【Spark MLlib】(二)Spark MLlib 特征工程 - 提取、转换和选择
Spark MLlib 中关于特征处理的相关算法,大致分为以下几组:
- 提取(Extraction):从“原始”数据中提取特征
- 转换(Transformation):缩放,转换或修改特征
- 选择(Selection):从较大的一组特征中选择一个子集
- 局部敏感哈希(Locality Sensitive Hashing,LSH):这类算法将特征变换的各个方面与其他算法相结合。
文章目录
-
- 一、特征的提取
-
- 1.1 TF-IDF
- 1.2 Word2Vec
- 1.3 CountVectorizer
- 1.4 FeatureHasher
- 二、特征的变换
-
- 2.1 Tokenizer(分词器)
- 2.2 StopWordsRemover(去停用词)
- 2.3 N-gram(N元模型)
- 2.4 Binarizer(二值化)
- 2.5 PCA(主元分析)
- 2.6 PolynomialExpansion(多项式扩展)
- 2.7 Discrete Cosine Transform(DCT离散余弦变换)
- 2.8 StringIndexer(字符串-索引变换)
- 2.9 IndexToString(索引-字符串变换)
- 2.10 OneHotEncoder(独热编码)
- 2.11 VectorIndexer(向量类型索引化)
- 2.12 Interaction(相互作用)
- 2.13 Normalizer(范数p-norm规范化)
- 2.14 StandardScaler(标准化)
- 2.15 MinMaxScaler(最大-最小规范化)
- 2.16 MaxAbsScaler(绝对值规范化)
- 2.17 VectorAssembler(特征向量合并)
- 2.18 QuantileDiscretizer(分位数离散化)
- 2.19 其他的几种变换
- 三、特征的选择
-
- 3.1 VectorSlicer(向量切片机)
- 3.2 RFormula(R模型公式)
- 3.3 ChiSqSelector(卡方特征选择器)
一、特征的提取
1.1 TF-IDF
词频-逆文本频率(Term frequency-inverse document frequency, (TF-IDF)是在文本挖掘中广泛使用的特征向量化方法,以反映术语对语料库中的文档的重要性。 用t表示一个术语,用d表示一个文件,用D表示语料库。词频TF(t,d)是术语t出现在文件d中的次数,而文档频率DF(t,D)是包含术语t的文件数量。 如果我们仅使用词频来衡量重要性,那么过分强调经常出现但很少提供有关文档的信息的术语非常容易,例如: “a”,“the”和“of”。 如果词语在语料库中经常出现,则表示它不包含有关特定文档的特殊信息。 逆向文档频率是词语提供的信息量的数字度量:
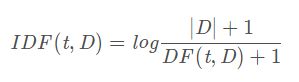
其中|D|是语料库中的文档总数。 由于使用了对数log,如果一个术语出现在所有文档中,其IDF值将变为0。请注意,应用平滑词语以避免语料库外的术语除以零。 TF-IDF指标只是TF和IDF的产物:
![]()
词频和文档频率的定义有几种变体。 在MLlib中,我们将TF和IDF分开以使其灵活。
-
TF(词频):HashingTF与CountVectorizer用于生成词频TF向量。HashingTF是一个特征词集的转换器(Transformer),它可以将这些集合转换成固定长度的特征向量。HashingTF利用hashingtrick,原始特征通过应用哈希函数映射到索引中。然后根据映射的索引计算词频。这种方法避免了计算全局特征词对索引映射的需要,这对于大型语料库来说可能是昂贵的,但是它具有潜在的哈希冲突,其中不同的原始特征可以在散列之后变成相同的特征词。为了减少碰撞的机会,我们可以增加目标特征维度,即哈希表的桶数。由于使用简单的模数将散列函数转换为列索引,建议使用两个幂作为特征维,否则不会将特征均匀地映射到列。默认功能维度为2^18=262144。可选的二进制切换参数控制词频计数。当设置为true时,所有非零频率计数设置为1。这对于模拟二进制而不是整数的离散概率模型尤其有用。
-
IDF(逆向文档频率):IDF是一个适合数据集并生成IDFModel的评估器,IDFModel获取特征向量并缩放每列。直观地说,它下调了再语料库中频繁出现的列。
package sparkml
import org.apache.spark.ml.feature.{HashingTF, IDF, Tokenizer}
import org.apache.spark.sql.SparkSession
object TFIDF {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName("TFIDF")
.master("local[*]")
.getOrCreate()
//通过代码的方式,设置Spark log4j的级别
spark.sparkContext.setLogLevel("WARN")
val sentenceData = spark.createDataFrame(Seq(
(0.0, "Hi I heard about Spark"),
(0.0, "I wish Java could use case classes"),
(1.0, "Logistic regression models are neat")
)).toDF("label", "sentence")
val tokenizer = new Tokenizer()
.setInputCol("sentence")
.setOutputCol("words")
val wordData = tokenizer.transform(sentenceData)
wordData.show()
val hashingTF = new HashingTF()
.setInputCol("words")
.setOutputCol("rawFeatures")
.setNumFeatures(20)
val featurizedData = hashingTF.transform(wordData)
featurizedData.show()
val idf = new IDF()
.setInputCol("rawFeatures")
.setOutputCol("features")
val idfModel = idf.fit(featurizedData)
val rescaledData = idfModel.transform(featurizedData)
rescaledData.show()
}
}
运行结果如下:
+-----+--------------------+--------------------+
|label| sentence| words|
+-----+--------------------+--------------------+
| 0.0|Hi I heard about ...|[hi, i, heard, ab...|
| 0.0|I wish Java could...|[i, wish, java, c...|
| 1.0|Logistic regressi...|[logistic, regres...|
+-----+--------------------+--------------------+
+-----+--------------------+--------------------+--------------------+
|label| sentence| words| rawFeatures|
+-----+--------------------+--------------------+--------------------+
| 0.0|Hi I heard about ...|[hi, i, heard, ab...|(20,[0,5,9,17],[1...|
| 0.0|I wish Java could...|[i, wish, java, c...|(20,[2,7,9,13,15]...|
| 1.0|Logistic regressi...|[logistic, regres...|(20,[4,6,13,15,18...|
+-----+--------------------+--------------------+--------------------+
+-----+--------------------+--------------------+--------------------+--------------------+
|label| sentence| words| rawFeatures| features|
+-----+--------------------+--------------------+--------------------+--------------------+
| 0.0|Hi I heard about ...|[hi, i, heard, ab...|(20,[0,5,9,17],[1...|(20,[0,5,9,17],[0...|
| 0.0|I wish Java could...|[i, wish, java, c...|(20,[2,7,9,13,15]...|(20,[2,7,9,13,15]...|
| 1.0|Logistic regressi...|[logistic, regres...|(20,[4,6,13,15,18...|(20,[4,6,13,15,18...|
+-----+--------------------+--------------------+--------------------+--------------------+
1.2 Word2Vec
Word2Vec是一个Estimator,它采用代表文档的单词序列并训练Word2VecModel。 该模型将每个单词映射到一个唯一的固定大小的向量。 Word2VecModel使用文档中所有单词的平均值将每个文档转换为向量; 然后,此向量可用作预测,文档相似度计算等功能。
举例
我们从一组文档开始,每个文档都表示为一系列单词。 对于每个文档,我们将其转换为特征向量。 然后可以将该特征向量传递给学习算法:
package sparkml
import org.apache.spark.ml.feature.Word2Vec
import org.apache.spark.sql.{Row, SparkSession}
import org.apache.spark.ml.linalg.Vector
object Word2vec {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName("Word2vec")
.master("local[*]")
.getOrCreate()
spark.sparkContext.setLogLevel("WARN")
val documentDF = spark.createDataFrame(Seq(
"Hi I heard about Spark".split(" "),
"I wish Java could use case classes".split(" "),
"Logistic regression models are neat".split(" ")
).map(Tuple1.apply)).toDF("text")
val word2vec = new Word2Vec()
.setInputCol("text")
.setOutputCol("result")
.setVectorSize(3)
.setMinCount(0)
val model = word2vec.fit(documentDF)
val result = model.transform(documentDF)
result.show(false)
result.collect().foreach{
case Row(text:Seq[_], features:Vector) =>
println(s"Text: [${text.mkString(",")}] => \nVector: $features\n")
}
}
}
运行结果如下:
+------------------------------------------+----------------------------------------------------------------+
|text |result |
+------------------------------------------+----------------------------------------------------------------+
|[Hi, I, heard, about, Spark] |[-0.008142343163490296,0.02051363289356232,0.03255096450448036] |
|[I, wish, Java, could, use, case, classes]|[0.043090314205203734,0.035048123182994974,0.023512658663094044]|
|[Logistic, regression, models, are, neat] |[0.038572299480438235,-0.03250147425569594,-0.01552378609776497]|
+------------------------------------------+----------------------------------------------------------------+
Text: [Hi,I,heard,about,Spark] =>
Vector: [-0.008142343163490296,0.02051363289356232,0.03255096450448036]
Text: [I,wish,Java,could,use,case,classes] =>
Vector: [0.043090314205203734,0.035048123182994974,0.023512658663094044]
Text: [Logistic,regression,models,are,neat] =>
Vector: [0.038572299480438235,-0.03250147425569594,-0.01552378609776497]
1.3 CountVectorizer
CountVectorizer和CountVectorizerModel旨在帮助将文本文档集合转换为计数向量(vectors of token counts)。当a-priori字典不可用时,CountVectorizer可用作Estimator来提取词汇表,并生成CountVectorizerModel。该模型为词汇表上的文档生成稀疏表示,然后可以将其传递给其他算法,如LDA。
在拟合过程中,CountVectorizer将选择按语料库中的术语频率排序的顶级词汇量词。可选参数minDF还通过指定词语必须出现在文档中的最小数量(或<1.0)来影响拟合过程。另一个可选的二进制切换参数控制输出向量。如果设置为true,则所有非零计数都设置为1.这对于模拟二进制而非整数计数的离散概率模型尤其有用。
package sparkml
import org.apache.spark.ml.feature.{CountVectorizerModel, CountVectorizer}
import org.apache.spark.sql.SparkSession
object CountVectorizer {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName("CountVectorizer")
.master("local[*]")
.getOrCreate()
spark.sparkContext.setLogLevel("WARN")
val df = spark.createDataFrame(Seq(
(0, Array("a", "b", "c")),
(1, Array("a", "b", "b", "c", "a"))
)).toDF("id", "words")
val cvModel: CountVectorizerModel = new CountVectorizer()
.setInputCol("words")
.setOutputCol("features")
.setVocabSize(3)
.setMinDF(2)
.fit(df)
val cvm = new CountVectorizerModel(Array("a", "b", "c"))
.setInputCol("words")
.setOutputCol("features")
cvModel.transform(df).show(false)
cvm.transform(df).show(false)
}
}
运行结果如下:
+---+---------------+-------------------------+
|id |words |features |
+---+---------------+-------------------------+
|0 |[a, b, c] |(3,[0,1,2],[1.0,1.0,1.0])|
|1 |[a, b, b, c, a]|(3,[0,1,2],[2.0,2.0,1.0])|
+---+---------------+-------------------------+
+---+---------------+-------------------------+
|id |words |features |
+---+---------------+-------------------------+
|0 |[a, b, c] |(3,[0,1,2],[1.0,1.0,1.0])|
|1 |[a, b, b, c, a]|(3,[0,1,2],[2.0,2.0,1.0])|
+---+---------------+-------------------------+
1.4 FeatureHasher
特征散列(Feature Hashing)将一组分类或数字特征映射到指定尺寸的特征向量中(通常远小于原始特征空间的特征向量)。这是使用散列技巧将要素映射到特征向量中的索引来完成的。
FeatureHasher转换器在多个特征上运行。每个特征可能是数值特征或分类特征。不同数据类型的处理方法如下:
- 数值特征:对于数值特征,特征名称的哈希值用于将值映射到向量中的索引。默认情况下,数值元素不被视为分类属性(即使它们是整数)。要将它们视为分类属性,请使用categoricalCols参数指定相关列。
- 字符串(属性)特征:对于属性特征,字符串“column_name = value”的哈希值用于映射到矢量索引,指示符值为1.0。因此,属性特征是“one-hot”编码的(类似于使用具有dropLast = false的OneHotEncoder)。
- 布尔特征:布尔值的处理方式与字符串特征相同。也就是说,布尔特征表示为“column_name = true”或“column_name = false”,指标值为1.0。
忽略空(缺失)值(在结果特征向量中隐式为零)。
这里使用的哈希函数也是HashingTF中使用的MurmurHash 3。由于散列值的简单模数用于确定向量索引,因此建议使用2的幂作为numFeatures参数;否则,特征将不会均匀地映射到矢量索引。
举例
假设我们有一个DataFrame,其中包含4个输入列real,bool,stringNum和string。这些不同的数据类型作为输入将说明变换的行为以产生一列特征向量。
real| bool|stringNum|string
----|-----|---------|------
2.2| true| 1| foo
3.3|false| 2| bar
4.4|false| 3| baz
5.5|false| 4| foo
训练过程示例:
# -*- coding: utf-8 -*-
"""
Describe:
"""
from __future__ import print_function
from pyspark.sql import SparkSession
from pyspark.ml.feature import FeatureHasher
if __name__ == "__main__":
spark = SparkSession\
.builder\
.appName("FeatureHasherExample")\
.getOrCreate()
dataset = spark.createDataFrame([
(2.2, True, "1", "foo"),
(3.3, False, "2", "bar"),
(4.4, False, "3", "baz"),
(5.5, False, "4", "foo")
], ["real", "bool", "stringNum", "string"])
hasher = FeatureHasher(inputCols=["real", "bool", "stringNum", "string"],
outputCol="features")
featurized = hasher.transform(dataset)
featurized.show(truncate=False)
spark.stop()
结果如下:
+----+-----+---------+------+--------------------------------------------------------+
|real|bool |stringNum|string|features |
+----+-----+---------+------+--------------------------------------------------------+
|2.2 |true |1 |foo |(262144,[174475,247670,257907,262126],[2.2,1.0,1.0,1.0])|
|3.3 |false|2 |bar |(262144,[70644,89673,173866,174475],[1.0,1.0,1.0,3.3]) |
|4.4 |false|3 |baz |(262144,[22406,70644,174475,187923],[1.0,1.0,4.4,1.0]) |
|5.5 |false|4 |foo |(262144,[70644,101499,174475,257907],[1.0,1.0,5.5,1.0]) |
+----+-----+---------+------+--------------------------------------------------------+
二、特征的变换
2.1 Tokenizer(分词器)
Tokenization是将文本(如一个句子)拆分成单词的过程。(在Spark ML中)Tokenizer(分词器)提供此功能。RegexTokenizer 提供了(更高级的)基于正则表达式 (regex) 匹配的(对句子或文本的)单词拆分。默认情况下,参数"pattern"(默认的正则表达式: “\s+”) 作为分隔符用于拆分输入的文本。或者,用户可以将参数“gaps”设置为 false ,指定正则表达式"pattern"表示"tokens",而不是分隔符,这样作为划分结果找到所有匹配项。
示例:
package sparkml
import org.apache.spark.ml.feature.{RegexTokenizer, Tokenizer}
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions._
object Tokenizer {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName("Tokenizer")
.master("local[*]")
.getOrCreate()
spark.sparkContext.setLogLevel("WARN")
val sentenceDataFrame = spark.createDataFrame(Seq(
(0, "Hi I heard about Spark"),
(1, "I wish Java could use case classes"),
(2, "Logistic,regression,models,are,neat")
)).toDF("id", "sentence")
val tokenizer = new Tokenizer()
.setInputCol("sentence")
.setOutputCol("words")
val regexTokenizer = new RegexTokenizer()
.setInputCol("sentence")
.setOutputCol("words")
//.setPattern("\\w")//alternatively .setPattern("\\w+").setGaps(falsa)
val countTokens = udf{(words: Seq[String]) => words.length}
val tokenized = tokenizer.transform(sentenceDataFrame)
tokenized.show(false)
tokenized.select("sentence", "words")
.withColumn("tokens", countTokens(col("words"))).show(false)
val regexTokenized = regexTokenizer.transform(sentenceDataFrame)
regexTokenized.select("sentence", "words")
.withColumn("tokens", countTokens(col("words"))).show(false)
}
}
运行结果如下:
+---+-----------------------------------+------------------------------------------+
|id |sentence |words |
+---+-----------------------------------+------------------------------------------+
|0 |Hi I heard about Spark |[hi, i, heard, about, spark] |
|1 |I wish Java could use case classes |[i, wish, java, could, use, case, classes]|
|2 |Logistic,regression,models,are,neat|[logistic,regression,models,are,neat] |
+---+-----------------------------------+------------------------------------------+
+-----------------------------------+------------------------------------------+------+
|sentence |words |tokens|
+-----------------------------------+------------------------------------------+------+
|Hi I heard about Spark |[hi, i, heard, about, spark] |5 |
|I wish Java could use case classes |[i, wish, java, could, use, case, classes]|7 |
|Logistic,regression,models,are,neat|[logistic,regression,models,are,neat] |1 |
+-----------------------------------+------------------------------------------+------+
+-----------------------------------+------------------------------------------+------+
|sentence |words |tokens|
+-----------------------------------+------------------------------------------+------+
|Hi I heard about Spark |[hi, i, heard, about, spark] |5 |
|I wish Java could use case classes |[i, wish, java, could, use, case, classes]|7 |
|Logistic,regression,models,are,neat|[logistic,regression,models,are,neat] |1 |
+-----------------------------------+------------------------------------------+------+
2.2 StopWordsRemover(去停用词)
Stop words(停用字)是在文档中频繁出现,但未携带太多意义的词语,它们不应该参与算法运算。
示例:
package sparkml
import org.apache.spark.ml.feature.StopWordsRemover
import org.apache.spark.sql.SparkSession
object StopWordsRemover {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName("StopWordsRemover")
.master("local[*]")
.getOrCreate()
spark.sparkContext.setLogLevel("WARN")
val dataset = spark.createDataFrame(Seq(
(0, Seq("I", "saw", "the", "red", "baloon")),
(1, Seq("Mary", "had", "a", "little", "lamb"))
)).toDF("id", "raw")
val remover = new StopWordsRemover()
.setInputCol("raw")
.setOutputCol("filtered")
remover.transform(dataset).show()
}
}
运行结果如下:
+---+--------------------+--------------------+
| id| raw| filtered|
+---+--------------------+--------------------+
| 0|[I, saw, the, red...| [saw, red, baloon]|
| 1|[Mary, had, a, li...|[Mary, little, lamb]|
+---+--------------------+--------------------+
2.3 N-gram(N元模型)
一个N-gram是一个长度为N(整数)的字的序列。NGram可用于将输入特征转换成N-grams。N-gram的输入为一系列的字符串,参数n表示每个N-gram中单词的数量。输出将由N-gram序列组成,其中每个N-gram由空格分割的n个连续词的字符串表示。如果输入的字符串序列少于n个单词,NGram输出为空。
package sparkml
import org.apache.spark.ml.feature.NGram
import org.apache.spark.sql.SparkSession
object Ngram {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName("Ngram")
.master("local[*]")
.getOrCreate()
spark.sparkContext.setLogLevel("WARN")
val dataset = spark.createDataFrame(Seq(
(0, Array("I", "saw", "the", "red", "baloon")),
(1, Array("Mary", "had", "a", "little", "lamb")),
(2, Array("xzw", "had", "as", "age", "qwe"))
)).toDF("id", "words")
val ngram = new NGram()
.setN(2)
.setInputCol("words")
.setOutputCol("ngrams")
val ngramDF = ngram.transform(dataset)
ngramDF.select("ngrams").show(false)
}
}
运行结果如下所示:
+----------------------------------------+
|ngrams |
+----------------------------------------+
|[I saw, saw the, the red, red baloon] |
|[Mary had, had a, a little, little lamb]|
|[xzw had, had as, as age, age qwe] |
+----------------------------------------+
2.4 Binarizer(二值化)
Binarization是将数值特征阈值化为二进制特征的过程。
示例:
package sparkml
import org.apache.spark.ml.feature.Binarizer
import org.apache.spark.sql.SparkSession
object Binarizer {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName("Binarizer")
.master("local[*]")
.getOrCreate()
spark.sparkContext.setLogLevel("WARN")
val data = Array((0, 0.1), (1, 0.8), (2, 0.2))
val dataFrame = spark.createDataFrame(data).toDF("id", "feature")
val binarizer: Binarizer = new Binarizer()
.setInputCol("feature")
.setOutputCol("binarized_feature")
.setThreshold(0.5)
val binarizerDataFrame = binarizer.transform(dataFrame)
println(s"Binarizer output with Threshold = ${binarizer.getThreshold}")
binarizerDataFrame.show(false)
}
}
运行结果如下:
Binarizer output with Threshold = 0.5
+---+-------+-----------------+
|id |feature|binarized_feature|
+---+-------+-----------------+
|0 |0.1 |0.0 |
|1 |0.8 |1.0 |
|2 |0.2 |0.0 |
+---+-------+-----------------+
2.5 PCA(主元分析)
PCA是使用正交变换将可能相关变量的一组观察值转换为主成分的线性不相关变量的值的一组统计过程。PCA类训练使用PCA将向量投影到低维空间的模型。
package sparkml
import org.apache.spark.ml.feature.PCA
import org.apache.spark.ml.linalg.Vectors
import org.apache.spark.sql.SparkSession
object PCA {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName("PCA")
.master("local[*]")
.getOrCreate()
spark.sparkContext.setLogLevel("WARN")
val data = Array(
Vectors.sparse(5, Seq((1, 1.0), (3, 7.0))),
Vectors.dense(2.0, 0.0, 3.0, 4.0, 5.0),
Vectors.dense(4.0, 0.0, 0.0, 6.0, 7.0)
)
val df = spark.createDataFrame(data.map(Tuple1.apply)).toDF("features")
val pca = new PCA()
.setInputCol("features")
.setOutputCol("pcafeatures")
.setK(3)
.fit(df)
val result = pca.transform(df)
.select("pcafeatures")
result.show(false)
}
}
运行结果如下:
+-----------------------------------------------------------+
|pcafeatures |
+-----------------------------------------------------------+
|[1.6485728230883807,-4.013282700516296,-5.524543751369388] |
|[-4.645104331781534,-1.1167972663619026,-5.524543751369387]|
|[-6.428880535676489,-5.337951427775355,-5.524543751369389] |
+-----------------------------------------------------------+
2.6 PolynomialExpansion(多项式扩展)
多项式扩展是将特征扩展为多项式空间的过程,多项式空间由原始维度的n度组合而成。
package sparkml
import org.apache.spark.ml.feature.PolynomialExpansion
import org.apache.spark.ml.linalg.Vectors
import org.apache.spark.sql.SparkSession
object PolynomialExpansion {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName("PolynomialExpansion")
.master("local[*]")
.getOrCreate()
spark.sparkContext.setLogLevel("WARN")
val data = Array(
Vectors.dense(2.0, 1.0),
Vectors.dense(0.0, 0.0),
Vectors.dense(3.0, -1.0)
)
val df = spark.createDataFrame(data.map(Tuple1.apply)).toDF("features")
val polyExpansion = new PolynomialExpansion()
.setInputCol("features")
.setOutputCol("polyFeatures")
.setDegree(3)
val polyDF = polyExpansion.transform(df)
polyDF.show(false)
}
}
2.7 Discrete Cosine Transform(DCT离散余弦变换)
离散余弦变换是将时域的N维实数序列转换成频域的N维实数序列的过程,类似于离散的傅里叶变换。DCT类提供了离散余弦变换的功能,将离散余弦变换后结果乘以得到一个与时域矩阵长度一致的矩阵。没有偏移被应用于变换的序列,即输入序列与输出之间是一一对应的。
package sparkml
import org.apache.spark.ml.feature.DCT
import org.apache.spark.ml.linalg.Vectors
import org.apache.spark.sql.SparkSession
object DCT {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName("DCT")
.master("local[*]")
.getOrCreate()
spark.sparkContext.setLogLevel("WARN")
val data = Array(
Vectors.dense(0.0, 1.0, -2.0, 3.0),
Vectors.dense(2.0, 0.0, 3.0, 4.0),
Vectors.dense(4.0, 0.0, 0.0, 6.0)
)
val df = spark.createDataFrame(data.map(Tuple1.apply)).toDF("features")
val dct = new DCT()
.setInputCol("features")
.setOutputCol("featuresdct")
.setInverse(false)
val dctDF = dct.transform(df)
dctDF.select("featuresdct").show(false)
}
}
运行结果如下所示:
+----------------------------------------------------------------+
|featuresdct |
+----------------------------------------------------------------+
|[1.0,-1.1480502970952693,2.0000000000000004,-2.7716385975338604]|
|[4.5,-2.118357115095672,1.5000000000000002,1.418648347168368] |
|[5.0,-1.3065629648763766,5.000000000000001,-0.5411961001461971] |
+----------------------------------------------------------------+
2.8 StringIndexer(字符串-索引变换)
StringIndexer(字符串-索引变换)将标签的字符串列编号改成标签索引列。标签索引序列的取值范围是[0,numLabels(字符串中所有出现的单词去掉重复的词后的总和)],按照标签出现频率排序,出现最多的标签索引为0。如果输入是数值型,我们先将数值映射到字符串,再对字符串迕行索引化。如果下游的 pipeline(例如:Estimator 或者 Transformer)需要用到索引化后的标签序列,则需要将这个 pipeline 的输入列名字指定为索引化序列的名字。大部分情况下,通过setInputCol设置输入的列名。
2.9 IndexToString(索引-字符串变换)
与StringIndexer对应,IndexToString 将索引化标签还原成原始字符串。一个常用的场景是先通过 StringIndexer 产生索引化标签,然后使用索引化标签进行训练,最后再对预测结果使用IndexToString来获得其原始的标签字符串。
package sparkml
import org.apache.spark.ml.feature.{IndexToString, StringIndexer}
import org.apache.spark.sql.SparkSession
object StringToIndexer {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName("StringToIndexer")
.master("local[*]")
.getOrCreate()
spark.sparkContext.setLogLevel("WARN")
val df = spark.createDataFrame(Seq(
(0, "a"),
(1, "b"),
(2, "c"),
(3, "a"),
(4, "a"),
(5, "c")
)).toDF("id", "category")
//StringIndexer
val indexer = new StringIndexer()
.setInputCol("category")
.setOutputCol("categoryIndex")
.fit(df)
val indexed = indexer.transform(df)
indexed.show()
//IndexToString
val converter = new IndexToString()
.setInputCol("categoryIndex")
.setOutputCol("origCategory")
val converted = converter.transform(indexed)
converted.select("id", "categoryIndex", "origCategory").show()
}
}
运行结果如下所示:
+---+--------+-------------+
| id|category|categoryIndex|
+---+--------+-------------+
| 0| a| 0.0|
| 1| b| 2.0|
| 2| c| 1.0|
| 3| a| 0.0|
| 4| a| 0.0|
| 5| c| 1.0|
+---+--------+-------------+
+---+-------------+------------+
| id|categoryIndex|origCategory|
+---+-------------+------------+
| 0| 0.0| a|
| 1| 2.0| b|
| 2| 1.0| c|
| 3| 0.0| a|
| 4| 0.0| a|
| 5| 1.0| c|
+---+-------------+------------+
2.10 OneHotEncoder(独热编码)
独热编码将一列标签索引映射到一列二进制向量,最多只有一个单值。该编码允许期望连续特征的算法使用分类特征。
package sparkml
import org.apache.spark.ml.feature.{OneHotEncoder, StringIndexer}
import org.apache.spark.sql.SparkSession
object OneHotEncoder {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName("StringToIndexer")
.master("local[*]")
.getOrCreate()
spark.sparkContext.setLogLevel("WARN")
val df = spark.createDataFrame(Seq(
(0, "a"),
(1, "b"),
(2, "c"),
(3, "a"),
(4, "a"),
(5, "c")
)).toDF("id", "category")
//StringIndexer
val indexer = new StringIndexer()
.setInputCol("category")
.setOutputCol("categoryIndex")
.fit(df)
val indexed = indexer.transform(df)
val encoder = new OneHotEncoder()
.setInputCol("categoryIndex")
.setOutputCol("categoryVec")
val encoded = encoder.transform(indexed)
encoded.show()
}
}
运行结果如下:
+---+--------+-------------+-------------+
| id|category|categoryIndex| categoryVec|
+---+--------+-------------+-------------+
| 0| a| 0.0|(2,[0],[1.0])|
| 1| b| 2.0| (2,[],[])|
| 2| c| 1.0|(2,[1],[1.0])|
| 3| a| 0.0|(2,[0],[1.0])|
| 4| a| 0.0|(2,[0],[1.0])|
| 5| c| 1.0|(2,[1],[1.0])|
+---+--------+-------------+-------------+
2.11 VectorIndexer(向量类型索引化)
VectorIndexer是指定向量数据集中的分类(离散)特征。它可以自动确定哪些特征是离散的,并将原始值转换为离散索引。具体来说,它执行以下操作:取一个Vector类型的输入列和一个参数maxCategories;根据不同值的数量确定哪些特征是离散,其中最多maxCategories的功能被声明为分类;为每个分类功能计算基于0的类别索引;索引分类特征并将原始特征值转换为索引;索引分类功能允许诸如决策树和树组合之类的算法适当地处理分类特征,提高性能。
2.12 Interaction(相互作用)
交互是一个变换器,它采用向量或双值列,并生成一个单个向量列,其中包含来自每个输入列的一个值的所有组合的乘积。例如:你有2个向量类型的列,每个列具有3个维度作为输入列,那么你将获得一个9维向量作为输出列。
package sparkml
import org.apache.spark.ml.feature.{Interaction, VectorAssembler}
import org.apache.spark.sql.SparkSession
object Interaction {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName("Interaction")
.master("local[*]")
.getOrCreate()
spark.sparkContext.setLogLevel("WARN")
val df = spark.createDataFrame(Seq(
(1, 1, 2, 3, 8, 4, 5),
(2, 4, 3, 8, 7, 9, 8),
(3, 6, 1, 9, 2, 3, 6),
(4, 10, 8, 6, 9, 4, 5),
(5, 9, 2, 7, 10, 7, 3),
(6, 1, 1, 4, 2, 8, 4)
)).toDF("id1", "id2", "id3", "id4", "id5", "id6", "id7")
val assembler1 = new VectorAssembler()
.setInputCols(Array("id2", "id3", "id4"))
.setOutputCol("vec1")
val assembled1 = assembler1.transform(df)
val assembler2 = new VectorAssembler().
setInputCols(Array("id5", "id6", "id7")).
setOutputCol("vec2")
val assembled2 = assembler2.transform(assembled1)
.select("id1", "vec1", "vec2")
val interaction = new Interaction()
.setInputCols(Array("id1", "vec1", "vec2"))
.setOutputCol("interactedCol")
val interacted = interaction.transform(assembled2)
interacted.show(truncate = false)
}
}
运行结果如下:
+---+--------------+--------------+------------------------------------------------------+
|id1|vec1 |vec2 |interactedCol |
+---+--------------+--------------+------------------------------------------------------+
|1 |[1.0,2.0,3.0] |[8.0,4.0,5.0] |[8.0,4.0,5.0,16.0,8.0,10.0,24.0,12.0,15.0] |
|2 |[4.0,3.0,8.0] |[7.0,9.0,8.0] |[56.0,72.0,64.0,42.0,54.0,48.0,112.0,144.0,128.0] |
|3 |[6.0,1.0,9.0] |[2.0,3.0,6.0] |[36.0,54.0,108.0,6.0,9.0,18.0,54.0,81.0,162.0] |
|4 |[10.0,8.0,6.0]|[9.0,4.0,5.0] |[360.0,160.0,200.0,288.0,128.0,160.0,216.0,96.0,120.0]|
|5 |[9.0,2.0,7.0] |[10.0,7.0,3.0]|[450.0,315.0,135.0,100.0,70.0,30.0,350.0,245.0,105.0] |
|6 |[1.0,1.0,4.0] |[2.0,8.0,4.0] |[12.0,48.0,24.0,12.0,48.0,24.0,48.0,192.0,96.0] |
+---+--------------+--------------+------------------------------------------------------+
2.13 Normalizer(范数p-norm规范化)
Normalizer是一个转换器,它可以将一组特征向量规划范,参数为p,默认值为2,p指定规范化中使用的p-norm。规范化操作可以使输入数据标准化,对后期机器学习算法的结果也有更好的表现。
package sparkml
import org.apache.spark.ml.feature.Normalizer
import org.apache.spark.ml.linalg.Vectors
import org.apache.spark.sql.SparkSession
object Norm {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName("norm")
.master("local[*]")
.getOrCreate()
spark.sparkContext.setLogLevel("WARN")
val data = Seq(
(0, Vectors.dense(0.0, 1.0, -2.0)),
(1, Vectors.dense(2.0, 0.0, 3.0)),
(2, Vectors.dense(4.0, 10.0, 2.0))
)
val df = spark.createDataFrame(data).toDF("id", "features")
val normalizer = new Normalizer()
.setInputCol("features")
.setOutputCol("normFeatures")
.setP(1.0)
val l1NormData = normalizer.transform(df)
l1NormData.show()
val lInfNormData = normalizer.transform(df, normalizer.p -> Double.PositiveInfinity)
lInfNormData.show()
}
}
运行结果如下:
+---+--------------+--------------------+
| id| features| normFeatures|
+---+--------------+--------------------+
| 0|[0.0,1.0,-2.0]|[0.0,0.3333333333...|
| 1| [2.0,0.0,3.0]| [0.4,0.0,0.6]|
| 2|[4.0,10.0,2.0]| [0.25,0.625,0.125]|
+---+--------------+--------------------+
+---+--------------+--------------------+
| id| features| normFeatures|
+---+--------------+--------------------+
| 0|[0.0,1.0,-2.0]| [0.0,0.5,-1.0]|
| 1| [2.0,0.0,3.0]|[0.66666666666666...|
| 2|[4.0,10.0,2.0]| [0.4,1.0,0.2]|
+---+--------------+--------------------+
2.14 StandardScaler(标准化)
StandardScaler转换Vector行的数据集,使每个要素标准化以具有单位标准偏差和或零均值。它需要参数:
withStd:默认为True。将数据缩放到单位标准偏差。
withMean:默认为false。在缩放之前将数据中心为平均值。它将构建一个密集的输出,所以在应用于稀疏输入时要小心。
StandardScaler是一个Estimator,可以适合数据集生成StandardScalerModel; 还相当于计算汇总统计数据。 然后,模型可以将数据集中的向量列转换为具有单位标准偏差和或零平均特征。
请注意,如果特征的标准偏差为零,它将在该特征的向量中返回默认的0.0值。
2.15 MinMaxScaler(最大-最小规范化)
MinMaxScaler转换Vector行的数据集,将每个要素重新映射到特定范围(通常为[0,1])。它需要参数:
min:默认为0.0,转换后的下限。
max:默认为1.0,转换后的上限。
MinMaxScaler计算数据集的统计信息,并生成MinMaxScalerModel。然后,模型可以单独转换每个要素,使其在给定的范围内。
特征E的重新缩放值被计算为:
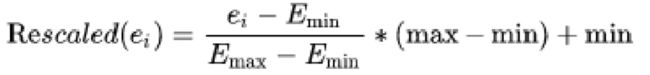
package sparkml
import org.apache.spark.ml.feature.MinMaxScaler
import org.apache.spark.ml.linalg.Vectors
import org.apache.spark.sql.SparkSession
object MinMaxScaler {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName("MinMaxScaler")
.master("local[*]")
.getOrCreate()
spark.sparkContext.setLogLevel("WARN")
val data = Seq(
(0, Vectors.dense(0.0, 1.0, -2.0)),
(1, Vectors.dense(2.0, 0.0, 3.0)),
(2, Vectors.dense(4.0, 10.0, 2.0))
)
val df = spark.createDataFrame(data).toDF("id", "features")
val scaler = new MinMaxScaler()
.setInputCol("features")
.setOutputCol("scaledFeatures")
val scalerModel = scaler.fit(df)
val scaledData = scalerModel.transform(df)
println(s"Features scaled to range: [${scaler.getMin}, ${scaler.getMax}]")
scaledData.select("features", "scaledFeatures").show()
}
}
运行代码如下:
Features scaled to range: [0.0, 1.0]
+--------------+--------------+
| features|scaledFeatures|
+--------------+--------------+
|[0.0,1.0,-2.0]| [0.0,0.1,0.0]|
| [2.0,0.0,3.0]| [0.5,0.0,1.0]|
|[4.0,10.0,2.0]| [1.0,1.0,0.8]|
+--------------+--------------+
2.16 MaxAbsScaler(绝对值规范化)
MaxAbsScaler转换Vector行的数据集,通过划分每个要素中的最大绝对值,将每个要素的重新映射到范围[-1,1]。 它不会使数据移动/居中,因此不会破坏任何稀疏性。MaxAbsScaler计算数据集的统计信息,并生成MaxAbsScalerModel。然后,模型可以将每个要素单独转换为范围[-1,1]。
package sparkml
import org.apache.spark.ml.feature.MaxAbsScaler
import org.apache.spark.ml.linalg.Vectors
import org.apache.spark.sql.SparkSession
object MaxAbsScaler {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName("MaxAbsScaler")
.master("local[*]")
.getOrCreate()
spark.sparkContext.setLogLevel("WARN")
val data = Seq(
(0, Vectors.dense(0.0, 1.0, -2.0)),
(1, Vectors.dense(2.0, 0.0, 3.0)),
(2, Vectors.dense(4.0, 10.0, 2.0))
)
val df = spark.createDataFrame(data).toDF("id", "features")
val scaler = new MaxAbsScaler()
.setInputCol("features")
.setOutputCol("scaledFeatures")
val scalerModel = scaler.fit(df)
val scaledData = scalerModel.transform(df)
scaledData.select("features", "scaledFeatures").show()
}
}
运行结果如下:
+--------------+--------------------+
| features| scaledFeatures|
+--------------+--------------------+
|[0.0,1.0,-2.0]|[0.0,0.1,-0.66666...|
| [2.0,0.0,3.0]| [0.5,0.0,1.0]|
|[4.0,10.0,2.0]|[1.0,1.0,0.666666...|
+--------------+--------------------+
2.17 VectorAssembler(特征向量合并)
VectorAssembler 是将给定的一系列的列合并到单个向量列中的 transformer。它可以将原始特征和不同特征transformers(转换器)生成的特征合并为单个特征向量,来训练ML模型,如逻辑回归和决策树等机器学习算法。VectorAssembler可接受以下的输入列类型:所有数值型、布尔类型、向量类型。输入列的值将按指定顺序依次添加到一个向量中。
package sparkml
import org.apache.spark.ml.feature.VectorAssembler
import org.apache.spark.ml.linalg.Vectors
import org.apache.spark.sql.SparkSession
object VectorAssembler {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName("VectorAssembler")
.master("local[*]")
.getOrCreate()
spark.sparkContext.setLogLevel("WARN")
val data = Seq(
(0, 18, 1.0, Vectors.dense(0.0, 10.0, 0.5), 1.0)
)
val df = spark.createDataFrame(data).toDF("id", "hour", "mobile", "userFeatures", "clicked")
val assembler = new VectorAssembler()
.setInputCols(Array("hour", "mobile", "userFeatures"))
.setOutputCol("features")
val output = assembler.transform(df)
println(output.select("features", "clicked").first())
}
}
运行结果如下:
[[18.0,1.0,0.0,10.0,0.5],1.0]
2.18 QuantileDiscretizer(分位数离散化)
QuantileDiscretizer(分位数离散化)采用具有连续特征的列,并输出具有分类特征的列。bin(分级)的数量由numBuckets 参数设置。buckets(区间数)有可能小于这个值,例如,如果输入的不同值太少,就无法创建足够的不同的quantiles(分位数)。
NaN values:在QuantileDiscretizer fitting时,NaN值会从列中移除,还将产生一个Bucketizer模型进行预测。在转换过程中,Bucketizer 会发出错误信息当在数据集中找到NaN值,但用户也可以通过设置handleInvalid来选择保留或删除数据集中的NaN值。如果用户选择保留NaN值,那么它们将被特别处理并放入自己的bucket(区间)中。例如,如果使用4个buckets(区间),那么非NaN数据将放入buckets[0-3],NaN将计数在特殊的bucket[4]中。
Algorithm:使用近似算法来选择bin的范围。可以使用relativeError参数来控制近似的精度。当设置为零时,计算精确的quantiles(分位数)。
package sparkml
import org.apache.spark.ml.feature.QuantileDiscretizer
import org.apache.spark.sql.SparkSession
object QuantileDiscretizer {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName("QuantileDiscretizer")
.master("local[*]")
.getOrCreate()
spark.sparkContext.setLogLevel("WARN")
val data = Array((0, 18.0), (1, 19.0), (2, 8.0), (3, 5.0), (4, 2.2))
var df = spark.createDataFrame(data).toDF("id", "hour")
val discretizer = new QuantileDiscretizer()
.setInputCol("hour")
.setOutputCol("result")
.setNumBuckets(3)
val result = discretizer.fit(df)
.transform(df)
result.show()
}
}
运行结果如下:
+---+----+------+
| id|hour|result|
+---+----+------+
| 0|18.0| 2.0|
| 1|19.0| 2.0|
| 2| 8.0| 1.0|
| 3| 5.0| 1.0|
| 4| 2.2| 0.0|
+---+----+------+
2.19 其他的几种变换
package sparkml
import org.apache.spark.ml.feature.SQLTransformer
import org.apache.spark.sql.SparkSession
object SQLTransformer {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName("SQLTransformer")
.master("local[*]")
.getOrCreate()
spark.sparkContext.setLogLevel("WARN")
val df = spark.createDataFrame(
Seq((0, 1.0, 3.0), (2, 2.0, 5.0))).toDF("id", "v1", "v2")
val sqlTrans = new SQLTransformer()
.setStatement("SELECT *, (v1 + v2) AS v3, (v1 * v2) AS v4 FROM __THIS__")
sqlTrans.transform(df).show(false)
}
}
+---+---+---+---+----+
|id |v1 |v2 |v3 |v4 |
+---+---+---+---+----+
|0 |1.0|3.0|4.0|3.0 |
|2 |2.0|5.0|7.0|10.0|
+---+---+---+---+----+
package sparkml
import org.apache.spark.ml.feature.Bucketizer
import org.apache.spark.sql.SparkSession
object Bucketizer {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName("Bucketizer")
.master("local[*]")
.getOrCreate()
val splits = Array(Double.NegativeInfinity, -0.5, 0.0, 0.5, Double.PositiveInfinity)
val data = Array(-999.9, -0.5, -0.3, 0.0, 0.2, 999.9)
val dataFrame = spark.createDataFrame(data.map(Tuple1.apply)).toDF("features")
val bucketizer = new Bucketizer()
.setInputCol("features")
.setOutputCol("bucketedFeatures")
.setSplits(splits)
val bucketedData = bucketizer.transform(dataFrame)
println(s"Bucketizer output with ${bucketizer.getSplits.length-1} buckets")
bucketedData.show()
}
}
Bucketizer output with 4 buckets
+--------+----------------+
|features|bucketedFeatures|
+--------+----------------+
| -999.9| 0.0|
| -0.5| 1.0|
| -0.3| 1.0|
| 0.0| 2.0|
| 0.2| 2.0|
| 999.9| 3.0|
+--------+----------------+
package sparkml
import org.apache.spark.ml.feature.ElementwiseProduct
import org.apache.spark.ml.linalg.Vectors
import org.apache.spark.sql.SparkSession
object ElementwiseProduct {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName("Bucketizer")
.master("local[*]")
.getOrCreate()
spark.sparkContext.setLogLevel("WARN")
val dataFrame = spark.createDataFrame(Seq(
("a", Vectors.dense(1.0, 2.0, 3.0)),
("b", Vectors.dense(4.0, 5.0, 6.0)))).toDF("id", "vector")
val transformingVector = Vectors.dense(0.0, 1.0, 2.0)
val transformer = new ElementwiseProduct()
.setScalingVec(transformingVector)
.setInputCol("vector")
.setOutputCol("transformedVector")
transformer.transform(dataFrame).show(false)
}
}
+---+-------------+-----------------+
|id |vector |transformedVector|
+---+-------------+-----------------+
|a |[1.0,2.0,3.0]|[0.0,2.0,6.0] |
|b |[4.0,5.0,6.0]|[0.0,5.0,12.0] |
+---+-------------+-----------------+
三、特征的选择
3.1 VectorSlicer(向量切片机)
向量切片机是一个转换器,它采用特征向量,并输出一个新的特征向量与原始特征的子阵列。从向量列中提取特征很有用。向量切片机接受具有指定索引的向量列,然后输出一个新的向量列,其值通过这些索引进行选择。有两种类型的指数:代表向量中的索引的整数索引,setIndices();表示向量中特征名称的字符串索引,setNames(),此类要求向量列有AttributeGroup,因为实现在Attribute的name字段上的匹配。
整数和字符串的规格都可以接受。此外,可以同时使用整数索引和字符串名称。必须至少选择一个特征。重复的功能是不允许的,所以选择的索引和名词之间不能有重叠。如果选择了功能的名称,则在遇到空的输入属性时会抛出异常。
package sparkml
import java.util
import org.apache.spark.ml.attribute.{Attribute, AttributeGroup, NumericAttribute}
import org.apache.spark.ml.feature.VectorSlicer
import org.apache.spark.ml.linalg.Vectors
import org.apache.spark.sql.types.StructType
import org.apache.spark.sql.{Row, SparkSession}
object VectorSlicer {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName("VectorSlicer")
.master("local[*]")
.getOrCreate()
spark.sparkContext.setLogLevel("WARN")
val data = util.Arrays.asList(
Row(Vectors.sparse(3, Seq((0, -2.0), (1, 2.3)))),
Row(Vectors.dense(-2.0, 2.3, 0.0))
)
val defaultAttr = NumericAttribute.defaultAttr
val attrs = Array("f1", "f2", "f3").map(defaultAttr.withName)
val attrGroup = new AttributeGroup("userFeatures", attrs.asInstanceOf[Array[Attribute]])
val dataset = spark.createDataFrame(data, StructType(Array(attrGroup.toStructField())))
val slicer = new VectorSlicer()
.setInputCol("userFeatures")
.setOutputCol("features")
slicer.setIndices(Array(1)).setNames(Array("f3"))
val output = slicer.transform(dataset)
output.show(false)
}
}
+--------------------+-------------+
|userFeatures |features |
+--------------------+-------------+
|(3,[0,1],[-2.0,2.3])|(2,[0],[2.3])|
|[-2.0,2.3,0.0] |[2.3,0.0] |
+--------------------+-------------+
3.2 RFormula(R模型公式)
RFormula选择由R模型公式指定的列。目前,支持R运算符的有限子集,包括’’,’.’,’:’,‘+’以及’-’,基本操作如下:分割目标和对象;+合并对象,“+0”表示删除截距;-删除对象,“-1”表示删除截距;:交互(数字乘法或二值化分类值);.出了目标外的全部列。
package sparkml
import org.apache.spark.ml.feature.RFormula
import org.apache.spark.sql.SparkSession
object RFormula {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName("RFormula")
.master("local[*]")
.getOrCreate()
spark.sparkContext.setLogLevel("WARN")
val dataset = spark.createDataFrame(Seq(
(7, "US", 18, 1.0),
(8, "CA", 12, 0.0),
(9, "NZ", 15, 0.0)
)).toDF("id", "country", "hour", "clicked")
val formula = new RFormula()
.setFormula("clicked ~ country + hour")
.setFeaturesCol("features")
.setLabelCol("label")
val output = formula.fit(dataset).transform(dataset)
output.select("features", "label").show()
}
}
运行结果如下:
+--------------+-----+
| features|label|
+--------------+-----+
|[0.0,0.0,18.0]| 1.0|
|[1.0,0.0,12.0]| 0.0|
|[0.0,1.0,15.0]| 0.0|
+--------------+-----+
3.3 ChiSqSelector(卡方特征选择器)
ChiSqSelector代表卡方特征选择。它适用于带有类别特征的标签数据。ChiSqSelector使用卡方独立测试来决定选择哪些特征。它支持三种选择方法:numTopFeatures, percentile, fpr。
numTopFeatures根据卡方检验选择固定数量的顶级功能。返类似于产生具有最大预测能力的功能;
percentile类似于numTopFeatures,但选择所有功能的一部分,而不是固定数量;
fpr选择p值低于阈值的所有特征,从而控制选择的假阳性率。
默认情况下,选择方法是numTopFeatures,默认的顶级功能数量设置为50。用户可以使用setSelectorType选择一种选择方法。
package sparkml
import org.apache.spark.ml.feature.ChiSqSelector
import org.apache.spark.ml.linalg.Vectors
import org.apache.spark.sql.SparkSession
object ChiSqSelector {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName("ChiSqSelector")
.master("local[*]")
.getOrCreate()
spark.sparkContext.setLogLevel("WARN")
val data = Seq(
(7, Vectors.dense(0.0, 1.0, -2.0, 1.0), 1.0),
(8, Vectors.dense(2.0, 0.0, 3.0, 0.0), 0.0),
(9, Vectors.dense(4.0, 10.0, 2.0, 0.1), 0.0)
)
val df = spark.createDataFrame(data).toDF("id", "features", "clicked")
val selector = new ChiSqSelector()
.setNumTopFeatures(1)
.setFeaturesCol("features")
.setLabelCol("clicked")
.setOutputCol("selectedFeatures")
val result = selector.fit(df)
.transform(df)
println(s"ChiSqSelector output with top ${selector.getNumTopFeatures} features selected")
result.show()
}
}
运行结果如下:
ChiSqSelector output with top 1 features selected
+---+------------------+-------+----------------+
| id| features|clicked|selectedFeatures|
+---+------------------+-------+----------------+
| 7|[0.0,1.0,-2.0,1.0]| 1.0| [0.0]|
| 8| [2.0,0.0,3.0,0.0]| 0.0| [2.0]|
| 9|[4.0,10.0,2.0,0.1]| 0.0| [4.0]|
+---+------------------+-------+----------------+