【MySQL】事务和索引
文章目录
- 事务(Transaction)
-
- 1. 定义
- 2. 如何操作事务
-
- 2.1 SQL 语句操作事务的几个关键字
- 2.2 使用 SQL 语句操作事务
- 2.3 JDBC 操作事务
- 3. 事务的四个特性:ACID
- 3.1 Atomic(原子性)
-
- 3.1.1 理解原子性
- 3.2 Consistency(一致性)
-
- 3.2.1 以银行转账的例子理解一致性
- 3.3 Isolation(隔离性)
- 3.4 Durability(持久性)
- 4. 隔离级别
-
- 4.1 读未提交
- 4.2 读已提交
- 4.3 可重复读
- 4.4 快照读
- 4.5 可串行化
- 索引
-
- 1. 索引的分类
- 2. 索引的作用
- 3. 创建索引
- 4. 索引的基本原理
-
- 4.1 添加索引之后的查询过程
- 5. 索引的 hit 和 miss
- 6. 索引的优缺点
- 7. 索引的使用场景
- 8. 了解 explain 命令
事务(Transaction)
1. 定义
- 事务这个词的含义很广泛,并不一定特指数据库中的事务
- 在开发者看来,一个不可再分的业务动作就是一个事务,这个动作最终表达为一条或者多条 SQL 语句
2. 如何操作事务
2.1 SQL 语句操作事务的几个关键字
==start transaction:==开启事务
==rollback:==回滚,主动让事务失败
==commit:==提交事务,代表事务完成,对事物的所有操作在 commit 之后才会生效
2.2 使用 SQL 语句操作事务
在 start transaction 和 commit(或 rollback)之间写出此事务的 SQL 语句
start transaction;
-- SQL1
-- SQL2
commit; -- 事务正常提交
-- rollback; -- 我们主动让事务失败
2.3 JDBC 操作事务
在使用 JDBC 时,Connection 下有一个 autocommit 属性,会使事务自动提交,默认情况下,此属性值是 true。
开启状态下,意味着每一条 SQL 都被视为一个独立的事务。我们要想让多条 SQL 在同一个事务中,只需使用 setAutoCommit 方法修改此属性为 false即可。
修改之后不会自动提交,就需要用到 Connection 下的两个方法 —— commit 和 rollback 来手动提交和主动失败。
String sql1 = "";
String sql2 = "";
// 要使用事务,在同一个事务中,操作 sql1 和 sql2,意味着必须在一条 Connection 完成
try (Connection c = DBUtil.connection()) {
c.setAutoCommit(false);
try (PreparedStatement ps = c.prepareStatement(sql1)) {
ps.executeUpdate();
}
try (PreparedStatement ps = c.prepareStatement(sql2)) {
ps.executeUpdate();
}
c.commit();
3. 事务的四个特性:ACID
事务的四大特性中,一致性是最基本的,其他三个特性都是为了维护一致性而生的
3.1 Atomic(原子性)
业务动作对应的 SQL 应该是看作一个整体,不可再分的。
3.1.1 理解原子性
简单来说,就是一个事务中的所有 SQL 要么全部成功,要么全部失败,所有的事务处于一种同生共死的状态。
体现在代码中就是,事务中有两条 SQL ,SQL1 执行通过,但是在执行 SQL2 时出现异常,此时事务就会回滚,两条 SQL 执行结果都被判定为失败。只有两条 SQL 都执行通过,事务才会提交
3.2 Consistency(一致性)
一致性由开发者来保证,针对数据整体做的不可变的承诺。
3.2.1 以银行转账的例子理解一致性
我们去银行从 ATM 中转账的时候一般分为两个步骤:
- 我的银行卡余额减少
- 转账接收方余额增加
如果在第一步完成之后,银行的服务器突然宕机,我的余额减少了,但是转账接收方的余额没有增加,我就会白白损失一笔巨款。在数据库中,这就是所谓的 不一致性
当一致性被维护时,银行的服务器突然宕机,转账这个业务应立即被判断为失败,我的余额也不会减少
3.3 Isolation(隔离性)
当有多个事务同时操作一段数据时,互相之间不会彼此干扰。
以上这句对隔离性的定义其实是比较理想的。事实上,如果要追求真正的隔离性,就要以牺牲并发性为代价的,所以 SQL 标准制定了隔离级别
3.4 Durability(持久性)
持续性也称为永久性,指一个事务一旦提交,它对数据库中数据的改变是永久性的。
4. 隔离级别
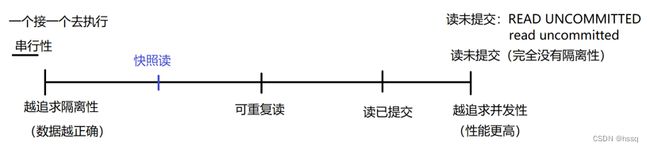
SQL 中的隔离级别分为以下几种:
- serializable(可串行性)
- snapshot read(快照读)
- repeatable read(可重复读)
- read committed(读已提交)
- read uncommited(读未提交)
如下图所示,越往左隔离性越好,越往右并发性越好(性能更高)
4.1 读未提交
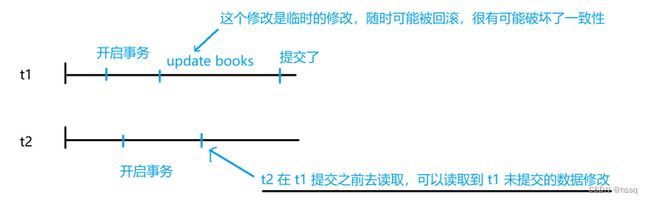
多个同时执行的事务,可以读取到其他事务处于未提交时的数据修改,可以认为完全没有隔离性,在此隔离级别下会产生副作用——脏读、不可重复读、幻读
脏读:读取到了脏数据,读到了其他事务没有提交的数据修改,而这段数据随时很有可能会被回滚,这样就会破坏一致性
4.2 读已提交
读已提交就是可以读取到其他事务已经提交的数据修改。
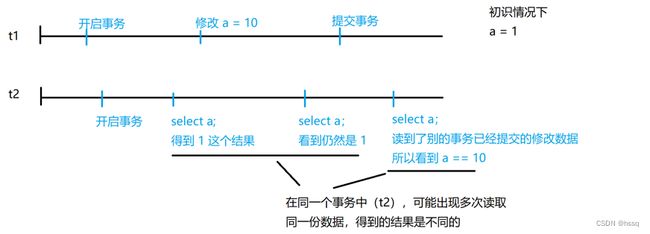
“ 读已提交 ” 隔离级别中避免了脏读,但是不可避免 不可重复读 和 幻读
不可重复读:同一个事务中,可能出现多次读取同一份数据,但结果不同。
4.3 可重复读
保证了在一次事务中(没有提交或者回滚),读取到的同一块数据无论何时的值都一样,即使有别的事务对这块数据进行了修改,也不会有影响
传统意义上的可重复读避免了脏读和不可重复读,但是仍然避免不了幻读

幻读:本事务修改了表中的数据,但是在本事务提交之前表中被另一个事务插入了一条数据并且提交了,这样就会导致本数据会看到一条突然出现的 “ 幽灵般的 ” 数据
出现幻读的原因是:可重复读只针对表中已有的数据做保护,对新添加的数据不做保护

4.4 快照读
快照读其实不是标准中存在的隔离级别,快照读连幻读的副作用都没有,目前来说基本没有副作用
MySQL 中的 “ 可重复读 ” 可以看作实际上的 “ 快照读 ”,MySQL 默认情况下的隔离级别就是可重复读
4.5 可串行化
微观视角下,每个事务必须排好队,一次只执行一条事务,每条事务之间完全隔离;宏观视角下,让然看作 “ 同时进行 ”,但是并发性(性能)差
索引
1. 索引的分类
index:普通索引
unique:唯一索引
fulltext:全文索引
spatial:时空索引
primary:主键
以下全文只针对普通索引
2. 索引的作用
索引的作用是用来提高查询速度
一般来说,在表中查询某条数据时,会把所有的元素遍历一遍,找到符合条件的元素,对表中的某个字段添加索引之后,就像是对这个字段创建了目录,可以大大提高查询速度
3. 创建索引
-- 使用 ALTER TABLE 语句添加索引
ALTER TABLE `table_name` ADD PRIMARY KEY ( `column` )
-- 使用 create 语句添加索引
CREATE INDEX `index_name` on `table_name` (`column_name`)
4. 索引的基本原理
索引的背后可以看作是一颗搜索树,搜索树的 key 是添加过索引的字段,value 可以看作是对应数据在硬盘上的位置(一种可能)
4.1 添加索引之后的查询过程
- 第一步,从搜索树(索引)中,根据添加索引的字段名找到匹配数据的位置
- 第二步,直接根据位置读取数据
相比未添加索引的遍历全表查询,速度会大幅提升
5. 索引的 hit 和 miss
注意,索引只会应用在被添加的字段,其他字段不受影响
一张表中,命中索引被称为 hit,有索引但未命中被称为 miss
6. 索引的优缺点
优点:
- 提升查询速度
缺点:
- 造成空间的使用增加
- 造成修改的性能下降(删、改、增)
添加完索引之后,还得保存索引数据,所以空间的使用就会增加;没有索引时修改数据只需要修改原始数据即可,有了索引之后,除了修改原始数据之外,还得修改索引结构,所以性能会下降
7. 索引的使用场景
- 数据量达到一定规模
- 针对查询很多、修改较少的表考虑索引
- 只针对频繁被查询的字段建立索引
8. 了解 explain 命令
通过 explain 命令可以判断是否命中索引,将 explain 命令加载 select 命令前即可
使用 explain 命令之后会出现如下图字段,比较 rows 字段即可判断是否添加索引,rows 字段是此 select 扫描的行数,一般来说,添加过索引后扫描的行数会非常少(前提数据庞大)
![]()