吴恩达《机器学习》课后测试Ex3:一对多分类(详细Python代码注解)
基于吴恩达《机器学习》课程
参考黄海广的笔记
对于此练习,我们将使用逻辑回归来识别手写数字(0到9)。 我们将扩展我们在练习2中写的逻辑回归的实现,并将其应用于一对多的分类。 让我们开始加载数据集。 注意这里用y=10代表数字0。
ex3data1.mat是一个MATLAB格式文件,其中包含5000个20*20像素的手写字体图像,以及他对应的数字。用Python读取我们需要使用SciPy。
import matplotlib.pyplot as plt
import numpy as np
import scipy.io as sio
import matplotlib
import scipy.optimize as opt
from sklearn.metrics import classification_report # 这个包是评价报告
sigmoid 函数
这里与二分类逻辑回归相同。
h θ ( x ) = 1 1 + e − θ T X h_\theta \left( x \right)=\frac{1}{1+{{e}^{-\theta^{T}X}}} hθ(x)=1+e−θTX1
# 实现sigmoid函数
def sigmoid(z):
return 1 / (1 + np.exp(-z))
正则化的代价函数
这里也与二分类相同。
J ( θ ) = 1 m ∑ i = 1 m [ − y ( i ) log ( h θ ( x ( i ) ) ) − ( 1 − y ( i ) ) log ( 1 − h θ ( x ( i ) ) ) ] + λ 2 m ∑ j = 1 n θ j 2 J\left( \theta \right)=\frac{1}{m}\sum\limits_{i=1}^{m}{[-{{y}^{(i)}}\log \left( {h_\theta}\left( {{x}^{(i)}} \right) \right)-\left( 1-{{y}^{(i)}} \right)\log \left( 1-{h_\theta}\left( {{x}^{(i)}} \right) \right)]}+\frac{\lambda }{2m}\sum\limits_{j=1}^{n}{\theta _{j}^{2}} J(θ)=m1i=1∑m[−y(i)log(hθ(x(i)))−(1−y(i))log(1−hθ(x(i)))]+2mλj=1∑nθj2
# 正则化的代价函数
def cost(theta, X, y, learningRate):
theta = np.matrix(theta)
X = np.matrix(X)
y = np.matrix(y)
first = np.multiply(-y, np.log(sigmoid(X * theta.T)))
second = np.multiply((1 - y), np.log(1 - sigmoid(X * theta.T)))
reg = (learningRate / (2 * len(X)) * np.sum(np.power(theta[:, 1:theta.shape[1]], 2)))
return np.sum(first - second) / len(X) + reg # sum不要忘掉 ,否则最后准确率差别很大
learningRate就是正则化参数 λ \lambda λ。
矩阵在乘向量时,向量会自动变成列后相乘,但是这里theta已经转为列只有一行的矩阵,所以要先转置为只有一列的矩阵再相乘。
正则化梯度计算
如果我们要使用梯度下降法令这个代价函数最小化,我们未对 θ 0 \theta_0 θ0进行正则化,所以梯度下降算法应分两种情形:
R e p e a t Repeat Repeat u n t i l until until c o n v e r g e n c e convergence convergence{
θ 0 : = θ 0 − a 1 m ∑ i = 1 m ( ( h θ ( x ( i ) ) − y ( i ) ) x 0 ( i ) ) {\theta_0}:={\theta_0}-a\frac{1}{m}\sum\limits_{i=1}^{m}{(({h_\theta}({{x}^{(i)}})-{{y}^{(i)}})x_{0}^{(i)}}) θ0:=θ0−am1i=1∑m((hθ(x(i))−y(i))x0(i))
θ j : = θ j − a [ 1 m ∑ i = 1 m ( ( h θ ( x ( i ) ) − y ( i ) ) x j ( i ) + λ m θ j ] {\theta_j}:={\theta_j}-a[\frac{1}{m}\sum\limits_{i=1}^{m}{(({h_\theta}({{x}^{(i)}})-{{y}^{(i)}})x_{j}^{\left( i \right)}}+\frac{\lambda }{m}{\theta_j}] θj:=θj−a[m1i=1∑m((hθ(x(i))−y(i))xj(i)+mλθj] ( f o r for for j = 1 , 2 , . . . n j=1,2,...n j=1,2,...n)
}
在Ex2 Part2中,使用for循环,这里使用向量化的梯度函数。二者结果一样,但是用向量计算更快。
# 正则化的梯度计算,没有梯度下降
def gradient(theta, X, y, learningRate):
# STEP1:将theta, X, y转换为numpy类型的矩阵
theta = np.matrix(theta)
X = np.matrix(X)
y = np.matrix(y)
# STEP2:将theta矩阵拉直(转换为一个向量)
parameters =int(theta.ravel().shape[1]) # 得到theta中的数量
# theta.ravel():将多维数组转换为一维数组,并不会产生源数据的副本. shape[1]:获取列数
# STEP3:计算预测的误差
error = sigmoid(X * theta.T) - y
# STEP4:根据上面的公式计算梯度
# 这里如果直接让theta[0,0] = 0,就不用STEP5了
grad = ((X.T * error) / len(X)).T + ((learningRate / len(X)) * theta)
# STEP5:由于j=0时不需要正则化,所以这里重置一下
grad[0, 0] = np.sum(np.multiply(error, X[:,0])) / len(X)
return np.array(grad).ravel()
设X中有N个训练数据,每个有n个特征,则X为N行n列矩阵。
STEP3图解如下,得到的error是列向量,就是 δ = a − y = ∂ C ∂ z \delta=a-y=\frac{\partial C}{\partial {z}} δ=a−y=∂z∂C, a = g ′ ( z ) a=g'(z) a=g′(z)。

X则是 ∂ z ∂ w = a \frac{\partial z}{\partial {w}}=a ∂w∂z=a,有 ∂ C ∂ w = ∂ z ∂ w ∂ C ∂ z \frac{\partial C}{\partial {w}}=\frac{\partial z}{\partial {w}}\frac{\partial C}{\partial {z}} ∂w∂C=∂w∂z∂z∂C,将所有偏导加起来取平均,即:((X.T * error) / len(X)).T最后得到n维行向量。

构建分类器
在本练习中,我们的任务是实现一对多分类方法。有k个不同类的标签就有k个分类器,每个分类器在“是 i”和“不是 i”之间决定。
我们将把分类器训练包含在一个函数中,该函数计算10个分类器中的每个分类器的最终权重,并将权重返回为k*(n + 1)数组,其中n是参数数量。
def one_vs_all(X, y, num_labels, learning_rate): # num_labels为类别数,这里是10
rows = X.shape[0] # X的行数(样本个数)
params = X.shape[1] # X的列数(一个样本的维度)
all_theta = np.zeros((num_labels, params + 1)) # 有一个偏置,维数+1
# all_theta为k * (n + 1)维,每一行就是一组逻辑回归参数
X = np.insert(X, 0, values=np.ones(rows), axis=1) # 在X的0号位插了一列1
for i in range(1, num_labels + 1):
theta = np.zeros(params + 1) # n + 1维向量,就是一组逻辑回归参数
# 对于y中的所有标签,若标签为i则设置y_i对应位置为1,否则为0
y_i = np.array([1 if label == i else 0 for label in y])
y_i = np.reshape(y_i, (rows, 1)) # 转为列向量
# 使用库函数minimize寻找参数,传入参数位置保证正确
fmin = minimize(fun=cost, x0=theta, args=(X, y_i, learning_rate), method='TNC', jac=gradient)
all_theta[i-1,:] = fmin.x # 将这组辑回归参数放入all_theta对应位置
return all_theta
预测标签
最后一步,使用训练完毕的分类器预测每个图像的标签。 对于这一步,我们将计算每个类的类概率,对于每个训练样本(使用当然的向量化代码),并将输出类标签为具有最高概率的类。
Tips:可以使用np.argmax()函数找到矩阵中指定维度的最大值。
def predict_all(X, all_theta):
# INPUT:参数值theta,测试数据X OUTPUT:预测值 TODO:对测试数据进行预测
# STEP1:获取矩阵的维度信息
rows = X.shape[0]
params = X.shape[1]
num_labels = all_theta.shape[0]
# STEP2:把矩阵X加入一行零元素
X = np.insert(X, 0, values=np.ones(rows), axis=1)
# STEP3:把矩阵X和all_theta转换为numpy型矩阵
X = np.matrix(X)
all_theta = np.matrix(all_theta)
# STEP4:计算样本属于每一类的概率
h = sigmoid(X * all_theta.T)
# STEP5:找到每个样本中预测概率最大的值
h_argmax = np.argmax(h, axis=1) # axis=1表示取h矩阵中每一行的最大值
# STEP6:因为我们的数组是零索引的,所以我们需要+1才是真正的标签
h_argmax = h_argmax + 1
return h_argmax
h_argmax为n行1列向量。X * all_theta.T图解:
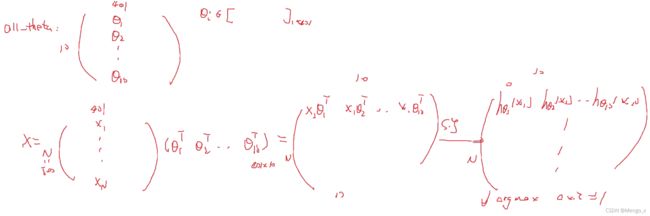
多类分类
def ex3_1():
data = loadmat('ex3data1.mat')
print(data)
print(data['X'].shape, data['y'].shape)
print(np.unique(data['y'])) # 看下有几类标签,验证合理性
读入样本文件ex3data1.mat,输出如下:
{'__header__': b'MATLAB 5.0 MAT-file, Platform: GLNXA64, Created on: Sun Oct 16 13:09:09 2011', '__version__': '1.0', '__globals__': [],
'X': array([[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]]),
'y': array([[10],
[10],
[10],
...,
[ 9],
[ 9],
[ 9]], dtype=uint8)}
(5000, 400) (5000, 1)
[ 1 2 3 4 5 6 7 8 9 10]
可以看到有五千个样本,一个样本是400维。400维“特征”是20 x 20图像中每个像素的灰度强度,把20 x 20矩阵一行一行拉为400维向量。
y对应图像中数字,注意这里用y=10代表数字0。
# 代码接上
all_theta = one_vs_all(data['X'], data['y'], 10, 1)
print(all_theta)
可见输出为10*401的数组:
[[-2.38282889e+00 0.00000000e+00 0.00000000e+00 ... 1.30423112e-03
-7.11706024e-10 0.00000000e+00]
[-3.18500790e+00 0.00000000e+00 0.00000000e+00 ... 4.46081618e-03
-5.08578236e-04 0.00000000e+00]
[-4.79836022e+00 0.00000000e+00 0.00000000e+00 ... -2.87164092e-05
-2.47500481e-07 0.00000000e+00]
...
[-7.98732644e+00 0.00000000e+00 0.00000000e+00 ... -8.94811011e-05
7.21853803e-06 0.00000000e+00]
[-4.57077403e+00 0.00000000e+00 0.00000000e+00 ... -1.34236218e-03
1.00754852e-04 0.00000000e+00]
[-5.39900164e+00 0.00000000e+00 0.00000000e+00 ... -1.16735543e-04
7.87935664e-06 0.00000000e+00]]
接下来就是调用预测:
# 代码接上
y_pred = predict_all(data['X'], all_theta) # predict_all返回的预测值n*1的向量
correct = [1 if a == b else 0 for (a, b) in zip(y_pred, data['y'])] # 判断预测值和标签是否相同
accuracy = (sum(map(int, correct)) / float(len(correct))) # 计算预测正确率,就是correct中1的个数
print('accuracy = {0}%'.format(accuracy * 100))
输出预测正确率为:
accuracy = 94.46%