深度学习基础——week2
!!!更好的阅读体验!!!
卷积神经网络(Convolutional Neural Network, CNN)
深度学习三部曲
-
Step1: 搭建神经网络结构
-
Step2: 找到一个合适的损失函数(Cost Function)
Eg : 回归损失:均方误差(MSE),平均绝对值误差(MAE)
分类损失:交叉熵损失,hinge loss
-
Step3: 找到一个合适的优化函数,更新参数
反向传播(BP),随机梯度下降(SGD),螺旋数据分类用的 Adam 等等。
全连接与卷积
全连接层的花费是巨大的,一张百万像素的图片输入维度1000000,假如隐藏层维度为1000,那么就需要 1 0 9 10^9 109个参数。此外拟合这么多的参数也需要巨量的数据,参数过多也可能会出现导致参数过多的过拟合现象。CNN是机器学习利用自然图像中一些已知结构(平移不变性、局部性等)的创造性方法。
基本概念
图像卷积
Input:输入 Kernel/filter:卷积核 weights:权重 output:输出
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FWzVF1Ja-1655473362032)(http://d2l.ai/_images/correlation.svg)]
显然,输出大小等于输入大小 n h × n w n_h \times n_w nh×nw减去卷积核大小 k h × k w k_h \times k_w kh×kw再加1,即: ( n h − k h + 1 ) × ( n w − k w + 1 ) . (n_h-k_h+1) \times (n_w-k_w+1). (nh−kh+1)×(nw−kw+1).
填充和步幅
填充
在应用多层卷积时,我们常常丢失边缘像素。解决这个问题的简单方法即为填充(padding):在输入图像的边界填充元素(通常填充元素是0)。显然输出形状为: ( n h − k h + p h + 1 ) × ( n w − k w + p w + 1 ) 。 (n_h-k_h+p_h+1)\times(n_w-k_w+p_w+1)。 (nh−kh+ph+1)×(nw−kw+pw+1)。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rje7pgHo-1655473362033)(https://zh.d2l.ai/_images/conv-pad.svg)]
在许多情况下,我们需要设置 p h = k h − 1 p_h=k_h-1 ph=kh−1和 p w = k w − 1 p_w=k_w-1 pw=kw−1,使输入和输出具有相同的高度和宽度。
卷积神经网络中卷积核的高度和宽度通常为奇数,例如1、3、5或7。选择奇数的好处是,保持空间维度的同时,我们可以在顶部和底部填充相同数量的行,在左侧和右侧填充相同数量的列。
步幅
每次滑动元素的数量称为步幅(stride)。当垂直步幅为 s h s_h sh、水平步幅为 s w s_w sw时,输出形状为 ⌊ ( n h − k h + p h + s h ) / s h ⌋ × ⌊ ( n w − k w + p w + s w ) / s w ⌋ . \lfloor(n_h-k_h+p_h+s_h)/s_h\rfloor \times \lfloor(n_w-k_w+p_w+s_w)/s_w\rfloor. ⌊(nh−kh+ph+sh)/sh⌋×⌊(nw−kw+pw+sw)/sw⌋.
填充和步幅可用于有效地调整数据的维度。
多输入多输出通道
多输入通道
如果有一张RGB的彩色图像具有 3 × h × w 3\times h\times w 3×h×w的形状。我们将这个大小为3的轴称为通道(channel)维度。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-K8vvtYeN-1655473362033)(https://zh.d2l.ai/_images/conv-multi-in.svg)]
如上图,在输入通道是2,输出通道是1的情况下。我们给每一个通道配一个卷积核,最后将得到的2个结果相加。
多输出通道
在最流行的神经网络架构中,随着神经网络层数的加深,我们常会增加输出通道的维数,通过减少空间分辨率以获得更大的通道深度。直观地说,我们可以将每个通道看作是对不同特征的响应。
用 c i c_i ci和 c o c_o co分别表示输入和输出通道的数目,并让 k h k_h kh和 k w k_w kw为卷积核的高度和宽度。为了获得多个通道的输出,我们可以为每个输出通道创建一个形状为 c i × k h × k w c_i\times k_h\times k_w ci×kh×kw的卷积核张量,这样卷积核的形状是 c o × c i × k h × k w c_o\times c_i\times k_h\times k_w co×ci×kh×kw。在运算中,每个输出通道先获取所有输入通道,再以对应该输出通道的卷积核计算出结果。
池化
池化(pooling)层具有双重目的:降低卷积层对位置的敏感性,同时降低对空间降采样表示的敏感性。一般有最大池化层(maximum pooling)和平均池化层(average pooling)。池化同样有填充、步幅、多输入输出等概念。
CNN典型结构

AlexNet
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BM2qXOko-1655473362034)(https://zh.d2l.ai/_images/alexnet.svg)]
AlexNet和LeNet的设计理念非常相似,但也存在显著差异。 首先,AlexNet比相对较小的LeNet5要深得多。 AlexNet由八层组成:五个卷积层、两个全连接隐藏层和一个全连接输出层。 其次,AlexNet使用ReLU而不是sigmoid作为其激活函数。
VGG

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-d309IDDo-1655473362034)(https://zh.d2l.ai/_images/vgg.svg)]
VGG-11使用可复用的卷积块构造网络。不同的VGG模型可通过每个块中卷积层数量和输出通道数量的差异来定义。
块的使用导致网络定义的非常简洁。使用块可以有效地设计复杂的网络。
在VGG论文中,Simonyan和Ziserman尝试了各种架构。特别是他们发现深层且窄的卷积(即3×3)比较浅层且宽的卷积更有效。
GoogLeNet
在GoogLeNet中,基本的卷积块被称为Inception块。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oMfPrdhc-1655473362034)(https://zh.d2l.ai/_images/inception.svg)]
Inception块由四条并行路径组成。 前三条路径使用窗口大小为1×1、3×3和5×5的卷积层,从不同空间大小中提取信息。 中间的两条路径在输入上执行1×1卷积,以减少通道数,从而降低模型的复杂性。 第四条路径使用3×3最大池化层,然后使用1×1卷积层来改变通道数。 这四条路径都使用合适的填充来使输入与输出的高和宽一致,最后我们将每条线路的输出在通道维度上连结,并构成Inception块的输出。在Inception块中,通常调整的超参数是每层输出通道数。
那么为什么GoogLeNet这个网络如此有效呢? 首先我们考虑一下 filter 的组合,它们可以用各种滤波器尺寸探索图像,这意味着不同大小的滤波器可以有效地识别不同范围的图像细节。 同时,我们可以为不同的滤波器分配不同数量的参数。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JHWSXKKw-1655473362035)(https://zh.d2l.ai/_images/inception-full.svg)]
GoogLeNet一共使用9个Inception块和全局平均汇聚层的堆叠来生成其估计值。Inception块之间的最大汇聚层可降低维度。 第一个模块类似于AlexNet和LeNet,Inception块的组合从VGG继承,全局平均汇聚层避免了在最后使用全连接层。
ResNet
残差网络的核心思想是:每个附加层都应该更容易地包含原始函数作为其元素之一。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yErqTuvL-1655473362035)(https://zh.d2l.ai/_images/residual-block.svg)]
如上图,假设我们的原始输入为x,而希望学出的理想映射为()。左图虚线框中的部分需要直接拟合出该映射(),而右图虚线框中的部分则需要拟合出残差映射()−。残差映射在现实中往往更容易优化。 实际中,当理想映射()极接近于恒等映射(f(x)=x)时,残差映射也易于捕捉恒等映射的细微波动。右图是ResNet的基础架构–残差块(residual block)。 在残差块中,输入可通过跨层数据线路更快地向前传播。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WYO6qJeF-1655473362035)(https://zh.d2l.ai/_images/resnet18.svg)]
最后的全局平均池化替代了全连接层。
通过配置不同的通道数和模块里的残差块数可以得到不同的ResNet模型。50-layer以上的ResNet网络中有着BottleNeck瓶颈结构(先降维再升维,减少参数量)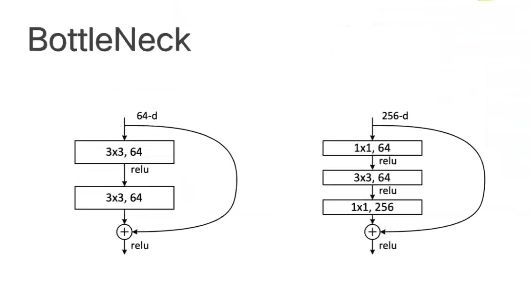
代码练习
MNIST 数据集分类
使用MNIST:
torchvision.datasets.MNIST(root, train=True, transform=None, target_transform=None, download=False)
- root 为数据集下载到本地后的根目录,包括 training.pt 和 test.pt 文件
- train,如果设置为True,从training.pt创建数据集,否则从test.pt创建。
- download,如果设置为True, 从互联网下载数据并放到root文件夹下
- transform, 一种函数或变换,输入PIL图片,返回变换之后的数据。
- target_transform 一种函数或变换,输入目标,进行变换。
创建全连接网络和CNN网络(待会我们要比较两个网络的效果):
class FC2Layer(nn.Module):
def __init__(self, input_size, n_hidden, output_size):
#继承
super(FC2Layer, self).__init__()
self.input_size = input_size
# 这里直接用 Sequential 就定义了网络
self.network = nn.Sequential(
nn.Linear(input_size, n_hidden),
nn.ReLU(),
nn.Linear(n_hidden, n_hidden),
nn.ReLU(),
nn.Linear(n_hidden, output_size),
nn.LogSoftmax(dim=1)
)
def forward(self, x):
# view一般出现在model类的forward函数中,用于改变输入或输出的形状
# x.view(-1, self.input_size) 的意思是多维的数据展成二维
x = x.view(-1, self.input_size)
return self.network(x)
class CNN(nn.Module):
def __init__(self, input_size, n_feature, output_size):
super(CNN, self).__init__()
# 下面是网络里典型结构的一些定义,一般就是卷积和全连接
# 池化、ReLU一类的不用在这里定义
self.n_feature = n_feature
self.conv1 = nn.Conv2d(in_channels=1, out_channels=n_feature, kernel_size=5)
self.conv2 = nn.Conv2d(n_feature, n_feature, kernel_size=5)
self.fc1 = nn.Linear(n_feature*4*4, 50)
self.fc2 = nn.Linear(50, 10)
# 下面的 forward 函数,定义了网络的结构,按照一定顺序,把上面构建的一些结构组织起来
def forward(self, x, verbose=False):
x = self.conv1(x)
x = F.relu(x) #relu
x = F.max_pool2d(x, kernel_size=2)#池化
x = self.conv2(x)
x = F.relu(x)
x = F.max_pool2d(x, kernel_size=2)
x = x.view(-1, self.n_feature*4*4)
x = self.fc1(x)
x = F.relu(x)
x = self.fc2(x)
x = F.log_softmax(x, dim=1)
return x
训练函数
def train(model):
model.train()
# 主里从train_loader里,64个样本一个batch为单位提取样本进行训练
for batch_idx, (data, target) in enumerate(train_loader):
# 把数据送到GPU中
data, target = data.to(device), target.to(device)
optimizer.zero_grad() # 优化器梯度归零
output = model(data)#得到当前的输出
loss = F.nll_loss(output, target)#计算loss
loss.backward()
optimizer.step()#优化
if batch_idx % 100 == 0:
print('Train: [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
测试函数
def test(model):
model.eval()
test_loss = 0
correct = 0
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
# 计算本次batch的损失,并加到 test_loss 中
test_loss += F.nll_loss(output, target, reduction='sum').item()
# get the index of the max log-probability,最后一层输出10个数,
# 值最大的那个即对应着分类结果,然后把分类结果保存在 pred 里
pred = output.data.max(1, keepdim=True)[1]
# 将 pred 与 target 相比,得到正确预测结果的数量,并加到 correct 中
# 这里需要注意一下 view_as ,意思是把 target 变成维度和 pred 一样的意思
correct += pred.eq(target.data.view_as(pred)).cpu().sum().item()
test_loss /= len(test_loader.dataset)
accuracy = 100. * correct / len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
accuracy))
结果
含有相同参数的 CNN 效果要明显优于简单的全连接网络,是因为 CNN 能够更好的挖掘图像中的信息。
从打乱像素顺序的实验结果来看,全连接网络的性能基本上没有发生变化,但是 卷积神经网络的性能明显下降。这是因为对于卷积神经网络,会利用像素的局部关系,但是打乱顺序以后,这些像素间的关系将无法得到利用。
CIFAR10 数据集分类
定义CNN网络
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net().to(device)
criterion = nn.CrossEntropyLoss()#损失函数
optimizer = optim.Adam(net.parameters(), lr=0.001)#优化函数
训练网络
for epoch in range(10): # 重复多轮训练
for i, (inputs, labels) in enumerate(trainloader):
inputs = inputs.to(device)
labels = labels.to(device)
# 优化器梯度归零
optimizer.zero_grad()
# 正向传播 + 反向传播 + 优化
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 输出统计信息
if i % 100 == 0:
print('Epoch: %d Minibatch: %5d loss: %.3f' %(epoch + 1, i + 1, loss.item()))
结果
准确率63%
![]()
使用 VGG16 对 CIFAR10 分类
建立模型
最开始的代码好像不能直接运行,改两个地方:self.features = self._make_layers(self.cfg)、self.classifier = nn.Linear(512, 10)。改了过后就可以跑了。
class VGG(nn.Module):
def __init__(self):
super(VGG, self).__init__()
self.cfg = [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M']
self.features = self._make_layers(self.cfg)
self.classifier = nn.Linear(512, 10)
def forward(self, x):
out = self.features(x)
out = out.view(out.size(0), -1)
out = self.classifier(out)
return out
def _make_layers(self, cfg):
layers = []
in_channels = 3
for x in cfg:
if x == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
layers += [nn.Conv2d(in_channels, x, kernel_size=3, padding=1),
nn.BatchNorm2d(x),
nn.ReLU(inplace=True)]
in_channels = x
layers += [nn.AvgPool2d(kernel_size=1, stride=1)]
return nn.Sequential(*layers)
结果
准确率83.87%
![]()