sklearn Decision Trees决策树
决策树
引导
sklearn.enseable集成算法,包括两个算法随机森林 RandomForest和极限森林 Extra-Trees,这些都是基于决策树。decision trees 用于分类和回归
什么是决策树?
决策树分类的思想类似于找对象。现想象一个女孩的母亲要给这个女孩介绍男朋友,于是有了下面的对话:
女儿:多大年纪了?
母亲:26。
女儿:长的帅不帅?
母亲:挺帅的。
女儿:收入高不?
母亲:不算很高,中等情况。
女儿:是公务员不?
母亲:是,在税务局上班呢。
女儿:那好,我去见见
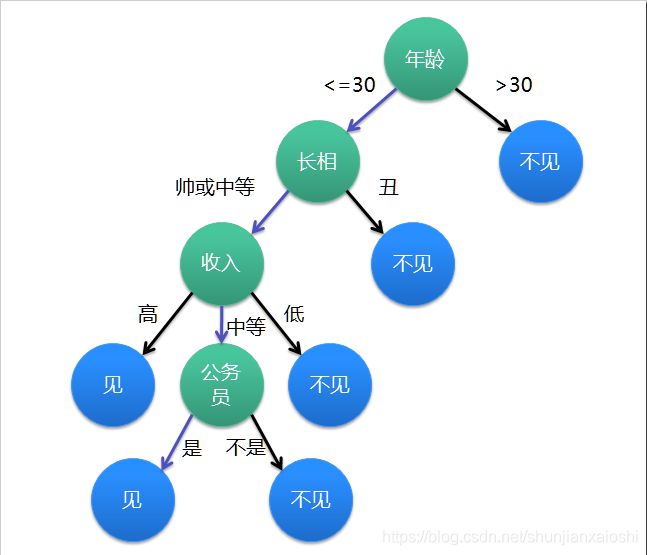
上图完整表达了这个女孩决定是否见一个约会对象的策略,其中绿色节点表示判断条件,蓝色节点表示决策结果,箭头表示在一个判断条件在不同情况下的决策路径,图中绿色箭头表示了上面例子中女孩的决策过程。
这幅图基本可以算是一颗决策树,说它“基本可以算”是因为图中的判定条件没有量化,如收入高中低等等,还不能算是严格意义上的决策树,如果将所有条件量化,则就变成真正的决策树了。
决策树(decision tree)是一个树结构(可以是二叉树或非二叉树)。其每个非叶节点表示一个特征属性上的测试,每个分支代表这个特征属性在某个值域上的输出,而每个叶节点存放一个类别。使用决策树进行决策的过程就是从根节点开始,测试待分类项中相应的特征属性,并按照其值选择输出分支,直到到达叶子节点,将叶子节点存放的类别作为决策结果。
决策树的优势
K-近邻算法可以完成很多分类任务,但是它最大的缺点就是无法给出数据的内在含义,决策树的主要优势就在于数据形式非常容易理解。决策树算法能够读取数据集合,构建类似于上面的决策树。决策树很多任务都是为了数据中所蕴含的知识信息,因此决策树可以使用不熟悉的数据集合,并从中提取出一系列规则,机器学习算法最终将使用这些机器从数据集中创造的规则。
决策树原理
决策树用到的是信息论,划分原则是将无序的数据结构化变得更加有序。有序和无序的度量我们使用熵来度量。
构造决策树
不同于逻辑斯蒂回归(最大似然,就是概率)和贝叶斯算法(概率论),决策树的构造过程不依赖领域知识,它使用属性选择度量来选择将元组最好地划分成不同的类的属性。所谓决策树的构造就是进行属性选择度量确定各个特征属性之间的拓扑结构。
构造决策树的关键步骤是分裂属性。所谓分裂属性就是在某个节点处按照某一特征属性的不同划分构造不同的分支,其目标是让各个分裂子集尽可能地“纯”。尽可能“纯”就是尽量让一个分裂子集中待分类项属于同一类别。
分裂属性分为三种不同的情况:
1、属性是离散值且不要求生成二叉决策树。此时用属性的每一个划分作为一个分支。
2、属性是离散值且要求生成二叉决策树。此时使用属性划分的一个子集进行测试,按照“属于此子集”和“不属于此子集”分成两个分支。
3、属性是连续值。此时确定一个值作为分裂点split_point,按照>split_point和<=split_point生成两个分支。
构造决策树的关键性内容是进行属性选择度量,属性选择度量是一种选择分裂准则,它决定了拓扑结构及分裂点split_point的选择。
属性选择度量算法有很多,一般使用自顶向下递归分治法,并采用不回溯的贪心策略。这里介绍常用的ID3算法。
贪心算法(又称贪婪算法)是指,在对问题求解时,总是做出在当前看来是最好的选择。也就是说,不从整体最优上加以考虑,他所做出的是在某种意义上的局部最优解
ID3算法
我们之前说到,有序和无序。那么有序和无序的度量我们使用熵来度量。熵这个概念最早起源于物理学,在物理学中是用来度量一个热力学系统的无序程度。
而在信息学里面,熵是对不确定性的度量。
在1948年,香农引入了信息熵,将其定义为离散随机事件出现的概率,一个系统越是有序,信息熵就越低,反之一个系统越是混乱,它的信息熵就越高。所以信息熵可以被认为是系统有序化程度的一个度量。
计算公式:
H = − ∑ i = 1 n p ( x i ) l o g 2 p ( x i ) H=-\sum^{n}_{i=1}p(x_{i})log_{2}p(x_{i}) H=−i=1∑np(xi)log2p(xi)
n是分类的数目,p(x)是概率,0~1之间,所以求对数是负数,熵是物理度量,是正数,所以前面得加个负号
ID3算法就是在每次需要分裂时,计算每个属性的增益率,然后选择增益率最大的属性进行分裂
信息增益
将数据进行排序后,熵变小了,原来的熵减去现在的熵就叫做,信息增益。
在划分数据集之前之后信息发生的变化称为信息增益,知道如何计算信息增益,我们就可以计算每个特征值划分数据集获得的信息增益,获得信息增益最高的特征就是最好的选择。信息增益即为两者的差值
ID3算法的发展
之后在ID3算法之上有C4.5算法(移除了必须是分类变量,现在它可以支持数字化的特征了),C5.0对内存进行了优化准确率更高,都是继承自ID3算法。CART(Classification and Regression Trees)和C4.5很相似,不同在于它支持回归(目标值的数据是连续地,类别分的多久慢慢变成回归了)
scikit-learn算法使用CART算法,目前它不支持分类变量(说明事物类别的一个名称,其取值是分类数据。如“性别”就是一个分类变量,其变量值为“男”或“女”),但是可以使用方法转换成量化的数字。
分类标准有熵和基尼系数两种
小案例
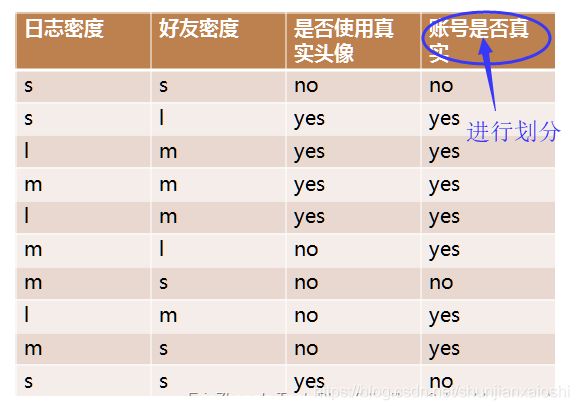

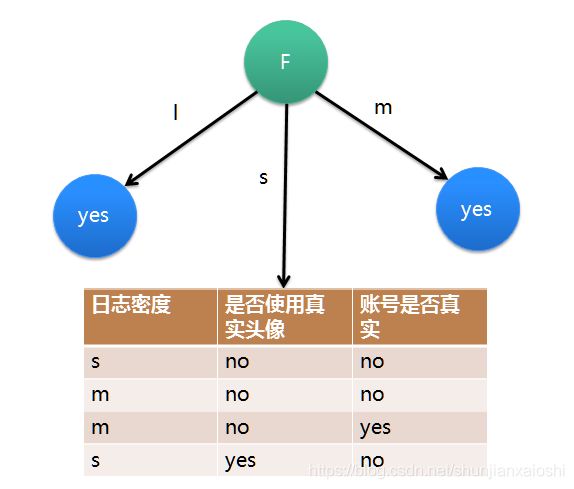
在上图的基础上,再递归使用这个方法计算子节点的分裂属性,最终就可以得到整个决策树
− ∑ i = 1 n p ( x i ) ∗ l o g 2 p ( x i ) -\sum_{i = 1}^{n}{p(xi)*log_2p(xi)} −i=1∑np(xi)∗log2p(xi)
∑ i = 1 n p ( x i ) ∗ l o g 2 1 p ( x i ) \sum_{i=1}^{n}p(xi)*log_2\frac{1}{p(xi)} i=1∑np(xi)∗log2p(xi)1
import numpy as np
# 对最后一列账号是否真实进行划分:3no(0.3) 7yes(0.7)
# 不进行划分,信息熵
info_D = 0.3*np.log2(1/0.3) + 0.7*np.log2(1/0.7)
info_D
#0.8812908992306926
# 决策树,对目标值进行划分
# 三个属性:日志密度,好友密度,是否真实头像
# 使用日志密度进行树构建
# 3 s 0.3 -------> 2no 1yes
# 4 m 0.4 -------> 1no 3yes
# 3 l 0.3 -------> 3yes
info_L_D = 0.3*(2/3*np.log2(3/2) + 1/3*np.log2(3)) + 0.4 * (0.25*np.log2(4) + 0.75*np.log2(4/3)) + 0.3*(1*np.log2(1))
info_L_D
#0.5999999999999999
# 信息增益
info_D - info_L_D
#0.2812908992306927
另一个分支 好友密度
# 好友密度
# 4 s 0.4 ---> 3no 1yes
# 4 m 0.4 ---> 4yes
# 2 l 0.2 ---> 2yes
info_F_D = 0.4*(0.75*np.log2(4/3) + 0.25*np.log2(4)) + 0 + 0
info_F_D
#0.32451124978365314
# 信息增益
info_D - info_F_D
#0.5567796494470394
#信息增益最大,所以决策树划分的时候把好友密度放在第一位
决策树的使用
import numpy as np
from sklearn.tree import DecisionTreeClassifier
from sklearn import datasets
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn import tree
from sklearn.model_selection import train_test_split
iris = datasets.load_iris()
X = iris['data']
y = iris['target']
feature_names = iris.feature_names
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size = 0.2,random_state = 1024)#每次生成的随机数据都一样
# 数据清洗,花时间
# 特征工程
# 使用模型进行训练
# 模型参数调优
# sklearn所有算法,封装好了
# 直接用,使用规则如下
clf = DecisionTreeClassifier(criterion='entropy') #标准 默认是基尼系数'gini'我们改为'entropy'信息熵 splitter默认'best'信息增益最大 可选随机 max_depth最大深度 min_samples_split min_samples_leaf通过它对数进行减枝
clf.fit(X_train,y_train)
y_ = clf.predict(X_test)
from sklearn.metrics import accuracy_score
accuracy_score(y_test,y_)
#1.0
39/120*np.log2(120/39) + 42/120*np.log2(120/42) + 39/120*np.log2(120/39)
#1.5840680553754911
42/81*np.log2(81/42) + 39/81*np.log2(81/39)
#0.9990102708804813
#通过画图展现决策树
plt.figure(figsize=(18,12)) #调大小
_ = tree.plot_tree(clf,filled = True,feature_names=feature_names,max_depth=1)#填充颜色 深度为1
plt.savefig('./tree.jpg')
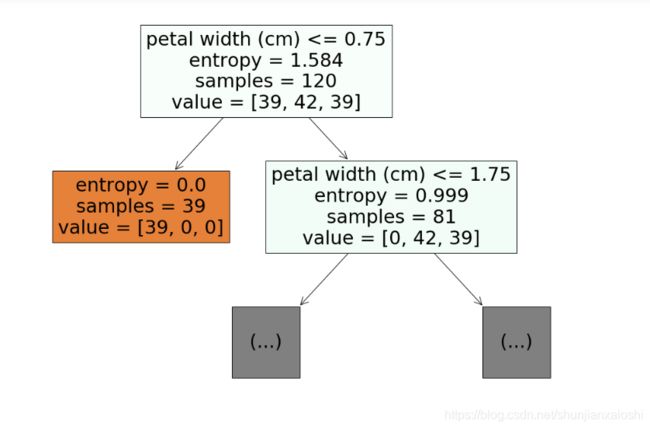
分支左边,颜色越深越纯,39个类别0,0个类别1和类别2
上面算法max_depth改为1的时候,准确率为0.67,为2的时候准确率为0.96,为None不指定,准确率为1。深度越深,运行时间约长。不一定最深的时候准确率最大,可能在之前就已经准确率最大了。所以需要找这个平衡点。
%%time
# 树的深度变浅了,树的裁剪
clf = DecisionTreeClassifier(criterion='entropy',max_depth=5)
clf.fit(X_train,y_train)
y_ = clf.predict(X_test)
from sklearn.metrics import accuracy_score
print(accuracy_score(y_test,y_))
plt.figure(figsize=(18,12))
_ = tree.plot_tree(clf,filled=True,feature_names = feature_names)
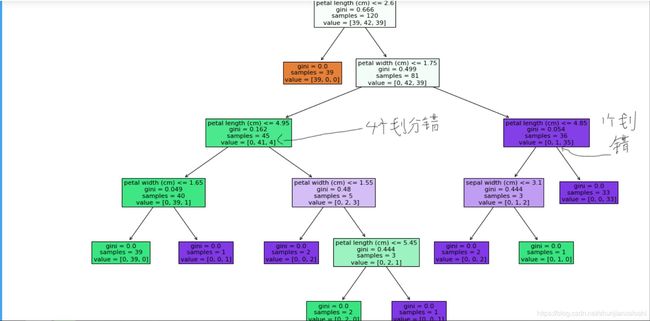
#我们裂分的数据特征是连续的,上面例子里面的s m l不是
# 连续的,continuous 属性 阈值 threshold
X_train
#array([[5.4, 3. , 4.5, 1.5],
# [6.1, 3. , 4.9, 1.8],
# [6.4, 2.7, 5.3, 1.9],
# [5.6, 2.8, 4.9, 2. ],...
#使用哪个特征变量都行 就看哪个的熵最小
#为什么选择petal length进行裂分?
# 波动程度,越大,离散,越容易分开
X_train.std(axis = 0)
#array([0.82300095, 0.42470578, 1.74587112, 0.75016619])
#第三个值最大 标准差越大 越波动 越能分开
np.sort(X_train[:,2])
#array([1. , 1.1, 1.2, 1.2, 1.3, 1.3, 1.3, 1.3, 1.3, 1.3, 1.4, 1.4, 1.4,1.4, 1.4, 1.4, 1.4, 1.4, 1.4, 1.5, 1.5, 1.5, 1.5, 1.5, 1.5, 1.5,1.5, 1.5, 1.5, 1.5, 1.5, 1.6, 1.6, 1.6, 1.7, 1.7, 1.7, 1.7, 1.9,第二类:3.3, 3.5, 3.5, 3.6, 3.7, 3.8, 3.9, 3.9, 3.9, 4. , 4. , 4. , 4. ,4.1, 4.1, 4.1, 4.2, 4.2, 4.2, 4.2, 4.3, 4.4, 4.4, 4.4, 4.5, 4.5,4.5, 4.5, 4.5, 4.5, 4.5, 4.6, 4.6, 4.6, 4.7, 4.7, 4.7, 4.7, 4.8,4.8, 4.8, 4.8, 4.9, 4.9, 4.9,第三类:5. , 5. , 5. , 5.1, 5.1, 5.1, 5.1,5.1, 5.1, 5.1, 5.2, 5.2, 5.3, 5.3, 5.4, 5.4, 5.5, 5.5, 5.5, 5.6,5.6, 5.6, 5.7, 5.8, 5.9, 5.9, 6. , 6. , 6.1, 6.1, 6.1, 6.3, 6.4,6.7, 6.7, 6.9])
#1.9 + 3.3 = 5.2
#5.2/2 = 2.6
#已经将第一类划分出去了,现在分第二类和第三类
X_train2 = X_train[y_train != 0]
X_train2
#array([[5.4, 3. , 4.5, 1.5],
# [6.1, 3. , 4.9, 1.8],...
#petal width第四个属性 它不是波动性最大的 还会有其他因素
X_train[y_train!=0].std(axis=0)
#array([0.66470906,0.32769349,0.80409522,0.4143847])
y_train2 = y_train[y_train!=0]
y_train2
#array([1, 2, 2, 2, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 1, 2, 2, 2, 1, 2, 2, 1,2, 1, 2, 2, 1, 1, 2, 2, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 1, 1, 2,2, 2, 2, 2, 1, 2, 1, 2, 2, 1, 2, 1, 1, 2, 1, 2, 2, 2, 1, 1, 2, 1,1, 1, 2, 2, 1, 1, 1, 1, 1, 1, 2, 1, 2, 1, 2])
#决策树在进行裂分的时候会先求熵,选择信息增益最大的那个
index = np.argsort(X_train2[:,0])
display(X_train2[:,0][index])
y_train2[index]

index = np.argsort(X_train2[:,1])
display(X_train2[:,1][index])
y_train2[index]
#使用它裂分 完全不好 你中有我 我中有你

index = np.argsort(X_train2[:,2])
display(X_train2[:,2][index])
y_train2[index]
#分的比较开 所以选择它

index = np.argsort(X_train2[:,3])
display(X_train2[:,3][index])
y_train2[index]
# 决策树模型,不需要对数据进行去量纲化,规划化,标准化
# 决策树升级版:集成算法(随机森林,(extrem)极限森林,梯度提升树,adaboost提升树)

使用gini系数
%%time
# 树的深度变浅了,树的裁剪
clf = DecisionTreeClassifier(criterion='gini',max_depth=5)
clf.fit(X_train,y_train)
y_ = clf.predict(X_test)
from sklearn.metrics import accuracy_score
print(accuracy_score(y_test,y_))
plt.figure(figsize=(18,12))
_ = tree.plot_tree(clf,filled=True,feature_names = feature_names)
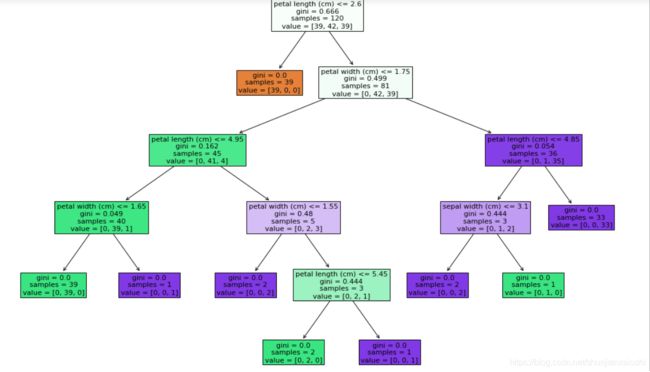
∑ i = 0 n p ( x i ) ∗ ( 1 − p ( x i ) ) \sum_{i = 0}^{n}p(xi)*(1-p(xi)) i=0∑np(xi)∗(1−p(xi))
# 1.0 其余都是0
# 百分之百纯
gini = 1*(1-1)
gini
#0
# 39 42 39
#39/120*(1 - 39/120)*2 + 42/120*(1 - 42/120)
#0.66625