Fully-Convolutional Siamese Network for Object Tracking
Updated on 2018-11-19 10:17:29
Paper: http://www.robots.ox.ac.uk/~vedaldi/assets/pubs/bertinetto16fully.pdf
Code: https://github.com/rafellerc/Pytorch-SiamFC (PyTorch Implementation)
Project Page: https://www.robots.ox.ac.uk/~luca/siamese-fc.html
摘要:任意目标的跟踪问题通常是根据一个物体的外观来构建表观模型.虽然也取得了不错的效果,但是他们这些 online-only approach 限制了模型可以学到的模型的丰富性.最近,已经有几个尝试开始探索深度卷积网络的强大的表达能力(express power).但是,当跟踪目标提前未知时,需要在线的执行 SGD 来适应网络的权重,严重的影响了系统的速度.本文中,我们提出一种基本的跟踪算法,端到端的进行全卷积孪生网络的训练,在 ILSVRC15 video object detection dataset 上进行训练.我们的 tracker 速度超过了实时,尽管看起来很简单,但是仍然在 VOT2015 bechmark 上取得了顶尖的效果.
引言:传统的跟踪算法都是在线的方式学习一个表观模型 (appearance model), 但是,这只是相对简单的学习到了简单的模型.另外一个问题就是,在计算机视觉当中,深度学习的方法已经被广泛的采用,但是由于监督学习的数据和实时要求的约束,基于深度学习的应用并不广泛.几个最近的工作目标在于意图用预先训练的深度卷积网络来客服这个缺陷.这些方法要么采用 shallow methods(如:correlation filters)利用网络的中间表示作为 feature;或者执行 SGD 算法来微调多层网络结构.但是,利用 shallow 的方法并不能充分的发挥 end-to-end 训练的优势,采用 SGD 的方法来微调却无法达到实时的要求.
本文提出一种方法,利用预先 offline 学习的方法,训练一个神经网络来解决 general 相似性学习的问题,这个函数在跟踪的过程中简单的进行评价.本文的核心贡献点就是:这种方法在达到相当结果的同时,速度方面达到实时.特别的,我们利用孪生网络,在一个较大的搜索图像内,来定位 exemplar image.进一步的贡献是:该网络是 fully-convolutional:稠密且有效的 sliding-window evaluation 的方法来计算两个输入的 cross-correlation.
相似性学习的方法已经相对被遗忘,由于跟踪领域并不需要涉及到大量有标签数据集.直至现在,现有的数据集相对而言,仅仅只有几百个标注的 videos.然而,我们相信 ILSVRC dataset 的出现对于物体检测而来使得训练这样一个模型成为可能.而且从 ImageNet 领域转移到 跟踪的benchmark是不同 domain 之间的转换,对于在 ImageNet 上训练,然后在 benchmark 上进行测试,并不存在所谓的不公平。
Deep Similarity learning for tracking .
学习去跟踪任意的物体,我们通过相似性学习的方法来解决。我们利用卷积神经网络来解决相似性函数的学习问题。并且通常用 Siamese architecture 来充当深度卷积网络。

Fully-convolutional Siamese Architecture :
本文提出一种全卷积的孪生网络结构, 我们说一个网络结构是 fully-convolutional,如果与 translation 有关。为了给出更加精确的定义,我们引入 $L_{\tau}$ 来表示转移操作 $(L_{\tau}x)[u] = x[u-\tau]$。
此处引入全卷积的优势在于:候选图像的尺寸不一定非得大小相同。
2.2 Training with large search images
我们才用一种判别的方法,在正负样本对上采用最大似然估计进行训练网络:
$l(y, v) = log(1+exp(-yv))$
其中 v 是单个样本候选对的 real-valued score, $y \in {+1, -1}$ 是其 gt label。我们采用一个样本图像和一个较大的搜索图像 来训练我们的全卷积网络。这将会产生一个得分响应(a map of scores v),可以有效的产生许多 examples。我们定义一个 score map 的损失函数为每一个损失的均值:
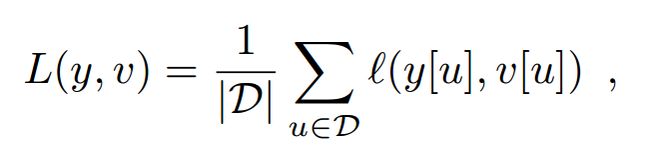
在 score map 上,对于每一个位置 u ,需要一个 真正的label $y[u] \in {+1, -1}$。网络的参数需要通过 SGD 的方法进行训练,解决如下问题:

像图2中所展示的那样,从标注的 video 数据集上,通过提取 exemplar 和 search images 得到的 Pairs,是在 target 中心的。从一个 video 的两帧上得到的 images 包括物体,最多相隔 T 帧。在训练的过程中,不考虑物体的类别。物体的尺寸处理,本文的方法可谓比较合理,像图中所示的那样,对图像进行填充,而不会损失物体尺寸上的信息。

如果 score map 的元素满足如下的条件,则认为该物体属于 positive examples:

在 Score map 上得到的正负样本的损失进行加权以消除类别不平衡的问题。
2.3 ImageNet Video for tracking.
Dataset curation:
本文利用 ImageNet video 进行 offline 的训练。这个数据集有 80多G 标注好的 video。
实际上要先对这些数据进行处理,主要包括:
1. 扔掉一些类别: snake,train,whale,lizard 等,因为这些物体经常仅仅出现身体的某一部分,且常在图像边缘出现;
2. 排除太大 或者 太小的物体;
3. 排除离边界很近的物体。
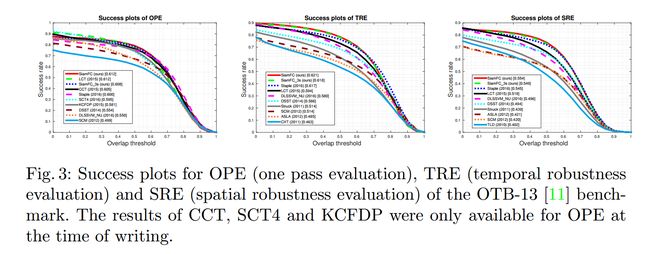
实验结果:
================