【kg推荐->精读】Differentiable Sampling on Knowledge Graph for Recommendation with Relational GNN
DSKReG
Abstract
出现冷启动问题时,将KGs作为side information可以缓解这一问题。
问题:node degrees是倾斜(skewed)的;KGs中大量交互是推荐无关的。
解决:本文提出一种基于知识图谱的 可微抽样 推荐方法。
- 设计了一种可微分抽样策略,使相关项目的选择与模型训练过程共同优化。
关键词
- Collaborative filtering
- Recommender Systems
- Knowledge Graph
- Graph Neural Network
1 Introduction
协同过滤是利用用户、物品的交互信息进行推荐的,但是存在冷启动问题。因此有些工作[1, 19, 22]将KGs作为side information**[11]**,通过 中间实体 在item之间提供额外的语义,从而从item的角度缓解冷启动问题。
笔记:KG作为side information,可以缓解冷启动问题
Q1. kg作为side information?先驱,需要看。✅
[1, 19, 22] [11]
一些方法。
- aggregating relevant interactions—[5,22]
- GNN, information aggregation—[6,9,13,17,26]
- aggregate entities in KGs to infer item embeddings—KGCN
- KGNN-LS
- KGAT[22]
- ATBRG[5]
尽管现在方法很有效,但是有2个局限性:
- node degree skewness
- noisy interactions
Node degree skewness指edges和nodes成幂律分布[2]。
- 一方面,nodes数量多,degrees低,neighbors不足,需要多层GNN聚合来接收高阶信息[22]✅。
- 另一方面,高degrees的nodes的高阶聚合导致其感受野呈指数增长[29],因此存在过度平滑问题[10, 16]。
noisy interactions指KG中存在大量与推荐无关的交互[5 ATBRG]。
- 现有方法通过聚集所有连接实体 推断 item embeddings。
- 然而,直接聚合这些不相关的实体没用,甚至增加了计算成本,从而降低性能。
为了解决这些问题,本文采用 基于抽样 的 关系GNN 从KG中提取推荐相关信息。
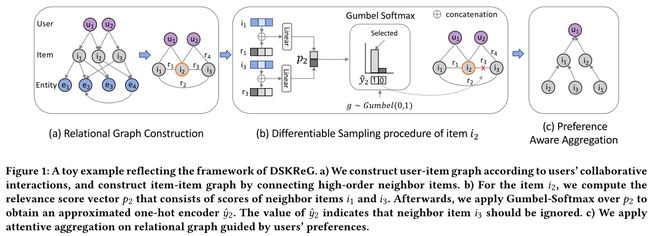
根据中间实体 连接KG中的items,并创建新的关系。如果两部电影由一个共同的导演连接,则创建一个共同导演关系。在图1(a)说明了这个过程,这种关系图构造的灵感源于异构图的工作**[24, 27]**。
Q2. 如何构造关系图的?图1a。模型的一部分,需要看✅
[24(HAN),27] HAN中:在Introduction部分对meta-path的介绍:连接两个对象的composite relation。
- 这样,可以明确地揭示items关系。
- 其次,采用基于抽样的邻居聚合,可以避免邻居数量的指数增长,从而缓解过度平滑问题。
需要设计一种合适的取样方法。
-
在基于KG的推荐中,大多数基于抽样的GNN 使用 邻居的统一抽样[18-20],这无法区分 推荐相关 的关系。
-
此外,先用的采样策略[6, 25, 31, 33]独立于优化过程,这进一步阻碍了端到端的训练方式。
-
RippeNet[18] detachedly地对一组固定大小的邻居进行采样,以infer item embeddings。
-
KGPolicy[25]使用disjoint reinforcement learning agents来发现KG中高质量的反面示例。
它们都将采样过程与训练过程分开,从而产生次优邻居选择。
Q3. 过去的采样方法:
- [18-20],18(RippleNet)√。19、20KGCN 应该是18的进阶(猜测)
- [6, 25, 31, 33],25(KGPolicy)√
过程1
因此,我们提出了一种新的基于知识图谱的**可微分采样(differentiable sampling)**模型,用于关联GNN推荐(DSKReG)。
给定一个item,根据关联关系和node embedding,计算connected items的相关性得分。相关性得分用于抽样前K个相关的邻居items。因此,我们的模型可以根据关系和item类型区分 连接邻居间的 推荐相关的 items。
过程2
我们还将Gumbel Softmax重参数化技巧[8, 28]应用到采样过程中,该技巧类似于类别分布的采样概率,从而使采样过程具有可微性。
因此,采样与训练联合优化,从而享受端到端的时尚。
我们的贡献概括如下:
1)我们根据关系和抽样item类型计算相关度得分,从而可以指导模型选择推荐相关的项目。
2)我们设计了一种可微分采样策略,使模型能够结合模型优化来改善采样过程。
3)我们在三个公共数据集上进行了实验,并证明了模型的有效性。
2 Our Approach
在本节中,我们首先阐述了**知识感知推荐(knowledge-aware recommendation)**的问题。然后,我们提出DSKReG框架,如图1所示。
2.1 Problem Definition
knowledge-aware recommendation的目标:预测用户u是否读物品v感兴趣,在给定历史交互和KG下。
- 形式上,一组用户 U \mathcal{U} U,一组物品 V \mathcal{V} V的历史交互 被表示为 用户-物品二部图 G Y = { ( u , y u v , v ) ∣ u ∈ U , v ∈ V } \mathcal{G}_{\mathrm{Y}}=\left\{\left(u, y_{u v}, v\right) \mid u \in \mathcal{U}, v \in \mathcal{V}\right\} GY={(u,yuv,v)∣u∈U,v∈V},其中 y u v = 1 y_{u v}=1 yuv=1表示用户u对物品v有过点击、购买等操作。KG包含item related properties,比如类型、导演和电影演员。
- 我们将KG形式化为异构图, G K = { ( h , r , t ) ∣ h , t ∈ E , r ∈ R } \mathcal{G}_{\mathbf{K}}=\{(h, r, t) \mid h, t \in \mathcal{E}, r \in \mathcal{R}\} GK={(h,r,t)∣h,t∈E,r∈R},例如(James Cameron, isdirectorof, Titanic),其中 E \mathcal{E} E和 R \mathcal{R} R表示实体集和关系集。
因此,knowledge-aware recommendation可以形式化为:
y ^ u v = F ( u , v ∣ Θ , G Y , G K ) , (1) \hat{y}_{u v}=\mathcal{F}\left(u, v \mid \Theta, \mathcal{G}_{\mathbf{Y}}, \mathcal{G}_{\mathbf{K}}\right), \tag{1} y^uv=F(u,v∣Θ,GY,GK),(1)
其中 y ^ u v \hat{y}_{u v} y^uv是用户对物品v的兴趣的预测, F \mathcal{F} F是学到的预测函数, Θ \Theta Θ是函数的权重。
2.2 Relational Neighborhood Construction
node degree skewness限制了KG中 连接稀缺的item的 可用邻居items池。
我们提出了“co-interact”模式来建立高阶的item-item关系,以缩短相关items之间的路径距离。直觉上,这些co-interact模式对推荐很重要。
例如用户可能对同一个作者的书感兴趣。我们从输入KG G K \mathcal{G}_{\mathbf{K}} GK提取co-interact模式,同时用 一组新的co-relations集,构造一个item-item的co-interact无向图 G c o \mathcal{G}_{\mathrm{co}} Gco,定义如下:
G c o = { ( i 1 , r ′ , i 2 ) ∣ if ( i 1 , r , t ) ∈ G K and ( i 2 , r , t ) ∈ G K } , (2) \mathcal{G}_{\mathrm{co}}=\left\{\left(i_1, r^{\prime}, i_2\right) \mid \text { if }\left(i_1, r, t\right) \in \mathcal{G}_{\mathbf{K}} \text { and }\left(i_2, r, t\right) \in \mathcal{G}_{\mathbf{K}}\right\}, \tag{2} Gco={(i1,r′,i2)∣ if (i1,r,t)∈GK and (i2,r,t)∈GK},(2)
其中 r ′ r^{\prime} r′表示新的“co-r”关系。跟着这些关系的导航,我们连接有co-interact模式的items,同时构造item-item图,如图1(a)。
这样,我们可以直接连接高阶邻居,避免感受野的指数增长。我们将user-item二部图 G Y \mathcal{G}_{\mathrm{Y}} GY和item-item co-interact图 G c o \mathcal{G}_{\mathrm{co}} Gco统一为单个图,表示为关系图。这样,我们可以为后续任务考虑用户和items之间的所有这些关系。
2.3 Differentiable Sampling
可微抽样,用于邻居选择(neighbors selection)。
只从item的角度阐述它,用户同理。
- co-interact关系与推荐的相关性 因用户而不同。例如,同一类型的电影比联合导演的影响更大。
- co-interact的关系是不平衡的。例如,共同指导者的item-item对 比 同一类别的项目 少的多。
这带来一个问题,当潜在邻居池很大,高度相关的邻居数量减少。[19, 20]采用相同的采样技术,仍然无法解决这个问题。
为了滤除噪声,保留真正相关的信息,本文采用relation-aware采样方法,该方法从关系(relation)的角度分配权值,如图1(b)。
抽样过程先为每一个item定义一个新的relation-aware相关性分数分布,然后从中进行抽样。对于item i 和它的co-related邻居 N ( i ) \mathcal{N}(i) N(i),relation-aware相关性分数分布的定义如下:
p ( v i , j = 1 ∣ w , b ) = exp ( w [ r i j ∥ e j ] + b ) ∑ m ∈ N ( i ) exp ( w [ r i m ∥ e m ] + b ) (3) p\left(v_{i, j}=1 \mid \mathbf{w}, b\right)=\frac{\exp \left(\mathbf{w}\left[\mathbf{r}_{i j} \| \mathbf{e}_j\right]+b\right)}{\sum_{m \in \mathcal{N}(i)} \exp \left(\mathbf{w}\left[\mathbf{r}_{i m} \| \mathbf{e}_m\right]+b\right)} \tag{3} p(vi,j=1∣w,b)=∑m∈N(i)exp(w[rim∥em]+b)exp(w[rij∥ej]+b)(3)
其中 p ( v i , j = 1 ∣ w , b ) p\left(v_{i, j}=1 \mid \mathbf{w}, b\right) p(vi,j=1∣w,b)表示item j与目标item i相关的可能性;w b是可学习的weight和bias;r ij和e j是关系的embedding和邻居item的embedding,d是embedding的维度。(自己的理解:最后一层套的是softmax)
简单理解应该是:关系embedding*邻居物品embedding,做softmax
co-relation和邻居item共同决定它的相邻关联概率(neighbor relevance probability)。
我们对用户应用相同的相关性计算过程。
(这里记得看图1b的小例子):b) 对于item i2,我们计算相关性得分向量 p2,由相邻item i1和i3的分数组成。之后,我们将Gumbel-Softmax应用于 p2 以获得一个近似one-hot的encoder y ^ 2 \hat{y}_2 y^2,它表示邻居item 3应该被忽略。
给定计算出的相关性分布,我们选择top-K最相关的items。以往[5]选择和优化过程是独立的,推荐的表现很大程度上取决于选择的结果。
为了让该过程可微分,并与优化结合,我们应用了Gumbel-Softmax重参数化技巧。
![]()
Gumbel公式balabala
Q4. 什么是Gumbel-Softmax?
[8]
解决了不可导、不具有随机性的问题。https://blog.csdn.net/u011345885/article/details/122610352
利用以上方法,我们可以获得top-K相关items。
2.4 Preference Aware Aggregation
还应该考虑user preference in the top-K neighbor messages propagation process。不同的用户可能对各种关系有不同的偏好,应该在聚合中考虑这些关系。,如图1©。
用于获得item i的embedding:( ϕ i j \phi_{ij} ϕij的使用与KGCN模型相似)

a ij表示item j是否被选为item i的邻居,e u是用户的embedding。
获得user u的embedding也是同理,但注意是使用connected item embeddings来计算的。
Q5. 如何聚合aggregation?
可能有帮助
- GNN, information aggregation—[6,9,13,17,26]
- aggregate entities in KGs to infer item embeddings—KGCN
2.5 Predicton and Optimization
- dot-product
e ^ u \hat{e}_u e^u,推断的user embedding; e ^ i \hat{e}_i e^i,推断的item embedding。
![]()
- BPR loss[15]
triplets (u, i, j) (用户,交互过的item,从未交互过的item)

3 Experiments
3.1 Experimental Settings
数据集
- Last.FM
- BookCrossing
- MovieLens-Sub
表2提供了统计数据。
基线
- KGAT
- KTNN-SX
- RippleNet
- knowledge embedding based method CFKG
3.2 Results

关注Recall,Precision,NDCG。
模型显著提高了NDCG。
3.3 Ablation Study(消融实验)
- 针对Relation-aware Sampling
四种策略:
- Uniform,随机
- L2。L2-norm
- Inner,内积
- GS,Gunmel-Softmax
- 针对Sampling Size
8个。
4 Conclusion
本文提出了一个新的框架DSKReG。
- 减轻节点度偏斜(the node degree skewness)和噪声交互(noisy interactions)问题。
- 它是基于抽样的关系GNN。
- 提出了可微的抽样策略,与模型训练同步优化。
在三个数据集(Last.FM, BookCrossing, MovieLens-Sub)上,证明了有效性。
我的总结/疑问
Q1. kg作为side information?先驱,需要看
Q2. 如何构造关系图的?图1a。模型的一部分,需要看
Q3. 过去的采样方法:
Q4. 什么是Gumbel-Softmax?
Q5. 如何聚合aggregation?
Q6. 什么是KG?