论文阅读笔记——Adversarial Attack on Attackers Post-Process to
Adversarial Attack on Attackers: Post-Process to Mitigate Black-Box Score-Based Query Attacks, NIPS 2022
论文相关
paper地址:https://arxiv.org/abs/2205.12134
official code: Sizhe-Chen/AAA: official repository for the NeurIPS 2022 paper “Adversarial Attack on Attackers: Post-Process to Mitigate Black-Box Score-Based Query Attacks” (github.com)
审稿意见:https://openreview.net/forum?id=7hhH95QKKDX
一作的homepage:https://sizhechen.top/
Abstract
提出了一种针对 SQAs 的新型的防御方式——Adversarial Attack on Attackers (AAA), confound the score-based query attacks (SQAs) towards incorrect attack directions by slightly modifying the output logits.
the first post-processing defense
优点:预防了SQAs(effective);CA不掉;改进置信度分数的标准(user-friendly);通用性好;a lightweight defense with a low cost(plug-in defenses)
model calibration can be simultaneously improved via post-processing [31, 32] to output accurate prediction confidence.
Background & Prior works
Query attacks
black-box attacks that only require the model’s output information.
分为两类:score-based query attacks (SQAs)、decision based query attacks (DQAs)
-
SQAs: greedily update AEs from original samples by observing the loss change indicated by DNN’s output scores, i.e., logits or probabilities
SQAs are black-box attacks that find the adversarial direction to update AEs by observing the loss change indicated by DNN’s output scores
-
DQAs: rely only on DNN’s decisions, e.g., the top-1 predictions, to generate AEs. Since DQAs could not perform the greedy update, they start crafting the AE from a different sample and keep DNN’s prediction wrong during the attack
缺点:need thousands of queries to reach a non-trivial attack success rate [44] compared to dozens of times for SQAs ; 而且在现实世界中一般都会输出confidence scores,没必要采用DQAs
Adversarial defense
两个不同的目标:
- improve DNN’s worst-case robustness: demands DNNs to have no AE around clean samples bounded by a norm ball. 最有效的:adversarial training (AT)
- mitigate real-case adversarial threats: the defense performance is evaluated by the feasible and query-efficient SQAs.
见 Limitations of prior works小节
Model calibration
Besides correct predictions, model calibration additionally requires DNNs to produce accurate confidence in their predictions [53]. For instance, exactly 80% of the samples predicted with 80% confidence should be correctly predicted.
评估指标:expected calibration error (ECE)
比较好的方法:temperature scaling [32]
temperature scaling is a simple but effective method [31], which divides all output logits by a single scalar tuned by a validation set so that the ECE intesting samples would be significantly reduced.
Limitations of prior works
Most existing defenses indirectly change outputs by optimizing the model [8, 18, 19] or pre-processing the inputs [14, 20], which, however, severely affect models’ normal performance for different reasons.
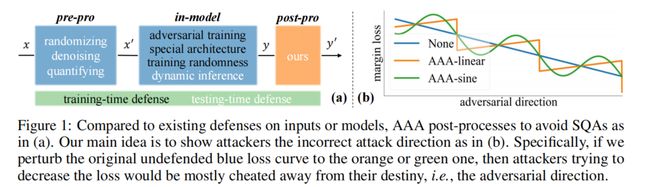
- Training a robust model, e.g., by adversarial training [8, 21], diverts the model’s attention to learning AEs, yielding the so-called accuracy-robustness trade-off
- Randomizing and blurring [20, 27, 28, 29] inputs reduce the signal-noise ratio, inevitably hurdling accurate decision.
- Dynamic inference [19, 30] is time-consuming due to the test-time optimization on model.

Contributions
idea: Since SQAs are black-box attacks that find the adversarial direction to update AEs by observing the loss change indicated by DNN’s output scores, we can perturb such scores directly to fool attackers into incorrect attack tracks.
贡献如下:
- We analyze current defenses from the view of SQA defenders and point out that a post processing module forms not only effective but also user-friendly and plug-in defenses.
- We design a novel adversarial attack on attackers (AAA) defense that fools SQA attackers to incorrect attack directions by slightly perturbing the DNN output scores.
- We conduct comprehensive experiments showing that AAA outperforms the other 8 defenses in the accuracy, calibration, and protection from all tested 6 SQAs under various settings.
limitation: not improve the commonly-studied worst-case robustness
Method
Preliminaries and motivation
SQAs:
For a sample x labelled by y, an SQA on a DNN f generates an AE x’ by minimizing the margin between logits [4, 5, 40, 58] as
![]()
namely the margin loss.
For attackers with label y, it can be known that the attack succeeds if L(f(x), y) < 0. To quickly realize this, SQAs only update AEs if a query x q x_q xq has a lower margin loss compared to the current best query x k x_k xk, i.e.,

贪心的思想
For defenders without the label y, it is possible to calculate the unsupervised margin loss based only on the logits vector z = f(x) as
![]()
by assuming the model prediction y ^ \hat{y} y^ to be correct, since handling originally misclassified samples falls beyond the scope of defense [17].
Adversarial attack on attackers
insights: Now that attackers conduct the adversarial attack on the model, why cannot we defenders actively perform an adversarial attack on attackers? If attackers search for the adversarial direction by scores, we can manipulate such scores to cheat them into an incorrect attack path.
just attackers (observing loss trend) rather than users (observing outputs) that are misled

Despite the choice of AAA to reverse the margin loss, it could prevent attacks using other loss types.
Experiments
Setup
8 defense baselines: random noise defense (RND [33]), adversarial training (AT [36, 59, 49]), dynamic inference (DENT [19]), training randomness (PNI [51]), and ensemble (TRS [60]).
mostly experiment with the linear design, AAA-sine: costly
6 state-of-the-art SQAs: random search methods including Square [5], SignHunter [40], and SimBA [4], and gradient estimation methods including NES [58], and Bandits [3].
mostly perform untargeted l ∞ l_∞ l∞ attacks, but we also test the targeted and l 2 l_2 l2 attacks under different bounds to observe AAA’s generalization.
use 8 DNNs, which are mostly WideResNets [34] as in [17].
2 datasets: cifar-10 and Imagenet
metrics: SQA adversarial accuracy, average query times, expected calibration error (ECE)
fool attackers: loss
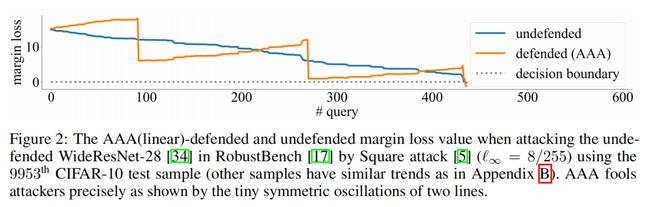
the orange line is mostly going opposite to the blue line in a precisely symmetric manner. Also, two lines cross the decision boundary at the same time, meaning that AAA does not change the decision (the negligible increase of AAA accuracy comes from randomness)
accuracy and calibration
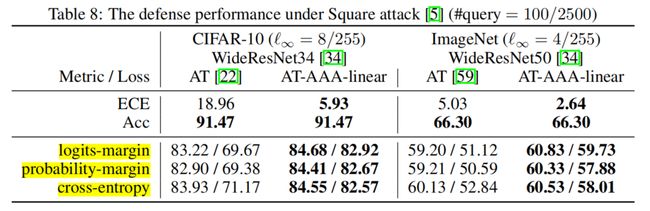
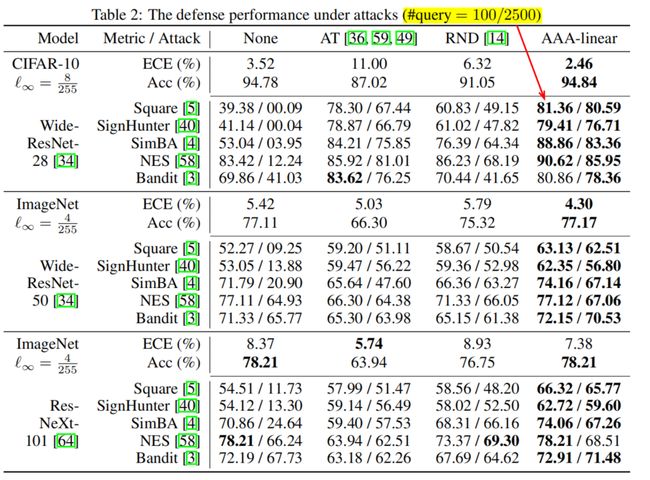
AAA outperforms alternatives in defending SQAs by a large margin with also the highest clean accuracy:
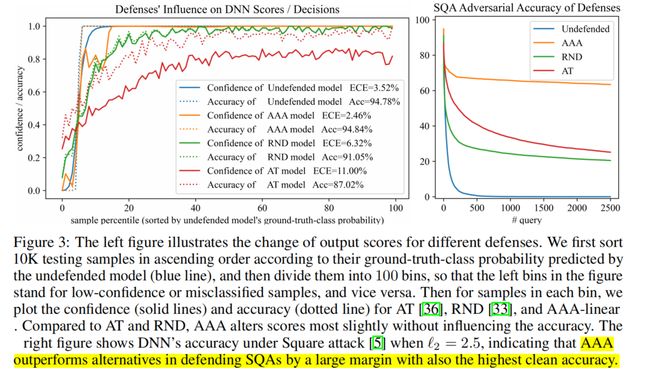
AAA-linear not only consistently reduces ECE by >12%, but also does not hurt clean accuracy:
SQA adversarial accuracy

Generalization of AAA
A targeted attack is successful only if an AE is mispredicted as a pre-set class, which, is randomly chosen from incorrect classes for each sample here.
AAA-linear本身已经足够好了,其实不需要跟AT结合(feasible but not necessary)

Hyper-parameters of AAA

attractor interval τ, reverse step α, calibration loss weight β

AAA’s good performance is insensitive to hyper-parameters, even if tuned in logarithmic scale.
Regarding the trend, an intuitive conclusion is that a larger α, a larger τ , or a smaller β that highlights defense more v.s. calibration would thereby increase the adversarial accuracy and ECE.
optimization times κ:
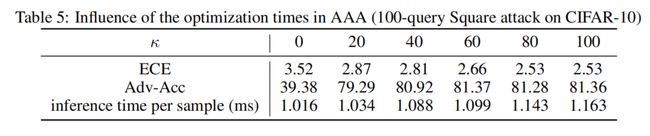
Optimizing low-dimensional logits is not costly, and good defense and calibration results are also obtainable by 60 to 80 iterations, which costs less time.
Adaptive attacks of AAA
设计adaptive attacks本身是困难的: costly and easy to bypass in real-world scenarios, require additional queries.
假设攻击者已经知道了防御措施,那么有两种针对AAA的直接的自适应攻击: going bidirectional or opposite to the original attack direction
adaptive attackers are also easy to fool because the dramatic drop of loss across intervals could be smoothed, e.g. by using a sine function to design the target loss as the second equation in (5).

顶会审稿人注意到的地方和我注意到的差别
审稿人提出的Weaknesses和作者的回复:
-
Three unrealistic constraints of SQAs make especially mitigating SQAs a weak motivation:攻击者不知道模型的具体细节,不能使用替代模型,可以获得置信度信息。
模型本身具有商业价值;训练替代模型需要training data,甚至可能泄露用户隐私;下游任务本身就是需要置信度信息的
-
只是针对一种具体攻击,没有考虑神经网络本身的健壮性。
AAA defense under decision-based attacks (DQAs)
确实不能减轻DQAs,但是DQAs没有SQAs那么有威胁性(需要相当多的查询次数)
不过没有考虑神经网络本身的健壮性确实也是一个weakness
-
AAA does not significantly hurdle SQAs
不认同,效果很好
-
防御者对攻击者了解得非常清楚,甚至知道迭代次数 τ
τ 不是迭代次数,只是一个超参数。realistic double-blind real-world threat model.
-
文章中假设的是non-adaptive attacker,对于linear,攻击者可以采用opposite direction
采用AAA-sine(被审稿人激励然后想到的,妙哇)
不认同,效果很好
-
防御者对攻击者了解得非常清楚,甚至知道迭代次数 τ
τ 不是迭代次数,只是一个超参数。realistic double-blind real-world threat model.
-
文章中假设的是non-adaptive attacker,对于linear,攻击者可以采用opposite direction
采用AAA-sine(被审稿人激励然后想到的,妙哇)