BERT 预训练学习(数据:样本构建、输入格式;算法:transformer、mlm和nsp任务)
任务:MLM完形填空、下一句预测
数据:构建样本数据及label,输入格式
参考:
1)**https://github.com/DA-southampton/TRM_tutorial/tree/main/BERT%E4%BB%A3%E7%A0%81%E4%BB%8E%E9%9B%B6%E8%A7%A3%E8%AF%BB
2)
**https://github.com/bojone/bert4keras/tree/master/pretraining
3)**https://zhuanlan.zhihu.com/p/419171690
4)https://github.com/MorvanZhou/NLP-Tutorials/blob/master/BERT.py
另外也可以参考transformers库的预训练代码:
5)https://github.com/huggingface/transformers/tree/master/examples/pytorch/language-modeling
1)代码案例学习
import math
import re
from random import *
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
# sample IsNext and NotNext to be same in small batch size
def make_batch():
batch = []
positive = negative = 0 ## 为了记录NSP任务中的正样本和负样本的个数,比例最好是在一个batch中接近1:1
while positive != batch_size/2 or negative != batch_size/2:
tokens_a_index, tokens_b_index= randrange(len(sentences)), randrange(len(sentences)) # 比如tokens_a_index=3,tokens_b_index=1;从整个样本中抽取对应的样本;
tokens_a, tokens_b= token_list[tokens_a_index], token_list[tokens_b_index]## 根据索引获取对应样本:tokens_a=[5, 23, 26, 20, 9, 13, 18] tokens_b=[27, 11, 23, 8, 17, 28, 12, 22, 16, 25]
input_ids = [word_dict['[CLS]']] + tokens_a + [word_dict['[SEP]']] + tokens_b + [word_dict['[SEP]']] ## 加上特殊符号,CLS符号是1,sep符号是2:[1, 5, 23, 26, 20, 9, 13, 18, 2, 27, 11, 23, 8, 17, 28, 12, 22, 16, 25, 2]
segment_ids = [0] * (1 + len(tokens_a) + 1) + [1] * (len(tokens_b) + 1)##分割句子符号:[0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
# MASK LM
n_pred = min(max_pred, max(1, int(round(len(input_ids) * 0.15)))) # n_pred=3;整个句子的15%的字符可以被mask掉,这里取和max_pred中的最小值,确保每次计算损失的时候没有那么多字符以及信息充足,有15%做控制就够了;其实可以不用加这个,单个句子少了,就要加上足够的训练样本
cand_maked_pos = [i for i, token in enumerate(input_ids)
if token != word_dict['[CLS]'] and token != word_dict['[SEP]']] ## cand_maked_pos=[1, 2, 3, 4, 5, 6, 7, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18];整个句子input_ids中可以被mask的符号必须是非cls和sep符号的,要不然没意义
shuffle(cand_maked_pos)## 打乱顺序:cand_maked_pos=[6, 5, 17, 3, 1, 13, 16, 10, 12, 2, 9, 7, 11, 18, 4, 14, 15] 其实取mask对应的位置有很多方法,这里只是一种使用shuffle的方式
masked_tokens, masked_pos = [], []
for pos in cand_maked_pos[:n_pred]:## 取其中的三个;masked_pos=[6, 5, 17] 注意这里对应的是position信息;masked_tokens=[13, 9, 16] 注意这里是被mask的元素之前对应的原始单字数字;
masked_pos.append(pos)
masked_tokens.append(input_ids[pos])
if random() < 0.8: # 80%
input_ids[pos] = word_dict['[MASK]'] # make mask
elif random() < 0.5: # 10%
index = randint(0, vocab_size - 1) # random index in vocabulary
input_ids[pos] = word_dict[number_dict[index]] # replace
# Zero Paddings
n_pad = maxlen - len(input_ids)##maxlen=30;n_pad=10
input_ids.extend([0] * n_pad)#在input_ids后面补零
segment_ids.extend([0] * n_pad)# 在segment_ids 后面补零;这里有一个问题,0和之前的重了,这里主要是为了区分不同的句子,所以无所谓啊;他其实是另一种维度的位置信息;
# Zero Padding (100% - 15%) tokens 是为了计算一个batch中句子的mlm损失的时候可以组成一个有效矩阵放进去;不然第一个句子预测5个字符,第二句子预测7个字符,第三个句子预测8个字符,组不成一个有效的矩阵;
## 这里非常重要,为什么是对masked_tokens是补零,而不是补其他的字符????我补1可不可以??
if max_pred > n_pred:
n_pad = max_pred - n_pred
masked_tokens.extend([0] * n_pad)## masked_tokens= [13, 9, 16, 0, 0] masked_tokens 对应的是被mask的元素的原始真实标签是啥,也就是groundtruth
masked_pos.extend([0] * n_pad)## masked_pos= [6, 5, 17,0,0] masked_pos是记录哪些位置被mask了
if tokens_a_index + 1 == tokens_b_index and positive < batch_size/2:
batch.append([input_ids, segment_ids, masked_tokens, masked_pos, True]) # IsNext
positive += 1
elif tokens_a_index + 1 != tokens_b_index and negative < batch_size/2:
batch.append([input_ids, segment_ids, masked_tokens, masked_pos, False]) # NotNext
negative += 1
return batch
# Proprecessing Finished
def get_attn_pad_mask(seq_q, seq_k):
batch_size, len_q = seq_q.size()
batch_size, len_k = seq_k.size()
# eq(zero) is PAD token
pad_attn_mask = seq_k.data.eq(0).unsqueeze(1) # batch_size x 1 x len_k(=len_q), one is masking
return pad_attn_mask.expand(batch_size, len_q, len_k) # batch_size x len_q x len_k
def gelu(x):
"Implementation of the gelu activation function by Hugging Face"
return x * 0.5 * (1.0 + torch.erf(x / math.sqrt(2.0)))
class Embedding(nn.Module):
def __init__(self):
super(Embedding, self).__init__()
self.tok_embed = nn.Embedding(vocab_size, d_model) # token embedding
self.pos_embed = nn.Embedding(maxlen, d_model) # position embedding
self.seg_embed = nn.Embedding(n_segments, d_model) # segment(token type) embedding
self.norm = nn.LayerNorm(d_model)
def forward(self, x, seg):
seq_len = x.size(1)
pos = torch.arange(seq_len, dtype=torch.long)
pos = pos.unsqueeze(0).expand_as(x) # (seq_len,) -> (batch_size, seq_len)
embedding = self.tok_embed(x) + self.pos_embed(pos) + self.seg_embed(seg)
return self.norm(embedding)
class ScaledDotProductAttention(nn.Module):
def __init__(self):
super(ScaledDotProductAttention, self).__init__()
def forward(self, Q, K, V, attn_mask):
scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(d_k) # scores : [batch_size x n_heads x len_q(=len_k) x len_k(=len_q)]
scores.masked_fill_(attn_mask, -1e9) # Fills elements of self tensor with value where mask is one.
attn = nn.Softmax(dim=-1)(scores)
context = torch.matmul(attn, V)
return context, attn
class MultiHeadAttention(nn.Module):
def __init__(self):
super(MultiHeadAttention, self).__init__()
self.W_Q = nn.Linear(d_model, d_k * n_heads)
self.W_K = nn.Linear(d_model, d_k * n_heads)
self.W_V = nn.Linear(d_model, d_v * n_heads)
def forward(self, Q, K, V, attn_mask):
# q: [batch_size x len_q x d_model], k: [batch_size x len_k x d_model], v: [batch_size x len_k x d_model]
residual, batch_size = Q, Q.size(0)
# (B, S, D) -proj-> (B, S, D) -split-> (B, S, H, W) -trans-> (B, H, S, W)
q_s = self.W_Q(Q).view(batch_size, -1, n_heads, d_k).transpose(1,2) # q_s: [batch_size x n_heads x len_q x d_k]
k_s = self.W_K(K).view(batch_size, -1, n_heads, d_k).transpose(1,2) # k_s: [batch_size x n_heads x len_k x d_k]
v_s = self.W_V(V).view(batch_size, -1, n_heads, d_v).transpose(1,2) # v_s: [batch_size x n_heads x len_k x d_v]
attn_mask = attn_mask.unsqueeze(1).repeat(1, n_heads, 1, 1) # attn_mask : [batch_size x n_heads x len_q x len_k]
# context: [batch_size x n_heads x len_q x d_v], attn: [batch_size x n_heads x len_q(=len_k) x len_k(=len_q)]
context, attn = ScaledDotProductAttention()(q_s, k_s, v_s, attn_mask)
context = context.transpose(1, 2).contiguous().view(batch_size, -1, n_heads * d_v) # context: [batch_size x len_q x n_heads * d_v]
output = nn.Linear(n_heads * d_v, d_model)(context)
return nn.LayerNorm(d_model)(output + residual), attn # output: [batch_size x len_q x d_model]
class PoswiseFeedForwardNet(nn.Module):
def __init__(self):
super(PoswiseFeedForwardNet, self).__init__()
self.fc1 = nn.Linear(d_model, d_ff)
self.fc2 = nn.Linear(d_ff, d_model)
def forward(self, x):
# (batch_size, len_seq, d_model) -> (batch_size, len_seq, d_ff) -> (batch_size, len_seq, d_model)
return self.fc2(gelu(self.fc1(x)))
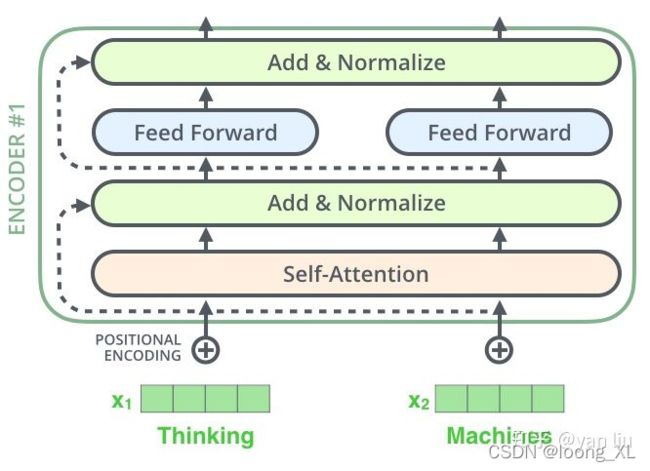
class EncoderLayer(nn.Module):
def __init__(self):
super(EncoderLayer, self).__init__()
self.enc_self_attn = MultiHeadAttention()
self.pos_ffn = PoswiseFeedForwardNet()
def forward(self, enc_inputs, enc_self_attn_mask):
enc_outputs, attn = self.enc_self_attn(enc_inputs, enc_inputs, enc_inputs, enc_self_attn_mask) # enc_inputs to same Q,K,V
enc_outputs = self.pos_ffn(enc_outputs) # enc_outputs: [batch_size x len_q x d_model]
return enc_outputs, attn
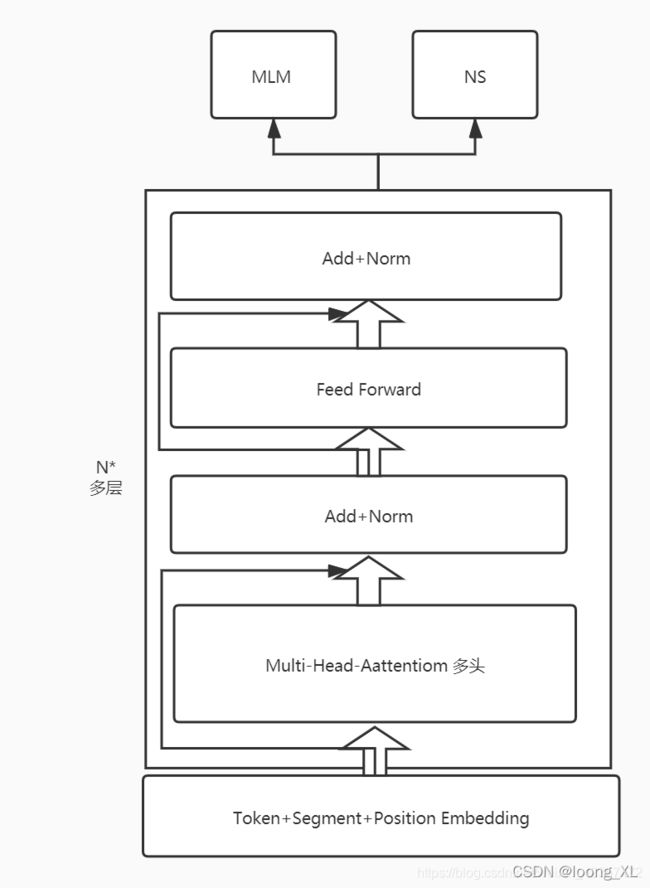
## 1. BERT模型整体架构
class BERT(nn.Module):
def __init__(self):
super(BERT, self).__init__()
self.embedding = Embedding() ## 词向量层,构建词表矩阵
self.layers = nn.ModuleList([EncoderLayer() for _ in range(n_layers)]) ## 把N个encoder堆叠起来,具体encoder实现一会看
self.fc = nn.Linear(d_model, d_model) ## 前馈神经网络-cls
self.activ1 = nn.Tanh() ## 激活函数-cls
self.linear = nn.Linear(d_model, d_model)#-mlm
self.activ2 = gelu ## 激活函数--mlm
self.norm = nn.LayerNorm(d_model)
self.classifier = nn.Linear(d_model, 2)## cls 这是一个分类层,维度是从d_model到2,对应我们架构图中就是这种:
# decoder is shared with embedding layer
embed_weight = self.embedding.tok_embed.weight
n_vocab, n_dim = embed_weight.size()
self.decoder = nn.Linear(n_dim, n_vocab, bias=False)
self.decoder.weight = embed_weight
self.decoder_bias = nn.Parameter(torch.zeros(n_vocab))
def forward(self, input_ids, segment_ids, masked_pos):
output = self.embedding(input_ids, segment_ids)## 生成input_ids对应的embdding;和segment_ids对应的embedding
enc_self_attn_mask = get_attn_pad_mask(input_ids, input_ids)
for layer in self.layers:
output, enc_self_attn = layer(output, enc_self_attn_mask)
# output : [batch_size, len, d_model], attn : [batch_size, n_heads, d_mode, d_model]
# it will be decided by first token(CLS)
h_pooled = self.activ1(self.fc(output[:, 0])) # [batch_size, d_model]
logits_clsf = self.classifier(h_pooled) # [batch_size, 2]
masked_pos = masked_pos[:, :, None].expand(-1, -1, output.size(-1)) # [batch_size, max_pred, d_model] 其中一个 masked_pos= [6, 5, 17,0,0]
# get masked position from final output of transformer.
h_masked = torch.gather(output, 1, masked_pos) # masking position [batch_size, max_pred, d_model]
h_masked = self.norm(self.activ2(self.linear(h_masked)))
logits_lm = self.decoder(h_masked) + self.decoder_bias # [batch_size, max_pred, n_vocab]
return logits_lm, logits_clsf
if __name__ == '__main__':
# BERT Parameters
maxlen = 30 # 句子的最大长度 cover住95% 不要看平均数 或者99% 直接取最大可以吗?当然也可以,看你自己
batch_size = 6 # 每一组有多少个句子一起送进去模型
max_pred = 5 # max tokens of prediction
n_layers = 6 # number of Encoder of Encoder Layer
n_heads = 12 # number of heads in Multi-Head Attention
d_model = 768 # Embedding Size
d_ff = 3072 # 4*d_model, FeedForward dimension
d_k = d_v = 64 # dimension of K(=Q), V
n_segments = 2
text = (
'Hello, how are you? I am Romeo.\n'
'Hello, Romeo My name is Juliet. Nice to meet you.\n'
'Nice meet you too. How are you today?\n'
'Great. My baseball team won the competition.\n'
'Oh Congratulations, Juliet\n'
'Thanks you Romeo'
)
sentences = re.sub("[.,!?\\-]", '', text.lower()).split('\n') # filter '.', ',', '?', '!'
word_list = list(set(" ".join(sentences).split()))
word_dict = {'[PAD]': 0, '[CLS]': 1, '[SEP]': 2, '[MASK]': 3}
for i, w in enumerate(word_list):
word_dict[w] = i + 4
number_dict = {i: w for i, w in enumerate(word_dict)}
vocab_size = len(word_dict)
token_list = list()
for sentence in sentences:
arr = [word_dict[s] for s in sentence.split()]
token_list.append(arr)
batch = make_batch()
input_ids, segment_ids, masked_tokens, masked_pos, isNext = map(torch.LongTensor, zip(*batch))
model = BERT()
criterion = nn.CrossEntropyLoss(ignore_index=0)
optimizer = optim.Adam(model.parameters(), lr=0.001)
for epoch in range(100):
optimizer.zero_grad()
logits_lm, logits_clsf = model(input_ids, segment_ids, masked_pos)## logits_lm 【6,5,29】 bs*max_pred*voca logits_clsf:[6*2]
loss_lm = criterion(logits_lm.transpose(1, 2), masked_tokens) # for masked LM ;masked_tokens [6,5]
loss_lm = (loss_lm.float()).mean()
loss_clsf = criterion(logits_clsf, isNext) # for sentence classification
loss = loss_lm + loss_clsf
if (epoch + 1) % 10 == 0:
print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.6f}'.format(loss))
loss.backward()
optimizer.step()
## save model
torch.save(model, "./train_model1.pkl")
# Predict mask tokens ans isNext
input_ids, segment_ids, masked_tokens, masked_pos, isNext = map(torch.LongTensor, zip(batch[0]))
print(text)
print([number_dict[w.item()] for w in input_ids[0] if number_dict[w.item()] != '[PAD]'])
logits_lm, logits_clsf = model(input_ids, segment_ids, masked_pos)
logits_lm = logits_lm.data.max(2)[1][0].data.numpy()
print('masked tokens list : ',[pos.item() for pos in masked_tokens[0] if pos.item() != 0])
print('predict masked tokens list : ',[pos for pos in logits_lm if pos != 0])
logits_clsf = logits_clsf.data.max(1)[1].data.numpy()[0]
print('isNext : ', True if isNext else False)
print('predict isNext : ',True if logits_clsf else False)
2)、3)代码案例学习
用bert4keras预训练:
参考:https://github.com/bojone/bert4keras/tree/master/pretraining
https://zhuanlan.zhihu.com/p/419171690用里面的数据做的样本和生成vocab.txt
all_data_url =r"D:\预训练\medical_all_data.txt"
base_path_data = open(all_data_url,encoding="utf-8").readlines()
all_word = []
print(len(base_path_data))
kk=["[PAD]","[UNK]","[CLS]","[SEP]","[MASK]","",""]
for one_data in base_path_data:
for one_word in one_data:
all_word.append(one_word)
all_word = list(set(all_word))
print(len(all_word))
all_word = kk + all_word
open("D:\预训练\medical_vocab.txt", "w",encoding="utf-8").write("\n".join(all_word))
2)用bert4keras的pretraining模块中的data_utils.py去生成模型需要的tfrecord格式
if __name__ == '__main__':
from bert4keras.tokenizers import Tokenizer
import json, glob, re
from tqdm import tqdm
model = 'roberta'
sequence_length = 512
workers = 40
max_queue_size = 4000
# dict_path = '/home/spaces_ac_cn/chinese_L-12_H-768_A-12/vocab.txt'
dict_path = r'D:\预训练\medical_vocab.txt'
tokenizer = Tokenizer(dict_path, do_lower_case=True)
# def some_texts():
# filenames = glob.glob('/home/spaces_ac_cn/corpus/*/*/*')
# np.random.shuffle(filenames)
# count, texts = 0, []
# for filename in filenames:
# with open(filename) as f:
# for l in f:
# l = json.loads(l)['text'].strip()
# texts.extend(re.findall(u'.*?[\n。]+', l))
# count += 1
# if count == 10: # 10篇文章合在一起再处理
# yield texts
# count, texts = 0, []
# if texts:
# yield texts
def some_texts():
# filenames = glob.glob('/home/spaces_ac_cn/corpus/*/*/*')
filename = r'D:\预训练\medical_all_data.txt'
# np.random.shuffle(filenames)
count, texts = 0, []
# for filename in filenames:
base_path_data = open(filename,encoding="utf-8").readlines()
for l in base_path_data:
texts.extend(re.findall(u'.*?[\n。]+', l.strip()))
count += 1
if count == 10: # 10篇文章合在一起再处理
yield texts
count, texts = 0, []
if texts:
yield texts
assert model in ['roberta', 'gpt', 'unilm'] # 判断是否支持的模型类型
if model == 'roberta':
# import jieba_fast as jieba
import jieba
jieba.initialize()
def word_segment(text):
return jieba.lcut(text)
TD = TrainingDatasetRoBERTa(
tokenizer, word_segment, sequence_length=sequence_length
)
for i in range(10): # 数据重复10遍
TD.process(
corpus=tqdm(some_texts()),
record_name=r'D:\预训练\corpus_tfrecord\corpus.%s.tfrecord' % i,
workers=workers,
max_queue_size=max_queue_size,
)
elif model == 'gpt':
TD = TrainingDatasetGPT(tokenizer, sequence_length=sequence_length)
TD.process(
corpus=tqdm(some_texts()),
record_name='../corpus_tfrecord/corpus.tfrecord',
workers=workers,
max_queue_size=max_queue_size,
)
elif model == 'unilm':
TD = TrainingDatasetUniLM(tokenizer, sequence_length=sequence_length)
TD.process(
corpus=tqdm(some_texts()),
record_name='../corpus_tfrecord/corpus.tfrecord',
workers=workers,
max_queue_size=max_queue_size,
)
3)用bert4keras的pretraining模块中的pretraining.py去训练生成bert模型
基本改下配置就行,batch改小,特别注意bert_config.json里的词表大小要改成自己生成的词表size
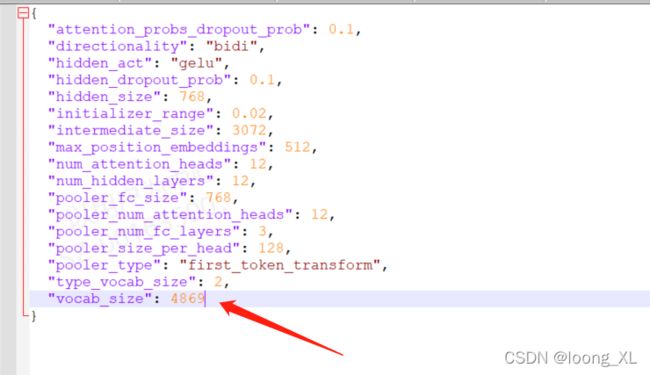
model = 'roberta'
# 语料路径和模型保存路径
# 如果是TPU训练,那么语料必须存放在Google Cloud Storage上面,
# 路径必须以gs://开头;如果是GPU训练,改为普通路径即可。
model_saved_path = r'D:\预训练\bert_model.ckpt'
corpus_paths = [
r'D:\预训练\corpus_tfrecord\corpus.0.tfrecord'
]
# 其他配置
sequence_length = 512
batch_size = 50
config_path = r'D:\预训练\roberta_zh_l12\bert_config.json'
checkpoint_path = None # 如果从零训练,就设为None
learning_rate = 0.00176
weight_decay_rate = 0.01
num_warmup_steps = 3125
num_train_steps = 125000
steps_per_epoch = 1000
grad_accum_steps = 16 # 大于1即表明使用梯度累积
epochs =2
#epochs = num_train_steps * grad_accum_steps // steps_per_epoch
exclude_from_weight_decay = ['Norm', 'bias']
exclude_from_layer_adaptation = ['Norm', 'bias']
tpu_address = None # 如果用多GPU跑,直接设为None
which_optimizer = 'lamb' # adam 或 lamb,均自带weight decay
lr_schedule = {
num_warmup_steps * grad_accum_steps: 1.0,
num_train_steps * grad_accum_steps: 0.0,
}
floatx = K.floatx()
预训练保存的模型还需要一次转化,直接加载会报错Key bert/embeddings/word_embeddings not found in checkpoint
参考:https://blog.csdn.net/weixin_43935696/article/details/119863654
https://blog.csdn.net/weixin_42357472/article/details/110841357
**** 把 bert, train_model, loss = build_transformer_model_with_mlm() 创建得到的bert传递出来;然后注释train_model.fit,train_model.load_weights(model_saved_path)
bert.save_weights_as_checkpoint(filename=r"D:\预训练\bert_model\bert_model.ckpt")
def build_transformer_model_for_pretraining():
"""构建训练模型,通用于TPU/GPU
注意全程要用keras标准的层写法,一些比较灵活的“移花接木”式的
写法可能会在TPU上训练失败。此外,要注意的是TPU并非支持所有
tensorflow算子,尤其不支持动态(变长)算子,因此编写相应运算
时要格外留意。
"""
if model == 'roberta':
bert, train_model, loss = build_transformer_model_with_mlm()
elif model == 'gpt':
bert, train_model, loss = build_transformer_model_with_lm()
elif model == 'unilm':
bert, train_model, loss = build_transformer_model_with_unilm()
# 优化器
optimizer = extend_with_weight_decay(Adam)
if which_optimizer == 'lamb':
optimizer = extend_with_layer_adaptation(optimizer)
optimizer = extend_with_piecewise_linear_lr(optimizer)
optimizer_params = {
'learning_rate': learning_rate,
'lr_schedule': lr_schedule,
'weight_decay_rate': weight_decay_rate,
'exclude_from_weight_decay': exclude_from_weight_decay,
'exclude_from_layer_adaptation': exclude_from_layer_adaptation,
'bias_correction': False,
}
if grad_accum_steps > 1:
optimizer = extend_with_gradient_accumulation(optimizer)
optimizer_params['grad_accum_steps'] = grad_accum_steps
optimizer = optimizer(**optimizer_params)
# 模型定型
train_model.compile(loss=loss, optimizer=optimizer)
# 如果传入权重,则加载。注:须在此处加载,才保证不报错。
if checkpoint_path is not None:
bert.load_weights_from_checkpoint(checkpoint_path)
return bert,train_model
with strategy.scope():
bert,train_model = build_transformer_model_for_pretraining()
train_model.summary()
# 模型训练
# train_model.fit(
# dataset,
# steps_per_epoch=steps_per_epoch,
# epochs=epochs,
# callbacks=[checkpoint, csv_logger],
# )
train_model.load_weights(model_saved_path)
bert.save_weights_as_checkpoint(filename=r"D:\预训练\bert_model\bert_model.ckpt")
加载训练的模型使用
from bert4keras.models import build_transformer_model
from bert4keras.tokenizers import Tokenizer
import numpy as np
config_path = r'D:\预训练\roberta_zh_l12\bert_config.json'
checkpoint_path = r'D:\预训练\bert_model\bert_model.ckpt'
dict_path = r'D:\预训练\medical_vocab.txt'
tokenizer = Tokenizer(dict_path, do_lower_case=True) # 建立分词器
model = build_transformer_model(config_path, checkpoint_path) # 建立模型,加载权重
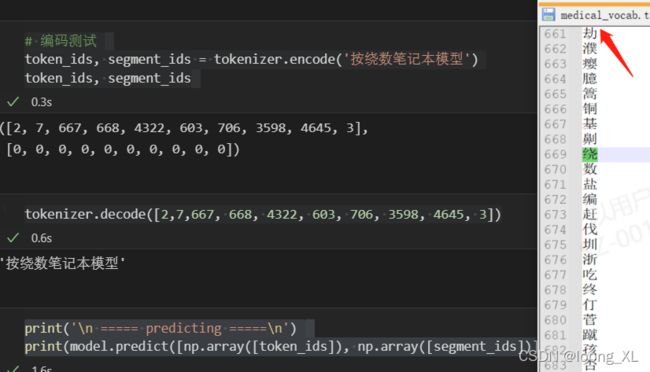
# 编码测试
token_ids, segment_ids = tokenizer.encode('按绕数笔记本模型')
token_ids, segment_ids
tokenizer.decode([2,7,667, 668, 4322, 603, 706, 3598, 4645, 3])
print('\n ===== predicting =====\n')
print(model.predict([np.array([token_ids]), np.array([segment_ids])]))