K-means聚类与推荐系统笔记
目录
K-means聚类
监督学习和无监督学习:
means 聚类原理简述
实例演示:
总结:
聚类推荐系统
推荐引擎
协同过滤算法基础的强预设:
基于协同过滤的推荐,又分三个子类:
协同过滤推荐几个要点
聚类推荐
聚类协同过滤推荐的优点:
例:基于用户聚类推荐
几个步骤:
用户聚类
分群热榜统计
聚类结果:
分群热榜统计结果:
在线服务
聚类推荐的优缺点
优点
缺点:
K-means聚类
聚类:事先不知道数据会分为几类,通过聚类分析将数据聚合成几个群体。聚类不需要对数据进行训练和学习。属于无监督学习。
监督学习和无监督学习:
监督学习(supervised learning),其训练样本是带有标记信息的。的目的是:对带有标记的数据集进行模型学习,从而便于对新的样本进行分类。
“无监督学习”(unsupervised learning)中,训练样本的标记信息是未知的,目标是通过对无标记训练样本的学习来揭示数据的内在性质及规律,为进一步的数据分析提供基础。对于无监督学习,应用最广的便是"聚类"(clustering)。
means 聚类原理简述
"聚类算法"试图将数据集中的样本划分为若干个通常是不相交的子集,每个子集称为一个“簇”(cluster),通过这样的划分,每个簇可能对应于一些潜在的概念或类别。
K-Means是聚类算法中的最常用的一种,k表示的是聚类为k个簇,means代表取每一个聚类中数据值的均值作为该簇的质心,即用每一个的类的质心对该簇进行描述。算法最大的特点是简单,好理解,运算速度快,但是一定要在聚类前需要手工指定要分成几类。缺点:可能收敛到局部最小值,在大规模数据上收敛较慢
K-Means 聚类算法的大致思想就是“物以类聚,人以群分”:
- 首先输入 k 的值,即我们指定希望通过聚类得到 k 个簇;
- 从数据集中随机选取 k 个数据点作为初始质心;
- 对集合中每一个样本点,计算与每一个质心的距离,离哪个质心距离近,就跟哪个质心为同一簇;
- 通过算法选出新的质心;
- 如果新质心和老质心之间的距离小于某一个设置的阈值(表示重新计算的质心的位置变化不大,趋于稳定,或者说收敛),可以认为我们进行的聚类已经达到期望的结果,算法终止;如果新质心和老质心距离变化很大,需要迭代3~5步骤。
实例演示:
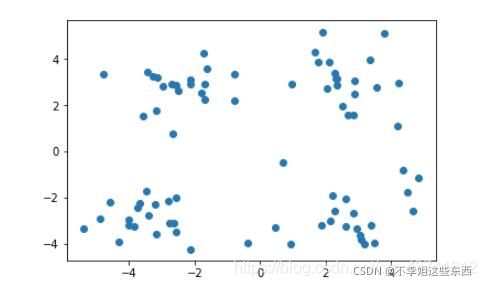
如下图所示,有6个点,从图上看应该可以分成两堆,前三个点一堆,后三个点另一堆。下面把 k-means 计算过程演示一下,同时检验是不是和预期一致:
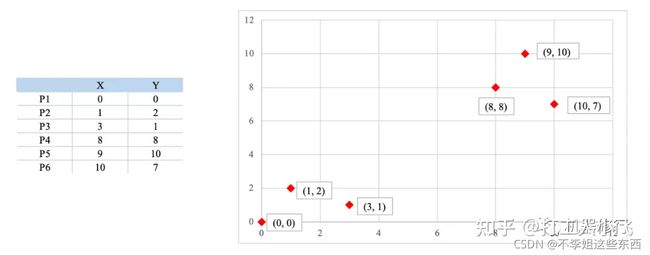
1.设定 k 值为2;
2.选择初始质心(就选 P1 和 P2);
3.计算样本点与质心的距离:
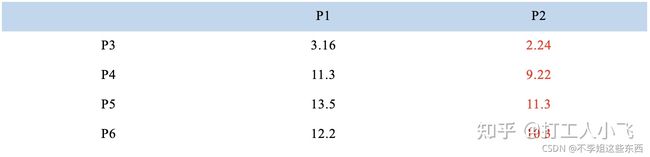
从上图可以看出,所有的样本点都离 P2 更近,所以结果是:
A簇:P1
B簇:P2、P3、P4、P5、P6
4. 计算新质心:
A簇没什么可选的,质心就是自己;
B簇有5个样本点,需要重新选质心,这里要注意选质心的方法是每个样本点X坐标的平均值和Y坐标的平均值组成成的新的质心,也就是说这个质心是“虚拟的”。
因此,B 簇选出新质心的坐标为:P哥((1+3+8+9+10)/5, (2+1+8+10+7)/5)=(6.2, 5.6)。
综合两组,新大哥为 P1(0,0),P哥(6.2,5.6),而P2-P6重新成为样本点。
5. 再次计算样本点到质心的距离:
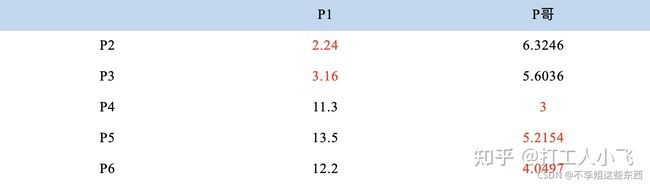
这时可以看到P2、P3离P1更近,P4、P5、P6离P哥更近,所以第二次站队的结果是:
A 簇:P1、P2、P3
B 簇:P4、P5、P6(虚拟大哥这时候消失)
6.第二次计算质心:
同样的方法选出新的虚拟质心:P哥1(1.33,1),P哥2(9,8.33),P1-P6都成为样本点。
7.第三次计算样本点到质心的距离:
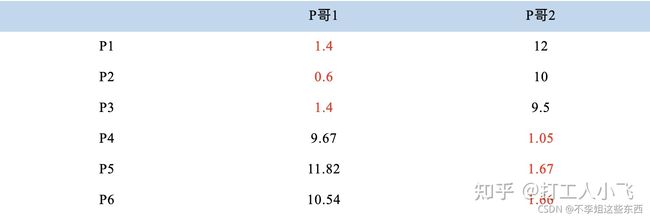
这时可以看到 P1、P2、P3 离 P哥1 更近,P4、P5、P6离 P哥2 更近,所以第二次站队的结果是:
A簇:P1、P2、P3
B簇:P4、P5、P6
我们可以发现,这次站队的结果和上次没有任何变化了,说明已经收敛,聚类结束,聚类结果和我们最开始设想的结果完全一致。
停止计算:质心不再改变,或达到给定最大循环次数
总结:
相似度的计算方法有很多,具体的应用选择合适的相似度计算方法。


K-means算法对初始化敏感,初始质点k给定的不同,可能会产生不同的聚类结果。
为了解决这个问题,可以使用另外一种称为二分K-means的聚类算法。
数据聚类是搭建一个正确数据模型的重要步骤。数据分析应当根据数据的共同点整理信息。然而主要问题是,什么通用性参数可以给出最佳结果,以及什么才能称为“最佳”。
基于质心的聚类\层次聚类\最大期望算法\基于密度的聚类算法(常见的,聚类算法很多很多,大部分流行程度和应用领域有限)
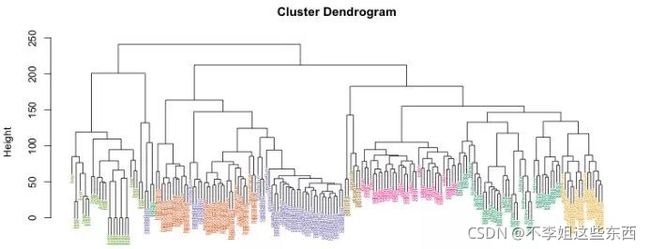
层次聚类
基于整个数据集对象间距离计算的聚类方法,可以从输入所有数据开始,然后将这些数据点组合成越来越大的簇,直到达到极限。层次聚类算法将返回树状图数据,该树状图展示了信息的结构,而不是集群上的具体分类。
聚类推荐系统
推荐引擎
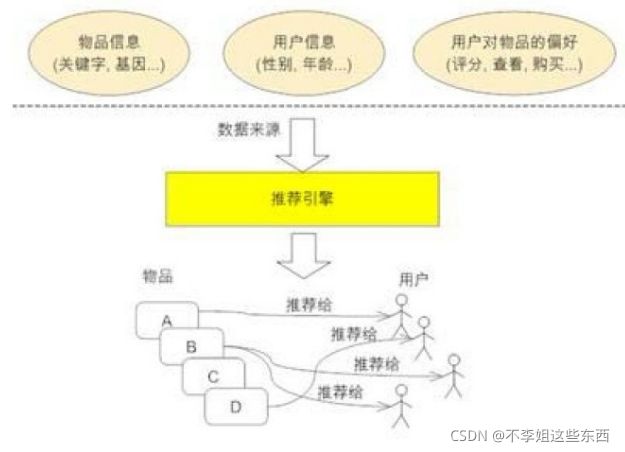
协同过滤算法基础的强预设:
在观测到用户消费过项目A之后,我们有很高的可能性观测到用户会喜欢与A相似的项目B以及相似的用户可能喜欢同一个项目。
所以协同过滤的核心在于描述项目和用户的相似性
基于协同过滤的推荐,又分三个子类:
- 基于用户的推荐(通过共同口味与偏好找相似邻居用户,K-邻居算法,你朋友喜欢,你也可能喜欢),
- 基于项目的推荐(发现物品之间的相似度,推荐类似的物品,你喜欢物品A,C与A相似,可能也喜欢C),
- 基于模型的推荐(基于样本的用户喜好信息构造一个推荐模型,然后根据实时的用户喜好信息预测推荐)。
协同过滤推荐几个要点
1.收集用户偏好
2.处理用户行为数据得到二维矩阵
降噪:剔除用户行为数据的噪音;归一化:将各个行为的数据同意在一个相同的取值范围,从而使得加权求和得到的总体喜好更加精准.
一维是用户列表,另一维是物品列表,值是用户对物品的偏好,[0,1]或[-1,1]
3.找到相似的用户和物品,计算相似用户或相似物品的相似度
相似度计算方法:基于向量,距离越近相似度越大.在推荐中,用户-物品偏好的二维矩阵下,我们将某个或某几个用户对某两个物品的偏好作为一个向量来计算两个物品之间的相似度,或者将两个用户对某个或某几个物品的偏好作为一个向量来计算两个用户之间的相似度。
常见的计算相似度的方法有:欧几里德距离,皮尔逊相关系数Cosine相似度,Tanimoto系数。
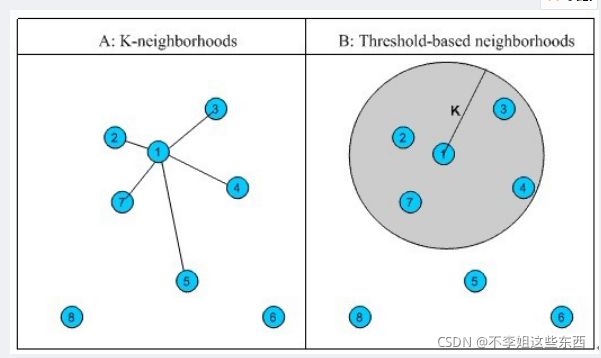
4.相似邻居计算.
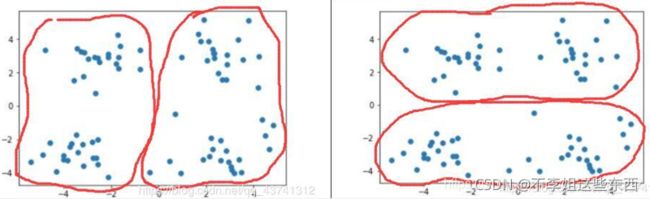
①固定数量的邻居K-neighborhoods(或Fix-sizeneighborhoods),不论邻居的“远近”,只取最近的K个,作为其邻居,如下图A部分所示;
②基于相似度门槛的邻居,落在以当前点为中心,距离为K的区域中的所有点都作为当前点的邻居,如下图B部分所示。
聚类推荐
聚类是分簇,对使用者或项目分簇。所以用直接聚类来做推荐的话,是从聚类得到的分簇中挑一些项目推荐这一类人群.
聚类协同过滤推荐的优点:
如果数据规模非常大,协同过滤中计算KNN(在全局user或item中找K个最近的邻居)是非常耗时的。但如果先对user (或item)做一个聚类,然后在目标user(或item)所属聚类簇中找KNN,可以极大地节省计算开销。
例:基于用户聚类推荐
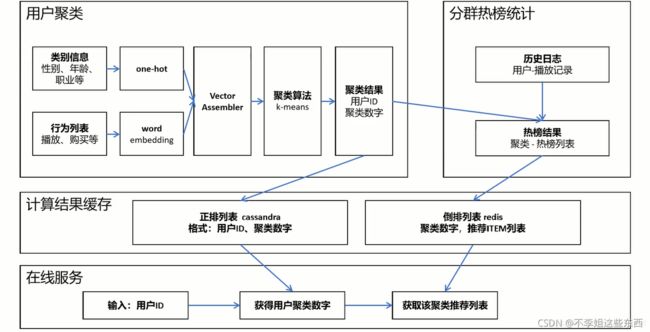
几个步骤:
用户聚类 → 分群热榜统计 → 计算结果缓存 → 在线服务
前两步的结果都会存入到高速缓存,然后在线服务使用缓存进行推荐
用户聚类
类别信息:性别、年龄、职业等等,
特征处理:使用one-hot把类别信息变成0、1的值
行为列表:播放、购买等等,
特征处理:因为时变长的,所以使用embedding的技术,转变成一个定长的密集向量。
embedding:把有序列表输出成定长向量,每一个向量的值是一个数字,这样不同人的行为列表就可以通过向量直接计算相似度。
特征工程之后,把one-hot向量列表和embedding向量列表进行拼接,成一个大的向量列表(Vector Assembler),里面都是数字,把Vector Assembler输出给聚类算法
聚类算法,比如说K-means,是按照距离度量的常见的聚类算法。聚类算法的计算结果是:key是用户ID,value是聚类数字。把计算结果做两个输出,一个缓存到高速缓存中,一个到下一步进行分群热榜统计
分群热榜统计
首先由历史日志,用户-播放记录
收到聚类结果之后,把聚类结果和历史日志通过用户ID进行join,
然后就可以计算每个聚类的热榜结果,格式是:聚类-热榜列表,把热榜结果发给缓存
计算结果缓存
聚类结果:
正排列表,一般使用Cassandra
格式是:用户ID、聚类数字
分群热榜统计结果:
倒排列表,一般使用redis
格式是:聚类数字、推荐Item列表
这两个列表可以通过聚类数字进行关联
在线服务
当用户请求的时候,可以得到用户ID,在缓存中的第一个列表中获取聚类数字,然后在第二个列表中获取推荐列表
这样就实现了得到聚类数字获取推荐列表
聚类推荐的优缺点
优点
实现简单,spark、sklearn均有现成接口,数据结果存储量很小;
可以用于新用户冷启动,使用用户注册信息、从站外获取用户信息,行为列表,做聚类即可个性化推荐
缺点:
精度不高,群体喜欢的内容,并不一定个人喜欢,不够‘个性化