros((height,width,3),np.uint8) #初始化,以便下面像素赋值
for i in range(0,height): #行
for j in range(0,width-100): #列
dst[i,j+100] = img[i,j]
cv2.imshow("dst",dst)
cv2.waitKey(0)
2.6图片镜像
①步骤:①创建一个足够大的“画板”②将一副图像分别从前向后、从后向前绘制③绘制中心分割线
②程序
import cv2
import numpy as np
img = cv2.imread("E:\\pictures\\4.jpg",1)
imgInfo = img.shape
height = imgInfo[0]
width = imgInfo[1]
deep = imgInfo[2] #图像的通道数
newImgInfo = (height*2,width,deep) #创建一个画板
dst = np.zeros(newImgInfo,np.uint8) #初始化,以便下面像素赋值
for i in range(0,height): #行
for j in range(0,width): #列
dst[i,j] = img[i,j] #先绘制上半部分
#因为是上下镜像,所以x不变,y*2
#下半部分图像坐标,x不变,y=2*h-y-1
dst[height*2-i-1,j] = img[i,j]
for i in range(0,width):
dst[height,i] = (0,0,255) #绘制中心分割线
cv2.imshow("dst",dst)
cv2.waitKey(0)
2.7图片缩放
参考图片位移
import cv2
import numpy as np
img = cv2.imread("E:\\pictures\\4.jpg",1)
imgInfo = img.shape
height = imgInfo[0]
width = imgInfo[1]
matScale = np.float32([[0.5,0,0],[0,0.5,0]])
dst = cv2.warpAffine(img,matScale,(int(width/2),int(height/2)))
cv2.imshow("dst",dst)
cv2.waitKey(0)
2.8图片仿射变换
import cv2
import numpy as np
img = cv2.imread("E:\\pictures\\4.jpg",1)
imgInfo = img.shape
height = imgInfo[0]
width = imgInfo[1]
#已知原图上的三个点(左上角,左下角,右上角)
matSrc = np.float32([[0,0],[0,height-1],[width-1,0]])
#将这三个点映射到目标图像上
matDst = np.float32([[50,50],[300,height-200],[width-300,100]])
#组合两个矩阵
matAffine = cv2.getAffineTransform(matSrc,matDst)
dst = cv2.warpAffine(img,matAffine,(width,height))
cv2.imshow('dst',dst)
cv2.waitKey(0)
输出:

2.9图片旋转
①API:getRotationMatrix2D()介绍:第一个参数:旋转的中心;第二个参数:旋转的角度;第三个参数:缩放的系数
②程序
import cv2
import numpy as np
img = cv2.imread("E:\\pictures\\4.jpg",1)
imgInfo = img.shape
height = imgInfo[0]
width = imgInfo[1]
#定义旋转矩阵
matRotate = cv2.getRotationMatrix2D((height*0.5,width*0.5),45,0.5)
dst = cv2.warpAffine(img,matRotate,(height,width))
cv2.imshow('dst',dst)
cv2.waitKey(0)
三
3.1图像灰度处理1
# 方法一:一开始图片导入的时候就以灰度图像显示
img0 = cv2.imread('image0.jpg',0)
# 方法二:使用cvtColor,将彩色图转为灰度图
dst = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY) #颜色空间转换
3.2图像灰度处理2
方法三:所谓灰度图,即RBG三通道的值一样,R=G=B = gray
import cv2
import numpy as np
img = cv2.imread("E:\\pictures\\4.jpg",1)
imgInfo = img.shape
height = imgInfo[0]
width = imgInfo[1]
# RGB R=G=B = gray (R+G+G)/3
dst = np.zeros((height,width,3),np.uint8)
for i in range(0,height): #行
for j in range(0,width): #列
(b,g,r) = img[i,j] #表示原图每个像素的三通道的值
gray = (int(b) + int(g) +int(r))/3
dst[i,j] = np.uint8(gray)
cv2.imshow('dst',dst)
cv2.waitKey(0)
方法四:公式:gray = r0.299 + g0.587 +b*0.114
前面的程序与上面相同,就for循环这里改变
for i in range(0,height): #行
for j in range(0,width): #列
(b,g,r) = img[i,j] #表示原图每个像素的三通道的值
b = int(b)
g = int(g)
r = int(r)
gray = r*0.299+g*0.587+b*0.114
dst[i,j] = np.uint8(gray)
对于方法四中的公式法,浮点数转为整型的过程中,会存在丢失精度的可能,可以将原值进行放大的操作,如乘1000等等
3.3颜色反转
①灰度图像的颜色反转 0-255 255-当前
import cv2
import numpy as np
img = cv2.imread("E:\\pictures\\4.jpg",1)
imgInfo = img.shape
height = imgInfo[0]
width = imgInfo[1]
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
dst = np.zeros((height,width,1),np.uint8) #转为灰度图像后是一个通道
for i in range(0,height): #行
for j in range(0,width): #列
grayPixel = gray[i,j]
dst[i,j] = 255-grayPixel
cv2.imshow('dst',dst)
cv2.waitKey(0)
②彩色图像的颜色反转 RGB 255-R=newR:0-255 255-当前
import cv2
import numpy as np
img = cv2.imread("E:\\pictures\\4.jpg",1)
imgInfo = img.shape
height = imgInfo[0]
width = imgInfo[1]
dst = np.zeros((height,width,3),np.uint8) #彩色图像有3个通道
for i in range(0,height): #行
for j in range(0,width): #列
(b,g,r) = img[i,j]
dst[i,j] = (255-b,255-g,255-r) #对三个通道进行赋值
cv2.imshow('dst',dst)
cv2.waitKey(0)
3.4马赛克
原理:马赛克是有形状的,有圆形、矩形等等,本节讲的是矩形。工作原理:首先选取马赛克的范围,然后再选取一个小区域,将这区域中的所有像素值,选用其中某一个点的像素值来表示。
import cv2
import numpy as np
img = cv2.imread("E:\\pictures\\4.jpg",1)
imgInfo = img.shape
height = imgInfo[0]
width = imgInfo[1]
for m in range(100,300): #行
for n in range(100,200): #列
# 将10*10像素的所有值用一个像素点表示
if m%10 == 0 and n%10 == 0:
for i in range(0,10):
for j in range(0,10):
(b,g,r) = img[m,n]
img[i+m,j+n] = (b,g,r)
cv2.imshow('dst',img)
cv2.waitKey(0)
输出:

3.5毛玻璃
理解:毛玻璃操作与马赛克的区别:马赛克是选取一个区域,其中该区域的像素值是由某指定的点的像素值,而毛玻璃中该区域的像素值是该区域中随机一个点的像素值。
import cv2
import numpy as np
import random
img = cv2.imread("E:\\pictures\\4.jpg",1)
imgInfo = img.shape
height = imgInfo[0]
width = imgInfo[1]
dst = np.zeros((height,width,3),np.uint8)
mm = 8
for m in range(0,height-mm): #行-mm,防止溢出
for n in range(0,width-mm): #列-mm
index = int(random.random()*8) #产生随机数0-7
(b,g,r) = img[m+index,n+index]
dst[m,n] = (b,g,r)
cv2.imshow('dst',dst)
cv2.waitKey(0)
输出:

PS:可以发现效果图中,图片的右边与下边有黑边,这是因为在for循环中,为了防止溢出,height和width都减去了mm即8个像素的值,一开始dst是设置的黑色。
3.6图片融合
方法:将图片1乘以一个权重 + 图片2乘以一个权重,每个像素值都这样,要保证两图片大小一致。
import cv2
import numpy as np
img0 = cv2.imread("E:\\pictures\\34.jpg",1)
img1 = cv2.imread("E:\\pictures\\35.jpg",1)
imgInfo = img0.shape
height = imgInfo[0]
width = imgInfo[1]
#定义要融合的部分ROI,这里只融合图片的四分之一
roiH = int(height/2)
roiW = int(width/2)
img0ROI = img0[0:roiH,0:roiW]
img1ROI = img1[0:roiH,0:roiW]
#dst
dst = np.zeros((roiH,roiW,3),np.uint8)
dst = cv2.addWeighted(img0ROI,0.5,img1ROI,0.5,0) #0.5表示权重
cv2.imshow('dst',dst)
cv2.waitKey(0)
3.7边缘检测1
边缘检测的实质是卷积运算
canny算子的步骤:1.转化为灰度图像 2.采用高斯滤波 3.调用canny方法
import cv2
img = cv2.imread("E:\\pictures\\4.jpg",1)
imgInfo = img.shape
height = imgInfo[0]
width = imgInfo[1]
cv2.imshow('src',img)
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
imgG = cv2.GaussianBlur(gray,(3,3),0) #(3,3)表示内核的大小
dst = cv2.Canny(img,50,50) #如果图片经过卷积后大于50这个值,就认为是边缘
cv2.imshow('dst',dst)
cv2.waitKey(0)
输出:


3.8边缘检测2
Sobel算子:步骤
①算子模板:分为竖直方向的算子和水平方向的算子
Eg.[ 1 2 1 [ 1 0 -1
0 0 0 2 0 -2
-1 -2 -1] 为竖直方向的算子 1 0 -1] 为水平方向的算子
②图片卷积
举个公式:[ 1 2 3 4 ] [ a b c d ] a1+b2+c3+d4 = dst
③阈值判断
Sqrt( aa + bb) 若大于阈值,则为边缘,小于则不是。
a指的是竖直方向的算子和竖直方向的图片进行卷积后得到的就是a,叫梯度,同理b是水平方向的梯度
# 用源码编写的情况
import cv2
import numpy as np
import math
img = cv2.imread("E:\\pictures\\4.jpg",1)
imgInfo = img.shape
height = imgInfo[0]
width = imgInfo[1]
cv2.imshow('src',img)
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
dst = np.zeros((height,width,1),np.uint8)
for i in range(0,height-2):
for j in range(0,width-2):
#这里减2的原因是:算子模板是3*3的,右下角像素的坐标为2,2,防止溢出
#下面的计算就是用的上面举例的算子模板
gy = gray[i,j]*1+gray[i,j+1]*2+gray[i,j+2]*1-\
gray[i+2,j]*1-gray[i+2,j+1]*2-gray[i+2,j+2]*1
#采用竖直方向的算子,横着计算
gx = gray[i,j]*1+gray[i+1,j]*2+gray[i+2,j]*1-\
gray[i,j+2]*1-gray[i+1,j+2]*2-gray[i+2,j+2]*1
#采用水平方向的算子,竖着计算
grad = math.sqrt(gx*gx+gy*gy)
if grad >50:
dst[i,j] = 255 #是边界,设为白色
else:
dst[i,j] = 0 #不是边界,设为黑色,和背景相同
cv2.imshow('dst',dst)
cv2.waitKey(0)
输出:

3.9浮雕效果
浮雕和边缘检测比较类似,也是计算梯度的过程
公式为:newP = gray0 - gray1 + 150
(两个灰度值相减,凸出对比,加150增强浮雕的效果)
import cv2
import numpy as np
img = cv2.imread("E:\\pictures\\4.jpg",1)
imgInfo = img.shape
height = imgInfo[0]
width = imgInfo[1]
cv2.imshow('src',img)
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
# newP = gray0 - gray1 + 150
dst = np.zeros((height,width,1),np.uint8)
for i in range(0,height):
for j in range(0,width-1):
grayP0 = int(gray[i,j]) #获取当前像素的灰度值
grayP1 = int(gray[i,j+1]) #获取下一个像素的灰度值
newP = grayP0-grayP1 + 150
if newP > 255:
newP = 255
if newP < 0:
newP = 0
dst[i,j] = newP
cv2.imshow('dst',dst)
cv2.waitKey(0)
输出:

3.10颜色映射
原理:将原图像的RGB像素值,映射到你自己认为的一个颜色区间
import cv2
import numpy as np
img = cv2.imread("E:\\pictures\\4.jpg",1)
imgInfo = img.shape
height = imgInfo[0]
width = imgInfo[1]
cv2.imshow('src',img)
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
# RGB 产生蓝色的效果 b=b*1.5 g=g*1.3
dst = np.zeros((height,width,3),np.uint8)
for i in range(0,height):
for j in range(0,width):
(b,g,r) = img[i,j]
b = b*1.5
g = g*1.3
if b > 255:
b = 255
if g > 255:
g = 255
dst[i,j] = (b,g,r)
cv2.imshow('dst',dst)
cv2.waitKey(0)
输出:

3.11油画特效
步骤:1.彩色图像到灰度图像的转换
2.分成若干个区域,比如77或者88区域,统计每个区域中的灰度值
3.将0-255划分为几个等级,并把第二步中的灰度值映射到这个等级中
4.统计之前划分区域映射到第三步等级中的个数
5.用统计出来的平均值替换原图像的像素值
import cv2
import numpy as np
img = cv2.imread("E:\\pictures\\4.jpg",1)
imgInfo = img.shape
height = imgInfo[0]
width = imgInfo[1]
cv2.imshow('src',img)
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
dst = np.zeros((height,width,3),np.uint8)
for i in range(4,height-4):
for j in range(4,width-4):
array1 = np.zeros(8,np.uint8) #定义8个灰度等级
for m in range(-4,4): #选取8*8的区域
for n in range(-4,4):
#步骤三:灰度等级的统计
p1 = int(gray[i+m,j+n]/32) #p1范围是0-7
array1[p1] = array1[p1] + 1 #表示当前的像素值,完成累加
currentMax = array1[0] #获取array1中哪个段内的像素值最多
l = 0
for k in range(0,8):
if currentMax < array1[k]:
currentMax = array1[k]
l = k
#统计均值
for m in range(-4,4):
for n in range(-4,4):
if gray[i+m,j+n] >=(l*32) and gray[i+m,j+n]<=((l+1)*32):
(b,g,r) = img[i+m,j+n]
dst[i,j] = (b,g,r)
cv2.imshow('dst',dst)
cv2.waitKey(0)

3.12线段绘制
cv2.line(dst,(100,100),(300,300),(0,0,255),20,cv2.LINE_AA)
参数说明:1.线段绘制的目标图像 2.线段绘制的起始点 3.线段绘制的结束点 4.线段的颜色 5.线段的宽度 6.线段的类型LINE_AA为抗锯齿形。
3.13矩形圆形任意多边形绘制
①绘制矩形
cv2.rectangle(dst,(50,100),(200,300),(0,0,255),-1)
参数说明:1.矩形绘制的目标图像 2.矩形的左上角坐标 3.矩形的右下角坐标 4.矩形线条的颜色 5.是否填充,若为-1,表示填充;若为大于0的数,表示线段的宽度
②绘制圆形
cv2.circle(dst,(50,50),50,(0,0,255),2)
参数说明:1.圆形绘制的目标图像 2.圆心的坐标 3.圆的半径 4圆形线条的颜色 5.是否填充,若为-1,表示填充;若为大于0的数,表示线段的宽度
③绘制椭圆
cv2.ellipse(dst,(100,100),(150,100),0,0,180,(0,0,255),-1)
参数说明:1.椭圆绘制的目标图像 2.椭圆的中心点坐标 3.椭圆的长轴和短轴的长度 4.椭圆的角度 5.起始角度 6.结束角度 7.椭圆的颜色 8.是否填充
④绘制任意多边形
points = [] #表示多边形的各个顶点坐标
cv2.polylines(dst,[points],True,(0,0,255))
3.14文字图片绘制
import cv2
img = cv2.imread("E:\\pictures\\image0.jpg",1)
font = cv2.FONT_HERSHEY_SIMPLEX #字体的选择
cv2.rectangle(img,(200,100),(500,400),(0,255,0),3)
cv2.putText(img,'this is a flower',(100,300),font,1,(200,100,255),2,cv2.LINE_AA)
#参数:1.dst 2.文字内容 3.坐标 4.字体 5.字体大小 6.字体颜色 7.字体粗细 8.线条线型
cv2.imshow('dst',img)
cv2.waitKey(0)
输出:

import cv2
img = cv2.imread("E:\\pictures\\image0.jpg",1)
height = int(img.shape[0]*0.2)
width = int(img.shape[1]*0.2)
imgResize = cv2.resize(img,(width,height)) #将要加上的图片缩放处理
for i in range(0,height):
for j in range(0,width):
img[i+200,j+350] = imgResize[i,j]
cv2.imshow('dst',img)
cv2.waitKey(0)
输出:

四
4.1彩色图片直方图
API:calcHist() 绘制图像的直方图
import cv2
import numpy as np
def ImageHist(image,type): #定义个绘制直方图的函数
color = (255,255,255) #设置颜色
windowName = 'Gray'
if type == 31:
color = (255,0,0)
windowName = 'Blue Hist'
elif type == 32:
color = (0,255,0)
windowName = 'Green Hist'
elif type == 33:
color = (0,0,255)
windowName = 'Red Hist'
hist = cv2.calcHist([image],[0],None,[256],[0.0,255.0])
#直方图函数参数说明:1.图片 2.当前通道 3.掩膜 4.直方图的大小,分成多少类
# 5.表明直方图中各个像素的值0-255表明像素从0-255都遍历一次
#开始绘图
#首先要知道直方图中最大值最小值以及它们的坐标,为了下面的坐标归一化
minValue,maxValue,minIndex,maxIndex = cv2.minMaxLoc(hist)
histImage = np.zeros([256,256,3],np.uint8)
for h in range(256):
intenNormal = int(hist[h]*256/maxValue) #将值归一化,使绘图美观
cv2.line(histImage,(h,256),(h,256-intenNormal),color)
cv2.imshow(windowName,histImage)
return histImage
img = cv2.imread('E:\\pictures\\image0.jpg')
channels = cv2.split(img) #将RGB图像分割成R G B 三个通道
for i in range(0,3):
ImageHist(channels[i],31+i)
cv2.waitKey(0)
输出:

4.2直方图均衡化
API:equalizeHist 直方图的均衡化
merge 图像通道的合成
split 图像通道的分解
①灰度图像的直方图均衡化
import cv2
img = cv2.imread('E:\\pictures\\image0.jpg',1)
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
cv2.imshow('src',gray)
dst = cv2.equalizeHist(gray)
cv2.imshow('dst',dst)
cv2.waitKey(0)
输出:

②彩色图像的直方图均衡化
import cv2
img = cv2.imread('E:\\pictures\\image0.jpg',1)
(b,g,r) = cv2.split(img) #通道分解
bH = cv2.equalizeHist(b)
gH = cv2.equalizeHist(g)
rH = cv2.equalizeHist(r)
result = cv2.merge((bH,gH,rH)) #通道合成
cv2.imshow('src',img)
cv2.imshow('dst',result)
cv2.waitKey(0)
输出:

③YUV图像的直方图均衡化
import cv2
img = cv2.imread('E:\\pictures\\image0.jpg',1)
imgYUV = cv2.cvtColor(img,cv2.COLOR_BGR2YCrCb)
channelYUV = cv2.split(imgYUV)
channelYUV[0] = cv2.equalizeHist(channelYUV[0])
channels = cv2.merge(channelYUV)
result = cv2.cvtColor(channels,cv2.COLOR_BGR2YCrCb)
cv2.imshow('src',imgYUV)
cv2.imshow('dst',result)
cv2.waitKey(0)
输出:

4.3图片修补
API:inpaint 图片修补
步骤:1.需要一个损坏的图 2.知道损坏的像素坐标 3.调用API
4.4灰度直方图源码
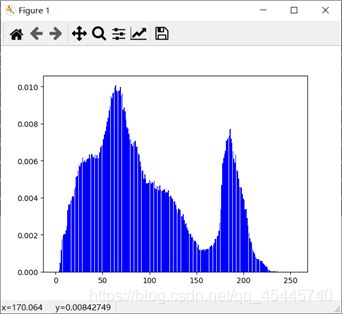
# 本质:统计每个像素灰度 出现的概率 0-255
import cv2
import numpy as np
import matplotlib.pyplot as plt
img = cv2.imread('E:\\pictures\\image0.jpg',1)
imgInfo = img.shape
height = imgInfo[0]
width = imgInfo[1]
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
count = np.zeros(256,np.float) #表示每个像素值在每个灰度等级下出现的概率,256个等级
for i in range(0,height):
for j in range(0,width):
pixel = gray[i,j] #获取每个灰度等级的像素
index = int(pixel) #转为int类型
count[index] = count[index]+1
for i in range(0,255): #每个灰度等级出现的概率
#分子是count,分母是所有的像素
count[i] = count[i]/(height*width)
x = np.linspace(0,255,256)
y = count
plt.bar(x,y,0.9,alpha=1,color='b')
plt.show()
cv2.waitKey(0)
输出:
4.5彩色直方图源码
import cv2
import numpy as np
import matplotlib.pyplot as plt
img = cv2.imread('E:\\pictures\\image0.jpg',1)
imgInfo = img.shape
height = imgInfo[0]
width = imgInfo[1]
count_b = np.zeros(256,np.float)
count_g = np.zeros(256,np.float)
count_r = np.zeros(256,np.float)
for i in range(0,height):
for j in range(0,width):
(b,g,r) = img[i,j]
index_b = int(b)
index_g = int(g)
index_r = int(r)
count_b[index_b] = count_b[index_b]+1
count_g[index_g] = count_g[index_g]+1
count_r[index_r] = count_r[index_r]+1
for i in range(0,256):
count_b[i] = count_b[i]/(height*width)
count_g[i] = count_g[i]/(height*width)
count_r[i] = count_r[i]/(height*width)
x = np.linspace(0,255,256)
y1 = count_b
plt.figure()
plt.bar(x,y1,0.9,alpha=1,color='b')
y2 = count_g
plt.figure()
plt.bar(x,y2,0.9,alpha=1,color='g')
y3 = count_r
plt.figure()
plt.bar(x,y3,0.9,alpha=1,color='r')
plt.show()
cv2.waitKey(0)

3.15灰度直方图均衡化源码分析
①累计概率的概念:假设直方图灰度等级1出现的概率是0.2,2出现的概率是0.3,3出现的概率是0.1,则1的累计概率是0.2,2的累计概率是0.2+0.3=0.5,3的累计概率是0.2+0.3+0.1=0.6。
假设256个灰度等级中,100的累计概率为0.5,则255*0.5=new的值作为映射的新的值
import cv2
import numpy as np
img = cv2.imread('E:\\pictures\\image0.jpg',1)
imgInfo = img.shape
height = imgInfo[0]
width = imgInfo[1]
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
cv2.imshow('src',gray)
count = np.zeros(256,np.float) #表示每个像素值在每个灰度等级下出现的概率,256个等级
for i in range(0,height):
for j in range(0,width):
pixel = gray[i,j] #获取每个灰度等级的像素
index = int(pixel) #转为int类型
count[index] = count[index]+1
for i in range(0,255): #每个灰度等级出现的概率
#分子是count,分母是所有的像素
count[i] = count[i]/(height*width)
#计算累计概率
sum1 = float(0)
for i in range(0,256):
sum1 = sum1 + count[i]
count[i] = sum1
#计算映射表
map1 = np.zeros(256,np.uint16)
for i in range(0,256):
map1[i] = np.uint16(count[i]*255)
#映射
for i in range(0,height):
for j in range(0,width):
pixel = gray[i,j]
gray[i,j] = map1[pixel]
cv2.imshow('dst',gray)
cv2.waitKey(0)
输出:

3.16彩色图像直方图均衡化源码分析
PS:和上节的代码差不多,灰度图是一个通道,彩色图是三个通道
import cv2
import numpy as np
img = cv2.imread('E:\\pictures\\image0.jpg',1)
imgInfo = img.shape
height = imgInfo[0]
width = imgInfo[1]
cv2.imshow('src',img)
count_b = np.zeros(256,np.float)
count_g = np.zeros(256,np.float)
count_r = np.zeros(256,np.float)
for i in range(0,height):
for j in range(0,width):
(b,g,r) = img[i,j]
index_b = int(b)
index_g = int(g)
index_r = int(r)
count_b[index_b] = count_b[index_b]+1
count_g[index_g] = count_g[index_g] + 1
count_r[index_r] = count_r[index_r] + 1
for i in range(0,255):
#分子是count,分母是所有的像素
count_b[i] = count_b[i]/(height*width)
count_g[i] = count_g[i] / (height * width)
count_r[i] = count_r[i] / (height * width)
#计算累计概率
sum_b = float(0)
sum_g = float(0)
sum_r = float(0)
for i in range(0,256):
sum_b = sum_b + count_b[i]
sum_g = sum_g + count_g[i]
sum_r = sum_r + count_r[i]
count_b[i] = sum_b
count_g[i] = sum_g
count_r[i] = sum_r
#计算映射表
map_b = np.zeros(256,np.uint16)
map_g = np.zeros(256,np.uint16)
map_r = np.zeros(256,np.uint16)
for i in range(0,256):
map_b[i] = np.uint16(count_b[i]*255)
map_g[i] = np.uint16(count_b[i] * 255)
map_r[i] = np.uint16(count_b[i] * 255)
#映射
dst = np.zeros((height,width,3),np.uint8)
for i in range(0,height):
for j in range(0,width):
(b,g,r) = img[i,j]
b = map_b[b]
g = map_b[g]
r = map_b[r]
dst[i,j] = (b,g,r)
cv2.imshow('dst',dst)
cv2.waitKey(0)
输出:

3.17亮度增强
原理:将每个像素点三通道的像素值增加,即p = p + 40
import cv2
import numpy as np
img = cv2.imread('E:\\pictures\\image0.jpg',1)
imgInfo = img.shape
height = imgInfo[0]
width = imgInfo[1]
cv2.imshow('src',img)
dst = np.zeros((height,width,3),np.uint8)
for i in range(0,height):
for j in range(0,width):
(b,g,r) = img[i,j]
bb = int(b)+40
gg = int(g)+40
rr = int(r)+40
if bb>255:
bb = 255
if gg>255:
gg = 255
if rr>255:
rr = 255
dst[i,j] = (bb,gg,rr)
cv2.imshow('dst',dst)
cv2.waitKey(0)
输出:

3.18磨皮美白
API:bilateralFilter 双边滤波
import cv2
img = cv2.imread('E:\\pictures\\image1.png',1)
dst = cv2.bilateralFilter(img,15,35,35)
cv2.imshow('src',img)
cv2.imshow('dst',dst)
cv2.waitKey(0)
输出:

3.19高斯均值滤波
API:GaussianBlur 高斯均值滤波
#调用API
import cv2
img = cv2.imread('E:\\pictures\\image0.JPG',1)
cv2.imshow('src',img)
dst = cv2.GaussianBlur(img,(5,5),1.5)
cv2.imshow('dst',dst)
cv2.waitKey(0)
# 源码分析
import cv2
import numpy as np
img = cv2.imread('E:\\pictures\\image0.JPG', 1)
imgInfo = img.shape
height = imgInfo[0]
width = imgInfo[1]
dst = np.zeros((height,width,3),np.uint8)
for i in range(3,height-3):
for j in range(3,width-3):
sum_b = int(0)
sum_g = int(0)
sum_r = int(0)
for m in range(-3,3):#-3 -2 -1 0 1 2
for n in range(-3,3):
(b,g,r) = img[i+m,j+n]
sum_b = sum_b+int(b)
sum_g = sum_g+int(g)
sum_r = sum_r+int(r)
b = np.uint8(sum_b/36)
g = np.uint8(sum_g/36)
r = np.uint8(sum_r/36)
dst[i,j] = (b,g,r)
cv2.imshow('dst',dst)
cv2.waitKey(0)
3.20中值滤波
#源码分析
import cv2
import numpy as np
img = cv2.imread('image11.jpg',1)
imgInfo = img.shape
height = imgInfo[0]
width = imgInfo[1]
img = cv2.cvtColor(img,cv2.COLOR_RGB2GRAY)
cv2.imshow('src',img)
dst = np.zeros((height,width,3),np.uint8)
collect = np.zeros(9,np.uint8)
for i in range(1,height-1):
for j in range(1,width-1):
k = 0
for m in range(-1,2):
for n in range(-1,2):
gray = img[i+m,j+n]
collect[k] = gray
k = k+1
# 0 1 2 3 4 5 6 7 8
# 1
for k in range(0,9):
p1 = collect[k]
for t in range(k+1,9):
if p1<collect[t]:
mid = collect[t]
collect[t] = p1
p1 = mid
dst[i,j] = collect[4]
cv2.imshow('dst',dst)
cv2.waitKey(0)