ubuntu18.04 CUDA10.1 docker中安装caffe-ssd及分类检测数据集训练与测试(一)
ubuntu18.04 CUDA10.1 docker中安装caffe-ssd教程
- 前言
- 一、caffe-ssd是什么?
- 二、使用步骤
-
- 1.总体环境介绍
- 2.创建docker与安装配置
- 3.caffe-ssd环境的搭建
- 总结
前言
在unbutu中配置显卡环境,docker容器的使用,以及搭建caffe-ssd深度学习的环境,最后训练自己的数据得出模型是一件困难的事情。经过一个多星期不断调试环境反复修改,作者本人终于搭建好了容器和caffe-ssd的环境,并成功训练起来了自己的分类数据集,得到了其pth模型,并转为caffe的om模型。
本篇文章主要是介绍caffe-ssd环境的搭建过程
一、caffe-ssd是什么?
ssd算法,其英文全名是Single Shot MultiBox Detector,属于one-stage方法,MultiBox指明了ssd算法是多框预测,是相对于RCNN系列目标检测算法,yolo系列目标检测算法的改进算法,ssd算法在准确度和速度上都比yolo要好很多,对于Faster R-CNN,首先通过CNN得到候选框,然后再进行分类与回归,而yolo与ssd可以一步到位完成检测。
Caffe(全称:Convolutional Architecture for Fast Feature Embedding),是一个计算CNN相关算法的深度学习框架,可以在LINUX下运行。
caffe-ssd则是一套框架+算法集成起来解决CV,NLP方向的解决方案。在计算机视觉领域的分类和检测应用领域广泛。
二、使用步骤
1.总体环境介绍
1)显卡GPU:NVIDIA GTX 1660 6G
2)CUDA:10.1
3) Anaconda3 + python3.6
4) Ubuntu18.04
2.创建docker与安装配置
查看是否存在容器
docker ps -a
 没有的话则创建容器:
没有的话则创建容器:
命令:nvidia-docker run --runtime=nvidia --gpus all -dit --restart=always --privileged -v /tmp/.X11-unix:/tmp/.X11-unix -v /work:/work -p 10086:22 -e DISPLAY=:0 -e LANG=C.UTF-8 --shm-size 16G --name ub18.04-cuda10.1-init -w / 镜像docker 的id /bin/bash
参数解释;
nvidia-docker run #
-dit # 后台运行容器
–restart=always # docker重启时,自动重启
–net=bredge-zwh # 网桥名称
-p 10086:22 # 端口映射
-v /work:/my_work # 目录映射
-v /tmp/.X11-unix:/tmp/.X11-unix # 图形界面信息窗体sockt
–privileged # container内的root拥有真正的root权限
-e DISPLAY=:0 # 图形界面端口
-e LANG=C.UTF-8 # 支持中文环境
–shm-size 16G # 共享内存
–name chipeak-ub18.04-cuda10.1-caffe-zwh # 容器名称
9e47e9dfcb9a # 进行id
/bin/bash # 启动终端
QT_X11_NO_MITSHM=1
-w /home/jello # 指定工作目录
--restart=always docker重启时,自动重启
-e LANG=C.UTF-8 支持中文环境
-p 本机端口——>容器端口映射
-v 挂在宿主文件,到容器。
-name 容器名称
-c 接下来的表示一个字符串
启动创建的docker容器``
docker exec -it docker的名字 /bin/bash
`
3.caffe-ssd环境的搭建
1)Anaconda安装 wget https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/Anaconda3-4.2.0-Linux-x86_64.sh #如果没有,则需要安装wget
bash Anaconda3-4.2.0-Linux-x86_64.sh #安装anaconda,一路yes
2)相关依赖库安装
apt-get update
apt-get install git
apt-get install libprotobuf-dev libleveldb-dev libsnappy-dev libopencv-dev libhdf5-serial-dev protobuf-compiler -y
apt-get install --no-install-recommends libboost-all-dev -y
apt-get install libopenblas-dev liblapack-dev libatlas-base-dev -y
apt-get install libgflags-dev libgoogle-glog-dev liblmdb-dev -y
参考博客:https://blog.csdn.net/tanghong1996/article/details/96307323
3)创建conda环境
conda env list #查看conda环境
conda create -n caffe-py3.6 python=3.6 #创建conda环境
conda activate caffe-py3.6 #激活conda环境
conda install libgcc #安装lib库
conda install protobuf=3.0.0
conda install -c menpo opencv3 numpy #安装opencv3
4)找到cudnn的路径
我的路径如下:/my_software_package/cudnn-10.1-linux-x64-v7.6.5.32
![]() 然后运行下面的命令:
然后运行下面的命令:
cp cuda/include/cudnn.h /usr/local/cuda/include/
cp cuda/lib64/libcudnn* /usr/local/cuda/lib64/
chmod a+r /usr/local/cuda/include/cudnn.h
5)caffe下载与配置
git clone git://github.com/weiliu89/caffe.git
cd caffe #进入caffe路径
git checkout ssd #检测是否存在ssd分支
cd ../
mv caffe caffe-ssd-init
cp -r caffe-ssd-init caffe-ssd-init
cd caffe-sdd
cp Makefile.config.example Makefile.config
下图是我下载的caffe路径
![]() 得到的caffe-ssd的目录结构
得到的caffe-ssd的目录结构
 修改Makefile.config里的配置
修改Makefile.config里的配置
1)查找
USE_CUDNN := 1
USE_OPENCV := 1
OPENCV_VERSION := 3
WITH_PYTHON_LAYER := 1 (这一句大概在94行 自行查找 ctrl+F)
全部取消注释
 2)39-45行修改,删除掉compute_20 21
2)39-45行修改,删除掉compute_20 21
 3)然后修改python目录,因为采用的是anaconda,所以
3)然后修改python目录,因为采用的是anaconda,所以
注释掉原先的python2.7引用目录,修改为anaconda
大概70-87行,这里的usr不修改。
将python2.7注释掉
#PYTHON_INCLUDE := /usr/include/python2.7
/usr/lib/python2.7/dist-packages/numpy/core/include
将
# ANACONDA_HOME := $(HOME)/anaconda2
# PYTHON_INCLUDE := $(ANACONDA_HOME)/include \
$(ANACONDA_HOME)/include/python2.7 \
$(ANACONDA_HOME)/lib/python2.7/site-packages/numpy/core/include \
改为:
ANACONDA_HOME := /my_app/anaconda3/envs/caffe-py3.6
PYTHON_INCLUDE := $(ANACONDA_HOME)/include \
$(ANACONDA_HOME)/include/python3.6m \
$(ANACONDA_HOME)/lib/python3.6/site-packages/numpy/core/include \
将
PYTHON_LIB := /usr/lib
# PYTHON_LIB := $(ANACONDA_HOME)/lib
改为:
#PYTHON_LIB := /usr/lib
PYTHON_LIB := $(ANACONDA_HOME)/lib
将
# PYTHON_LIBRARIES := boost_python3 python3.5m
修改成:
PYTHON_LIBRARIES := boost_python3 python3.6m

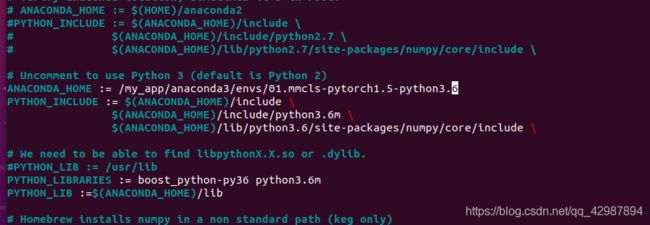 将一图的Anconda路径变为二图的样子,注意是自己的Anconda路径,不然会编译报错。
将一图的Anconda路径变为二图的样子,注意是自己的Anconda路径,不然会编译报错。
4.将INCLUDE_DIRS := $(PYTHON_INCLUDE) /usr/local/include
LIBRARY_DIRS := $(PYTHON_LIB) /usr/local/lib /usr/lib
修改为:
INCLUDE_DIRS := $(PYTHON_INCLUDE) /usr/local/include /usr/include/hdf5/serial
LIBRARY_DIRS := $(PYTHON_LIB) /usr/local/lib /usr/lib /usr/lib/x86_64-linux-gnu /usr/lib/x86_64-linux-gnu/hdf5/serial
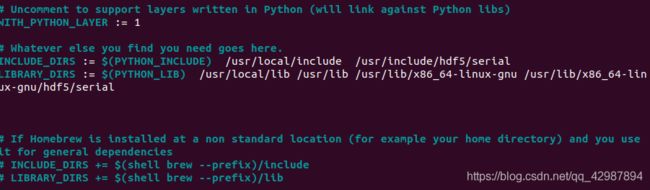 路径根据自己的环境配置来,一定自己查找一下路径是否正确,我在这里走了很多弯路,都是环境路径没有配置好!
路径根据自己的环境配置来,一定自己查找一下路径是否正确,我在这里走了很多弯路,都是环境路径没有配置好!
保存退出修改Makefile中的配置
将下面注释
#NVCCFLAGS +=-ccbin=$(CXX) -Xcompiler-fPIC ( C O M M O N F L A G S ) 添 加 N V C C F L A G S + = − D F O R C E I N L I N E S − c c b i n = (COMMON_FLAGS) 添加 NVCCFLAGS += -D_FORCE_INLINES -ccbin= (COMMONFLAGS)添加NVCCFLAGS+=−DFORCEINLINES−ccbin=(CXX) -Xcompiler -fPIC $(COMMON_FLAGS)
将
LIBRARIES += boost_thread stdc++
更改成
LIBRARIES += boost_thread stdc++ boost_regex
将
LIBRARIES += glog gflags protobuf boost_system boost_filesystem boost_regex m hdf5_hl hdf5
修改为:
LIBRARIES += glog gflags protobuf leveldb snappy
lmdb boost_system boost_filesystem hdf5_hl hdf5 m
opencv_core opencv_highgui opencv_imgproc opencv_imgcodecs opencv_videoio
 这个很重要必须的改一下,要不后面容易报错。退出保存一下就行了。就这样我们全部修改完毕!
这个很重要必须的改一下,要不后面容易报错。退出保存一下就行了。就这样我们全部修改完毕!
make
make all -j12
 遇到这个错误,说明Makefile.config路径没调好,如下图调整自己的Anaconda路径:
遇到这个错误,说明Makefile.config路径没调好,如下图调整自己的Anaconda路径:
 最后结果为如下图说明编译成功
最后结果为如下图说明编译成功
_第11张图片](http://img.e-com-net.com/image/info8/9e2686d06d7b466cb030fe25429a926f.jpg) 上图为正确的测试编译
上图为正确的测试编译
make runtest -j12 #这一步可能会报错,但不会有太大的问题,继续下面的步骤就好了。
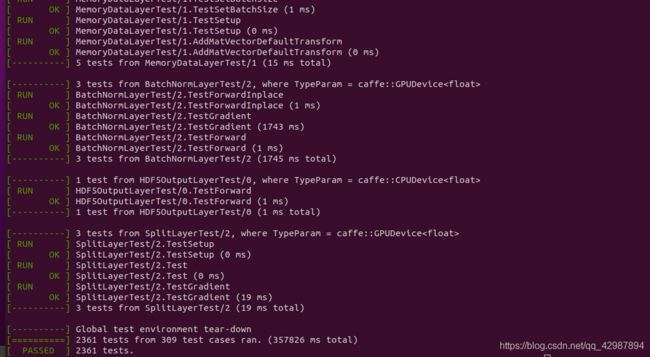 这是运行成功的截图
这是运行成功的截图
make pycaffe
 最后进入到cd caffe/python下进行python #python环境测试
最后进入到cd caffe/python下进行python #python环境测试
 需要导入scikit-image工具包
需要导入scikit-image工具包
pip install scikit-image
 出现上图错误,需要安装protobuf
出现上图错误,需要安装protobuf
pip install protobuf
成功:
python
>>> import caffe as cf
>>> print(cf.__version__)
1.0.0
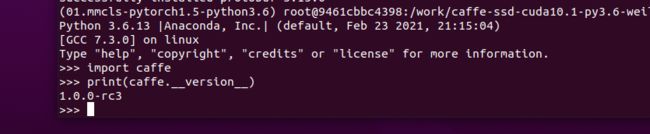 安装成功,到次就可以安安静静的去训练数据跑模型了,哈哈
安装成功,到次就可以安安静静的去训练数据跑模型了,哈哈
总结
花费了一个多星期的时间,终于将代码跑通,下面是我后续跑通的截图,我跑了一个公开数据集ImageNet在加上我自己的数据集。下期我将详细的写怎样处理公开数据集,从训练,测试到模型转换完整流程!
 最后,如果按照教程做起来比较吃力的话,遇见的BUG比较多,留下你们的联系方式,我可以将完全做好caffe-ssd的docker镜像传给你们。哈哈,希望看到有效的话,点个赞收藏一下,这是对我最大的鼓励,谢谢!
最后,如果按照教程做起来比较吃力的话,遇见的BUG比较多,留下你们的联系方式,我可以将完全做好caffe-ssd的docker镜像传给你们。哈哈,希望看到有效的话,点个赞收藏一下,这是对我最大的鼓励,谢谢!