Python实现主成分分析法(PCA)+支持向量回归机(SVR)的组合预测
1.导包
import csv
import numpy as np
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
from datetime import datetime
from sklearn.metrics import explained_variance_score
from sklearn.svm import SVR
from sklearn.metrics import mean_squared_error
from sklearn.metrics import accuracy_score
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report
from sklearn.metrics import explained_variance_score
from sklearn import metrics
import random
from sklearn.decomposition import PCA
from sklearn.metrics import mean_absolute_error # 平方绝对误差
2.导数据
#时间
time=[]
#特征
feature=[]
#目标
target=[]
csv_file = csv.reader(open('XJYJSJ.csv'))
for content in csv_file:
content=list(map(float,content))
if len(content)!=0:
feature.append(content[1:11])
target.append(content[0:1])
csv_file = csv.reader(open('XJYJT.csv'))
for content in csv_file:
content=list(map(str,content))
if len(content)!=0:
time.append(content)
targets=[]
for i in target:
targets.append(i[0])
feature.reverse()
targets.reverse()
3.标准化
# 标准化转换
scaler = StandardScaler()
# 训练标准化对象
scaler.fit(feature)
# 转换数据集
feature= scaler.transform(feature)
#str转datetime
time_rel=[]
for i,j in enumerate(time):
time_rel.append(datetime.strptime(j[0],'%Y/%m/%d %H:%M'))
time_rel.reverse()
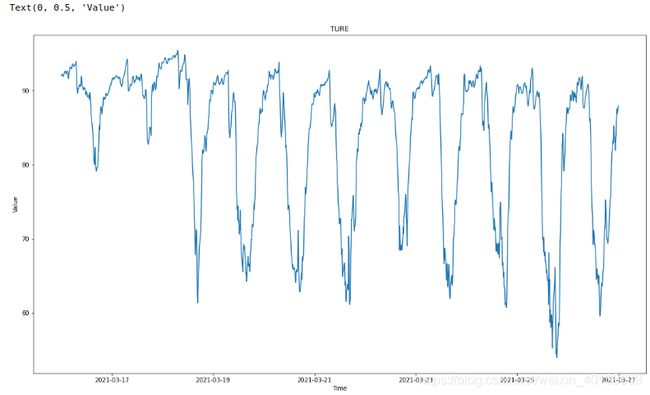
fig = plt.gcf()
fig.set_size_inches(18.5, 10.5)
plt.title('TURE')
plt.plot(time_rel, targets)
plt.xlabel('Time')
plt.ylabel('Value')
4.PCA
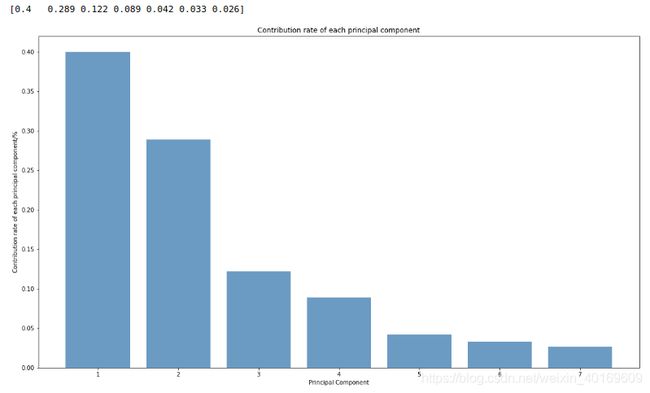
输入所有维度,查看每一个维度的比重。
pca = PCA(n_components=7)
newfeature = pca.fit_transform(feature)
x_data = ['1','2','3','4','5','6','7']
y_data = np.around(pca.explained_variance_ratio_, 3)
# 绘图
plt.bar(x=x_data, height=y_data,color='steelblue', alpha=0.8)
fig = plt.gcf()
fig.set_size_inches(18.5, 10.5)
plt.title("Contribution rate of each principal component")
# 为两条坐标轴设置名称
plt.xlabel("Principal Component")
plt.ylabel("Contribution rate of each principal component/%")
print(np.around(pca.explained_variance_ratio_, 3))
结果如下:
使用前5维,已经可以占比将近95%。
5.降维
使用PCA将数据降到5维,获取新特征。
newfeature =PCA(n_components=5).fit_transform(feature)
6.支持向量回归机(SVR)
PCA—SVR:
feature_train, feature_test, target_train, target_test = train_test_split(newfeature, targets, test_size=0.1,random_state=8)
feature_test=newfeature[int(len(newfeature)*0.9):int(len(newfeature))]
target_test=targets[int(len(targets)*0.9):int(len(targets))]
label_time=time_rel[int(len(time_rel)*0.9):int(len(time_rel))]
model_svr = SVR()
model_svr.fit(feature_train,target_train)
predict_results=model_svr.predict(feature_test)
pcasvr=predict_results
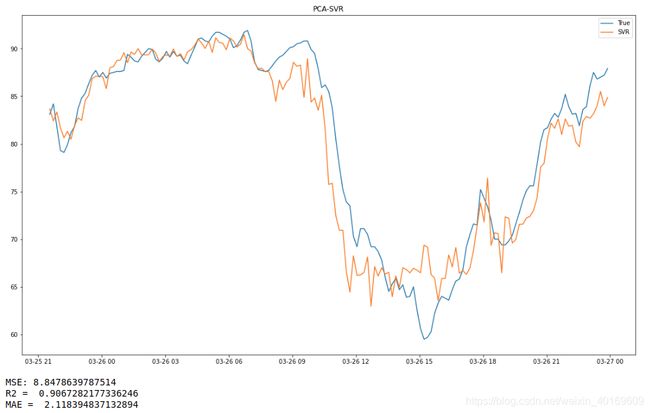
plt.plot(label_time,target_test)#测试数组
plt.plot(label_time,predict_results)#测试数组
plt.legend(['True','SVR'])
fig = plt.gcf()
fig.set_size_inches(18.5, 10.5)
plt.title("SVR") # 标题
plt.show()
print("MSE:",mean_squared_error(target_test,predict_results))
print("R2 = ",metrics.r2_score(target_test,predict_results)) # R2
print("MAE = ",mean_absolute_error(target_test,predict_results)) # R2
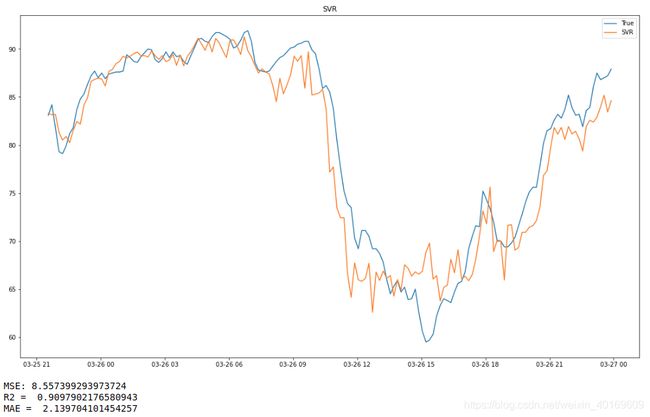
SVR:
feature_train, feature_test, target_train, target_test = train_test_split(feature, targets, test_size=0.1,random_state=8)
feature_test=feature[int(len(feature)*0.9):int(len(feature))]
target_test=targets[int(len(targets)*0.9):int(len(targets))]
label_time=time_rel[int(len(time_rel)*0.9):int(len(time_rel))]
model_svr = SVR()
model_svr.fit(feature_train,target_train)
predict_results=model_svr.predict(feature_test)
SVR=predict_results
plt.plot(label_time,target_test)#测试数组
plt.plot(label_time,predict_results)#测试数组
plt.legend(['True','SVR'])
fig = plt.gcf()
fig.set_size_inches(18.5, 10.5)
plt.title("SVR") # 标题
plt.show()
print("MSE:",mean_squared_error(target_test,predict_results))
print("R2 = ",metrics.r2_score(target_test,predict_results)) # R2
print("MAE = ",mean_absolute_error(target_test,predict_results)) # R2
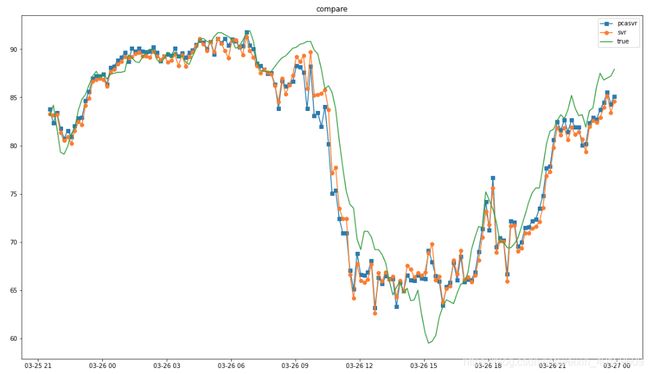
7.对比
plt.plot(label_time,PCASVR,marker='s')#测试数组
plt.plot(label_time,SVR,marker='o')#测试数组
plt.plot(label_time,target_test)#测试数组
plt.legend(['pcasvr','svr','true'])
fig = plt.gcf()
fig.set_size_inches(18.5, 10.5)
plt.title("compare") # 标题
plt.show()