如何 Get 机器学习必备的数学技能?(文末赠书)
西瓜书(《机器学习》,清华大学出版社)和花书(《深度学习》,人民邮电出版社)分别是目前国内机器学习、深度学习领域销量最大的教材。它们的质量得到了大家的公认,可是数学知识不扎实的读者往往,在阅读理解中遇到一些困难。
1
数学对机器学习与深度学习的重要性
经典教材学起来难,问题到底出在哪里?抛开作者的内容设计、表述方式不谈。相比于普通的编程类书籍,机器学习和深度学习的难度本来就很大,出现这一结果也是在意料之中的。总结起来,困难主要是这几个方面:
数学。这两本书里密集的出现数学概念和公式,对大部分读者来说都是很困难的,尤其是不少数学知识超出了理工科本科“微积分”,“线性代数”,“概率论与数理统计”3门课的范围。陌生的数学符号和公式让大家茫然不知所措。
机器学习和深度学习中的一些思想不易理解。有些复杂的算法,比如支持向量机、反向传播算法、EM算法、概率图模型、变分推断,它们到底解决了什么问题,为什么要这样做,这些书里解释的不太清楚,这就造成了读者不知其所以然。
抽象。有些机器学习算法是很抽象的,比如流形学习、谱聚类算法等。如果不给出直观的解释,也是难以理解的。
不能和应用结合。很多教材普遍存在的一个问题是没有讲清楚这个方法到底有什么用,应该怎么用。
所有这些问题中,数学无疑是排在第一位的!因此,要学好机器学习、深度学习,以及强化学习,掌握必需的数学知识是先决条件。
2
西瓜书中的数学
先看看西瓜书的情况。西瓜书在附录里介绍了3部分数学知识:
A 矩阵
B 优化
C 概率分布
其中,A介绍了矩阵的基本演算,矩阵与向量求导,奇异值分解。B介绍了拉格朗日乘子法,KKT条件,拉格朗日对偶,二次规划,半正定规则,梯度下降法,坐标下降法。C介绍了常见概率分布(包括均匀分布,伯努利分布,二项分布,多项分布,贝塔分布,狄利克雷分布,高斯分布),共轭分布,KL散度。限于篇幅,对于这些内容只是粗略的进行了介绍。除非之前学过这些内容,否则只靠看西瓜书是很难理解它们的。
西瓜书涵盖了机器学习的主体知识,包括有监督学习,无监督学习,半监督学习,强化学习,以及机器学习理论。限于篇幅,作者不可能面面俱到的详细讲解这些算法的原理,尤其是数学推导与证明。
西瓜书中所用到的很多数学知识,相信绝大部分读者都未曾接触过,比如:
接下来看看西瓜书中一些典型的难以理解的地方:
logistic回归训练问题的求解,包括凸优化,牛顿法;
训练决策树时用到的熵,信息增益;
支持向量机推导中所用到的拉格朗日对偶,强对偶,KKT条件;
贝叶斯分类器这一章中所提到的Gibbs采样和EM算法之后;
高斯混合聚类中的EM算法;
基于图的半监督学习中的拉普拉斯矩阵以及其特征值与特征向量;
概率图模型这一章中的MCMC采样和变分推断;
其他的我们就不一一列举,仅仅这些内容,基本上都不在本科数学讲述的范围之内,这意味着读者要先补充至少以下课程的知识:
最优化方法
信息论
随机过程
图论
就拿MCMC采样来说,如果你不知道马尔可夫过程以及平稳分布,细致平衡条件,根本不可能理解这类算法的原理,包括为什么要这样做。而你如果不理解KL散度,就没法知道变分推断到底在干什么。
3
花书中的数学
与机器学习相比,深度学习的大部分内容对数学要求并没有那么高。如果是以工程应用和非理论的学术研究为目的,主要也就是线性代数的一些运算,各种损失函数,梯度下降法,反向传播算法。比起机器学习中的支持向量机,EM算法,概率图模型,概率推断,各种采样算法,要容易的多。花书要友好一些,在开头几章就用较大的篇幅介绍了数学知识,基本上覆盖了深度学习的主要数学知识点。包括:
线性代数
概率论与信息论
数值计算
大家应该能感觉到,花书的第1部分“应用数学与机器学习基础”和第2部分“深度网络:现代实践”相对容易理解,只要有一些数学基础,都能读懂。问题出在第3部分-深度学习研究:
线性因子模型
自编码器
表示学习
深度学习中的结构化概率模型
蒙特卡洛方法
直面配分函数
近似推断
深度生成模型
这几章的数学知识明显增多,而且有很多是大家不熟悉的。又出现了令大家普遍头疼的内容,比如:
MCMC采样算法;
EM算法;
近似推断和变分推断;
变分法;
RBM的训练算法
如果不清楚混合模型,比如高斯混合模型,以及最大似然估计,最大后验概率估计,就没法理解EM算法到底解决了什么问题,为什么要这样做,以及算法为什么能够收敛。
如果没有理解泛函的概概念,也没法理解变分法的思想,以及欧拉-拉格朗日方程的推导过程。花书中普遍用到的而大家又没有学过的数学知识,无外乎还是这几门课:
最优化方法
信息论
随机过程
图论
从上面总结的内容来看,如果不打好数学基础,想要学好花书和西瓜书是不现实的。

4
究竟需要哪些数学知识
我们先看典型的机器学习算法所用到的数学知识点,如下表所示。限于篇幅,这里没有列出强化学习、机器学习理论、自动化机器学习(AutoML)等内容所用的数学知识。
算法 |
所用的数学知识 |
|
分类与回归 |
贝叶斯分类器 |
随机变量,贝叶斯公式,正态分布,最大似然估计 |
决策树 |
熵,信息增益,Gini系数 |
|
KNN算法 |
距离函数 |
|
线性判别分析 |
散布矩阵,逆矩阵,广义瑞利商,拉格朗日乘数法,协方差矩阵,特征值与特征向量,标准正交基 |
|
人工神经网络 |
矩阵运算,链式法则,交叉熵,欧氏距离,梯度下降法 |
|
支持向量机 |
点到超平面的距离,拉格朗日对偶,强对偶,Slater条件,KKT条件,凸优化,核函数,Mercer条件,SMO算法 |
|
logistic回归与softmax回归 |
条件概率,伯努利分布,多项分布,最大似然估计,凸优化,梯度下降法,牛顿法 |
|
随机森林 |
随机抽样,方差 |
|
Boosting算法 |
牛顿法,泰勒公式 |
|
线性回归,岭回归,LASSO回归 |
均方误差,最小二乘法,向量范数,梯度下降法,凸优化 |
|
数据降维 |
主成分分析 |
均方误差,协方差矩阵,拉格朗日乘数法,协方差矩阵,特征值与特征向量,标准正交基 |
核主成分分析 |
核函数 |
|
流形学习 |
线性组合,均方误差,相似度图,拉普拉斯矩阵,特征值与特征向量,拉格朗日乘数法,KL散度,t分布,测地线与测地距离 |
|
距离度量学习 |
NCA |
概率,梯度下降法 |
ITML |
KL散度,带约束的优化 |
|
LMNN |
线性变换,梯度下降法 |
|
高斯混合模型与EM算法 |
正态分布,多项分布,边缘分布,条件分布,数学期望,Jensen不等式,最大似然估计,最大后验概率估计,拉格朗日乘数法 |
|
高斯过程回归 |
正态分布,条件分布,高斯过程 |
|
概率图模型 |
HMM |
马尔可夫过程,条件分布,边缘分布,最大似然估计,EM算法,拉格朗日乘数法 |
CRF |
图,条件概率,最大似然估计,拟牛顿法 |
|
贝叶斯网络 |
图,条件概率,贝叶斯公式,最大似然估计 |
|
聚类 |
K均值算法 |
EM算法 |
谱聚类 |
图,拉普拉斯矩阵,特征值与特征向量 |
|
Mean Shift算法 |
核密度估计,梯度下降法 |
|
深度生成模型 |
GAN |
概率分布变换,KL散度,JS散度,互信息,梯度下降法 |
VAE |
概率分布变换,KL散度,变分推断,梯度下降法 |
|
变分推断 |
KL散度,变分法,贝叶斯公式 |
|
MCMC采样 |
马尔可夫链,平稳分布,细致平衡条件,条件概率 |
从这张表可以看出来,频繁用到的知识点就是向量和矩阵的运算,梯度下降法等优化算法,概率,信息论中的模型概念。整体来说,是下面这几门课的内容:
微积分
线性代数
概率论
最优化方法
信息论
随机过程
图论
下面这张图列出了这些知识的整体结构。其中线性代数与微积分是基础,其他的课程都是建立在它们之上的。最优化方法严重依赖于微积分(尤其是多元函数微积分)的知识,信息论与随机过程是概率论的延伸。

下面我们分别来介绍这几门课在机器学习中到底用到了哪些内容。
微积分
微积分由一元函数微积分、多元函数微积分两部分构成,它是整个高等数学的基石。通常情况下,机器学习需要得到一个函数(模型,或者说假设),既然是函数,那自然就离不开微积分了。微积分为我们研究函数的性质,包括单调性、凹凸性、以及极值提供了理论依据。同时它也是学习概率论、信息论、最优化方法等后续课程的基础。
在机器学习中,最应该被记住的微积分知识点是下面的两张图。第一张图是微分学:
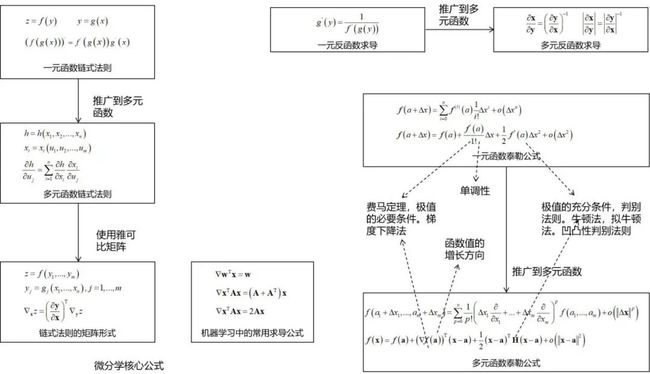
微分学中最应该被记住的是链式法则和泰勒公式。后者是理解在机器学习中使用最多的梯度下降法、牛顿法、拟牛顿法等数值优化算法推导的基础,前者为计算各种目标函数的导数提供了依据。借助于雅克比矩阵,多元函数的链式法则有简介而优雅的表达,多元函数反函数求导公式可以与一元函数反函数求导公式达成形式上的统一。借助于梯度、Hessian矩阵以及向量内积、二次型,多元函数的泰勒公式与一元函数的泰勒公式可以达成形式上的统一。
第二张图是积分学:

积分学中最关键的是积分换元公式,借助于雅克比行列式,可以与一元函数定积分的换元公式达成形式上的统一。积分换元公式在后面的概率论(如概率分布变换,逆变换采样算法),信息论(如多维正态分布的联合熵)等课程中有广泛的应用,务必要掌握。
线性代数
接下来看线性代数。线性代数对于机器学习是至关重要的。机器学习算法的输入、输出、中间结果通常为向量、矩阵。使用线性代数可以简化问题的表达,用一个矩阵乘法,比写成多重求和要简洁明了得多。线性代数是学习后续数学课程的基础。它可以与微积分结合,研究多元函数的性质。线性代数在概率论中也被使用,比如随机向量,协方差矩阵。线性代数在图论中亦有应用-如图的邻接矩阵,拉普拉斯矩阵。在随机过程中同样有应用-如状态转移矩阵。下面的图列出了线性代数的核心知识结构:

向量与矩阵是线性代数中的基本计算对象,这门课基本上围绕着它们而展开。特征值与特征向量是机器学习中使用频率仅次于向量和矩阵的知识点,它连接其了众多的知识点,决定了矩阵的若干重要性质。
概率论
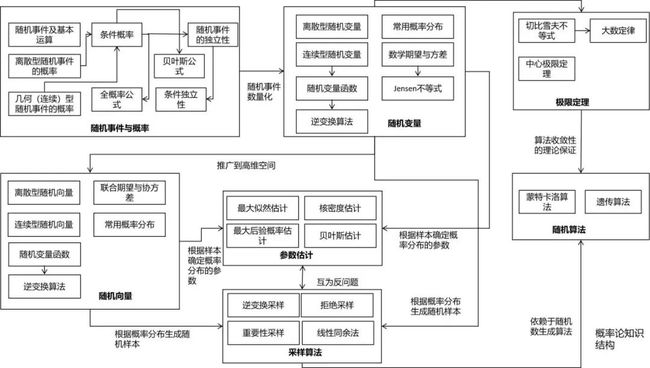
概率论对于机器学习来说也是至关重要的,它是一种重要的工具。如果将机器学习算法的输入、输出看作随机变量/向量,则可以用概率论的观点对问题进行建模。使用概率论的一个好处是可以对不确定性进行建模,这对于某些问题是非常有必要的。另外,它还可以挖掘变量之间的概率依赖关系,实现因果推理。概率论为某些随机算法-如蒙特卡洛算法、遗传算法,以及随机数生成算法-包括基本随机数生成、以及采样算法提供了理论依据和指导。最后,概率论也是信息论,随机过程的先导课程。下面这张图清晰地列出了概率论的核心知识:
下面这张图是对机器学习中概率模型的总结:
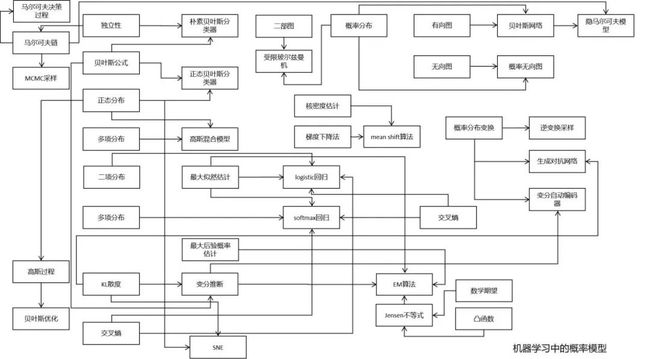
从这张图可以清晰的看出频繁使用的概率论知识点,最重要的莫过于条件概率,贝叶斯公式,正态分布,最大似然估计。
最优化方法
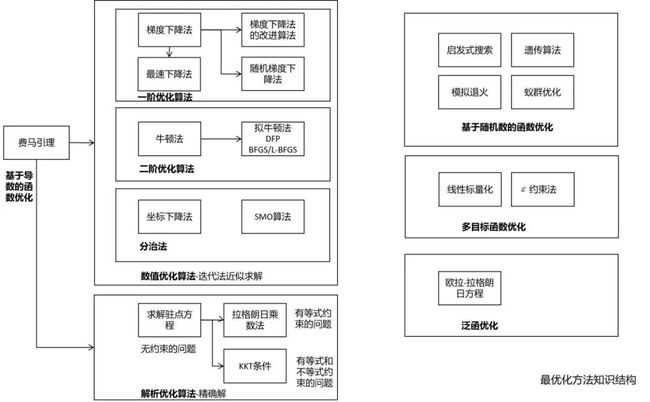
最优化方法在机器学习中处于中心地位。几乎所有机器学习算法最后都归结于求解最优化问题,从而确定模型参数,或直接获得预测结果。前者的典型代表是有监督学习,通过最小化损失函数或优化其他类型的目标函数确定模型的参数;后者的典型代表是数据降维算法,通过优化某种目标函数确定降维后的结果,如主成分分析。下面这张图列出了最优化方法的核心知识:
信息论
信息论是概率论的延伸,在机器学习与深度学习中通常用于构造目标函数,以及对算法进行理论分析与证明。在机器学习尤其是深度学习中,信息论的知识随处可见,比如:
决策树的训练过程中需要使用熵作为指标
在深度学习中经常会使用交叉熵、KL散度、JS散度、互信息等概念
变分推断的推导需要以KL散度为基础
距离度量学习、流形降维等算法也需要信息论的知识
总体来说,在机器学习中用得最多的是熵,交叉熵,KL散度,JS散度,互信息,条件熵等。下面这张图列出了信息论的核心知识:

熵是最基本的概念,推广到多个概率分布,可以得到交叉熵,KL散度,以及JS散度。推广到多个随机变量,可以得到互信息,条件熵。
随机过程
随机过程同样是概率论的延伸。在机器学习中,随机过程被用于概率图模型、强化学习、以及贝叶斯优化等方法。不理解马尔可夫过程,你将对MCMC采样算法一筹莫展。下面这张图列出了机器学习中随机过程的核心知识:
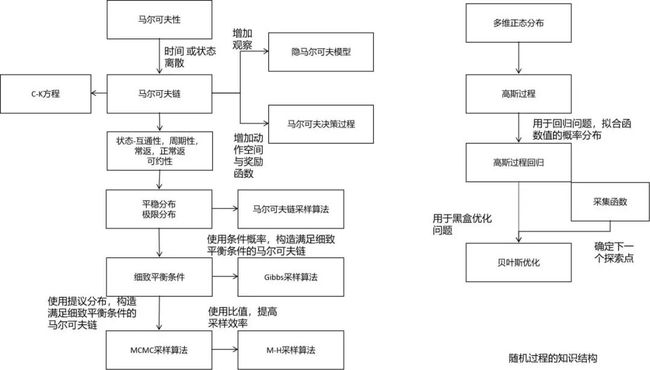
在机器学习中所用的主要是马尔可夫过程和高斯过程。隐马尔可夫过程,马尔可夫决策过程都是它的延伸。平稳分布、细致平衡条件也是理解MCMC采样的核心基础。
图论
在机器学习中,概率图模型是典型的图结构。流形降维算法与谱聚类算法均使用了谱图理论。计算图是图的典型代表,图神经网络作为一种新的深度学习模型,与图论也有密切的关系。下面这张图列出了图论的整体知识结构:

这里相等难以理解的是谱图理论。谱图理论的核心是拉普拉斯矩阵,归一化拉普拉斯矩阵,理解它们需要扎实的线性代数基础。
4
《机器学习的数学》是你的一个好选择
如何解决数学问题?这里我们给出了一个精确而实用的答案,先学下面这本书:
这本书用最小的篇幅精准的覆盖了机器学习、深度学习、强化学习所需的核心数学知识。章节结构设计科学合理,不需要的东西,统统不讲,这样可以有效的减小读者的学习成本。
数学抽象难懂,是几乎所有读者都会面临的一个问题。如何把一些概念、理论清晰地讲述出来,是一个非常有挑战性的话题。在这一方面,作者进行了大量的思考与设计,力求用浅显易懂的语言把晦涩的知识讲述清楚,并用实例、图/表、程序代码等形式把抽象的知识具象化,确保读者理解起来无困难。下面来看几个例子。
使用图/表等方式降低理解难度。
很多读者觉得反向传播算法不易理解,不清楚为什么要这样做,到底解决了什么问题。书中条理清晰地阐述了反向传播算法的原理,推导简洁而易懂,同时附以下面的图让读者理解算法的核心步骤与本质。

2. 使用实例降低理解难度
书中大量使用了在机器学习中、实际生活中的例子进行讲解,化抽象为具体。以马尔可夫决策过程为例,强化学习中的马尔可夫决策过程一直让很多读者觉得难解。相信很多读者会有下面的疑问:
强化学习中为什么需要用马尔可夫决策过程进行建模?
为什么需要用状态转移概率?
为什么奖励函数与状态转移有关?
确定性策略,非确定性策略到底是怎么回事?
书中对马尔可夫决策过程进行了清晰的阐述,并以人工降雨这种大家都能理解的生活例子进行说明。


3.对难以理解的知识点有清晰、透彻的解释
机器学习中所用的数学知识,有不少是公认的难以理解的。比如正交变换,QR算法,奇异值分解,拟牛顿法,拉格朗日对偶,概率分布变换等。这些数学概念的定义,推导中的关键步骤,以及为何要这样做,在很多教材中并没有交代。本书对这些难点的讲解进行了精心的设计。
以Householder变换为例,它在矩阵分解、特征值计算等任务中具有重要的作用。不少读者在学习矩阵分析、数值分析等课程的时候可能会有这样的疑问:
为什么用Householder变换可以将矩阵变换为近似对角的矩阵?
Householder变换的变换矩阵是怎样构造的,为什么要这么构造?
为何不直接将对称矩阵变换为对角矩阵?
对于这些问题,本书都有清晰的交代。

4. 令很多人头疼的变分推断:

5. 其他的我们就不再一一列举。
一般的数学教材通常不会讲授机器学习的相关内容,而专门的机器学习教材又不会详细讲解数学知识,二者之间存在一个鸿沟。从更大的层面看,不知数学有何用,不知学了怎么用,是很多读者面临的一个问题。针对这一问题本书也给出了很好的答案:从机器学习的角度讲述数学,从数学的角度看待机器学习。这是本书的一大特色,全书实现了机器学习与数学的无缝衔接。对于很多数学知识,我们会讲到它在机器学习中的应用;而对于大多数机器学习算法,我们也会讲清它的数学原理。这些内容已经涵盖了机器学习、深度学习、强化学习的核心范围。读完本书,读者对机器学习算法也基本上也有了一个整体的理解。
4
配套的高质量课程
在出版这本书的同时,我们还推出了高质量的配套课程,由《机器学习的数学》的作者亲自讲解,帮你打下坚实的数学基础。课程的内容与书的内容高度贴合,结构设计科学、合理,我们将为你清晰的讲述:
一元函数微积分
线性代数与矩阵分析
多元函数微积分
最优化方法
概率论
信息论
随机过程
图论
的主体知识。在讲授的时候,我们同样会与它们在机器学习中的应用相结合,实现数学与机器学习的无缝衔接。为了便于理解,增加动手能力,课程中会有一些Python代码的讲解与实现。结合课程与这本书,将彻底让你解决数学这一难题,为以后的学习、学术研究,职业生涯打下坚实的基础。
今天我们为大家提供4个名额,赠送这本书给大家!中奖的朋友请记得留下联系方式和地址!欢迎大家扫码参与!
分享
收藏
点赞
在看
