【学习笔记】语义分割综述
语义分割就是图像分割,是图像像素级的分类,即给图像的每一个像素点分类。与之临近的一个概念叫实例分割,实例分割就是语义分割+目标检测。语义分割只能分割出所有同类的像素,目标检测把不同的个体分开就行了,如Mask RCNN。
评价指标
在了解评价指标之前,先来看一下混淆矩阵。混淆矩阵来源于分类评价指标,表示的是A类别是否正确分类为A类别。
比如我们一个模型对15个样本进行预测,然后结果如下。
真实值:0 1 1 0 1 1 0 0 1 0 1 0 1 0 0
预测值:1 1 1 1 1 0 0 0 0 0 1 1 1 0 1
混淆矩阵是

很明显,有了混淆矩阵后就可以很方便的计算准确率,召回率、F1 score等指标了。
1. Pixel Accuracy(像素准确率)
像素准确率是图像分割最简单的指标,就是正确分类的像素数量除以总像素数量,也就是混淆矩阵对角线的和除以矩阵的总和。即:
![]()
2. IOU(Intersection Over Union)
顾名思义,IOU就是交并比,Ground Truth与Prediction区域的交并比。
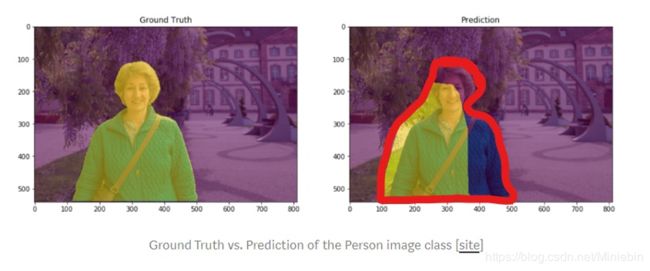
假如人的像素类别为1, 背景的像素类别为0。对应到混淆矩阵上,对于类别1来说,交集就是对角线元素,并集为真实标签为1的像素和+所有预测为1的像素和-交集。即
![]()
3. mIOU(mean IOU)
顾名思义,mIOU就是对所有类别的IOU求均值了。
4. Dice Score(F1 Score)
![]()
网络模型介绍
- FCN
- UNet
- SegNet
- Deeplab(V1 V2)
- RefineNet
- PSPNet
- Deeplab v3
- EncNet
- ......
1. FCN
https://arxiv.org/abs/1411.4038 (2014年)
FCN是深度学习应用在图像分割的开篇之作,奠定了语义分割的原理基础。
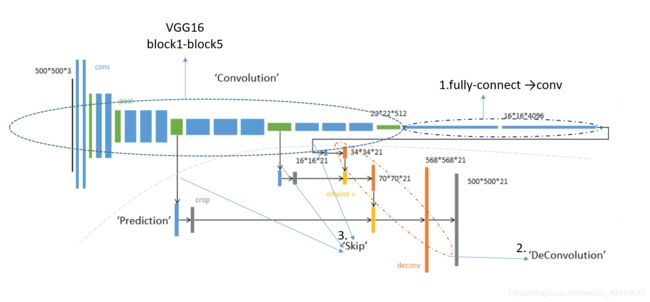
- Fully Convolution :全链接层转换为卷积层。VGG得到的特征图通过上采样恢复尺寸
- Transpose Convolution: 上采样的方式,类似于卷积的逆过程,但不是真正的逆,只是形式尺寸上恢复了尺寸,转置卷积的参数通过学习获得。
- Skip Architecture: 用于融合相同尺度下,卷积层和转置卷积层的feature map, 提高分割的精细程度。
2. UNet
https://arxiv.org/abs/1505.04597v1 (2015)
UNet的设计就是应用与医学图像的分割。由于医学影像处理中,数据量较少,本文提出的方法有效提升了使用少量数据集训练检测的效果,提出了处理大尺寸图像的有效方法。
UNet的网络架构继承自FCN,并在此基础上做了些改变。提出了Encoder-Decoder概念,实际上就是FCN那个先卷积再上采样的思想。

- U形结构:完全对称。
- Skip Architecture
- Transpose Convolution
3. SegNet
https://arxiv.org/abs/1511.00561 (2015)
SegNet继承自FCN,在FCN基础上做了些改变,网络在内存上更小。
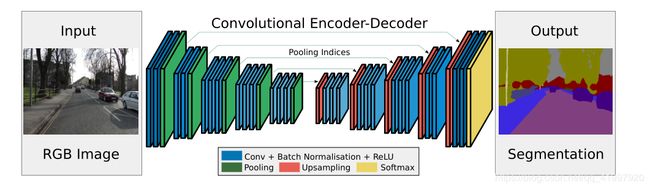
- Encoder-Decoder概念:提出编码器-解码器概念,编码就是卷积过程,解码就是上采样过程。
- Skip Architecture: 使用contact的方式融合链接。
- Maxpooling-INdices: 又叫Unpooling(反池化),就是把Encoder里池化时的索引存储下来,在Decoder上采样时,按照索引放大尺寸,其他部分填充0,再用conv操作(same conv)填充下稀疏矩阵,平滑下feature map。如下图所示:
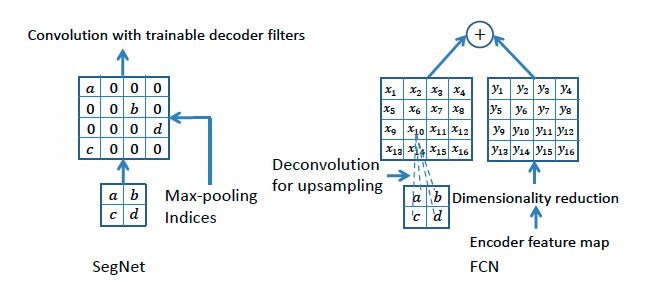
从Maxpooling-Indices结构中可以看出,SegNet是具有更少的参数的,所以速度相对较快,但Maxpooling-Indices跟插值之类的算法一样,是不需要学习的参数的,所以没有Transpose Convolution精度高,所以SegNet的效果并不如FCN8s吧。
4. Deeplab
Deeplab v1: https://arxiv.org/abs/1412.7062 (2014)
Deeplab v2: https://arxiv.org/abs/1606.00915 (2016)
在介绍Deeplab前,先要介绍下空洞卷积(Dilated Convolution)和条件随机场CRF。
空洞卷积就是在卷积核中间填充0,或者在输入map上等间隔采样,其计算方式与标准卷积相同。
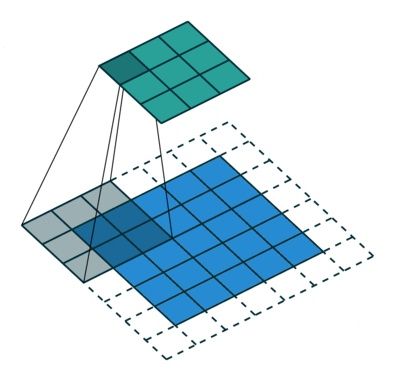
标准卷积
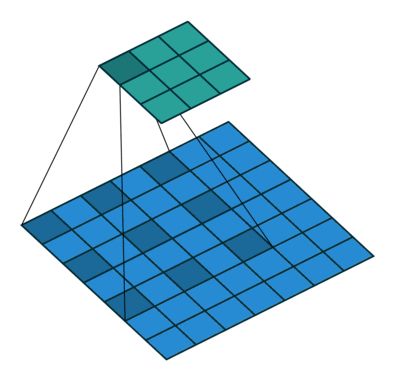
空洞卷积
上图所示即为标准卷积和空洞卷积。那为什么要使用空洞卷积呢?
论文中的说法是,FCN是用传统的CNN那样对图像先卷积再池化,降低图像尺寸同时增大感受野,在上采样扩大图像尺寸。但在减小增大尺寸的过程中,肯定有一些信息丢失了,造成了分割效果粗糙。而dilated conv就是能够不通过池化也能获得较大的感受野的操作。同时,dilated conv通过设置不同的holes,还能得到类似于不同尺度下的特征。(这些理论的东西看看就罢,大部分经验的东西,看似找了个合理的说法而已,但黑匣子还是黑匣子,这种说法很难在深度学习上推而广之)
条件随机场
DeepLab:深度卷积网络,多孔卷积 和全连接条件随机场 的图像语义分割 Semantic Image Segmentation with Deep Convolutional Nets, Atro_Taylor Guo-CSDN博客_基于条件随机场的图像语义分割
整体来说,Deeplab做了两件事情:
- 去掉了最后两个Pooling层,改用Dilated Convolution来扩大感受野,避免池化带来的信息损失。
- 对于模型得到的heatmap, 考虑到图像中分割边缘的先验知识,如梯度变化,颜色等,使用条件随机场CRF精修heatmap, 进一步优化分割精度。
5. RefineNet
RefineNet: https://arxiv.org/pdf/1611.06612.pdf (2016)
UNet的变种,使用Encoder-Decoder结构。其中Encoder使用ResNet101, Decoder使用RefineNet结构。
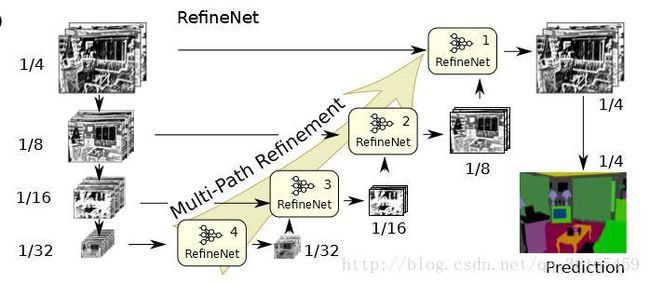
上图是网络的整体架构。RefineNet block 的作用就是把不同分辨率的特征图进行融合。最左边一栏使用的是ResNet,先把pretrained ResNet 按特征图的分辨率分成四个ResNet blocks,然后向右把四个blocks 分别作为4 个path 通过RefineNet block 进行融合,最后得到一个refined feature map(接softmax 层,再双线性插值输出)。除了RefineNet-4,所有的RefineNet block 都是二输入的,用于融合不同level 做refine,而单输入的RefineNet-4 可以看作是先对ResNet 的一个task adaptation。

上图是refineNet的结构细节。具体如下:
- RCU:是从残差网络中提取出来的单元结构
- Multi-resolution fusion:是先对多输入的特征图都用一个卷积层进行自适应(都化到最小的特征图的尺寸大小),再上采样,最后做element-wise 的相加。如果是像RefineNet-4 的单输入block 这一部分就不用了。
- Chained residual pooling:卷积层作为之后加权求和的权重,relu 对接下来池化的有效性很重要,而且使得模型对学习率的变化没这么敏感。这个链式结构能从很大范围区域上获取背景context。另外,这个结构中大量使用了identity mapping 这样的连接,无论长距离或者短距离的,这样的结构允许梯度从一个block 直接向其他任一block 传播
- Output convolutions:输出前再加一个RCU。
6. PSPNet
[论文笔记] PSPNet:Pyramid Scene Parsing Network - 知乎
7. Deeplab V3
.....