2022第五届“泰迪杯”数据分析技能赛-B题-银行客户忠诚度分析(下)
2022第五届“泰迪杯”数据分析技能赛-B题-银行客户忠诚度分析(上)链接:https://blog.csdn.net/weixin_60200880/article/details/127917207?spm=1001.2014.3001.5502
题目链接:链接:https://pan.baidu.com/s/1x1U-kobvPjNMm8xnvS9Gdg
提取码:7id3
目录
任务4 特征构建
任务5 银行客户长期忠诚度预测建模
任务5.1
任务5.2
比赛总结
good
bad
任务4 特征构建
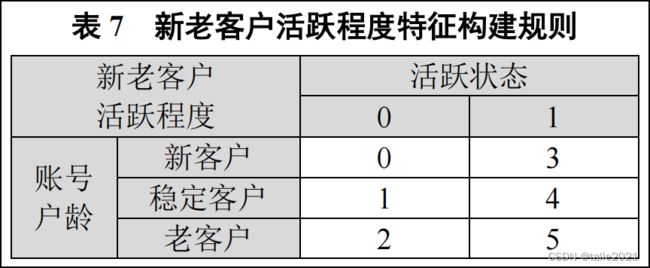
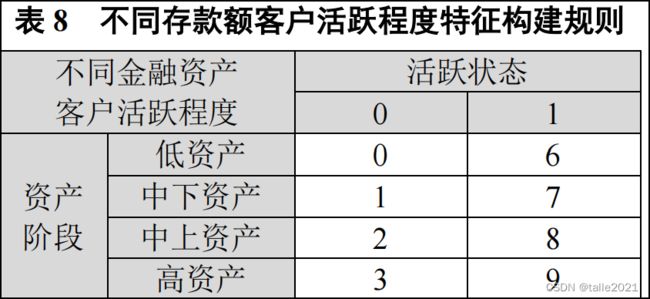
(2) 根据表 8,构建不同金融资产客户活跃程度的特征,并将结果存于“IsActiveAssetStage”列。

import pandas as pd
long_data=pd.read_excel('F:\\泰迪杯B题\\B题:银行客户忠诚度分析赛题数据\\任务4.xlsx')
IsActiveStatus=[]
IsActiveAssetStaget=[]
CrCardAssetStage=[]
for i in range(len(long_data["Age"])):
IsActiveStatus.append(0)
IsActiveAssetStaget.append(0)
CrCardAssetStage.append(0)
for i in range(len(short_data["Age"])):
if long_data.loc[i,'Status']=='新客户' and long_data.loc[i,'IsActiveMember']==0:
IsActiveStatus[i]=0
if long_data.loc[i,'Status']=='稳定客户' and long_data.loc[i,'IsActiveMember']==0:
IsActiveStatus[i]=1
if long_data.loc[i,'Status']=='老客户' and long_data.loc[i,'IsActiveMember']==0:
IsActiveStatus[i]=2
if long_data.loc[i,'Status']=='新客户' and long_data.loc[i,'IsActiveMember']==1:
IsActiveStatus[i]=3
if long_data.loc[i,'Status']=='稳定客户' and long_data.loc[i,'IsActiveMember']==1:
IsActiveStatus[i]=4
if long_data.loc[i,'Status']=='老客户' and long_data.loc[i,'IsActiveMember']==1:
IsActiveStatus[i]=5
for i in range(len(short_data["Age"])):
if long_data.loc[i,'AssetStage']=='低资产' and long_data.loc[i,'IsActiveMember']==0:
IsActiveAssetStaget[i]=0
if long_data.loc[i,'AssetStage']=='中下资产' and long_data.loc[i,'IsActiveMember']==0:
IsActiveAssetStaget[i]=1
if long_data.loc[i,'AssetStage']=='中上资产' and long_data.loc[i,'IsActiveMember']==0:
IsActiveAssetStaget[i]=2
if long_data.loc[i,'AssetStage']=='高资产' and long_data.loc[i,'IsActiveMember']==0:
IsActiveAssetStaget[i]=3
if long_data.loc[i,'AssetStage']=='低资产' and long_data.loc[i,'IsActiveMember']==1:
IsActiveAssetStaget[i]=6
if long_data.loc[i,'AssetStage']=='中下资产' and long_data.loc[i,'IsActiveMember']==1:
IsActiveAssetStaget[i]=7
if long_data.loc[i,'AssetStage']=='中上资产' and long_data.loc[i,'IsActiveMember']==1:
IsActiveAssetStaget[i]=8
if long_data.loc[i,'AssetStage']=='高资产' and long_data.loc[i,'IsActiveMember']==1:
IsActiveAssetStaget[i]=9
for i in range(len(short_data["Age"])):
if long_data.loc[i,'AssetStage']=='低资产' and long_data.loc[i,'HasCrCard']==0:
CrCardAssetStage[i]=0
if long_data.loc[i,'AssetStage']=='中下资产' and long_data.loc[i,'HasCrCard']==0:
CrCardAssetStage[i]=2
if long_data.loc[i,'AssetStage']=='中上资产' and long_data.loc[i,'HasCrCard']==0:
CrCardAssetStage[i]=5
if long_data.loc[i,'AssetStage']=='高资产' and long_data.loc[i,'HasCrCard']==0:
CrCardAssetStage[i]=5
if long_data.loc[i,'AssetStage']=='低资产' and long_data.loc[i,'HasCrCard']==1:
CrCardAssetStage[i]=6
if long_data.loc[i,'AssetStage']=='中下资产' and long_data.loc[i,'HasCrCard']==1:
CrCardAssetStage[i]=7
if long_data.loc[i,'AssetStage']=='中上资产' and long_data.loc[i,'HasCrCard']==1:
CrCardAssetStage[i]=9
if long_data.loc[i,'AssetStage']=='高资产' and long_data.loc[i,'HasCrCard']==1:
CrCardAssetStage[i]=9
data_1={'IsActiveStatus':IsActiveStatus,'IsActiveAssetStaget':IsActiveAssetStaget,'CrCardAssetStage':CrCardAssetStage}
df_1=pd.DataFrame(data_1)
df_1.to_excel('F:\\泰迪杯B题\\B题:银行客户忠诚度分析赛题数据\\result4.xlsx',sheet_name='sheet1',index=None)任务5 银行客户长期忠诚度预测建模
任务5.1
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import missingno as ms
import plotly.express as px
import plotly.graph_objs as go
import plotly.figure_factory as ff
from plotly.subplots import make_subplots
import plotly.offline as pyo
pyo.init_notebook_mode()
sns.set_style('darkgrid')
plt.style.use('fivethirtyeight')
%matplotlib inline
from sklearn.decomposition import PCA
from imblearn.over_sampling import SMOTE
from sklearn.model_selection import train_test_split,cross_val_score
from sklearn.ensemble import RandomForestClassifier,AdaBoostClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
from sklearn.svm import SVC
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import f1_score as f1
from sklearn.metrics import confusion_matrix
import eli5
from eli5.sklearn import PermutationImportance
import shap
plt.rc('figure',figsize=(18,9))
import warnings
warnings.filterwarnings("ignore")
pd.set_option('display.max_columns', 26)
long_data=pd.read_excel('F:\\泰迪杯B题\\B题:银行客户忠诚度分析赛题数据\\result1_2.xlsx')2.建模
x=long_data.drop("Exited",axis=1)
y=long_data["Exited"]
# 随机打乱数据
from sklearn.utils import shuffle
data_train=shuffle(long_data)
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.30,random_state=0)3.定义建模函数
def create_model(model):
#模型训练
model.fit(x_train,y_train)
#模型预测
y_pred=model.predict(x_test)
#准确率acc
acc=accuracy_score(y_test,y_pred)
#混淆矩阵
cm=confusion_matrix(y_test,y_pred)
#分类报告
cr=classification_report(y_test,y_pred)
print(f"Test Accuracy of {model}:{acc}")
print(f"Confusion Matrix of {model}:\n{cm}")
print(f"Classification Report of {model}:\n{cr}")4.十种模型
4.1 KNN
from sklearn.neighbors import KNeighborsClassifier
knn=KNeighborsClassifier()
create_model(knn)
---------------------代码分割线-----------------------------
Test Accuracy of KNeighborsClassifier():0.8041199855439104
Confusion Matrix of KNeighborsClassifier():
[[2106 112]
[ 430 119]]
Classification Report of KNeighborsClassifier():
precision recall f1-score support
0 0.83 0.95 0.89 2218
1 0.52 0.22 0.31 549
accuracy 0.80 2767
macro avg 0.67 0.58 0.60 2767
weighted avg 0.77 0.80 0.77 2767
4.2 DecisionTreeClassifier
from sklearn.tree import DecisionTreeClassifier
dt=DecisionTreeClassifier()
create_model(dt)
-----------------------代码分割线------------------------
Test Accuracy of DecisionTreeClassifier():0.8062883989880737
Confusion Matrix of DecisionTreeClassifier():
[[1919 299]
[ 237 312]]
Classification Report of DecisionTreeClassifier():
precision recall f1-score support
0 0.89 0.87 0.88 2218
1 0.51 0.57 0.54 549
accuracy 0.81 2767
macro avg 0.70 0.72 0.71 2767
weighted avg 0.81 0.81 0.81 27674.3 RandomForestClassifier
from sklearn.ensemble import RandomForestClassifier
rd_clf=RandomForestClassifier(criterion='entropy'
,max_depth=11
,max_features='auto'
,min_samples_leaf=2
,min_samples_split=3
,n_estimators=130)
create_model(rd_clf)
------------------------------------代码分割线--------------------------------------
Test Accuracy of RandomForestClassifier(criterion='entropy', max_depth=11, max_features='auto',
min_samples_leaf=2, min_samples_split=3,
n_estimators=130):0.8782074448861583
Confusion Matrix of RandomForestClassifier(criterion='entropy', max_depth=11, max_features='auto',
min_samples_leaf=2, min_samples_split=3,
n_estimators=130):
[[2165 53]
[ 284 265]]
Classification Report of RandomForestClassifier(criterion='entropy', max_depth=11, max_features='auto',
min_samples_leaf=2, min_samples_split=3,
n_estimators=130):
precision recall f1-score support
0 0.88 0.98 0.93 2218
1 0.83 0.48 0.61 549
accuracy 0.88 2767
macro avg 0.86 0.73 0.77 2767
weighted avg 0.87 0.88 0.86 2767
4.4 AdaBoostClassifier
from sklearn.ensemble import AdaBoostClassifier
ada=AdaBoostClassifier(base_estimator=dt)
create_model(ada)
------------------------------------------代码分割线-------------------------------------
Test Accuracy of AdaBoostClassifier(base_estimator=DecisionTreeClassifier()):0.8091796169136248
Confusion Matrix of AdaBoostClassifier(base_estimator=DecisionTreeClassifier()):
[[1927 291]
[ 237 312]]
Classification Report of AdaBoostClassifier(base_estimator=DecisionTreeClassifier()):
precision recall f1-score support
0 0.89 0.87 0.88 2218
1 0.52 0.57 0.54 549
accuracy 0.81 2767
macro avg 0.70 0.72 0.71 2767
weighted avg 0.82 0.81 0.81 27674.5 GradientBoostingClassifier
from sklearn.ensemble import GradientBoostingClassifier
gb=GradientBoostingClassifier()
create_model(gb)
----------------------------------代码分割线----------------------------------------
Test Accuracy of GradientBoostingClassifier():0.878930249367546
Confusion Matrix of GradientBoostingClassifier():
[[2155 63]
[ 272 277]]
Classification Report of GradientBoostingClassifier():
precision recall f1-score support
0 0.89 0.97 0.93 2218
1 0.81 0.50 0.62 549
accuracy 0.88 2767
macro avg 0.85 0.74 0.78 2767
weighted avg 0.87 0.88 0.87 27674.6 XGBClassifier
from xgboost import XGBClassifier
xgb=XGBClassifier(objective='binary:logistic'
,learning_rate=0.5
,max_depth=5
,n_estimators=150)
create_model(xgb)
----------------------------------------------代码分割线------------------------------------
Test Accuracy of XGBClassifier(base_score=0.5, booster='gbtree', callbacks=None,
colsample_bylevel=1, colsample_bynode=1, colsample_bytree=1,
early_stopping_rounds=None, enable_categorical=False,
eval_metric=None, gamma=0, gpu_id=-1, grow_policy='depthwise',
importance_type=None, interaction_constraints='',
learning_rate=0.5, max_bin=256, max_cat_to_onehot=4,
max_delta_step=0, max_depth=5, max_leaves=0, min_child_weight=1,
missing=nan, monotone_constraints='()', n_estimators=150,
n_jobs=0, num_parallel_tree=1, predictor='auto', random_state=0,
reg_alpha=0, reg_lambda=1, ...):0.8641127574990964
Confusion Matrix of XGBClassifier(base_score=0.5, booster='gbtree', callbacks=None,
colsample_bylevel=1, colsample_bynode=1, colsample_bytree=1,
early_stopping_rounds=None, enable_categorical=False,
eval_metric=None, gamma=0, gpu_id=-1, grow_policy='depthwise',
importance_type=None, interaction_constraints='',
learning_rate=0.5, max_bin=256, max_cat_to_onehot=4,
max_delta_step=0, max_depth=5, max_leaves=0, min_child_weight=1,
missing=nan, monotone_constraints='()', n_estimators=150,
n_jobs=0, num_parallel_tree=1, predictor='auto', random_state=0,
reg_alpha=0, reg_lambda=1, ...):
[[2106 112]
[ 264 285]]
Classification Report of XGBClassifier(base_score=0.5, booster='gbtree', callbacks=None,
colsample_bylevel=1, colsample_bynode=1, colsample_bytree=1,
early_stopping_rounds=None, enable_categorical=False,
eval_metric=None, gamma=0, gpu_id=-1, grow_policy='depthwise',
importance_type=None, interaction_constraints='',
learning_rate=0.5, max_bin=256, max_cat_to_onehot=4,
max_delta_step=0, max_depth=5, max_leaves=0, min_child_weight=1,
missing=nan, monotone_constraints='()', n_estimators=150,
n_jobs=0, num_parallel_tree=1, predictor='auto', random_state=0,
reg_alpha=0, reg_lambda=1, ...):
precision recall f1-score support
0 0.89 0.95 0.92 2218
1 0.72 0.52 0.60 549
accuracy 0.86 2767
macro avg 0.80 0.73 0.76 2767
weighted avg 0.85 0.86 0.86 27674.7 CatBoostClassifier
from catboost import CatBoostClassifier
cab=CatBoostClassifier(iterations=10)
create_model(cab)
--------------------------------------代码分割线--------------------------------------------
Learning rate set to 0.5
0: learn: 0.4772704 total: 142ms remaining: 1.27s
1: learn: 0.4010936 total: 143ms remaining: 570ms
2: learn: 0.3680817 total: 144ms remaining: 336ms
3: learn: 0.3486839 total: 145ms remaining: 218ms
4: learn: 0.3360775 total: 147ms remaining: 147ms
5: learn: 0.3280172 total: 148ms remaining: 98.7ms
6: learn: 0.3221241 total: 150ms remaining: 64.1ms
7: learn: 0.3176367 total: 151ms remaining: 37.7ms
8: learn: 0.3148666 total: 152ms remaining: 16.9ms
9: learn: 0.3115188 total: 153ms remaining: 0us
Test Accuracy of :0.8760390314419949
Confusion Matrix of :
[[2148 70]
[ 273 276]]
Classification Report of :
precision recall f1-score support
0 0.89 0.97 0.93 2218
1 0.80 0.50 0.62 549
accuracy 0.88 2767
macro avg 0.84 0.74 0.77 2767
weighted avg 0.87 0.88 0.86 2767
4.8 ExtraTreesClassifier
from sklearn.ensemble import ExtraTreesClassifier
etc=ExtraTreesClassifier()
create_model(etc)
-------------------------------代码分割线--------------------------------------
Test Accuracy of ExtraTreesClassifier():0.8695337911095049
Confusion Matrix of ExtraTreesClassifier():
[[2158 60]
[ 301 248]]
Classification Report of ExtraTreesClassifier():
precision recall f1-score support
0 0.88 0.97 0.92 2218
1 0.81 0.45 0.58 549
accuracy 0.87 2767
macro avg 0.84 0.71 0.75 2767
weighted avg 0.86 0.87 0.85 27674.9 LGBMClassifier
from lightgbm import LGBMClassifier
lgbm=LGBMClassifier(learning_rate=0.1)
create_model(lgbm)
-----------------------------代码分割线------------------------------------------
Test Accuracy of LGBMClassifier():0.8764004336826888
Confusion Matrix of LGBMClassifier():
[[2143 75]
[ 267 282]]
Classification Report of LGBMClassifier():
precision recall f1-score support
0 0.89 0.97 0.93 2218
1 0.79 0.51 0.62 549
accuracy 0.88 2767
macro avg 0.84 0.74 0.77 2767
weighted avg 0.87 0.88 0.87 27674.10 svm
from sklearn import svm
wclf=svm.SVC(kernel='rbf',class_weight={1:3})
create_model(wclf)
--------------------------------代码分割线------------------------------------
Test Accuracy of SVC(class_weight={1: 3}):0.8015901698590532
Confusion Matrix of SVC(class_weight={1: 3}):
[[2218 0]
[ 549 0]]
Classification Report of SVC(class_weight={1: 3}):
precision recall f1-score support
0 0.80 1.00 0.89 2218
1 0.00 0.00 0.00 549
accuracy 0.80 2767
macro avg 0.40 0.50 0.44 2767
weighted avg 0.64 0.80 0.71 27675.绘制模型评分直方图
models=pd.DataFrame({"model":["SVM","KNN","Decision Tree","Random Forest","Ada Boost","Gradient Boosting","XgBoost","catBoost","Extra Trees","LGBM"],
"acc":[0.802,0.804,0.806,0.878,0.809,0.879,0.864,0.876,0.869,0.876]})
models=models.sort_values("acc",ascending=True)
px.bar(models
,x="acc"
,y="model"
,text="acc"
,color='acc'
,template='plotly_dark'
,title='Models Comparision')
6.模型可解释性
在这里选择Gradient Boost(gb)同时使用shap库来进行解释
6.1 shap值计算
# 模型可解释性,选择Extra Tree(etc)
explainer=shap.TreeExplainer(gb)
# 在explainer中传入特征值的数据,计算shap值
shap_values=explainer.shap_values(x_test)
shap_values
-------------------------------------------------------------------
array([[-1.62093641e-01, -2.90161088e-02, 1.17664011e-01, ...,
-1.07458257e-05, -3.58140368e-01, 1.20403416e-02],
[-1.51243735e-01, -4.63661455e-02, 1.47073454e-01, ...,
-1.07458257e-05, 4.34854369e-01, -1.76490066e-01],
[-1.93332535e-01, -6.02414362e-02, -1.25060216e-01, ...,
1.07458257e-05, -2.47356490e-01, -3.77205325e-02],
...,
[-6.51192238e-02, -3.84451253e-02, 1.61559034e-01, ...,
4.56697590e-05, -2.59919373e-01, 2.10393113e-02],
[-1.50441872e-01, 1.86815435e-03, -1.54295830e-01, ...,
-1.07458257e-05, 3.89491535e-01, -4.21581673e-02],
[-1.76659921e-01, -1.06582926e-01, -1.20482271e-01, ...,
1.07458257e-05, -2.99516880e-01, 4.03566576e-02]])6.2 Feature importance
shap.summary_plot(shap_values,x_test,plot_type="bar")
shap.summary_plot(shap_values,x_test)
任务5.2

fact_data=pd.read_csv('F:\泰迪杯B题\B题:银行客户忠诚度分析赛题数据\B题:银行客户忠诚度分析赛题数据\long-customer-test.csv')
pred=gb.predict(fact_data)
CustomerId=[]
for i in range(len(fact_data["CustomerId"])):
CustomerId.append(0)
for i in range(len(fact_data["CustomerId"])):
CustomerId[i]=fact_data.loc[i,"CustomerId"]
pred
--------------------------------------------------------------------------------------
array([0, 1, 0, 1, 0, 0, 1, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0,
1, 0, 0, 0, 0, 1, 1, 0, 1, 1, 1, 0, 0, 1, 1, 1, 1, 0, 0, 0, 0, 0,
0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
1, 0, 1, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0,
0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0,
0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 1, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0,
0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0,
1, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 1, 0, 0, 1, 0, 0,
0, 0, 1, 1, 0, 0, 0, 0, 1, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0,
0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0,
0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 1, 0, 0, 0, 0, 0, 1, 1, 0, 1, 0, 0, 0, 0, 1, 0, 1, 1, 0, 0, 0,
1, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 1, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1,
1, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 1,
0, 1, 0, 0, 1, 0, 0, 1, 1, 0, 0, 1, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1,
0, 0, 1, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0,
1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0,
0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0,
0, 0, 1, 0, 1, 1, 1, 0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0,
1, 0, 0, 0, 1, 1, 1, 1, 0, 0, 0, 1, 0, 1, 0, 1, 0, 0, 1, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 1, 0, 0, 1, 1, 0, 1,
0, 0, 1, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 1,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 1, 0, 1, 0, 0,
0, 0, 0, 0, 1, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 0,
1, 0, 0, 0, 1, 0, 0, 0, 1, 0, 1, 1, 0, 0, 0, 0, 0, 1, 1, 0, 0, 1,
0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 1, 0, 0, 1, 0, 0, 0, 1, 0, 0, 1, 0, 0, 1, 0, 1, 0, 0, 1, 0,
0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 1, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0,
1, 0, 0, 0, 0, 1, 1, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1,
0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0,
0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 1, 0, 0, 1, 0, 1, 0, 0, 1, 1, 0,
0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 1, 0, 1, 0, 0,
0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0,
0, 1, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0,
0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0,
0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0,
0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 1, 0, 0,
0, 0, 1, 0, 0, 0, 0, 1, 0, 0], dtype=int64)写入文件
data_1={'CustomerId':CustomerId,'Exited':pred}
df_1=pd.DataFrame(data_1)
df_1.to_excel('F:\\泰迪杯B题\\B题:银行客户忠诚度分析赛题数据\\result5.xlsx',sheet_name='sheet1',index=None)部分预测结果如下:
| Customerld | Exited |
|---|---|
| 15779131 | 0 |
| 15674442 | 0 |
| 15719508 | 1 |
| 15730076 | 1 |
| 15792228 | 1 |
至此,整个题目基本完成!

比赛总结
首先,这是我第一次单独一个人参加并完成比赛,这个比赛组队规则是1-3人组队,我没有组队的原因其实有很多(这里就不说了……)。接下来说说这次比赛好的方面和一些不足的地方吧。
good
好的方面当然是题目能做完且按时提交啦,因为B题比赛时间是周日,A题比赛时间是周六,然后第一天A题的题目确实是有点不按套路出牌,我本来给自己设定的时间是下午6点就开始写论文的,结果到6点题目只做了一半不到(o(╥﹏╥)o),最后还是放弃做题开始写论文,整个过程都很不尽人意。B题能做完主要是算法部分有提前准备算法和代码,所以整个过程感觉还是良好的,也积累了不少经验。
bad
1.最大最大的问题:虽然题目有做完,但是论文质量不高(可能是第一次写论文的原因吧,之前都是队友写的),最大的问题就是论文忘了加标题,论文的排版、说明、过程叙述也都不是很好。

2.比赛过程也反映了自己对代码不够熟练,整道题基本每解决一个小任务都要csdn
3.比赛状态也不是很好,睡眠不足+能量不足(因为单独参赛赶时间,直到下午两点辅导员催做核酸顺路在饭堂买了点吃的)
总之,能在比赛中找到自己的不足还是值得的,争取下次能做得更好吧!
接下来该准备期末考了(⊙﹏⊙)