大数据实训项目
文章目录
- 一、项目概况
-
- 1、项目介绍
- 2、项目要求
- 3、爬取字段
- 4、数据存储
- 5、数据分析、转化、演示
- 二、环境配置
-
- 1、JDK
- 2、Hadoop集群
- 3、zookeeper
- 4、hive
- 5、sqoop
- 6、flume
- 三、爬取数据
-
- 1、创建项目
- 2、编写主程序进行数据爬取
- 3、编写pipelines,进行数据保存
- 4、编写settings,进行相关配置
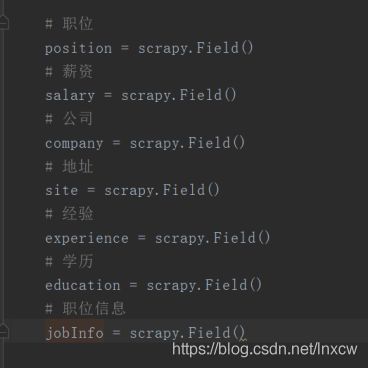
- 5、编写items,进行字典定义
- 6、爬取数据
- 四、数据分析
-
- 1、Flume收集日志
- 2、数据存储到hdfs
- 3、数据分析
- 4、sqoop数据转存
- 项目源码:
一、项目概况
1、项目介绍
利用python编写爬虫程序,从招聘网站上爬取数据,将数据存入到MongoDB数据库中,将存入的数据作一定的数据清洗后做数据分析,最后将分析的结果做数据可视化。
2、项目要求
1、具体要求:招聘网站上的数据,选择两个招聘网站。招聘网站包括:智联招聘、前程无忧、应届生求职、拉勾、中华英才网。
2、评分标准:选取网站总分5分,若只选取一个网站爬取数据得3分。
3、爬取字段
1)、具体要求:职位名称、薪资水平、招聘单位、工作地点、工作经验、学历要求、工作内容(岗位职责)、任职要求(技能要求)。
2)、评分标准:
(1)搭建爬虫框架并运行:5分;
(2)选择合适格式保存数据:5分;
(3)爬取部分字段:5分;
(4)爬取全部字段:10分。
4、数据存储
1)、具体要求:将爬取的数据存储到hdfs上。利用flume收集日志。若整个过程利用mangdb转hdfs则为15分。
2)、评分标准:
(1)正确搭建hadoop平台:10分;
(2)正确选择flume协议传输形式:10分,若部分正确则5分;
(3)能将数据存储到hdfs:10分。
5、数据分析、转化、演示
具体要求(要求:1、利用hive进行分析,2、将hive分析结果利用sqoop技术存储到mysql数据库中,并最后显示分析结果。):
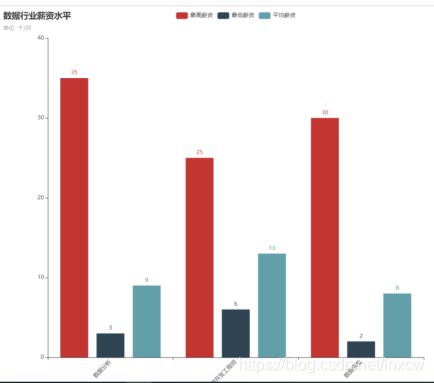
(1)分析“数据分析”、“大数据开发工程师”、“数据采集”等岗位的平均工资、最高工资、最低工资,并作条形图将结果展示出来;
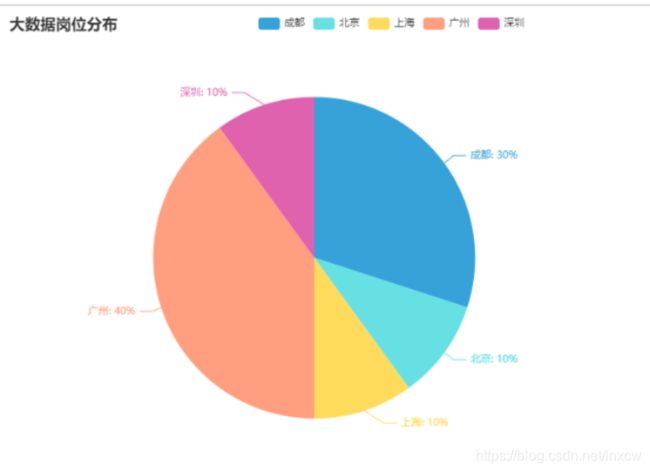
(2)分析“数据分析”、“大数据开发工程师”、“数据采集”等大数据相关岗位在成都、北京、上海、广州、深圳的岗位数,并做饼图将结果展示出来。
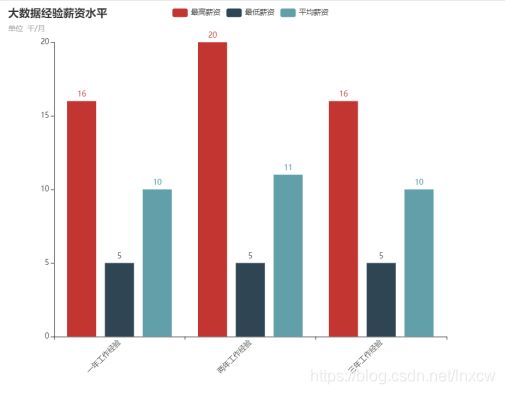
(3)分析大数据相关岗位1-3年工作经验的薪资水平(平均工资、最高工资、最低工资),并做出条形图展示出来;
(4)分析大数据相关岗位几年需求的走向趋势,并做出折线图展示出来。
二、环境配置
1、JDK
https://blog.csdn.net/lnxcw/article/details/106336186
2、Hadoop集群
https://blog.csdn.net/lnxcw/article/details/106337928
3、zookeeper
https://blog.csdn.net/lnxcw/article/details/106801692
4、hive
https://blog.csdn.net/lnxcw/article/details/106445419
5、sqoop
https://blog.csdn.net/lnxcw/article/details/106537791
6、flume
https://blog.csdn.net/lnxcw/article/details/106540916
三、爬取数据
1、创建项目
scrapy startproject job02
cd job02
scrapy genspider chinahr chinahr.com
2、编写主程序进行数据爬取
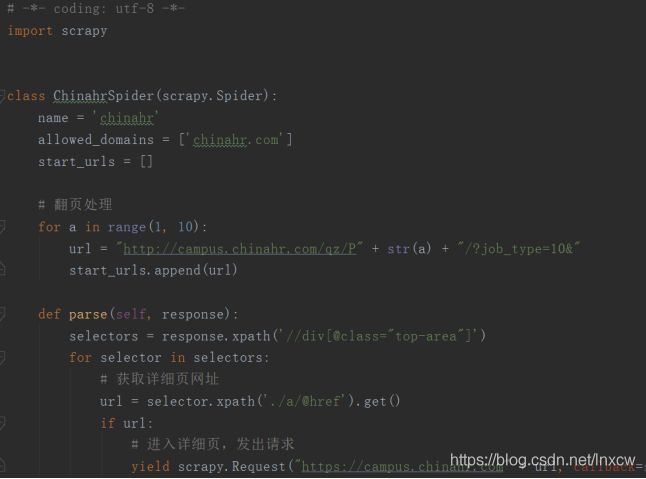
3、编写pipelines,进行数据保存
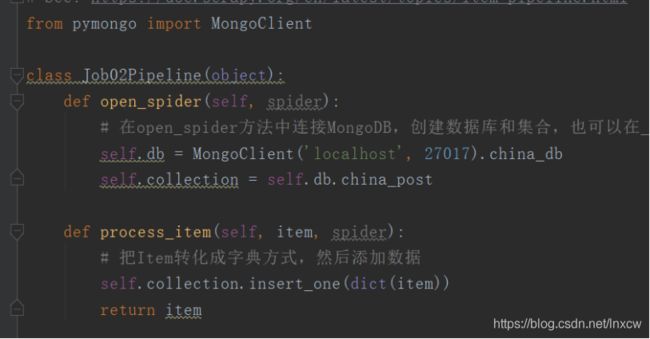
4、编写settings,进行相关配置
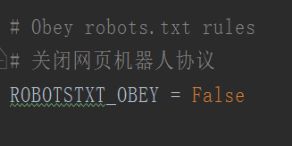
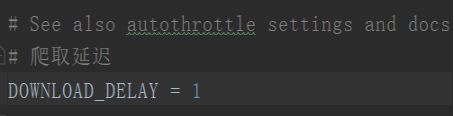
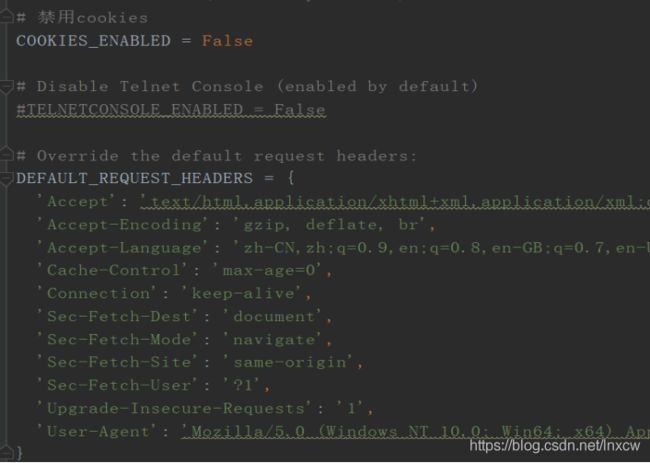
5、编写items,进行字典定义
6、爬取数据
数据量:389000
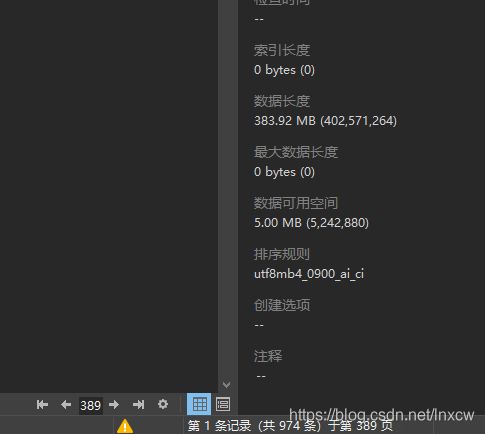
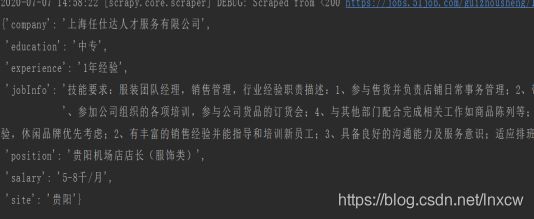
四、数据分析
1、Flume收集日志
编写conf文件,监听文件目录,并将监听数据存储到hdfs
我这里监听的目录是/opt/data
在目录有文件时,flume将监听到的数据上传到/Hadoop/flume里面,并自动创建了一个日期和时间的目录存放日志
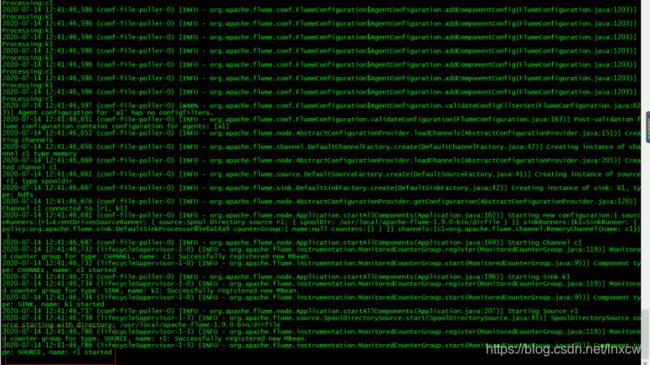
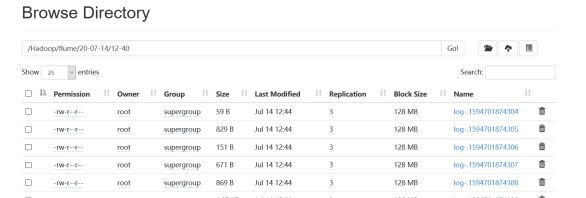
2、数据存储到hdfs
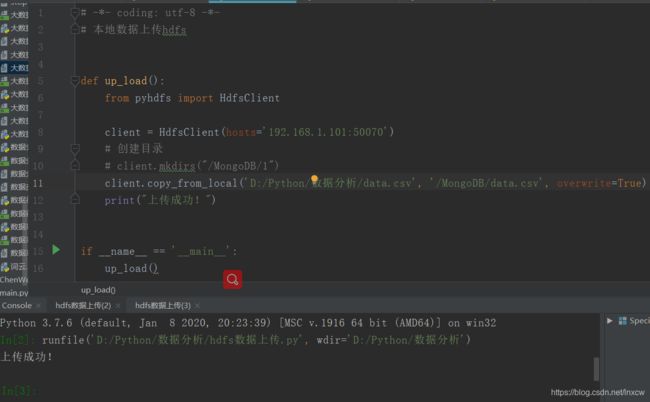
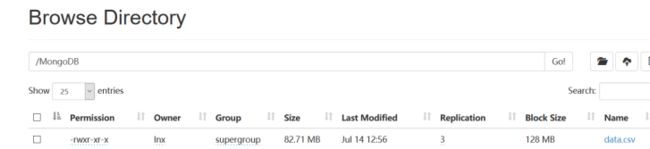
3、数据分析
(1)、hive表创建
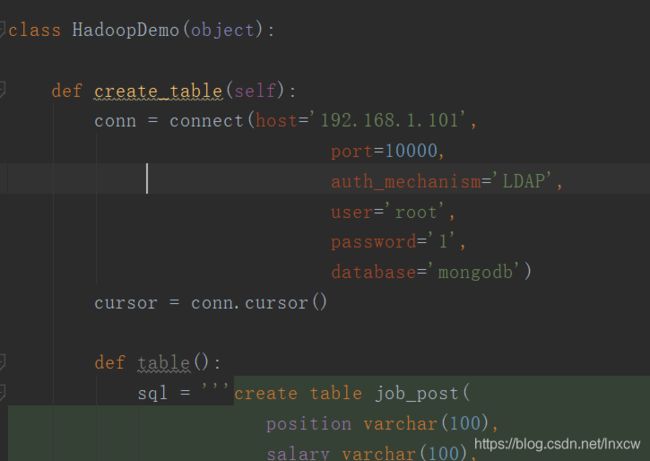
create table job_post(
position varchar(100),
salary varchar(100),
company varchar(100),
site varchar(100),
experience varchar(100),
education varchar(100),
jobInfo varchar(1000) )
row format delimited fields terminated by ','
tblproperties("skip.header.line.count"="1");
create table table1(
position varchar(100),
max_list varchar(100),
avg_list varchar(100),
min_list varchar(100))
row format delimited fields terminated by ',';
create table table2(
site varchar(100),
number varchar(100))
row format delimited fields terminated by ',';
create table table3(
experience varchar(100),
max_list varchar(100),
avg_list varchar(100),
min_list varchar(100))
row format delimited fields terminated by ',';
create table table4(
data varchar(100),
number varchar(100))
row format delimited fields terminated by ',' ;
create table ex(
position string,
day string)
row format delimited fields terminated by ',';
数据导入:
load data local inpath "/opt/data/data.csv" overwrite into table job_post;
load data local inpath "/opt/data/数据岗位薪资水平.txt" overwrite into table table1;
load data local inpath "/opt/data/数据分析岗位分布.txt" overwrite into table table2;
load data local inpath "/opt/data/大数据经验薪资水平.txt" overwrite into table table3;
load data local inpath "/opt/data/大数据相关岗位需求.txt" overwrite into table table4;
load data local inpath "/opt/data/data1.csv" overwrite into table ex;
(2)、mysql表创建
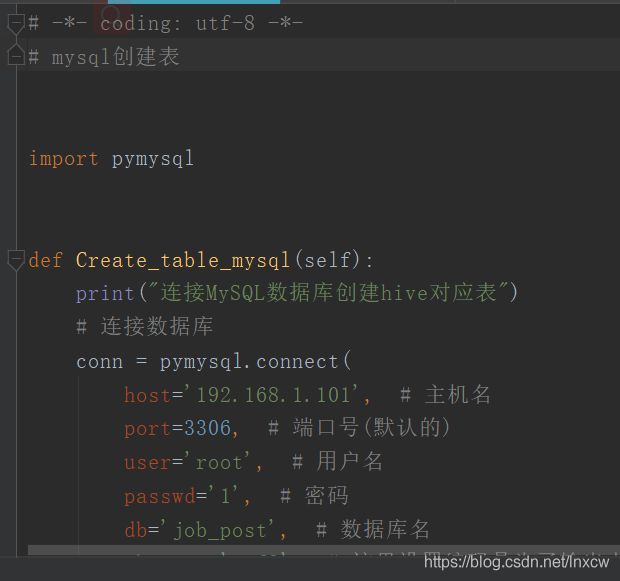
# -*- coding: utf-8 -*-
# mysql创建表
import pymysql
def Create_table_mysql(self):
print("连接MySQL数据库创建hive对应表")
# 连接数据库
conn = pymysql.connect(
host='192.168.1.101', # 主机名
port=3306, # 端口号(默认的)
user='root', # 用户名
passwd='1', # 密码
db='job_post', # 数据库名
charset='utf8', # 这里设置编码是为了输出中文
)
cursor = conn.cursor()
def table1():
sql1 = '''create table table1(
position varchar(100),
max_list varchar(100),
avg_list varchar(100),
min_list varchar(100))'''
cursor.execute(sql1)
print("表1创建成功!")
def table2():
sql2 = '''create table table2(
site varchar(100),
number varchar(100))'''
cursor.execute(sql2)
print("表2创建成功!")
def table3():
sql3 = '''create table table3(
experience varchar(100),
max_pay_level varchar(100),
average_pay_level varchar(100),
min_pay_level varchar(100))'''
cursor.execute(sql3)
print("表3创建成功!")
def table4():
sql4 = '''create table table4(
data varchar(100),
number varchar(100))'''
cursor.execute(sql4)
print("表4创建成功!")
# commit 修改
table1()
table2()
table3()
table4()
conn.commit()
# 关闭游标
cursor.close()
print("创建成功!")
(3)、数据行业薪资
连接数据库,将所需数据查询出来存放到列表,并对数据进行清洗后进行数据分析,将分析结果绘制图表。
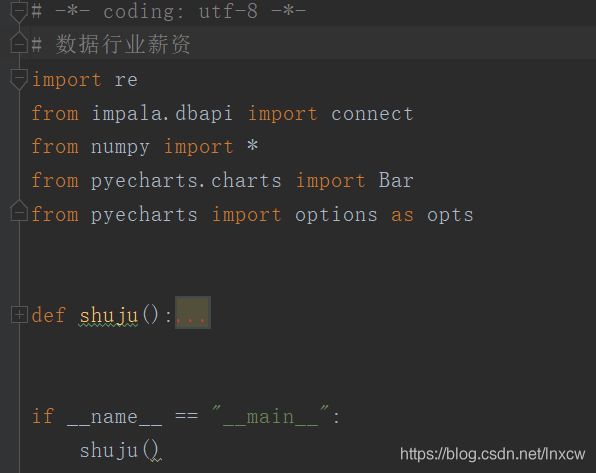
# -*- coding: utf-8 -*-
# 数据行业薪资
import re
from impala.dbapi import connect
from numpy import *
from pyecharts.charts import Bar
from pyecharts import options as opts
def shuju():
conn = connect(host='192.168.1.101',
port=10000,
auth_mechanism='LDAP',
user='root',
password='1',
database='mongodb')
cursor = conn.cursor()
# 最低工资
all_min_salary_list = []
# 最高工资
all_max_salary_list = []
# 平均工资
all_average_salary_list = []
# 岗位
all_addr_list = []
# 求出数据分析相关岗位的最值
def shujufenxi():
# 最低工资
min_salary_list = []
# 最高工资
max_salary_list = []
# 平均工资
average_salary_list = []
sql01 = "select salary from job_post where position like '%数据分析%' and salary like '%/%'"
cursor.execute(sql01)
results = cursor.fetchall()
# 数据清洗
for i in results:
if "万/月" in i[0]:
wan_yue = re.findall(r"(.*)万/月", i[0])[0]
num_list = wan_yue.split("-")
num_1 = eval(num_list[0]) * 10
num_2 = eval(num_list[1]) * 10
i = str(num_1) + "-" + str(num_2) + "千/月"
elif "万/年" in i[0]:
wan_yue = re.findall(r"(.*)万/年", i[0])[0]
num_list = wan_yue.split("-")
num_1 = eval(num_list[0]) * 10 / 12
num_2 = eval(num_list[1]) * 10 / 12
i = str(int(num_1)) + "-" + str(int(num_2)) + "千/月"
elif "千/月" in i[0]:
wan_yue = re.findall(r"(.*)千/月", i[0])[0]
num_list = wan_yue.split("-")
num_1 = eval(num_list[0])
num_2 = eval(num_list[1])
i = str(num_1) + "-" + str(num_2) + "千/月"
else:
continue
min_salary = i.split("-")[0]
max_salary = re.findall(r'([\d+\.]+)', (i.split("-")[1]))[0]
average_salary = "{:.1f}".format((float(min_salary) + float(max_salary)) / 2)
# 将获取的数据分别写入
min_salary_list.append(eval(min_salary))
max_salary_list.append(eval(max_salary))
average_salary_list.append(eval(average_salary))
listjob = '数据分析'
listmin = min(min_salary_list)
listmax = max(max_salary_list)
listaverage = int(mean(average_salary_list))
all_min_salary_list.append(listmin)
all_max_salary_list.append(listmax)
all_average_salary_list.append(listaverage)
all_addr_list.append(listjob)
print(listjob, listmin, listaverage, listmax)
file = open('数据岗位薪资水平.txt', 'w', encoding='utf-8')
file.write('{},{},{},{}'.format(listjob, listmax, listaverage, listmin))
file.write('\n')
file.close()
# 关闭游标
conn.commit()
# 求出大数据开发工程师相关岗位的最值
def bigdata():
# 最低工资
min_salary_list = []
# 最高工资
max_salary_list = []
# 平均工资
average_salary_list = []
sql = "select salary from job_post where position like '%大数据开发工程师%' and salary like '%/%'"
cursor.execute(sql)
results = cursor.fetchall()
for i in results:
if "万/月" in i[0]:
wan_yue = re.findall(r"(.*)万/月", i[0])[0]
num_list = wan_yue.split("-")
num_1 = eval(num_list[0]) * 10
num_2 = eval(num_list[1]) * 10
i = str(num_1) + "-" + str(num_2) + "千/月"
elif "万/年" in i[0]:
wan_yue = re.findall(r"(.*)万/年", i[0])[0]
num_list = wan_yue.split("-")
num_1 = eval(num_list[0]) * 10 / 12
num_2 = eval(num_list[1]) * 10 / 12
i = str(int(num_1)) + "-" + str(int(num_2)) + "千/月"
elif "千/月" in i[0]:
wan_yue = re.findall(r"(.*)千/月", i[0])[0]
num_list = wan_yue.split("-")
num_1 = eval(num_list[0])
num_2 = eval(num_list[1])
i = str(num_1) + "-" + str(num_2) + "千/月"
else:
continue
min_salary = i.split("-")[0]
max_salary = re.findall(r'([\d+\.]+)', (i.split("-")[1]))[0]
average_salary = "{:.1f}".format((float(min_salary) + float(max_salary)) / 2)
# 将获取的数据分别写入
min_salary_list.append(eval(min_salary))
max_salary_list.append(eval(max_salary))
average_salary_list.append(eval(average_salary))
listjob = '大数据开发工程师'
listmin = min(min_salary_list)
listmax = max(max_salary_list)
listaverage = int(mean(average_salary_list))
all_min_salary_list.append(listmin)
all_max_salary_list.append(listmax)
all_average_salary_list.append(listaverage)
all_addr_list.append(listjob)
print(listjob, listmin, listaverage, listmax)
file = open('数据岗位薪资水平.txt', 'a+', encoding='utf-8')
file.write('{},{},{},{}'.format(listjob, listmax, listaverage, listmin))
file.write('\n')
file.close()
conn.commit()
# 求出数据采集相关岗位最值
def shujucaiji():
# 最低工资
min_salary_list = []
# 最高工资
max_salary_list = []
# 平均工资
average_salary_list = []
sql = "select salary from job_post where position like '%数据采集%' and salary like '%/%'" # .format(Job)
cursor.execute(sql)
results = cursor.fetchall()
for i in results:
if "万/月" in i[0]:
wan_yue = re.findall(r"(.*)万/月", i[0])[0]
num_list = wan_yue.split("-")
num_1 = eval(num_list[0]) * 10
num_2 = eval(num_list[1]) * 10
i = str(num_1) + "-" + str(num_2) + "千/月"
elif "万/年" in i[0]:
wan_yue = re.findall(r"(.*)万/年", i[0])[0]
num_list = wan_yue.split("-")
num_1 = eval(num_list[0]) * 10 / 12
num_2 = eval(num_list[1]) * 10 / 12
i = str(int(num_1)) + "-" + str(int(num_2)) + "千/月"
elif "千/月" in i[0]:
wan_yue = re.findall(r"(.*)千/月", i[0])[0]
num_list = wan_yue.split("-")
num_1 = eval(num_list[0])
num_2 = eval(num_list[1])
i = str(num_1) + "-" + str(num_2) + "千/月"
else:
continue
min_salary = i.split("-")[0]
max_salary = re.findall(r'([\d+\.]+)', (i.split("-")[1]))[0]
average_salary = "{:.1f}".format((float(min_salary) + float(max_salary)) / 2)
# 将获取的数据分别写入
min_salary_list.append(eval(min_salary))
max_salary_list.append(eval(max_salary))
average_salary_list.append(eval(average_salary))
listjob = '数据采集'
listmin = min(min_salary_list)
listmax = max(max_salary_list)
listaverage = int(mean(average_salary_list))
all_min_salary_list.append(listmin)
all_max_salary_list.append(listmax)
all_average_salary_list.append(listaverage)
all_addr_list.append(listjob)
print(listjob, listmin, listaverage, listmax)
file = open('数据岗位薪资水平.txt', 'a+', encoding='utf-8')
file.write('{},{},{},{}'.format(listjob, listmax, listaverage, listmin))
file.write('\n')
file.close()
conn.commit()
shujufenxi()
bigdata()
shujucaiji()
# 关闭游标
cursor.close()
conn.commit()
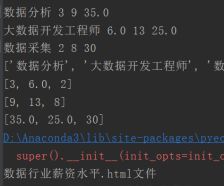
print(all_addr_list)
print(all_min_salary_list)
print(all_average_salary_list)
print(all_max_salary_list)
bar = Bar(
init_opts=opts.InitOpts(width="1000px", height="800px"),
)
bar.set_global_opts(
title_opts=opts.TitleOpts(title="数据行业薪资水平", subtitle="单位 千/月"),
xaxis_opts=opts.AxisOpts(axislabel_opts={"rotate": 45}),
)
bar.add_xaxis(all_addr_list)
bar.add_yaxis("最高薪资", all_max_salary_list)
bar.add_yaxis("最低薪资", all_min_salary_list)
bar.add_yaxis("平均薪资", all_average_salary_list)
bar.render("数据行业薪资水平.html")
print("数据行业薪资水平.html文件")
if __name__ == "__main__":
shuju()
(4)大数据行业占地区比重
连接数据库,将所需数据查询出来存放到列表,并对数据进行清洗后进行数据分析,将分析结果绘制图表。
(5)大数据经验薪资图
连接数据库,将所需数据查询出来存放到列表,并对数据进行清洗后进行数据分析,将分析结果绘制图表。
(6)大数据近日需求
连接数据库,将所需数据查询出来存放到列表,并对数据进行清洗后进行数据分析,将分析结果绘制图表。
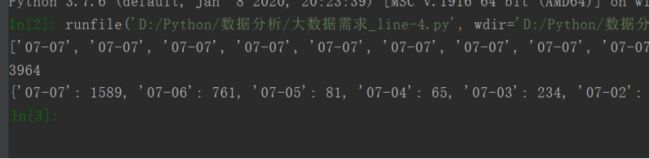
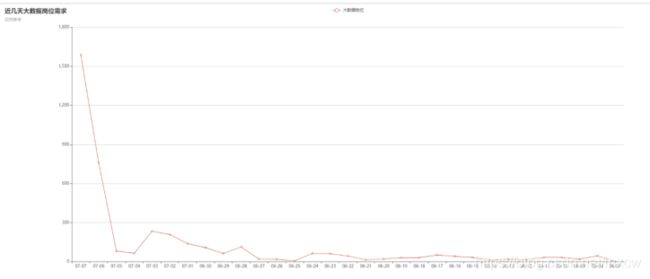
4、sqoop数据转存
将hive数据库里面的内容导出到mysql
sh sqoop export --connect jdbc:mysql://192.168.1.101:3306/job_post?characterEncoding=UTF-8 --username root --password 1 --table table2 --export-dir /home/apache-hive-2.3.6-bin/warehouse/mongodb.db/table2 --input-fields-terminated-by ','
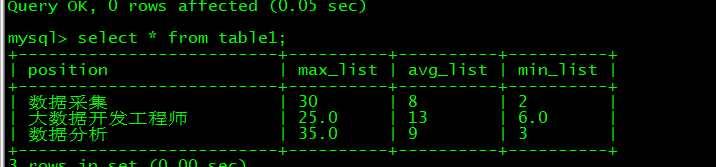

项目源码:
链接:https://pan.baidu.com/s/1R-Nwf4QoC5KcFUokF_4pFw
提取码:36i6