新手炼丹师的调参内经——深度学习涨点技巧总结
新手炼丹师的调参内经——深度学习涨点技巧总结
训练神经网络的过程就像是一个炼丹的过程,各位炼丹师们除了要设计一个好的丹方(Contribution),配置好的炼丹炉(GPU Server),当然这其中也不能够忽略对火候(Tricks)的掌控。就像一个一品丹药,由九品炼药师和五品炼药师分别在相同的炼丹炉里面炼制,炼制出来的成丹效果肯定也是天差地别,而导致这种差别的最主要原因就是两位炼药师之间经验的差别。设计一个好的丹方这没有什么好说的,就是各位炼药师多读paper,再充分发挥自己的想象力,不断试错,最终成功的过程。炼丹炉一言蔽之就是
Money is all you need!。所以,可以去人为控制且方便有效的炼丹三件套之一就是火候。这也正是博主写这篇博客的原因,作为一个新手炼丹师,希望和大家分享一下我自己的炼丹经验。
文章目录
- 新手炼丹师的调参内经——深度学习涨点技巧总结
-
- 1. Introduction
- 2. 准备工作
-
- 2.1 合并训练集与测试集
- 2.2 交叉验证
- 3. 数据处理
-
- 3.1 数据筛选
- 3.2 数据归一化和增强
- 4. 基本超参数
-
- 4.1 学习率(Learning Rate)
- 4.2 批次大小(Batch Size)
- 5. 网络结构
-
- 5.1 BatchNorm
- 5.2 Dropout
- 6. 权重初始化
- 7. 优化器(Optimizer)
- 8. 学习率策略(Scheduler)
- 9. 训练策略
- Summary
- Reference
1. Introduction
这篇博客将一个从准备到成丹的完整过程按顺序拆分为:准备工作、数据处理、基本超参数、网络结构、权重初始化策略、优化器(optimizer)、学习率策略(scheduler)、训练策略这八个大的板块,再对这些板块分别进行详细地讲解。PS:本博客涉及到的技术细节均基于Pytorch1.6,且都是vision领域的
2. 准备工作
准备工作的目的就是高效筛选丹方。可能大家都碰到过这样一种情况,那就是好不容易想出来一个自己觉得非常make sense的idea,然后就开始使劲调参数,调到最后发现这个方法根本行不通,这样既浪费了时间还没有任何效果,特别是在面对大数据集的时候,训练个一次就要个几周那时间成本就会更加昂贵。所以,博主在这里介绍两种高效筛选丹方的技巧:
2.1 合并训练集与测试集
这个方法是博主最推荐的办法,在能够拿得到测试集的前提下(一般不打比赛,大部分的research应该都是能直接拿到测试集的),可以使用ConcatDataset将训练集和测试集合并起来训练,按照baseline的训练流程训练,看看自己的网络能不能过拟合,这个时候只需要稍微尝试调整一下学习率,如果不论怎么调整学习率都无法过拟合的话,建议可以直接放弃这个丹方。
2.2 交叉验证
这类方法就是适用于无法拿到测试集的情况下,将训练集分成k折,然后用k-1分训练,1分测试。这样轮询训练,如果效果不错的情况下就基本认为丹方没有大问题,就可以进行后续的进一步试验。详细的交叉验证训练流程可以参考K-Fold 交叉验证 (Cross-Validation)的理解与应用。
3. 数据处理
3.1 数据筛选
这项工作是一个比较耗时耗力的工作,这类数据一般会分成两类:错误数据和噪声数据。
错误数据就是读取就会报错的数据,例如ImageNet里面可能有些图像读取的时候会报raise IOError("image file is truncated ")错误,这就意味着这周图像后面的bytes编码有点问题。这时候你可以选择加入这两行代码
from PIL import ImageFile
ImageFile.LOAD_TRUNCATED_IMAGES = True
强行读取被截断的图像,不过读入的图像有可能就是这样的(图像来源)。也可以直接从数据集中删除这些错误图像:

噪声数据的处理就较为麻烦,这类数据只能通过人工查看后矫正,建议一般放在最后作为精度冲刺的手段,只要噪声数据不是很多,在可以接受的范围之内,还是建议多考虑一些抗噪的方法,而不是人工矫正。
3.2 数据归一化和增强
torchvision.transforms提供了数据归一化和增强的操作,transforms.Normalize(mean, std)可以很轻松地实现数据的归一化操作,至于为什么归一化可以加速网络收敛可以参考我的另一篇博客第二章: 多变量线性回归。
数据增强包括了旋转、翻转、裁剪、颜色抖动等等操作,不同的task有效的数据增强方式一般不同,博主的建议是可以自己花时间做小实验去尝试哪种数据增强对你自己的task有效。这里推荐一篇中文的博客,有结果图像也有代码实例:二十二种 transforms 图片数据预处理方法。当然还是需要去看看官网的API torchvision.transforms,这里面有最新的变换操作和每个参数的讲解。
4. 基本超参数
4.1 学习率(Learning Rate)
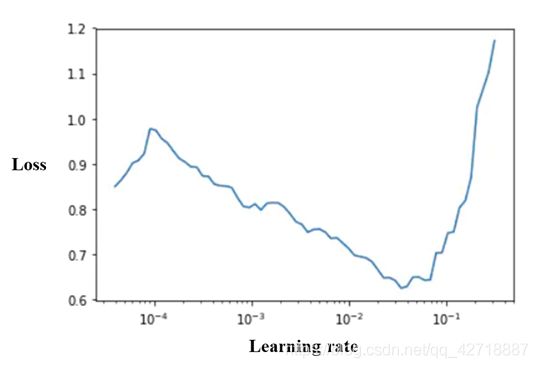
学习率作为炼丹过程中一个非常非常非常重要的超参数,在很多情况之下都是各位炼丹师调参的首选目标。这里博主推荐一种fastai的lr_find()函数寻找合适的初始学习率的方法。如上图所示,可以首先确定一个初始学习率的尝试范围(一般baseline的论文中都可以比较容易找到),然后改变学习率并绘制出固定Steps之后平均损失与学习率之间的统计图,这种图一般会呈现出一个对钩,所以我们只需要选择曲线的最低点对应的学习率作为初始学习率即可。
推荐参考fastai的首席设计师Sylvain Gugger的一篇博客How Do You Find A Good Learning Rate(上图来源)。
4.2 批次大小(Batch Size)
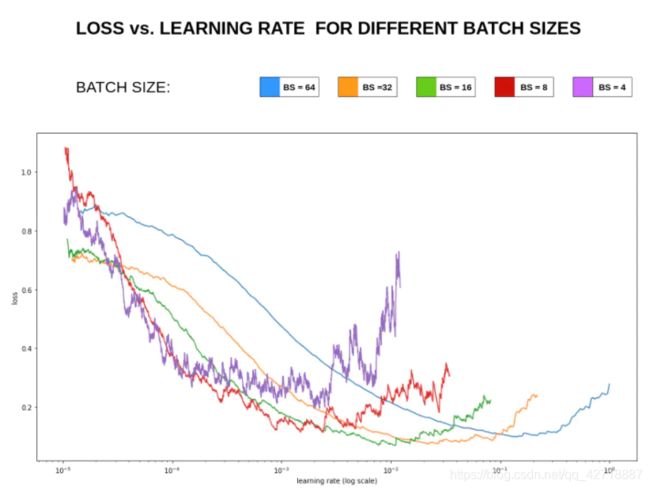
上图来源Visualizing Learning rate vs Batch size。批次大小作为两个基本超参数之一,对于网络模型训练的性能也有着十分重要的影响。特别是在contrastive learning和metric learning两个领域,这个超参数往往越大越好,可能会给模型性能带了巨大的提升。越大的batch size意味着我们学习的时候,收敛方向的confidence越大,我们前进的方向更加坚定,而小的batch size,在更新的时候则显得比较杂乱,所以需要小的学习率来保证不至于出错。所以这里给出一个经验公式(参考了MoCov3):
l r ′ = b s ′ b s × l r lr' = \frac{bs'}{bs} \times lr lr′=bsbs′×lr
其中 l r ′ lr' lr′和 b s ′ bs' bs′是新的学习率和批次大小, l r lr lr和 b s bs bs是之前寻找到的最优学习率和批次大小。
5. 网络结构
5.1 BatchNorm
BN层作为涨点利器,现在已经作为卷积神经网络的标配模块了。不过它对batch size有较高要求,因为batch size较小的话难以得到一个较好的统计估计,不同的任务对于batch size的要求不一样(一般数据集越大要求batch size越大,因为数据集越大也就代表着图片与图片之间的差异越大,需要更大的batch size才能得到一个较好的均值与方差的估计),在不使用SyncBN的情况之下,一般对于那些比较吃显卡的任务,至少要求每张卡BN前向传播的bs ≥ \geq ≥ 10。
还是拿metric learning举例子,如果source domain和target domain之间的域差异过大,建议使用不共享参数的孪生神经网络。因为,如果使用共享参数的网络,BN难以估计到一个对于source domain和target domain都较为合适的均值与方差。
BN可以接受更大的lr,按照pytorch官网在ImageNet上训练的例子和我自己的试验经验,一般有BN的网络可以接受比没有BN的网络大10倍左右的学习率。
5.2 Dropout
Dropout类似于bagging ensemble减少variance,一般适合于全连接层部分,而卷积层由于其参数并不是很多,所以不需要dropout,加上的话对模型的泛化能力并没有太大的影响。
6. 权重初始化
权重初始化相比于其他的技巧来说使用的并不是特别频繁,因为大家现在搞research很多都用的是pretrained的模型。不过这里博主还是介绍一下三种比较常用的初始化方法,用于初始化自己设计的模型:
- kaiming_normal/uniform_:kaiming_uniform_是Pytorch的Linear与Conv层的默认初始化函数,这个初始化函数适合leaky_relu和relu这一系列的激活函数。
- xavier_normal/uniform_:这个初始化函数适合以前的tanh, sigmoid这一类的激活函数。
- truncated_normal:个人感觉比较适合小数据集,有些task会比上面两个好一点,不过一般还是首推上面两个,在Pytorch官网没有提供高层的封装,这里博主贴出自己的实现代码:
from torch.nn import init
@torch.no_grad()
def _reset_parameters(self):
mean = 0.0
std = 0.005
torch.clamp_(init.normal_(self.w1), mean-2*std, mean+2*std)
torch.clamp_(init.normal_(self.w2), mean-2*std, mean+2*std)
init.constant_(self.b1, 0.001)
init.constant_(self.b2, 0.001)
7. 优化器(Optimizer)
-
Adam及其一堆的变体:对学习率不敏感,就算初始化学习率设置的不够好还是有较好的结果;收敛速度快,不过容易陷入sharp local minimum,建议小数据集和快速试验的时候使用。
-
SGD+momentum:对学习率很敏感,使用它的时候一定要精调学习率,影响非常大;收敛速度较慢,往往需要更多的epochs才能达到较好的结果,不过这个优化器上限往往更高,适合那种大数据集刷点。
8. 学习率策略(Scheduler)
学习率策略也是炼丹之中十分重要的一个小组件,这里列举一些常用的策略进行说明,要想了解更多可以去看看Pytorch的官网说明:
- ReduceLROnPlateau:当监控的指标不发生变化的时候去调整学习率,这个策略就比较符合人类的直观感受,就是loss下不去了,我就把学习率降一点。
- Linear Decay:这是一个比较万金油的衰减策略,适合很多任务,不过Pytorch官方没有提供高层封装,需要自己用LambdaLR去实现,这里贴出博主自己的实现:
epochs = 100
scheduler = LambdaLR(optimizer, lambda epoch: 1.0-epoch/epochs)
-
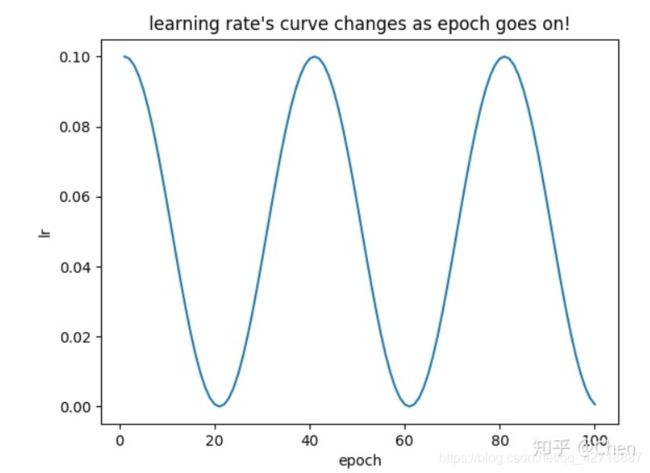
CosineAnnealingLR & CosineAnnealingWarmRestarts:分类问题用的挺多的,周期性地调整学习率,这种退火操作可以有效地防止网络陷入局部最优。下图来源
-
StepLR & MultiStepLR:通过设置里程碑,当epoch到达里程碑之后调整学习率。博主研究的领域就是metric learning之下的一个小方向,使用StepLR效果较好。一般就是在总Epochs的 3 4 \frac{3}{4} 43之时,将学习率调整为原来的 1 10 \frac{1}{10} 101。
9. 训练策略
- 混合精度训练:以前大家使用混合精度训练一般是用apex这个库,而Pytorch1.6开始原生支持混合精度训练,使用混合精度训练大约能节省 1 3 \frac{1}{3} 31的显存占用,也就是你可以使用更大的batch size去提升网络性能和加速网络训练。涉及到的核心概念GradScaler和autocast,注释上面都有解释,个人推荐使用Pytorch原生的混合精度训练,这里贴出训练示例:
# Creates a GradScaler once at the beginning of training.
# Creates model and optimizer in default precision
model = Net().cuda()
optimizer = optim.SGD(model.parameters(), ...)
# Creates a GradScaler once at the beginning of training.
scaler = GradScaler()
for epoch in epochs:
for input, target in data:
optimizer.zero_grad()
# Runs the forward pass with autocasting.
with autocast():
output = model(input)
loss = loss_fn(output, target)
# Scales loss. Calls backward() on scaled loss to create scaled gradients.
# Backward passes under autocast are not recommended.
# Backward ops run in the same dtype autocast chose for corresponding forward ops.
scaler.scale(loss).backward()
# scaler.step() first unscales the gradients of the optimizer's assigned params.
# If these gradients do not contain infs or NaNs, optimizer.step() is then called,
# otherwise, optimizer.step() is skipped.
scaler.step(optimizer)
# Updates the scale for next iteration.
scaler.update()
特别注意: 当你要是用torch.nn.DataParallel和torch.nn.DistributedDataParallel两个并行训练的方式时,一定要在自己模型的forward前面使用@autocast装饰器或者使用autocast上下文管理:
MyModel(nn.Module):
...
@autocast()
def forward(self, input):
...
# Alternatively
MyModel(nn.Module):
...
def forward(self, input):
with autocast():
...
- 差分学习率:差分学习率就是在不同的层设置不同的学习率,可以提高神经网络的训练效果,一般我们使用pretrained模型之后可以将pretrained模型的学习率设置小一点,将自己随机初始化的模型学习率设置大一点。Pytorch的优化器已经考虑到这一点了,所以它支持参数的分组训练:
optim.SGD([
{'params': model.base.parameters()},
{'params': model.classifier.parameters(), 'lr': 1e-2}
], lr=1e-3, momentum=0.9)
-
梯度归一化:即算出来的梯度或者loss除以minibatch size或者某一个常数,让梯度更加稳定,这里可以参考Transformer有关梯度的处理。
-
梯度裁剪: 限制最大梯度范数或者value,当梯度范数或者value大于设定的值之后直接进行裁剪。属于暴力地防止梯度爆炸的出现,建议不到万不得已不要使用,因为这个操作会大大地加长训练时间。pytorch实现这个操作的两个类是torch.nn.utils.clip_grad_norm_()和torch.nn.utils.clip_grad_value_(),从名字就可以看出来这两个是
in-place操作,所以只需要在backward之后,step之前使用裁剪即可:
pred = model(x)
loss = loss_fn(pred, label)
optimizer.zero_grad()
loss.backward()
# gradient clip
nn.utils.clip_grad_norm_(model.parameters(), max_norm=20.)
optimizer.step()
- 梯度累积:初学者可能会很疑惑为什么么Pytorch让用户自己去控制optimizer.zero_grad(),这正是由于Pytorch想让用户可以搞一些骚操作才这样做的。梯度累积就是通过几次前向传播再一次反向传播的操作达到不增加显存占用的情况下,增加batch size的效果,这样做的效果介于不使用梯度累积和直接扩大batch size(加钱)之间,主要原因是使用梯度累积,BN层估计得到的均值和方差还是小batch size得到的,所以效果会比直接增加batch size的效果差。
for i,(images,target) in enumerate(train_loader):
# 1. input output
outputs = model(images)
loss = criterion(outputs,target)
# 2.1 loss regularization
loss = loss/accumulation_steps
# 2.2 back propagation
loss.backward()
# 3. update parameters of net
if((i+1)%accumulation_steps)==0:
# optimizer the net
optimizer.step() # update parameters of net
optimizer.zero_grad() # reset gradient
-
尽量对数据做shuffle:这个对于metric learning的问题尤为重要,因为就是需要不同的example直接进行对比才能训练出较好的模型。
-
weight decay:Pytorch将weight decay作为torch.optim.Optimizer构造器的参数,相当于l2的正则化,一般会设置为1e-4左右,不过不同任务还是有所不同,有些任务不设置weight decay可能效果更好。
-
label smoothing:这也算是一种正则化方法,在蒸馏、分类和检测问题中用的挺多的,可以参考我的这篇博客Self-Knowledge Distillation: A Simple Way for Better Generalization论文阅读
-
hard negative mining:这个就是把难样本放进一个池子里面,模型精度上不去了就开始训练这些难样本,注意这里往往需要将学习率调小一点,两者配合使用进行冲分。
-
Ensemble:是论文和比赛刷结果的终极核武器,就是拿几个不同的模型将每个模型的结果进行平均或者按照某种方式(误差加权、投票、蒸馏等等)融合,往往能涨两三个点。
Summary
欢迎大家和我讨论一起分享自己的炼丹心经!
Reference
- 半天2k赞火爆推特!李飞飞高徒发布33条神经网络训练秘技
- 深度学习调参tricks总结
- Bag of Tricks for Convolutional Neural Networks
- 你有哪些deep learning(rnn、cnn)调参的经验?
- 关于训练神经网路的诸多技巧Tricks(完全总结版)
- 写给新手炼丹师:2021版调参上分手册