深度学习汇总(一)
文章目录
-
- 目标检测评价指标
-
- 概述
- 特征通道与信息融合
-
- 概述
- 1 × 1 1\times1 1×1卷积及其作用
-
- 概述
- 1 × 1 1\times1 1×1卷积在瓶颈结构中的作用以及 1 × 1 1\times1 1×1卷积在增强网络表达能力中的作用
-
- 概述
- 网络宽度对模型性能的影响
-
- 深度:
- 宽度:
- 多输入网络?什么时候需要多输入?
-
- 概述
- 分组卷积
-
- 概述
- 深度可分离卷积
-
- 概述
- 空间可分离卷积
-
- 概述
- 批量标准化
-
- 概述
- Dropout正则化
-
- 概述
- 随机梯度下降
-
- 概述
- v4解码
-
- 概述
- yolo_training.py文件解读
-
- 概述
- ATSS
- Gan网络如何实现数据增强的?原理是什么?
-
- 概述
目标检测评价指标
概述
参考文章:https://blog.csdn.net/weixin_44878336/article/details/120646078
这是我实验室的同门,在学习上给予了我很大的帮助,该文章一定能解决你的困惑。
特征通道与信息融合
概述
特征通道与信息融合我的理解是特征融合,我相信Resnet论文中提出的残差模块是特征信息融合最好的体现。
就拿残差模块来说,有一条主干路,在这条通路上面,包含卷积、归一化、池化、激活函数等各个处理输入特征信息的模块,而在主干路之外还有一条对输入特征信息进行压缩的卷积模块,该作用仅仅就是为了和主干路的输出特征信息进行融合。因此,两条支路的特征信息融合在一起,就包括了源输入的信息和处理后的深层次信息。这里还要说的就是,在两通路特征信息进行融合之前,主要的融合方式可以概括为:add:特征通道数不变,在原尺寸的基础上特征信息直接叠加;concatenate另一种方法就是原通道信息上的信息不变,进行通道数上的叠加。这只是两种特征信息的融合方式。
“注意力”特征融合:注意力特征融合可以概括为通道注意力特征融合和空间注意力特征融合。
通道注意力模块:
通道注意力是关注什么样的特征是有意义的。对于图像而言,输入是三通道的信息,经过卷积等操作后,输入维度上压缩,而通道数增加,每个通道都有自己信息,而通道注意力模块就是对每个通道进行衡量,分别得到每个通道的重要程度,而这个重要程度可以理解为我们想要的特征信息在每个通道上的多少,特征信息多的通道,会得到一个大的权重,也就是我们更关注这个通道,特征信息少的通道自然得到的权重小,我们的关注程度更低。通道注意力怎么得到每个通道的权重:输入是一个 H × W × C H\times W \times C H×W×C 的特征 F F F(H x W代表像素大小),我们先分别进行一个空间的全局最大池化和平均池化得到两个 1 × 1 × C 1\times 1\times C 1×1×C的通道描述。接着,再将它们分别送入一个多层神经网络,比如两层:第一层神经元个数为 C r \frac{C}{r} rC,激活函数为 R e l u Relu Relu,第二层神经元个数为 C C C。这个两层的神经网络是共享的。然后,再将得到的两个特征相加后经过一个 S i g m o i d Sigmoid Sigmoid激活函数得到权重系数 W i W_i Wi。最后,输入的特征 F F F每个通道就可得到刚刚计算得到的权重,这样每个通道就有了自己的权重,也就是每个通道的特征信息的重要程度得到了划分。通道注意力代表作有:
SENet
我的另一篇文章:https://editor.csdn.net/md/?articleId=120718999
空间注意力模块:
空间注意力类似于通道注意力模块,最终的目的都是针对输入的特征信息的每个通道乘以一个权重,为了就是对后续的处理,模型或者网络更加关注权重系数大的通道,而不在纠结花算力在权重系数(重要程度小的通道上)。
1 × 1 1\times1 1×1卷积及其作用
概述
如果卷积的输出输入都只是一个平面,那么 1 × 1 1\times1 1×1卷积核并没有什么意义,它是完全不考虑像素与周边其他像素关系。但卷积的输出输入是长方体,所以 1 × 1 1\times1 1×1卷积实际上是对每个像素点,在不同的channels上进行线性组合(信息整合),且保留了图片的原有平面结构,调控depth(深度,我认为就是指的通道数吧),从而完成升维或降维的功能。
- 1、降维( dimension reductionality ):比如,一张500 * 500且厚度depth(通道数)为100 的图片在20个filter(卷积核)上做 1 × 1 1\times1 1×1的卷积,那么结果的大小为50050020。
- 2、加入非线性:卷积层之后经过激励层, 1 × 1 1\times1 1×1的卷积在前一层的学习表示上添加了非线性激励( non-linear activation ),提升网络的表达能力。因为 1 × 1 1\times1 1×1卷积核,可以在保持feature map尺度不变的(即不损失分辨率)的前提下大幅增加非线性特性(利用后接的非线性激活函数),把网络做的很深,增加非线性特性。
1 × 1 1\times1 1×1卷积在瓶颈结构中的作用以及 1 × 1 1\times1 1×1卷积在增强网络表达能力中的作用
概述
1 × 1 1\times1 1×1卷积在瓶颈结构中的作用: 1 × 1 1\times1 1×1卷积可以保证和特征图卷积之后不损失分辨率,而且在模块组合中,在 3 × 3 3\times3 3×3卷积之前增加 1 × 1 1\times1 1×1卷积可以减少通道数。但是实验中表明, 1 × 1 1\times1 1×1卷积不适合在特征尺寸很大的时候使用,我认为是在特征尺寸很大的时候,我们的目的就是压缩尺寸,使得到的特征图尺寸更小,具有更大的感受野,也就是充分提取关键信息。而 1 × 1 1\times1 1×1卷积只会压缩通道数或者增加通道数,不会对特征图进行任何的操作。在特征图已经经过很多次卷积,变得很小的时候,使用 1 × 1 1\times1 1×1卷积在扩张或压缩通道数,在进行最后的卷积,可能效果更佳。另外 1 × 1 1\times1 1×1的卷积可以极大地减少参数量,但是也要清楚,参数量的减少不一定会提升模型的运算速度,即使拥有小的参数量,运算速度仍会很慢。
网络宽度对模型性能的影响
深度:
对于深度学习处理图像类的信息而言,网络层数的加深对于网络模型而言,至关重要。相比较提取图像的特征,更深层次的网络,往往能够提取更好的特征信息。如下图所示:



从上图就可以看出,网络的深度对图像提取关键信息,至关重要。如果一味地加深网络的层数,也会带来很多问题。比如:梯度不稳定(网络反向传播),网络退化的问题始终都是存在的,可以缓解,没法消除,这就有可能出现网络加深,性能反而开始下降。
宽度:
参考文章:https://www.zhihu.com/question/291790340/answer/667260880
宽度,即通道(channel)的数量。增加网络的深度就是逐层的抽象,不断精炼提取关键信息。如上图所示:第一层学习到了目标的边缘,第二层学习到了目标简单的形状,第三层开始学习到了目标的形状。通过读文章,有文章指出,增加通道数在一定意义上确实使原有的特征信息更加丰富,但是通道数的增加对于计算量而言使倍数增加的,也有作者实验验证了,再同时增加深度和宽度的基础上,确实可以取得更优的性能,也就是说我们不知道深度增加到多少宽度增加到多少,模型可以取得最佳的性能,所以只能相对而言。另外宽度相对于深度而言,对GPU的利用更优,GPU的并行计算,更加容易训练模型。
**总结:**模型增加宽度非常关键。比如DenseNet中的密集连接,充分利用了每个通道信息。总结的来说就是充分利用通道数,在一个模块的输出,以concat的连接方式融合上一层的输出,完美的结合了原有的特征信息,而且也在此基础上增加了更加丰富的特征信息。何乐而不为~
多输入网络?什么时候需要多输入?
概述
这个问题是我在一本付费的电子书上面看到的章节题目,因为付费不能看到他的答案,但是自己又对这个问题感兴趣,所以拿出来分享一下,我也是查阅网上的相关资料,基本都是针对神经网络多输入和多输出或者多输入和单输出类似的回答和博客。总的回想一下,多输入这个问题其实我们早就遇到了,对于神经网络入门的房价预测,对于最终的房价,影响因素不单单只有房屋的面积,还有楼层,地段等等因素,这个就是多因素影响最终房价的自变量,如果根据这些影响因素建立与房价的回归网络,就是一个多输入单输出的问题了,所以在很多问题上面都有体现。这就是我理解的多输入问题,至于什么时候选择或者需要多输入,那一定是单一的自变量不足以满足最终的结果,也就是最终的结果不是单一的输入是可以决定的,此时,我们引入其他的影响因素,来共同决定输出。我认为不管是多对单,还是多对多的形式,一切都是按着你的需求,解决问题的需求来决定。(个人理解)
分组卷积
概述
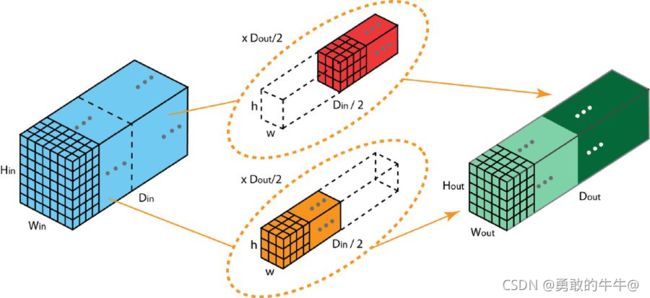
常规卷积:
如果输入feature map尺寸为 C ∗ H ∗ W C∗H∗W C∗H∗W,卷积核有N个,输出feature map的通道数与卷积核的数量相同也是N。
分组卷积:
上图展示了具有两个过滤器分组的分组卷积。在每个过滤器分组中,每个过滤器的深度仅有名义上的 2 D 2D 2D卷积的一半。它们的深度是 D o u t 2 \frac{Dout}{2} 2Dout。每个过滤器分组包含 D o u t 2 \frac{Dout}{2} 2Dout个过滤器。第一个过滤器分组(红色)与输入层的前一半 ( [ : , : , 0 : D i n / 2 ] ) ([:, :, 0:Din/2]) ([:,:,0:Din/2])卷积,而第二个过滤器分组(橙色)与输入层的后一半 ( [ : , : , D i n / 2 : D i n ] ) ([:, :, Din/2:Din]) ([:,:,Din/2:Din])卷积。因此,每个过滤器分组都会创建 D o u t 2 \frac{Dout}{2} 2Dout个通道。整体而言,两个分组会创建2× D o u t 2 \frac{Dout}{2} 2Dout=Dout 个通道。然后我们将这些通道堆叠在一起,得到有 Dout 个通道的输出层。
分组卷积的优点:
在非常深的神经网络中,分组卷积非常重要。会使模型更加高效,模型参数会随过滤器分组数的增大而减小。
深度可分离卷积
概述
参考:https://zhuanlan.zhihu.com/p/257145620
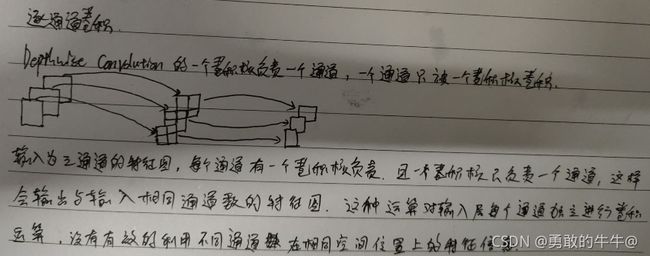
个人理解:深度可分离卷积可以理解为将普通的卷积分为两步来计算,第一步为逐通道卷积,第二步为逐点卷积。
逐通道卷积:假如输入为三通道的特征图,逐通道卷积就是设置和通道数相同的卷积核,与输入特征进行卷积,得到的是通道数一样,尺寸改变的特征信息。这样的卷积运算仅仅是对每个通道的特征进行卷积,并没有有效利用不同通道在空间位置的信息。所以特征图经过逐通道卷积后,得到的特征图进行逐点卷积。配合图来理解:
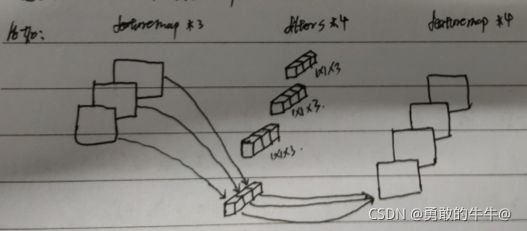
逐点卷积:对逐通道卷积后的特征图进行 1 × 1 1\times1 1×1卷积,卷积核个数由上一层的通道数决定,经过 1 × 1 1\times1 1×1卷积后,各层的特征图就利用在一起,起到了和普通卷积的效果。配合图来理解:
空间可分离卷积
概述
参考文章:https://zhuanlan.zhihu.com/p/257145620
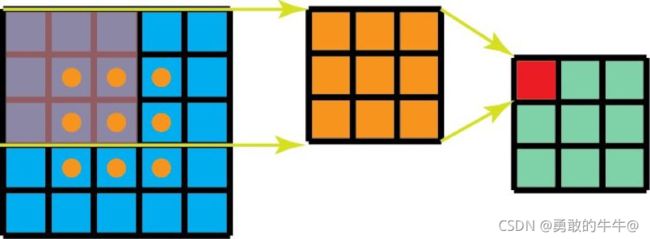
首先从普通的2D卷积来看(先不考虑通道数),如下图所示,输入是特征图维度为 5 ∗ 5 5*5 5∗5,卷积核为: 3 ∗ 3 3*3 3∗3,步长为1,填充为0,特征图经过卷积后的输出为 3 ∗ 3 3*3 3∗3大小。
空间分离卷积就是对卷积核进行矩阵行和列的矩阵分解,比如下面公式所示:
[ 2 4 1 2 ] = [ 2 1 ] × [ 2 1 ] \left[\begin{matrix}2 & 4 \cr 1 & 2\end{matrix}\right] =\left[\begin{array}{ccc}2\\\\1\\\\\end{array}\right] \times \left[\begin{array}{ccc} 2 & 1 \end{array}\right] [2142]=⎣ ⎡21⎦ ⎤×[21]
从公式上理解就是把上图中的 3 × 3 3\times3 3×3卷积分解为 3 × 1 3\times1 3×1和 1 × 3 1\times3 1×3的两个卷积,前后分别对输入特征图进行卷积处理。具体如下图所示:
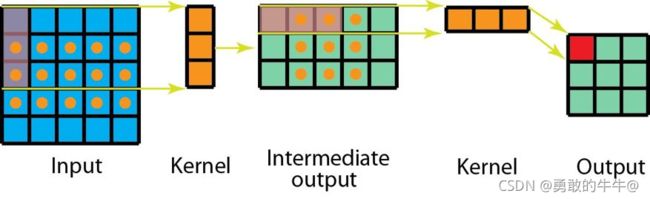
最终都可以得到 3 × 3 3\times3 3×3的特征图,只不过是把卷积核给分开,然后卷积核分开对输入的特征进行处理,空间分离卷积确实在卷积操作中减少了参数量,但深度学习却很少使用它。一大主要原因是并非所有的核都能分成两个更小的核。如果我们用空间可分卷积替代所有的传统卷积,那么我们就限制了自己在训练过程中搜索所有可能的核。这样得到的训练结果可能是次优的。
批量标准化
概述
参考文章:
https://zhuanlan.zhihu.com/p/93643523
https://zhuanlan.zhihu.com/p/24810318
批量标准化(Batch Normalization)
Batch normalization 的 batch 是批数据, 把数据分成小批进行随机梯度下降, 而且在每批数据进行前向传播的时候, 对每一层都进行 normalization (标准化或者归一化)的处理。BN通常被加在卷积池化后激活函数的前面,其作用可以加快模型训练时的收敛速度,使得模型训练过程更加稳定,避免梯度爆炸或者梯度消失。在残差结构的模块中,通常都是 卷积+BN+激活 的结构。下图是有或者没有BN层,使用 tanh 激活函数以后, 输出值得分布情况。

Batch Normalization核心公式:
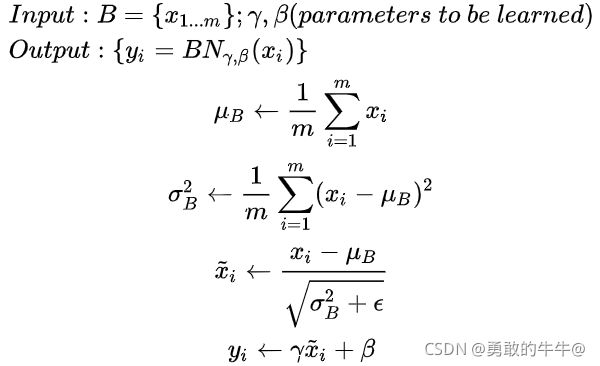
式中:
- 输入为数值集合(B),可训练参数 γ \gamma γ, β \beta β
- BN的具体操作为:先计算 B B B的均值和方差,之后将 B B B集合的均值、方差变换为0、1(对应上式中 x ~ i \widetilde{x}_i x i),最后将 B B B中每个元素乘以 γ \gamma γ 再加 β \beta β ,输出。 γ \gamma γ和 β \beta β是可训练参数
- 归一化的目的:将数据规整到统一区间,减少数据的发散程度,降低网络的学习难度。 B N BN BN的精髓在于归一之后,使用 γ \gamma γ和 β \beta β作为还原参数,在一定程度上保留原数据的分布
举个具体的例子来说明均值和方差相对于BN而言,到底意味着什么
比如一个批次的图片数据来说为: N × H × W × C N\times H\times W\times C N×H×W×C,其中N为该批次内的图片数量,H为图片特征的高,W为图片特征的宽,C为该批次内特征的通道数,假设该批次内有4张图片,每张图片的通道数为3,分别为RGB,那么BN中计算该批次数据的均值就是:以通道数为基准,R通道的均值为图像像素总和除以 N ( 4 ) × H × W N(4)\times H\times W N(4)×H×W。B通道和G通道以此类推。 γ \gamma γ和 β \beta β(可训练参数)的维度等于张量的通道数。
Dropout正则化
概述
参考文章:https://zhuanlan.zhihu.com/p/390990848
对于神经网络来说,当数据集过小或者过于简单,当你在一个复杂的模型训练时,就会出现过拟合的情况。Dropout的提出作为训练神经网络的一种trick选择。在每个训练批次中,通过忽略一半的特征检测器(让一半的隐层节点值为0),可以明显地减少过拟合现象,通俗的来说,就是在某一层神经元使用Dropout,该层的神经元会随机丢弃一些神经元参与训练,因为在该层你丢弃了一部分神经元,所以在下一层也只有一部分神经元参与训练,在一定程度上可以防止模型过拟合,增加模型的泛化性。如下图所示:
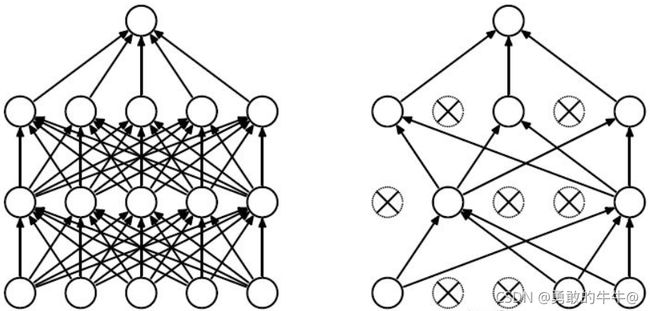
起初我是只知道我们在做检测或者分类任务时,Dropout作为提高模型能力的一种方式,可能大多数的人只知道我们加入该trick,模型会随机丢弃掉我们设置比率的神经元,需要注意的是,假如有十个神经元,我们设置丢弃率为 p = 0.3 p=0.3 p=0.3,最后保留参与训练的神经元个数为7个,我们还需要对剩余的7个神经元进行缩放,也就是乘以 1 1 − p \frac{1}{1-p} 1−p1,如果在训练的时候没有对剩余神经元进行缩放,那么在测试的时候,就要对权重进行缩放。
疑惑:对于CNN来说,其中应用的Dropout是对于神经元的随机丢弃还是对输入特征图的随机丢弃还有待研究
随机梯度下降
概述
比较推荐李沐博主提出的:用梯度下降来优化人生~~连接:https://zhuanlan.zhihu.com/p/414009313
非常有感触的一句话送给大家,像我一样在迷途中的人:所谓成熟,就是习惯任何人的忽冷忽热,看淡任何人的渐行渐远;用绝对清醒的理智;压制不该有的情绪
v4解码
概述
在代码中就是首先生成特征层大小的网格,然后将我们预先设置好了的在原图中416416先验框的尺寸调整到有效特征层大小上,最后从v4的网络预测结果获得先验框的中心调整参数 x o f f s e t x_offset xoffset和 y o f f s e t y_offset yoffset和宽高的调整参数h和w,对在特征层尺寸大小上的先验框进行调整,将每个网格点加上它对应的x_offset和y_offset的结果就是调整后的先验框的中心,也就是预测框的中心,然后再利用先验框和h、w结合 计算出调整后的先验框的的长和宽,也就是预测框的高和宽,这样就能得到在特征层上得到整个预测框的位置了,最后我们将在有效特征层上的预测框的位置再调整到原图416416的大小上。有待确认此时在原图上就可以得到三个有效特征层的所有先验框,总数为 13 ∗ 13 ∗ 3 + 26 ∗ 26 ∗ 3 + 52 ∗ 52 ∗ 3 13*13*3 + 26*26*3 + 52*52*3 13∗13∗3+26∗26∗3+52∗52∗3个框框,—>,我们就可以获得预测框在原图上的位置,当然得到最终的预测结果后还要进行得分排序与非极大抑制筛选,由于一个网格点有3个先验框,则调整后有3个预测框,在原图上绘制的时候,同一个目标就有3个预测框,那要找出最合适的预测框,我们需要进行筛选。如下图举例:假设3个蓝色的是我们获得的预测框,黄色的是真实框,红色的是用与预测目标的网格,我们就需要对这检测同一个目标的网格点上的3个调整后的先验框(也就是预测框)进行筛选。

yolo_training.py文件解读
概述
- 1.计算loss所需参数
在计算loss的时候,实际上是网络预测结果prediction和目标target之间的对比。 - 2.prediction是什么
对于v4的模型来说,网络最后输出的内容就是三个有效特征层,3个有效特征层的每个网格点(特征点)对应着预测框及其种类,即三个特征层分别对应着图片被分为不同size的网格后,每个网格点上三个先验框对应的位置、置信度及其种类。
输出层的shape分别为 ( 13 , 13 , 75 ) , ( 26 , 26 , 75 ) , ( 52 , 52 , 75 ) (13,13,75),(26,26,75),(52,52,75) (13,13,75),(26,26,75),(52,52,75),最后一个维度为75是因为是基于voc数据集的,它的类为20种,每一个特征层的每一个特征点(网格点)都预先设置3个先验框,每个先验框包含 1 + 4 + 20 1+4+20 1+4+20个参数信息,1代表这个先验框内部是否有目标,4代表框的中心点坐标(x,y)和框的宽高(h,w)参数信息,20代表框的种类信息,所以每一个特征点对应3*25参数, 即最后维度为3x25。如果使用的是coco训练集,类则为80种,最后的维度应该为255 = 3x85,三个特征层的shape为(13,13,255),(26,26,255),(52,52,255)
**注意:**此处得到的网络预测结果(3个有效特征层)y_prediction此时并没有解码,也就是yolov4.py文件中YoLoBody类的输出结果,有效特征层解码了之后才是真实图像上的情况。 - 3.target是什么
t a r g e t target target就是你制作的训练集中标注图片中的数据信息,这是网络的真实框情况。就是一个真实图像中,真实框的情况。第一个维度是batch_size,第二个维度是每一张图片里面真实框的数量,第三个维度内部是真实框的信息,包括位置以及种类。 - 4.loss的计算过程
拿到 p r e d pred pred和 t a r g e t target target后,不可以简单的减一下作为对比,需要进行如下步骤。
–> 第一步:对yolov3网络的预测结果进行解码,获得网络预测结果对先验框的调整数据
–> 第二步:对真实框进行处理,获得网络应该真正有的对先验框的调整数据,也就是网络真正应该有的预测结果 ,然后和我们得到的网络的预测结果进行对比,代码中 g e t t a r g e t get_target gettarget函数
-----> 判断真实框在图片中的位置,判断其属于哪一个网格点去检测。
-----> 判断真实框和哪个预先设定的先验框重合程度最高。
-----> 计算该网格点应该有怎么样的预测结果才能获得真实框(利用真实框的数据去调整预先设定好了的先验框,得到真实框该网格点应该预测的先验框的调整数据)
-----> 对所有真实框进行如上处理。
-----> 获得网络应该有的预测结果,将其与v4预测实际的预测结果对比。
–> 第三步: 将真实框内部没有目标对应的网络的预测结果,且重合程度较大的先验框进行忽略,因为图片的真实框中没有目标,也就是这个框的内部没有对象,框的位置信息是没有用的,网络输出的这个先验框的信息和其代表的种类是没有意义的,这样的得到调整的先验框应该被忽略掉,网络只输出框内部有目标的数据信息,代码中get_ignore函数。
–> 第四步:利用真实框得到网络真正的调整数据和网络预测的调整数据后,我们就对其进行对比loss计算。
这里需要注意的是:上述处理过程依次对3个有效特征才层进行计算的,因为网络是分3个有效特征层进行预测的,计算3个有效特征层的loss的值相加之后就是我们模型最终的loss值,就可以进行反向传播和梯度下降了。
ATSS
笔记:基于锚点和无锚点检测的本质区别在于如何定义正训练样本和负训练样本,从而导致了两者之间的性能差异。如何选择正负训练样本是当前目标检测器的重要问题,自适应训练样本选择—>根据目标的统计特征自动选择正样本和负样本。
Gan网络如何实现数据增强的?原理是什么?
概述
模型通过框架中至少两个模块:生成模型(Generative Model)和判别模型(Discriminative Model)的互相博弈学习中产生更好的输出。
机器学习的模型大体可以分为两类,生成模型和判别模型。判别模型需要输入变量,通过某种模型来预测,生成模型是给定某种隐含信息,来随机产生观测数据。
- 判别模型:给定一张图,判断这张图里的动物是猫还是狗
- 生成模型:给一系列猫的图片,生成一张新的猫咪
Gan的基本原理很简单:这里以生成图片为例进行说明,假设我们有两个网络,分别为G和D,G是一个生成图片的网络,他接收一个随机的噪声Z,通过这个噪声生成图片,记作 G ( Z ) G(Z) G(Z)。D是一个判别网络,判断一张图片是不是真实图片,他的输入参数是X,X代表一张图片,输出D(X),D(X)代表X为真实图片的概率,如果为1,就代表是真实的图片,如果输出为0,则代表不可能是真实图片。
在训练的过程中,生成网络G的目标就是根据输入的图片尽量生成真实的图片去欺骗判别网络D,而D的目标就是尽量把G生成的图片和真实的图片分别开来。这样,G和D就形成了动态的“博弈过程”。如下图所示:
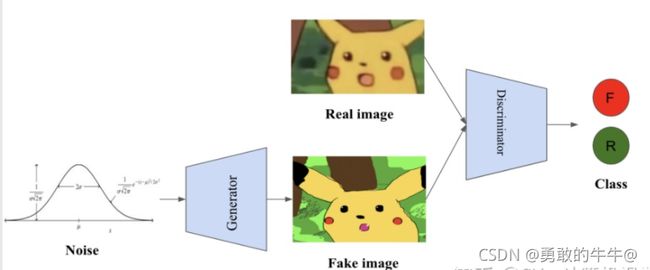
Gan网络用生成的图像来做数据增强--------->
-------->疑问?通过上面的理解,判别网络用于判别生成网络的内容是否真实,而对于Gan网络的应用来说,是怎么做到数据增强功能的?
这个问题仍然不是很明白——待解决
(注:参考的都是性价比很高的文章,已给出参考地址,不是原创,但是在此基础上加了很多自己的理解,不断更新中 …ing)