我参加 NVIDIA Sky Hackathon---yolov5数据标注+模型训练
在标注过程中,将图片分为三类,分别为banana、zhiban、yilaguan三个类别,在yolov5的数据labels标注种分别将其划为0,1,2三类。在确定了分类规则后,使用labelimg进行标注。在此附上labelimg的项目代码:https://github.com/tzutalin/labelImg
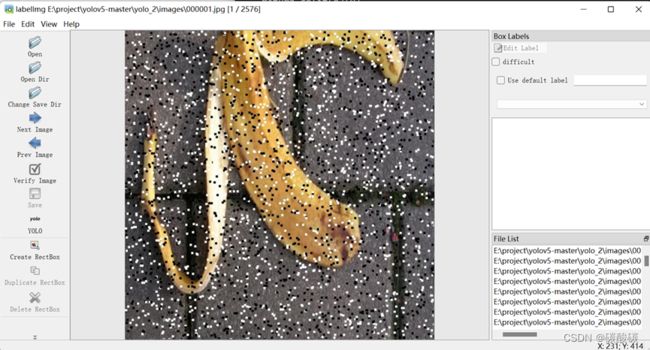
标注工作完成后,因本项目采用的是yolo格式的数据集,所以在模型导出的过程中需要设定为yolo格式。小组同时就官方给的xml类型的标注labels编写脚本进行转换,待所有数据格式转换完毕后,将labels中的框画到图片中以测试效果:

在此小组也尝试了一种更为高效的标注平台CVAT,此平台需要在linux平台中部署,并且可以开启一个服务器,小组成员所有人都可以同时在这个标注平台上进行标注,管理员可以在后台给每个成员创建账号,并在其中给每个成员创建标注任务,就并发性和界面UI的设计上来说要优于labelmg不少。同样,在此附上CVAT的项目代码:GitHub - opencv/cvat: Annotate better with CVAT, the industry-leading data engine for machine learning. Used and trusted by teams at any scale, for data of any scale.
其次,我们针对模型的鲁棒性进行优化,对于图片大小编写脚本对图片随机添加3000个大小为3*3像素点的椒盐噪声,虽然会相对降低模型的精确度,但是就综合性能来说还是有一定提升。

核心代码如下:
for i in range(0, temp):
if random.randint(1, temp) % 2 == 0:
newheight= random.randint(0, height)
newwidth=random.randint(0, width)
img[newheight:min(newheight+3,height), newwidth:min(newwidth+3,width)] = (255, 255, 255)
if random.randint(1, temp) % 2 != 0:
newheight= random.randint(0, height)
newwidth=random.randint(0, width)
img[newheight:min(newheight+3,height), newwidth:min(newwidth+3,width)] = (0, 0, 0)
- 模型训练
- 硬件选择
对于模型的训练过程,我们基于小组成员的机器配置情况,考虑到充分利用到GPU的性能,我们使用小组成员的RTX3060显卡,使用yolov5x预训练模型,以batch 8训练300批,在经过效果评估后,虽然效果差强人意,但是为了追求更好的训练效果,突破硬件设备限制,我们分别采用了Kaggle上的GPU训练和租用阿里的服务器分别进行训练。经过13小时的训练,训练完成并获取到了best.pt和last.pt
- 训练流程
在训练过程中,我们使用yolov5x预训练模型对数据集进行训练,下图是训练命令和测试命令:
![]()
![]()
在训练和推理命令中我们可以看到, batch-size为8,训练300批次。在推理中我们保存每一张图片的txt,以及每一个类别中分别成功识别了哪些图片。
在训练的过程中,因为需要对模型进行一些超参数的设置以优化训练效果,而yolov5自带了这样一种超参数的设置方法,如图:

在模型训练优化过程中,我们主要调整马赛克功能和图片的缩放、剪切、旋转,在对模型进行了超参数的调整后,可以正式开始训练。
- 效果评估
下图为训练完毕后生成的两个模型文件以及参数评估:
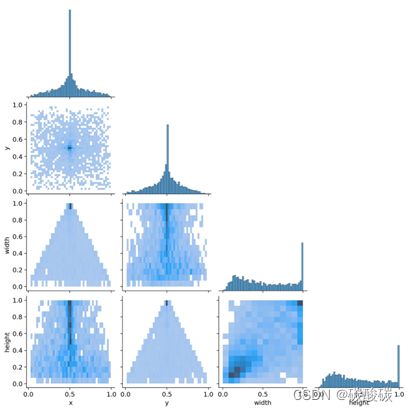
在最终的模型训练完毕后,我们对模型进行了准确率评估,最终我们得到的结果为:
