使用pandas进行数据预处理实验结果即截图
10.2 pandas数据结构
10.2.1 Series
Series的字符串表现形式为:索引在左边,值在右边。如果没有为数据指定索引,就会自动创建一个0到N-1(N为数据的长度)的整数型索引。
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
obj=Series([3,5,6,10,9,2])
print(obj)
print(obj.index)


pandas会自动创建一个整型索引。现在,我们创建对数据点进行标记的索引.
from pandas import Series,DataFrame
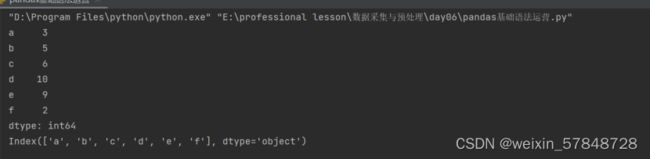
obj=Series([3,5,6,10,9,2],index=['a','b','c','d','e','f'])
print(obj)
print(obj.index)
创建好Series以后,可以利用索引的方式选取Series的单个或一组值。作为演示
print(obj['a'])
print(obj[['b','d','f']])
可以对Series进行NumPy数组运算。
print(obj[obj>5])
print(obj * 2)

可以将Series看成是一个有定长的有序字典,因为它是索引值到数据值的一个映射。
print('b' in obj)
print('m' in obj)、

此外,也可以用字典创建Series。
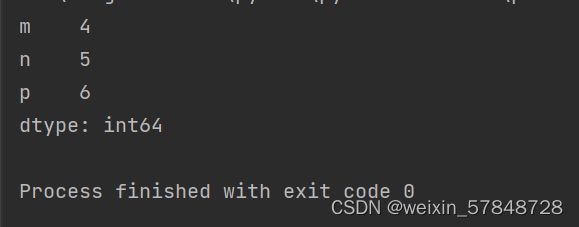
dic={'m':4,'n':5,'p':6}
obj3=Series(dic)
print(obj3)
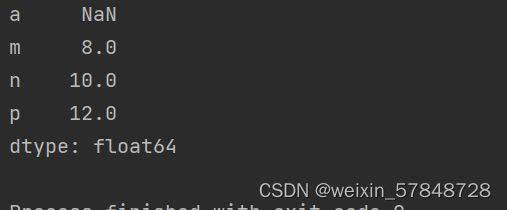
使用字典生成Series时,可以指定额外的索引。如果额外的索引与字典中的键不匹配,则不匹配的索引部分数据为NaN。
ind=['m','n','p','a']
obj4=Series(dic,index=ind)
print(obj4)

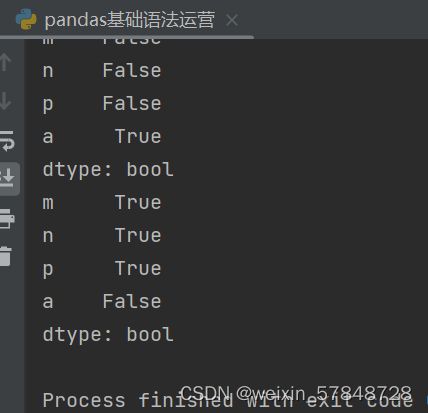
pandas提供了isnull()和notnull()函数用于检测缺失数据。
print(pd.isnull(obj4))
print(pd.notnull(obj4))
可以对不同的Series进行算术运算,在运算过程中,pandas会自动对齐不同索引的数据。
print( obj3+obj4)
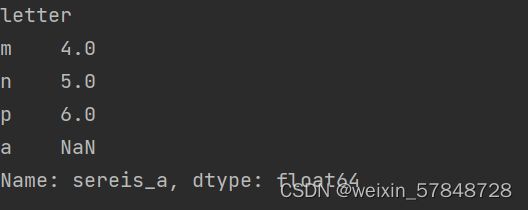
Series对象本身及其索引都有一个name属性。
obj4.name='sereis_a'
obj4.index.name='letter'
print(obj4)
Series的索引可以通过赋值的方式进行改变。
obj4.index=['u','v','w','a']

10.2.2Dataframe
DataFrame是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔值等)。DataFrame既有行索引也有列索引,它可以被看作由Series组成的字典(公用同一个索引)。跟其他类似的数据结构相比,DataFrame中面向行和面向列的操作基本是平衡的。其实,DataFrame中的数据是以一个或多个二维块存放的(而不是列表、字典或者别的一维数据结构)。
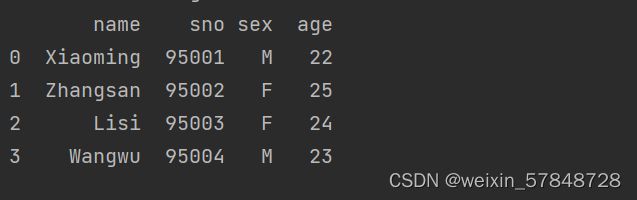
from pandas import Series,DataFrame
data = {'sno':['95001', '95002', '95003', '95004'],
'name':['Xiaoming','Zhangsan','Lisi','Wangwu'],
'sex':['M','F','F','M'],
'age':[22,25,24,23]}
frame=DataFrame(data)
print(frame)

虽然没有指定行索引,但是,pandas会自动添加索引。
如果指定列索引,则会按照指定顺序排列。
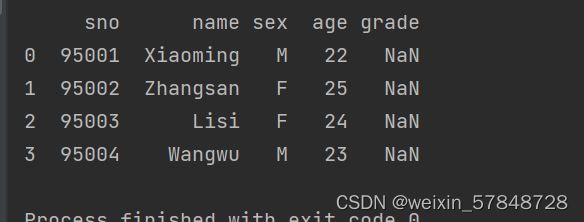
在制定列索引时,如果存在不匹配的列,则不匹配的列的值为NaN
frame=DataFrame(data,columns=['sno','name','sex','age','grade'])
print(frame)
可以同时指定行索引和列索引:
frame=DataFrame(data,columns=['sno','name','sex','age','grade'],index=['a','b','c','d'])

通过类似字典标记或属性的方式,可以获取Series(列数据):
print(frame['sno'])
print(frame.name)
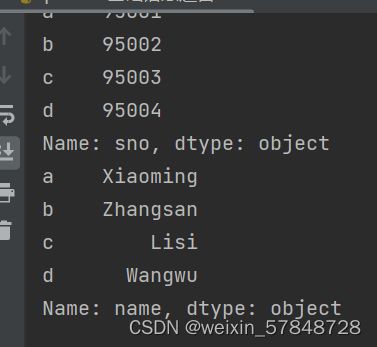
或者,也可以采用“切片”的方式一次获取多个行:
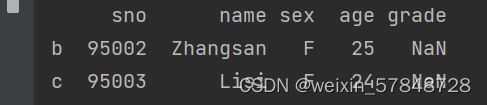
可以用“切片”的方式使用列名称获取1个列:

也可以用“切片”的方式使用列名称获取多个列:
print(frame.loc[:, 'sex':])
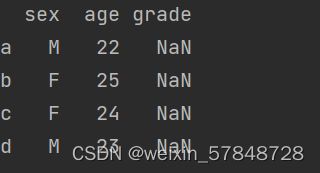
可以给列赋值,赋值是列表的时候,列表中元素的个数必须和数据的行数匹配:
frame['grade']=[93,109,72,104]
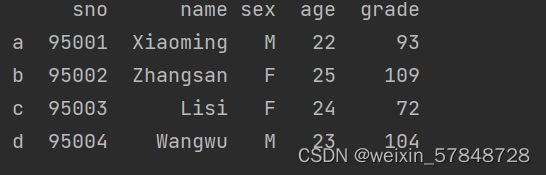
可以用一个Series修改一个DataFrame的值,将精确匹配DataFrame的索引,空位将补上缺失值:
frame['grade']=Series([67,109],index=['a','c'])
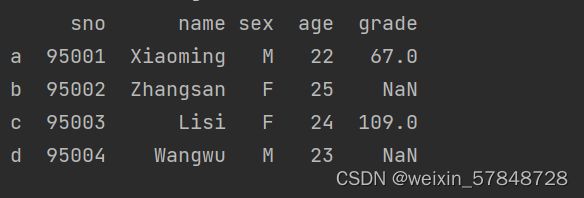
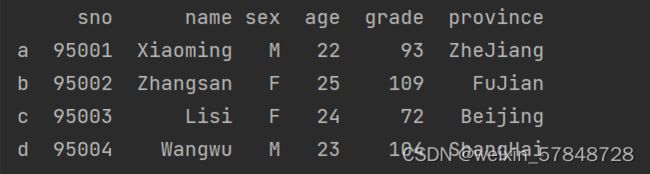
可以增加一个新的列:
frame['province']=['ZheJiang','FuJian','Beijing','ShangHai']
可以把嵌套字典(字典的字典)作为参数,传入DataFrame,其中,外层字典的键作为列(column),内层键作为行索引(index):
可以对结果进行转置
10.3基本功能
10.3.1 重新索引
import numpy as np
import pandas as pd
#pandas中的reindex方法可以为Series和DataFrame添加或者删除索引。如果新添加的索引没有对应的值,则默认为NaN。如果减少索引,就相当于一个切片操作。
from pandas import Series,DataFrame
s1 = Series([1, 2, 3, 4], index=['A', 'B', 'C', 'D'])
print(s1)
## 重新指定index, 多出来的index,可以使用fill_value填充
print(s1.reindex(index=['A', 'B', 'C', 'D', 'E'], fill_value = 10))
# 修改索引,将s2的索引增加到15个,如果新增加的索引值不存在,默认为NaN
s2 = Series(['A', 'B', 'C'], index = [1, 5, 10])
print(s2.reindex(index=range(15)))
# 修改索引,将s2的索引增加到15个,如果新增加的索引值不存在,默认为NaN
print( s2.reindex(index=range(15)))
# ffill: 表示forward fill,向前填充
# 如果新增加索引的值不存在,那么按照前一个非NaN的值填充进去
print(s2.reindex(index=range(15), method='ffill'))
# 减少index
print( s1.reindex(['A', 'B']))
df1 = DataFrame(np.random.rand(25).reshape([5, 5]), index=['A', 'B', 'D', 'E', 'F'], columns=['c1', 'c2', 'c3', 'c4', 'c5'])
print(df1)
# 为DataFrame添加一个新的索引
# 可以看到自动扩充为NaN
print(df1.reindex(index=['A', 'B', 'C', 'D', 'E', 'F']))
# 扩充列
print(df1.reindex(columns=['c1', 'c2', 'c3', 'c4', 'c5', 'c6']))
# 减少index
print(df1.reindex(index=['A', 'B']))
10.3.2 丢弃指定轴上的项——10.3.6 函数应用和映射
可以使用drop()方法丢弃指定轴上的项,drop()方法返回的是一个在指定轴上删除了指定值的新对象
import numpy as np
import pandas as pd
#pandas中的reindex方法可以为Series和DataFrame添加或者删除索引。如果新添加的索引没有对应的值,则默认为NaN。如果减少索引,就相当于一个切片操作。
from pandas import Series,DataFrame
s1 = Series(np.arange(4), index = ['a', 'b', 'c','d'])
print(s1.drop(['a', 'b']))
# DataFrame根据索引行/列删除行/列
df1 = DataFrame(np.arange(16).reshape((4, 4)),
index = ['a', 'b', 'c', 'd'],
columns = ['A', 'B', 'C', 'D'])
print(df1)
print(df1.drop(['A','B'],axis=1)) #在列的维度上删除AB两行,axis值为1表示列的维度
print(df1.drop('a', axis = 0) ) #在行的维度上删除行,axis值为0表示行的维度
print(df1.drop(['a', 'b'], axis = 0))
data = DataFrame(np.arange(16).reshape((4, 4)),
index = ['a', 'b', 'c', 'd'],
columns = ['A', 'B', 'C', 'D'])
print(data)
print(data['A']) #打印列
print(data[['A', 'B']]) #花式索引
print(data[:2]) #切片索引,选择行
print(data[data.A > 5]) #根据条件选择行
print(data < 5) #打印True或者False
data[data < 5] = 0 #条件索引
print(data)
#下面是关于DataFrame算术运算的实例
df1 = DataFrame(np.arange(12).reshape((3,4)),columns=list("abcd"))
df2 = DataFrame(np.arange(20).reshape((4,5)),columns=list("abcde"))
print(df1)
print(df2)
print(df1+df2)
print(df1.add(df2,fill_value=0) ) #为df1添加第3行和e这一列
print(df1.add(df2).fillna(0) ) #按照正常方式将df1和df2相加,然后将NaN值填充为0
#10.3.5 DataFrame和Series之间的运算
frame = DataFrame(np.arange(12).reshape((4,3)),columns=list("bde"),
index=["Beijing","Shanghai","Shenzhen","Xiamen"])
print(frame)
print(frame.iloc[1]) # 获取某一行数据
print(frame.index) #获取索引
series = frame.iloc[0]
print(series)
print(frame - series)
#函数应用和映射
frame = DataFrame(np.arange(12).reshape((4,3)),columns=list("bde"),
index=["Beijing","Shanghai","Shenzhen","Xiamen"])
print(frame)
f = lambda x : x.max() - x.min() # 匿名函数
print(frame.apply(f)) #apply默认第二个参数axis=0,作用于列方向上,axis=1时作用于行方向上
#可以使用applymap()将一个规则应用到DataFrame中的每一个元素

10.3.7排序和排名
import numpy as np
import pandas as pd
#pandas中的reindex方法可以为Series和DataFrame添加或者删除索引。如果新添加的索引没有对应的值,则默认为NaN。如果减少索引,就相当于一个切片操作。
from pandas import Series, DataFrame
series = Series(range(4),index=list("dabc"))
print(series)
print(series.sort_index()) #索引按字母顺序排序
frame= DataFrame(np.arange(8).reshape((2,4)),
index=["three","one"],
columns=list("dabc"))
print(frame)
print(frame.sort_index())
print(frame.sort_index(axis=1,ascending=False))
# 按照DataFrame中某一列的值进行排序
df = DataFrame({"a":[4,7,-3,2],"b":[0,1,0,1]})
print(df)
# 按照b这一列的数据值进行排序
print(df.sort_values(by="b"))
#排名(rank)是指根据值的大小/出现次数来进行排名,得到一组排名值。排名跟排序关系密切,且它会增设一个排名值(从1开始,一直到数组中有效数据的数量)。默认情况下,rank()通过将平均排名分配到每个组打破平级关系。也就是说,如果有两组数值一样,那他们的排名将会被加在一起再除以2。
obj=Series([7,-4,7,3,2,0,5])
print(obj.rank())
print(obj.rank(method='first'))
print(obj.rank(method='min'))
print(obj.rank(method='max'))
#也可以对DataFrame使用rank(),实例如下:
frame = DataFrame({'b': [3, 1, 5, 2], 'a': [10, 4, 3, 7], 'c': [2, 7, 9, 4]})
print(frame)
print(frame.rank(axis=1)) # axis=0时作用于列方向上,axis=1时作用于行方向上
10.3.10 分组
import numpy as
import pandas as pd
from pandas import Series, DataFrame
dict_obj = {'key1' : ['a', 'b', 'a', 'b', 'a', 'b', 'a', 'a'],
'key2' : ['one', 'one', 'two', 'three','two', 'two', 'one', 'three'],
'data1': np.random.randn(10),
'data2': np.random.randn(10)}
df_obj = DataFrame(dict_obj)
print(df_obj)
print(df_obj.groupby('key1'))
print(type(df_obj.groupby('key1')))
print(df_obj['data1'].groupby(df_obj['key1']))
print(type(df_obj['data1'].groupby(df_obj['key1'])))
import pandas as pd
import numpy as np
from pandas import Series,DataFrame
dict_obj = {'key1' : ['a', 'b', 'a', 'b', 'a', 'b', 'a', 'a'],
'key2' : ['one', 'one', 'two', 'three','two', 'two', 'one', 'three'],
'data1': np.random.randn(10),
'data2': np.random.randn(10)}
df_obj = DataFrame(dict_obj)
print(df_obj)
grouped1 = df_obj.groupby('key1')
print(grouped1.mean())
grouped2 = df_obj['data1'].groupby(df_obj['key1'])
print(grouped2.mean())
print(grouped1.size()) # 返回每个分组的元素个数
print(grouped2.size())
print(df_obj.groupby([df_obj['key1'], df_obj['key2']]).size())
grouped3 = df_obj.groupby(['key1', 'key2'])
print(grouped3.size())
print(grouped3.mean())
dict_obj = {'key1' : ['a', 'b', 'a', 'b', 'a', 'b', 'a', 'a'],
'key2' : ['one', 'one', 'two', 'three','two', 'two', 'one', 'three'],
'data1': np.random.randn(10),
'data2': np.random.randn(10)}
df_obj = DataFrame(dict_obj)
print(df_obj)
self_def_key = [0, 1, 2, 3, 3, 4, 5, 7]
print(df_obj.groupby(self_def_key).size())
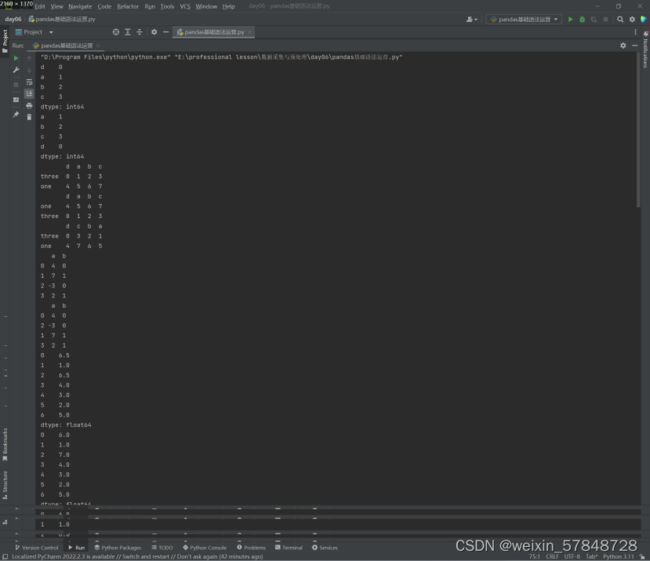
10.3.11 cut()函数
#10.3.11 cut()函数
import pandas as pd
import numpy as np
from pandas import DataFrame
info_nums = DataFrame({'num': np.random.randint(1, 50, 11)})
print(info_nums)
info_nums['num_bins'] = pd.cut(x=info_nums['num'], bins=[1, 25, 50])
print(info_nums)
print(info_nums['num_bins'].unique())
#演示如何向箱子添加标签
import pandas as pd
import numpy as np
from pandas import DataFrame
info_nums = DataFrame({'num': np.random.randint(1, 10, 7)})
print(info_nums)
info_nums['nums_labels'] = pd.cut(x=info_nums['num'], bins=[1, 7, 10], labels=['Lows', 'Highs'], right=False)
print(info_nums)
print(info_nums['nums_labels'].unique())

10.4 汇总和描述统计
10.4.1 与描述统计相关的函数
#10.4 汇总和描述统计
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
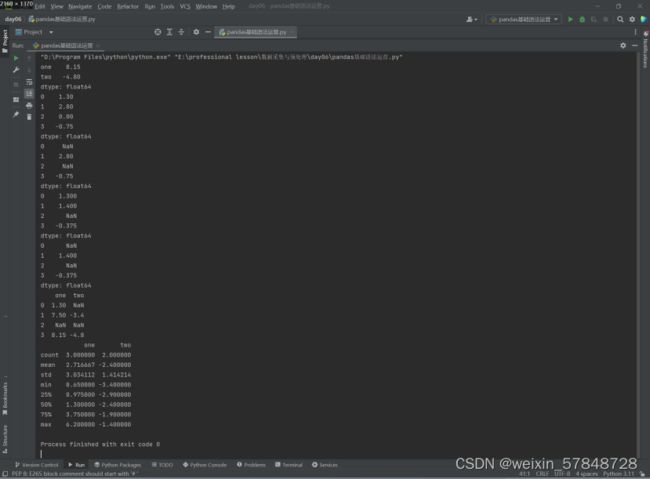
df=DataFrame([[1.3,np.nan],[6.2,-3.4],[np.nan,np.nan],[0.65,-1.4]],columns=['one','two'])
print(df.sum()) #计算每列的和,默认排除NaN
print(df.sum(axis=1)) #计算每行的和,默认排除NaN
#计算每行的和,设置skipna=False,NaN参与计算,结果仍为NaN
print(df.sum(axis=1,skipna=False))
print(df.mean(axis=1))
print(df.mean(axis=1,skipna=False)) #计算每行的平均值,NaN参与运算
print(df.cumsum()) #求样本值的累计和
print(df.describe()) #针对列计算汇总统计
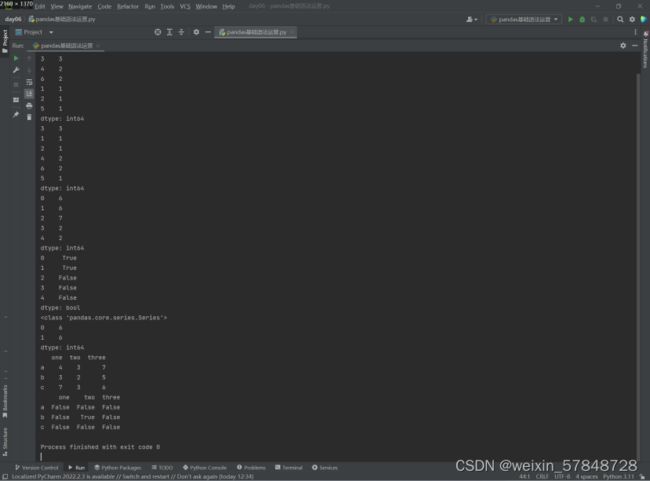
10.4.2 唯一值、值计数以及成员资格
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
#判断Series中的值是否重复,False表示重复
s = Series([3, 3, 1, 2, 4, 3, 4, 6, 5, 6])
print(s.is_unique)
#输出Series中不重复的值,返回值没有排序,返回值的类型为数组
print(s.unique())
#统计Series中重复值出现的次数,默认是按出现次数降序排序
print(s.value_counts())
#按照重复值的大小排序输出频率
print(s.value_counts(sort=False))
s = Series([6,6,7,2,2])
print(s)
#判断矢量化集合的成员资格,返回一个布尔类型的Series
print(s.isin([6]))
print(type(s.isin([6])))
#通过成员资格方法选取Series中的数据子集
print(s[s.isin([6])])
data = [[4,3,7],[3,2,5],[7,3,6]]
df = DataFrame(data,index=["a","b","c"],columns=["one","two","three"])
print(df)
#返回一个布尔型的DataFrame
print(df.isin([2]))
RESULT
10.5 处理缺失数据
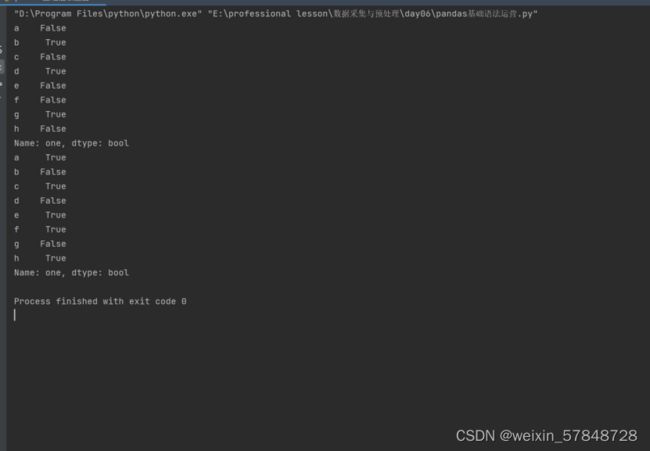
10.5.1检查缺失值
为了更容易地检测缺失值,pandas提供了isnull()和notnull()函数,它们也是Series和DataFrame对象的方法。
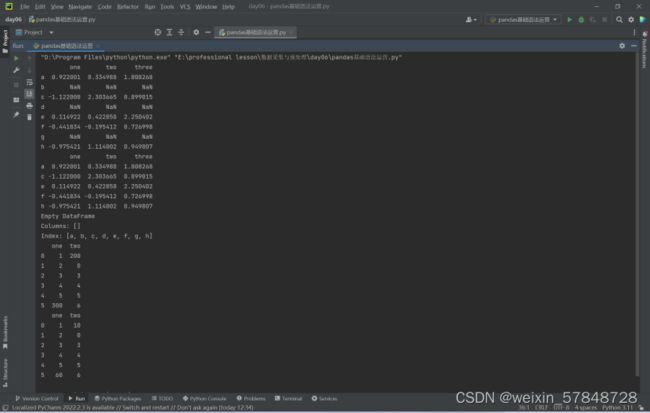
df = DataFrame(np.random.randn(5, 3), index=['a', 'c', 'e', 'f','h'],columns=['one', 'two', 'three'])
df = df.reindex(['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h'])
print(df['one'].isnull())
print(df['one'].notnull())
10.5.2清理/填充缺失值——10.5.3 丢失缺少的值
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
df = DataFrame(np.random.randn(5, 3), index=['a', 'c', 'e', 'f','h'],columns=['one', 'two', 'three'])
df = df.reindex(['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h'])
print(df)
print(df.dropna()) #默认情况下,axis = 0,即在行上应用
print(df.dropna(axis=1)) # axis = 1时在列上应用
# 可以用一些具体的值取代一个通用的值
df = DataFrame({'one':[1,2,3,4,5,300],'two':[200,0,3,4,5,6]})
print(df)
print(df.replace({200:10,300:60}))