QoS服务模型
QoS服务模型
- 1.QoS概念
- 2.影响网络质量的四大因素
-
- 2.1带宽
- 2.2时延
- 2.3抖动
- 2.4丢包
- 3.改善通信质量的方案
-
- 3.1尽力而为服务模型
-
- 3.1.1增大网络带宽
- 3.1.2升级网络设备
- 3.2综合服务模型
- 3.3区分服务模型
- 4.QoS报文分类与标记
-
- 4.1简单流分类/哪些报文中运用到QoS优先级
-
- 4.1.1Vlan帧头中的802.3p字域中的PRI字段
- 4.1.2MPLS报文中的EXP字段
- 4.1.3IP报文中的Type of Service字段
-
- DSCP字段
- 4.2复杂流分类
-
- 4.2.1复杂流配置案例
- 5.拥塞管理与拥塞避免
-
- 5.1拥塞管理的七种调度算法
-
- 5.1.1FIFO
- 5.1.2PQ(Prioroty Queueing)
- 5.1.3WRR(Weighted Round Robin)
- 5.1.4WFQ(Weighted Fair Queueing)
- 5.1.5 PQ+WFQ
- 5.1.6CBQ(Class-based Queueing)
- 5.2拥塞避免
-
- 5.2.1尾丢弃的缺点
- 6流量监管与流量整形
-
- 6.1流量管理
- 6.2流量整形
- 6.3流量监管与流量整形比较
- 7.问题总结
1.QoS概念
指一个网络能够利用各种基础技术,为指定的网络通信提供更好的服务能力,是网络的一种安全机制, 是用来解决网络延迟和阻塞等问题的一种技术
2.影响网络质量的四大因素
2.1带宽
最大带宽BWmax=传输路径上的最小带宽
2.2时延
 传输时延:一个数据位从发送方到达接收方所需要的时间。该时延取决于传输距离和传输介质,与带宽无关。
传输时延:一个数据位从发送方到达接收方所需要的时间。该时延取决于传输距离和传输介质,与带宽无关。
串行化时延:指发送节点在传输链路上开始发送报文的第一个比特至发完该报文的最后一个比特所需的时间。该时延取决于链路带宽以及报文大小。
处理时延:指路由器把报文从入接口放到出接口队列需要的时间。它的大小跟路由器的处理性能有关。
队列时延:指报文在队列中等待的时间。它的大小跟队列中报文的大小和数量、带宽以及队列机制有关。
2.3抖动
概念:由于每个报文的端到端时延不一样,就会导致这些报文不能等间隔到达目的端,这种现象叫做抖动
2.4丢包
处理过程:路由器在收到报文的时候可能由于CPU繁忙,无法处理报文而导致丢包;
排队过程:在把报文调度到队列的时候可能由于队列被装满而导致丢包
传输过程:报文在链路上传输的过程中,可能由于种种原因(如链路故障等)导致的丢包
3.改善通信质量的方案
3.1尽力而为服务模型
Best Effort Service Modle
对时延,可靠性不提供保证,适用于绝大多数网络应用,如:FTP,E-Mail
缺省下的服务模型,通过先入先出FIFO队列实现
3.1.1增大网络带宽
优点:改善带宽瓶颈,串行化延迟
缺点:网络建设成本高
3.1.2升级网络设备
优点:改善处理延迟,队列延迟,丢包等
缺点:成本高,替换设备增大业务风险
3.2综合服务模型
Intergrated Service Modle

优点:可以为某些特定业务提供带宽,延迟有保证
缺点:
1.实现比较复杂;
2.无流量发送时,仍然占有带宽
3.要求方案中所有节点都要支持RSVP协议
*RSVP协议工作过程:在应用程序发送报文前,需要向网络申请特定的带宽和所需的特定服务质量的请求,等收到确认信息后才发送报文。
3.3区分服务模型
Differtentiated Service Modle
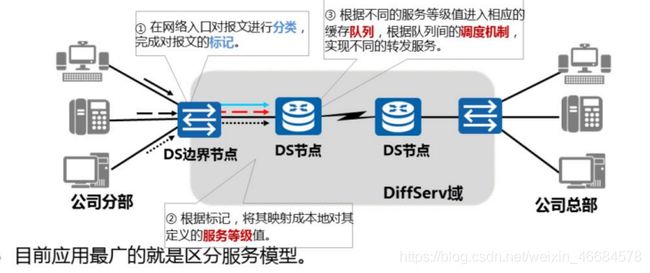
优点:灵活,可扩展性强,将复杂的服务质量保证通过报文自身携带的信息转化为单挑行为
工作过程:首先将网络中的流量分成多个类,然后为每个类定义相应的处理行为,使其拥有不同的优先转发,丢包率,时延。
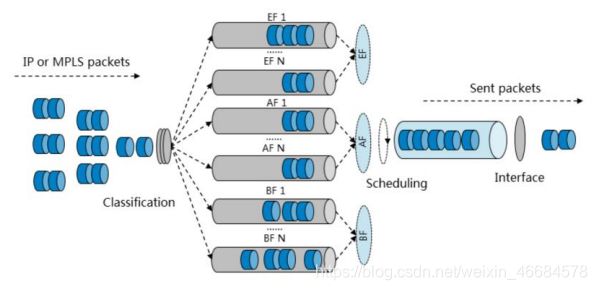
4.QoS报文分类与标记
作用:用于QoS模型中的区分服务模型,是部署DiffServ QoS的基础
4.1简单流分类/哪些报文中运用到QoS优先级
复杂流分类:基于源目端口,源目IP,协议号(五元组)
注:以下的三种报文都是按照QoS优先级这一种粗略的方式,因此叫做简单流分类
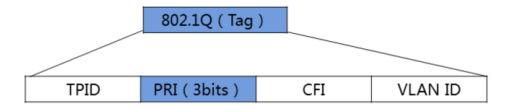
4.1.1Vlan帧头中的802.3p字域中的PRI字段
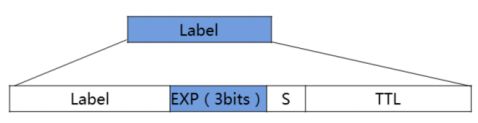
4.1.2MPLS报文中的EXP字段
4.1.3IP报文中的Type of Service字段

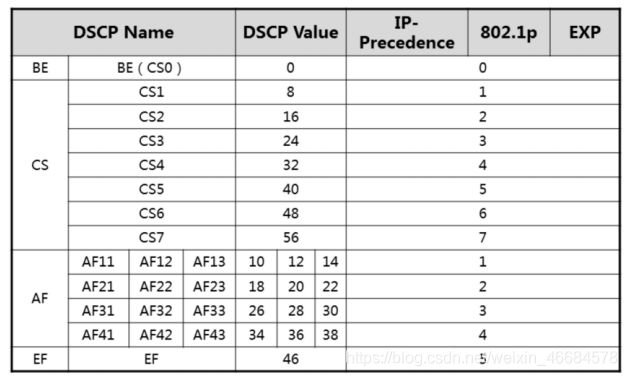
DSCP字段
注:由于IP=Precedence只有3bits,远远不能满足需要。
因此将其扩展为6bits(占用了D/T/R),这6bits被称为IP报文的DSCP字段
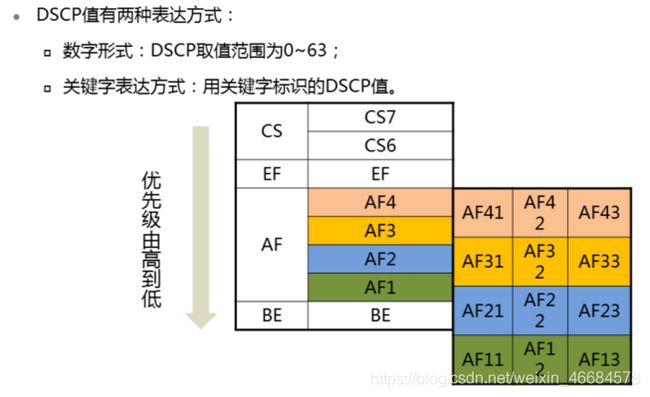
AFxy中,x代表不同的类别,y代表当队列被装满的时候丢包的概率,例如AF1类中的报文,其中丢包概率由小到大排序为AF11
不同关键字常用于标识不同报文(可自行定义):
CS6和CS7默认用于协议报文,而且是大多数厂商设备的硬件队列里最高优先级的报文,因为如果这些报文无法接收的话会引起协议中断。
EF常用于承载语音的流量,因为语音要求低延迟,低抖动,低丢包率,是仅次于协议报文的最重要的报文。
AF4用来承载语音的信令流量,这里的信令是电话的呼叫控制,绝对不能允许在通话的时候的中断。所以语音要优先于信令。
AF3可以用来承载IPTV的直播流量,直播的实时性很强,需要连续性和大吞吐量的保证。
AF2可以用来承载VOD(Video on Demand:视频点播)的流量,相对于直播流量来说,VOD对实时性要求没那么强烈,允许有时延或者缓冲。
AF1可以用来承载普通上网业务。
4.2复杂流分类
由于某些客户的需求,简单流分类无法满足。
Eg:对于领导的流量(不论是语音流量,短信流量等QoS中优先级低的流量),始终优先转发。
此时需要复杂流分类,标记,策略一系列的操作。
4.2.1复杂流配置案例
四步骤思想:分类——>标记——>策略——>接口下应用
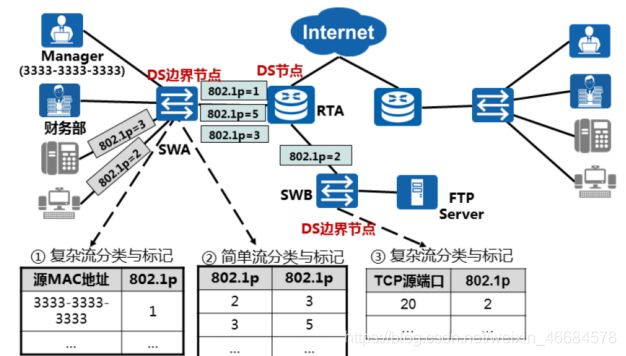
//分类
traffic classifier manager if-match source-mac xxxx-xxxx-xxxx-xxxx
traffic classifier voice if-match 8021p 3、
//标记 — 相当于重新排序,给每一个位置编写一个名字,例如:manager
traffic behavior manager remark 8021p 1 //manager被标记为1
traffic behavior voice remark 8021p 5 //voice被重新标记为5
//策略 — 将分类的流量放入新编的位置,转发时按照新编的顺序
traffic policy a1 classifier manager behavior manager
traffic voice a2 classifier manager behavior voice
//应用
int g0/0/0 traffic-policy a1 inbound
int g0/0/1 traffic-policy a2 inbound
5.拥塞管理与拥塞避免
出现拥塞的原因:
1.汇聚问题:多条分支链路汇聚到一条链路,导致带宽不够用
2.速率不匹配:从高带宽链路进入设备,再由低带宽链路转发
拥塞的负面影响:
1.过高时延导致数据重传
2.增加报文传输的时延和抖动
3.网络有效吞吐率降低
4.浪费网络资源
拥塞管理两步骤:
1.排队:将接收的报文放入设备的不同的缓存队列中。将报文中包含的QoS优先级(或端口优先级)映射成设备内部的优先级,然后根据内部优先级(0-7,共8个优先级)和队列的映射关系,将报文放入不同的队列中。
2.调度:根据各队列的调度机制实现不同报文的差分转发
5.1拥塞管理的七种调度算法
拥塞管理的本质就是排队
5.1.1FIFO
先进先出,是设备的默认调度算法
5.1.2PQ(Prioroty Queueing)
原理:优先级从高到低依次分为4个队列。在报文出队的时候,PQ会先让最高优先级的出队,当最高优先级报文全部出队后,在让次高优先级出队,以此类推。
优点:高优先级报文能够优先转发
缺点:较低优先级的报文可能一直发不出去,出现“饿死”的现象。
5.1.3WRR(Weighted Round Robin)
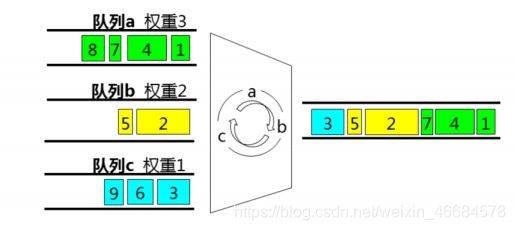
原理:根据每个队列的权重n,轮流调度每个队列中的报文。
优点:避免了PQ的饿死现象。
缺点:
1.按照权重划分,但权重不是优先级,导致高优先级队列无法优先发送。
2.有可能低延时的报文无法及时调度
5.1.4WFQ(Weighted Fair Queueing)
关键词:权重 Weight
权重不同,带宽不同
原理:
1.入队:WFQ对报文按流特征进行分类,对于IP网络,相同源IP地址、目的IP地址、源端口号、目的端口号、协议号、ToS的报文属于同一个流,而对于MPLS网络,具有相同的标签和EXP域值的报文属于同一个流。每一个流被分配到一个队列,该过程称为散列,采用HASH算法来自动完成,这种方式会尽量将不同特征的流分入不同的队列中。WFQ允许的队列数目是有限的,用户可以根据需要配置该值
2.调度:WFQ按流的优先级来分配每个流应占有的出口带宽。优先级的数值越小,所得的带宽越少。
优点:
1.按照权重分配带宽,长报文和短报文能够公平调度
2.WFQ在计算报文调度次序时增加了优先权方面的考虑。从统计上,WFQ使高优先权的报文获得优先调度的机会多于低优先权的报文
缺点:
1.若流的种类多,可能多个流进入同一个队列。同一队列中的报文有长有短,排列无序,因此低延时业务(短报文)仍然得不到及时调度;
2.无法实现用户自定义分类规则;
5.1.5 PQ+WFQ
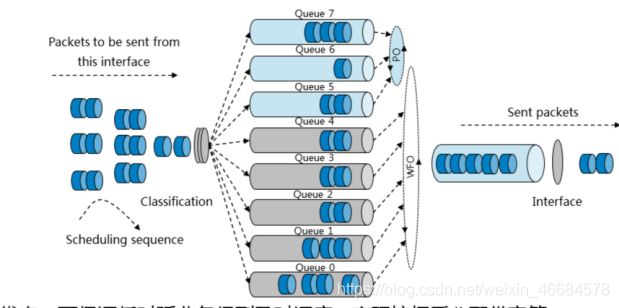
原理:
如图,在进行调度时,首先按照PQ方式优先调度Queue7、Queue6和Queue5队列中的报文流,只有这些队列中的报文流全部调度完毕后,才开始以WFQ方式调度Queue4、Queue3、Queue2、Queue1和Queue0队列中的报文流。
重要的协议报文或者有低延时需求的报文放入PQ调度队列中。
优点:
低延时的报文能够及时调度
缺点:
无法根据用户自定义灵活分类报文的需求
5.1.6CBQ(Class-based Queueing)
原理:
基于类的加权公平队列是对WFQ功能的扩展,为用户提供了自定义类的支持。
CBQ首先根据IP优先级或者DSCP优先级、入接口、IP报文的五元组等规则来对报文进行分类,然后让不同类别的报文进入不同的队列。对于不匹配任何类别的报文,会送入系统定义的缺省类。
CBQ三队列:
EF队列:满足低时延业务。
EF队列拥有绝对优先级,仅当EF队列中的报文调度完毕后,才会调度其他队列中的报文。
AF队列:满足需要带宽保证的关键数据业务。
每个AF队列分别对应一类报文,用户可以设定每类报文占用的带宽。当系统调度报文出队的时候,会按用户为各类报文设定的带宽将报文进行出队发送,可实现各个类的队列的公平调度。
BE队列:满足不需要严格QoS保证的尽力发送业务。
当报文不匹配用户设定的所有类别时,报文会被送入系统定义的缺省BE(Best Effort,尽力传送)类。BE队列使用接口剩余带宽和WFQ调度方式进行发送。
优点:
提供了自定义类的支持;可为不同的业务定义不同的调度策略
缺点:
涉及到复杂的流分类,启用CBQ会耗费一定的系统资源
5.2拥塞避免
尽量缓解拥塞现象出现的丢包等不良后果。
传统的处理方式是尾丢弃
5.2.1尾丢弃的缺点
1.引发TCP全局同步现象

TCP滑动窗口机制:
滑动窗口本质上是描述接受方的TCP数据报缓冲区大小的数据,发送方根据这个数据来计算自己最多能发送多长的数据。如果发送方收到接受方的窗口大小为0的TCP数据报,那么发送方将停止发送数据,等到接受方发送窗口大小不为0的数据报的到来。
建立TCP链接后,发送方不断发送越来越多的数据包,发送方的窗口中是一些未收到ack确认的数据包,当发送方的窗口值达到最大时,停止发送过程。此时接收方的缓冲区外的数据包都要丢弃,此时发送方滑动窗口就会变小,发包速度减慢(滑动窗口大小会随着数据包而改变),然后在缓慢增加发送数据包的速度;当再次出现丢包时,重复之前的操作。这样尽可能使数据快速发送,又不至于丢包。
TCP全局同步:
对于TCP报文,如果大量的报文被丢弃,将造成TCP超时,从而引发TCP慢启动,使得TCP减少报文的发送。当队列同时丢弃多个TCP连接的报文时,将造成多个TCP连接同时进入拥塞避免和慢启动状态以调整并降低流量,这就被称为TCP全局同步现象。这样多个TCP连接发往队列的报文将同时减少,而后又会在某个时间同时出现流量高峰,如此反复,使网络资源利用率低。
解决TCP全局同步:早期随机检测RED
可在队列未装满时先随机丢弃一部分报文。通过预先降低一部分TCP链接的传输速率来尽可能延缓TCP全局同步的到来。
2.引起TCP饿死
原理:当接收方的缓存队列已经被装满时,TCP发送方会减小窗口大小,减少数据的发送,此时链路被空闲出来的流量,就会被无连接的UDP占用。当接收方缓存队列再次被填满时,会继续减小TCP的窗口大小,减少TCP流量的发送,久而久之,会引起TCP饿死现象。
3.无差别的丢弃
原理:尾丢弃很有可能导致大量非关键数据被转发,而大量关键数据被丢弃。
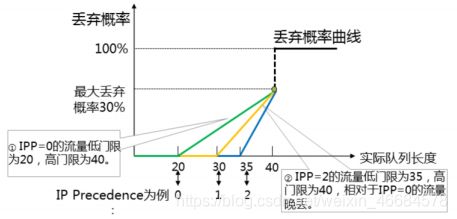
解决TCP饿死和无差别丢弃:WRED
可实现每一种优先级都能独立设置报文的丢包的高门限、低门限及丢包率,
报文到达低门限时,开始丢包,
随着门限的增高,丢包率不断增加,
最高丢包率不超过设置的最大丢包率,直至到达高门限,报文全部丢弃。
这样按照一定的丢弃概率主动丢弃队列中的报文,从一定程度上避免了尾丢弃带来的所有缺点
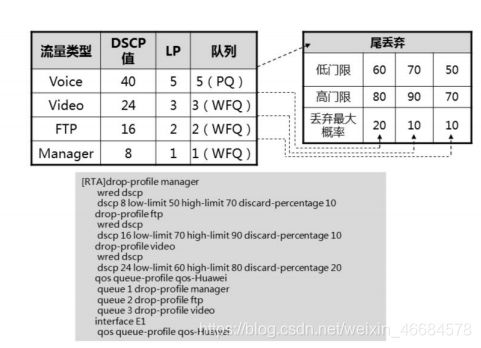
WRED配置
1.配置(dscp,高门限,低门限等信息)
drop-profile manager
wred dscp //基于dscp
dscp 8 low-limit 50 high-limit 70discard-percentage 10
2.队列丢弃
queue 1 drop-profile manager
3.接口配置
interface g0/0/0
qos queue-profile qos-Huawei
6流量监管与流量整形
本质:限速
网络中拥塞现象很常见,若不限制用户发送的业务流量,大量用户不断发送数据会使得网络更加拥堵。
6.1流量管理
配置在设备的入口端。将流量转发速度限制在一个范围内,如果报文转发速度超出这个范围,则超过限速的报文就会被丢掉或降低优先级转发
6.2流量整形
配置在设备的出口端。将流量转发速度限制在一个范围内,如果报文转发速度超出这个范围,则超过限速的报文就会被缓存,等待链路空闲时在被发送
流量整形TS(Traffic Shaping)的典型作用是限制流出某一网络的某一连接的正常流量与突发流量,使这类报文以比较均匀的速度向外发送,是一种主动调整流量输出速率的措施,故只能对输出的流量进行速率控制。常用GTS(Generic Traffic Shaping)技术来限制某类流量。
6.3流量监管与流量整形比较
| 限速类型 | 优点 | 缺点 |
|---|---|---|
| 流量监管 | 可实现不同报文的限速及重标记 | 造成较高的丢包率;链路空闲时带宽得不到充分利用 |
| 流量整形 | 较少丢弃报文,充分利用带宽 | 引入额外的时延和抖动,需要较多的设备缓冲资源 |
7.问题总结
1.问:为什么要对报文标记
答:端到端进行QoS部署(区分服务模型)时,就需要每台设备都对报文进行分类,这样就会导致耗费大量地设备处理资源,为此提出了对报文进行标记的方法,这样只需下游设备对标记进行识别即可提供差分服务
2.问:流量监管和流量整形的区别
答:1.在进行报文流量控制时,流量监管是对超过流量限制的报文进行丢弃;而流量整形则将超过流量限制的报文缓存在队列中,等待链路空闲的时候再发送
2.流量整形配置在设备入口端,流量整形配置在设备出口端