OLAP(三):Impala介绍 、 (和hive/spark对比)、COMPUTE STATS
一、Impala概述
Impala是用于处理存储在Hadoop集群中的大量数据的MPP(大规模并行处理)SQL查询引擎。与其他Hadoop的SQL引擎相比,它提供了高性能和低延迟。换句话说,Impala是性能最高的SQL引擎(提供类似RDBMS的体验),它提供了访问存储在Hadoop分布式文件系统中的数据的最快方法。
Impala是什么?
Impala提供对大数据更快速,交互式 SQL查询。
Impala支持对存储在HDFS、HBase及S3等数据查询。
Impala使用和Hive相同的元数据、SQL定义、ODBC驱动及用户接口。
Impala提供实时、批数据的统一查询平台。
Impala是对现有大数据查询工具的补充,不能替代基于Hive的MapReduce批处理任务框架(适用于耗时长的批处理任务,例如ETL等)。
Impala建立在集群之上的分布式查询,易于扩展。
二、Impala架构
Impala是在Hadoop集群中的许多系统上运行的MPP(大规模并行处理)查询执行引擎。 与传统存储系统不同,impala与其存储引擎解耦。 它有三个主要组件,即Impala daemon(Impalad),Impala Statestore 和Impala元数据或metastore。
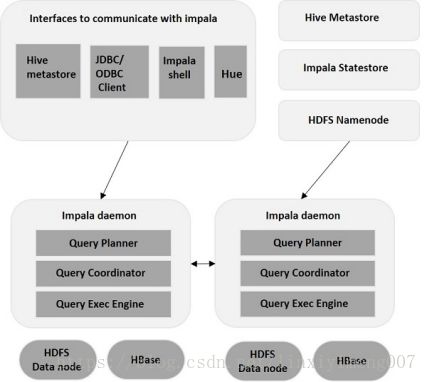
Impala daemon(Impalad)、
Impala daemon(也称为impalad)在安装Impala的每个节点上运行。 它接受来自各种接口的查询,如impala shell,hue browser等...并处理它们。
每当将查询提交到特定节点上的impalad时,该节点充当该查询的“协调器节点”类似spark中Applicationmaster。 Impalad还在其他节点上运行多个查询。 接受查询后,Impalad读取和写入数据文件,并通过将工作分发到Impala集群中的其他Impala节点来并行化查询。 当查询处理各种Impalad实例时,所有查询都将结果返回到中央协调节点。根据需要,可以将查询提交到专用Impalad或以负载平衡方式提交到集群中的另一Impalad。
Impala 存储的状态
Impala有另一个称为Impala State存储的重要组件,它负责检查每个Impalad的运行状况,然后经常将每个Impala Daemon运行状况中继给其他守护程序。 这可以在运行Impala服务器或群集中的其他节点的同一节点上运行。
Impala State存储守护进程的名称为存储的状态。 Impalad将其运行状况报告给Impala State存储守护程序,即存储的状态。在由于任何原因导致节点故障的情况下,Statestore将更新所有其他节点关于此故障,并且一旦此类通知可用于其他impalad,则其他Impala守护程序不会向受影响的节点分配任何进一步的查询。
Impala元数据和元存储
Impala元数据和元存储是另一个重要组件。 Impala使用传统的MySQL或PostgreSQL数据库来存储表定义。 诸如表和列信息和表定义的重要细节存储在称为元存储的集中式数据库中。每个Impala节点在本地缓存所有元数据。 当处理极大量的数据和/或许多分区时,获得表特定的元数据可能需要大量的时间。 因此,本地存储的元数据缓存有助于立即提供这样的信息。当表定义或表数据更新时,其他Impala后台进程必须通过检索最新元数据来更新其元数据缓存,然后对相关表发出新查询。
查询处理接口
要处理查询,Impala提供了三个接口,如下所示。
1、Impala-shell - 使用Cloudera VM设置Impala后,可以通过在编辑器中键入impala-shell命令来启动Impala shell。 我们将在后续章节中更多地讨论Impala shell。
2、Hue界面 - 您可以使用Hue浏览器处理Impala查询。 在Hue浏览器中,您有Impala查询编辑器,您可以在其中键入和执行impala查询。 要访问此编辑器,首先,您需要登录到Hue浏览器
3、ODBC / JDBC驱动程序 - 与其他数据库一样,Impala提供ODBC / JDBC驱动程序。 使用这些驱动程序,您可以通过支持这些驱动程序的编程语言连接到impala,并构建使用这些编程语言在impala中处理查询的应用程序。
查询执行过程
1、每当用户使用提供的任何接口传递查询时,集群中的Impalads之一就会接受该查询。 此Impalad被视为该特定查询的协调程序。
Impalad将query解析为具体的执行计划Planner, 交给当前机器Coordinator即为中心协调节点
Coordinator(中心协调节点)根据执行计划Planner,通过本机Executor执行,并转发给其它有数据的impalad用Executor进行执行
2、在接收到查询后,查询协调器使用Hive元存储中的表模式验证查询是否合适。 稍后,它从HDFS名称节点收集关于执行查询所需的数据的位置的信息,并将该信息发送到其他impalad以便执行查询。
3、所有其他Impala守护程序读取指定的数据块并处理查询。 一旦所有守护程序完成其任务,查询协调器将收集结果并将其传递给用户。
各个impalad的Executor执行完成后,将结果返回给中心协调节点,中心节点Coordinator将汇聚的查询结果返回给客户端
impala查询执行过程、 剖析
Impala 实现了一个 SQL 查询处理引擎,它基于充当工作线程和协调器的守护进程集群。
客户端将其查询提交给协调器,该协调器负责在集群的工作线程之间分配查询执行。
Impala 查询处理可以分为三个阶段:编译、准入控制和执行,如下图所示:
编译
当 Impala 协调器收到来自客户端的查询时,它会解析查询,将查询中的表和列引用与 Impala 目录服务器管理的架构目录中包含的数据统计信息对齐,然后对查询进行类型检查和验证。
使用表和列统计信息,协调器生成优化的分布式查询计划 - 关系运算符树 - 具有可并行化的查询片段。它将查询片段分配给工作人员,考虑到数据局部性——从而形成片段实例——并估计查询的每个主机主内存消耗的峰值。它进一步确定了工作人员在接收他们的片段时最初将分配用于处理的主内存的分配。
准入控制
编译后,协调器将查询提交给准入控制。准入控制基于主内存估计和片段分配以及已经准许进入集群的查询来决定查询是被准许执行、排队还是拒绝。
为此,它会在每个主机和每个集群的基础上保留一个估计被承认的查询消耗的主内存的计数——后者被划分为由集群管理员定义的所谓的资源池。如果查询有足够的空间来适应每个主机和每个资源池的计数,它将被允许执行。
准入控制的关键指标是查询的MEM_LIMIT:查询的每台主机内存消耗允许的最大值。MEM_LIMIT 通常——但并不总是我们稍后会看到的——与查询编译阶段估计的每个节点内存消耗峰值相同。
执行
准入后,协调器开始执行查询。它将片段实例分发给工作程序,收集部分结果,组装总结果,并将其返回给客户端。
工作程序从查询编译阶段确定的初始主内存预留开始执行。随着执行的进行,工作人员可能会严格遵守准入控制所允许的 MEM_LIMIT 来增加为查询分配的内存。如果查询的主内存消耗接近这个限制,它可能会决定将内存溢出到磁盘(如果允许的话)。如果主内存消耗达到 MEM_LIMIT,则查询将被终止。
在执行期间,协调器会监视查询的进度并记录详细的查询配置文件。查询配置文件将比较查询编译阶段的估计行数和主内存消耗与查询实际消耗的行数和主内存。这为查询优化和表统计的质量提供了宝贵的见解。
Impala 准入控制详解
在对 Impala 查询执行的一般概述之后,让我们深入了解Impala 准入控制。准入控制主要由
分配给每个守护进程的主内存(mem_limit配置参数);
分配给资源池的总集群内存份额及其配置;
查询计划器的总内存消耗和每个主机的内存消耗估计。
让我们看一下关键资源池配置参数和查询的准入控制过程的具体示例。
资源池:资源池允许将 Impala 集群内存总量划分为不同的用例和租户。分段不是在公共池中运行所有查询,而是允许管理员将资源分配给最重要的查询,以便它们不会被业务优先级较低的查询中断。
关键的资源池配置参数是:Max Memory:集群中可以允许池中运行的查询的总主内存量。如果在池中已运行的查询的预期总主内存之上,将被允许进入池的查询的预期总主内存消耗超过此限制,则查询将不被允许。查询可能会被拒绝或排队,具体取决于池的队列配置。
最大查询内存限制:查询允许的最大每台主机内存消耗的上限 (MEM_LIMIT)。准入控制永远不会对查询施加大于最大查询内存限制的 MEM_LIMIT - 即使查询编译阶段估计的每个主机内存消耗峰值超过此限制。与 Max Memory 不同,Maximum Query Memory Limit 影响所有池的准入控制。即,如果在已经运行的查询的 MEM_LIMIT 之上的查询的 MEM_LIMIT(受最大查询内存限制限制)超过给定守护程序的配置主内存 mem_limit,则该查询将不被接受。
此参数的目的是限制查询对准入控制的大且可能不好或过于保守的峰值每主机内存消耗估计的影响 - 例如,基于没有统计信息的表或非常复杂的查询的查询。此参数与 Max Memory、守护进程的数量以及守护进程的 mem_limit 配置相结合,分别隐式地定义了在池中和跨池中运行的查询的潜在并行度。根据经验,最大查询内存限制应该是最大内存除以捕获所需查询池并行度的守护进程数量的一部分。
最小查询内存限制:查询允许的最大每台主机内存消耗的下限 (MEM_LIMIT)。无论每个主机的内存估计如何,MEM_LIMIT 都不会小于此值。最小查询内存限制的安全值为每个节点 1GB。
Clamp MEM_LIMIT:客户端可以通过将 MEM_LIMIT 查询选项显式设置为不同的值(例如,通过在其查询前添加 SET MEM_LIMIT=...mb)来覆盖由查询编译估计的每个主机内存消耗峰值以及由准入控制派生的结果 MEM_LIMIT . 如果 Clamp MEM_LIMIT 未设置为 true(这是默认值),则用户可以完全忽略资源池的最小和最大查询内存限制设置。如果设置为 true,则客户端明确提供的任何 MEM_LIMIT 都将绑定到最小和最大查询内存限制设置。
Max Running Queries:虽然最小和最大查询内存限制设置与最大内存设置和守护进程的数量一起隐含地定义了一个资源池内可以并行运行的查询数量的范围,但最大运行查询允许定义一个固定的可以同时运行的查询数。
Max Queued Queries:如果一个查询不能被立即接纳,因为它的 MEM_LIMIT 会超过池的最大内存限制或守护进程的 mem_limit 配置参数,Impala 准入控制可以将查询发送到池的等待队列。Max Queued Queries 定义了这个队列的大小,默认为 200。如果队列已满,查询将被拒绝。
队列超时:查询在被拒绝之前可以在池的等待队列中等待多长时间的限制。默认超时为一分钟。
准入控制示例
让我们使用一个简化的示例来说明 Impala 准入控制以及每个主机的峰值内存消耗估计和资源池设置之间的相互作用:
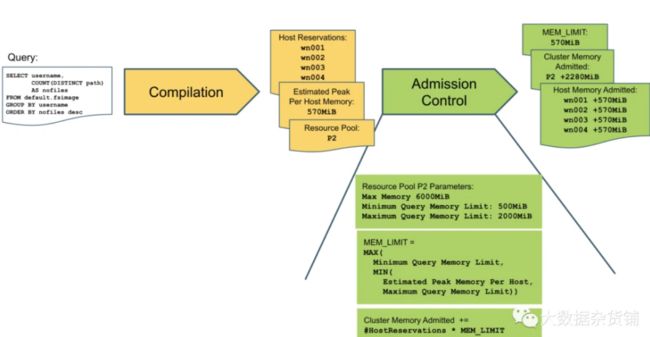
在上图中,客户端通过示例资源池 P2 向 Impala 协调器提交了一个简单的 group by / count 聚合 SQL 查询。使用正在查询的表的架构目录和查询统计信息,查询规划器估计每台主机的峰值内存使用量为 570 MiB。此外,规划器已确定查询的片段将在主机 wn001、wn002、wn-003 和 wn004 上执行。有了这个查询编译结果,查询就被移交给准入控制。
出于示例的目的,我们假设资源池 P2 已配置为 2000 MiB 的最大查询内存限制、500MiB 的最小查询内存限制和 6000MiB 的最大内存设置。
每个主机的峰值内存消耗估计为 570MiB,正好符合最小和最大查询内存限制设置。因此,准入控制不会以任何方式修改此估计值,而是将 MEM_LIMIT 设置为 570 MiB。如果估计值高于 2000MiB,则 MEM_LIMIT 将被限制为 2000MiB;如果估计值低于 500MiB,则 MEM_LIMIT 将被缓冲到 500MiB。
对于准入,准入控制检查节点 wn001、wn002、wn-003 和 wn004 上已经运行的查询的所有 MEM_LIMIT 总和加上 570 MiB 是否超过这些节点配置的主内存 mem_limit 中的任何一个。
准入控制进一步检查查询的 MEM_LIMIT 乘以查询将在已经运行的查询之上运行的节点数是否仍然符合 P2 配置的 6000 MiB 的最大内存设置。
如果两个检查中的任何一个失败,准入控制将排队或拒绝查询,具体取决于是否已达到等待队列限制。
如果两个检查都通过,准入控制允许查询在 570MiB 的 MEM_LIMIT 下执行。只要每个工作节点在节点上消耗的主内存不超过此限制,它就会执行查询——如果是这种情况,工作节点将终止查询。
准入控制最终将受影响节点的主机内存准入计数增加 MEM_LIMIT (570MiB);它还将通过查询将在 MEM_LIMIT (570MiB * 4 = 2280 MiB) 上运行的节点数增加资源池的集群内存。
二、为什么选择Impala? Impala的优点:Impala数据查询效率比Hive快几倍甚至数十倍
Impala通过使用标准组件(如HDFS,HBase,Metastore,YARN)将传统分析数据库的SQL支持和多用户性能与Apache Hadoop的可扩展性和灵活性相结合。
三、Impala相对于Hive所使用的优化技术
1、没有使用 MapReduce进行并行计算,虽然MapReduce是非常好的并行计算框架,但它更多的面向批处理模式,而不是面向交互式的SQL执行。与 MapReduce相比:Impala把整个查询分成一执行计划树,而不是一连串的MapReduce任务,在分发执行计划后,Impala使用拉式获取数据的方式获取结果,把结果数据组成按执行树流式传递汇集,减少了把中间结果写入磁盘的步骤,再从磁盘读取数据的开销。Impala使用服务的方式避免 每次执行查询都需要启动的开销,即相比Hive没了MapReduce启动时间。
2、更好的IO调度,Impala知道数据块所在的磁盘位置能够更好的利用多磁盘的优势,同时Impala支持直接数据块读取和本地代码计算checksum。
3、通过选择合适的数据存储格式可以得到最好的性能(Impala支持多种存储格式)。
4、最大使用内存,中间结果不写磁盘,及时通过网络以stream的方式传递。
5、使用LLVM产生运行代码,针对特定查询生成特定代码,同时使用Inline的方式减少函数调用的开销,加快执行效率。
Impala是Cloudera由C++编写的基于MPP(massively parallel processing 大规模并行处理)理念的查询引擎
6、充分利用可用的硬件指令(SSE4.2)。
四、Impala与Hive的异同
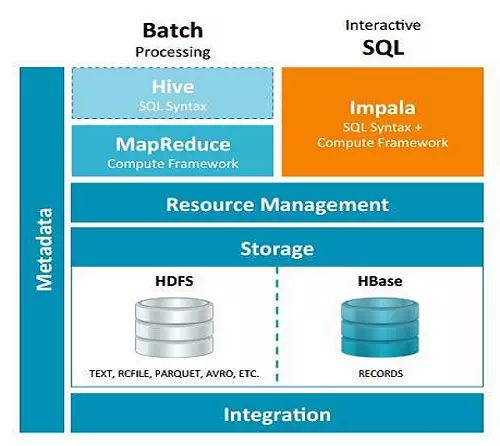
1、相同点
数据存储
- 使用相同的存储数据池都支持把数据存储于HDFS, HBase。
元数据:
- 两者使用相同的元数据
SQL解释处理:
- 比较相似都是通过词法分析生成执行计划。
2、不同点
1、执行计划:
- Hive: 依赖于MapReduce执行框架,执行计划分成 map->shuffle->reduce->map->shuffle->reduce…的模型。如果一个Query会 被编译成多轮MapReduce,则会有更多的写中间结果。由于MapReduce执行框架本身的特点,过多的中间过程会增加整个Query的执行时间。
- Impala: 把执行计划表现为一棵完整的执行计划树,可以更自然地分发执行计划到各个Impalad执行查询,而不用像Hive那样把它组合成管道型的 map->reduce模式,以此保证Impala有更好的并发性和避免不必要的中间sort与shuffle。
主节点生成执行计划树并分发执行计划至各节点并行执行的拉式获取数据(MR:推式获取数据)
2、数据块
Impala拥有HDFS上面各个data block的信息,当它处理查询的时候能够在各个datanode上面更均衡的分发查询。
它访问/分析存储在Hadoop数据节点上的数据,而无需数据移动。由于在数据驻留(在Hadoop集群上)时执行数据处理,因此在使用Impala时,不需要对存储在Hadoop上的数据进行数据转换和数据移动。减少网络IO
3、数据流:
- Hive: 采用推的方式,每一个计算节点计算完成后将数据主动推给后续节点。
- Impala: 采用拉的方式,后续节点通过getNext主动向前面节点要数据,以此方式数据可以流式的返回给客户端,且只要有1条数据被处理完,就可以立即展现出来,而不用等到全部处理完成,更符合SQL交互式查询使用。
4、内存使用:
- Hive: 在执行过程中如果内存放不下所有数据(内存不够时),则会使用外存,以保证Query能顺序执行完。每一轮MapReduce结束,中间结果也会写入HDFS中,同样由于MapReduce执行架构的特性,shuffle过程也会有写本地磁盘的操作。
- Impala:在执行SQL语句的时候,Impala不会把中间数据写入到磁盘,而是在内存中完成了所有的处理。 在遇到内存放不下数据时,当前版本1.0.1是直接返回错误,而不会利用外存,以后版本应该会进行改进。这使用得Impala目前处理Query会受到一 定的限制,最好还是与Hive配合使用。Impala在多个阶段之间利用网络传输数据,在执行过程不会有写磁盘的操作(insert除外)
5、调度、任务执行
- Hive任务的调度依赖于Hadoop的调度策略。
- Impala的调度由自己完成,目前的调度算法会尽量满足数据的局部性,即扫描数据的进程应尽量靠近数据本身所在的物理机器。但目前调度暂时还没有考虑负载均衡的问题。从Cloudera的资料看,Impala程序的瓶颈是网络IO,目前Impala中已经存在对Impalad机器网络吞吐进行统计,但目前还没有利用统计结果进行调度。
- 使用Impala的时候,查询任务会马上执行而不是生产Mapreduce任务,这会节约大量的初始化时间。
6、汇编、充分利用可用的硬件指令
一个关键原因是,Impala为每个查询产生汇编级的代码,当Impala在本地内存中运行的时候,这些汇编代码执行效率比其它任何代码框架都更快,因为代码框架会增加额外的延迟。
容错
- Hive任务依赖于Hadoop框架的容错能力,可以做到很好的failover
- Impala中不存在任何容错逻辑,如果执行过程中发生故障,则直接返回错误。当一个Impalad失败时,在这个Impalad上正在运行的所有query都将失败。但由于Impalad是对等的,用户可以向其他Impalad提交query,不影响服务。当StateStore失败时,也不会影响服务,但由于Impalad已经不能再更新集群状态,如果此时有其他Impalad失败,则无法及时发现。这样调度时,如果谓一个已经失效的Impalad调度了一个任务,则整个query无法执行。
适用面:
- Hive: 复杂的批处理查询任务,数据转换任务。
- Impala:实时数据分析,因为不支持UDF,能处理的问题域有一定的限制,与Hive配合使用,对Hive的结果数据集进行实时分析。
7、Impala使用Apache Hive的元数据,ODBC驱动程序和SQL语法。
Impala将相同的元数据,SQL语法(Hive SQL),ODBC驱动程序和用户界面(Hue Beeswax)用作Apache Hive,为面向批量或实时查询提供熟悉且统一的平台。
6、可以将Impala与业务智能工具(如Tableau,Pentaho,Micro策略和缩放数据)集成。
Impala的缺点
1、Impala不提供任何对序列化和反序列化的支持。
2、Impala只能读取文本文件,而不能读取自定义二进制文件。
3、每当新的记录/文件被添加到HDFS中的数据目录时,该表需要被刷新。
4、对内存依赖大,只在内存中计算,官方建议128G(一般64G基本满足),可优化: 各个节点汇总的节点(服务器)内存选用大的,不汇总节点可小点
5、稳定性不如hive
四、Impala、Hive 性能对比测试
共10643213条
1、count
执行语句:select count(1) from impala_hbase;
Impala耗时:28.58s
Hive耗时:255.412s
2、group by
执行语句:select dn,count(1) from impala_hbase group by dn;
Impala耗时:60.13s
Hive耗时:257.453s
四、注意事项
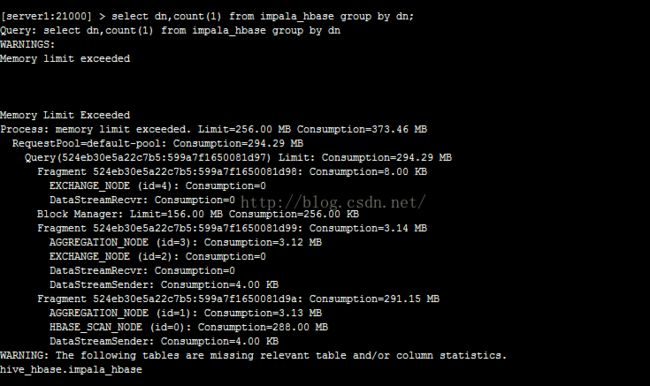
Impala有个内存阈值的设置,如果该值设置太小,Impala执行大数据量查询时,会受限于内存阈值而无法正确执行,如下:

3、 where
select * from chengyeliang where foo=1314;
hive:耗时19.967秒
impala:耗时0.31秒
hive:耗时110.581秒
impala:耗时24.50秒
五、关系数据库和Impala
Impala使用类似于SQL和HiveQL的Query语言。 下表描述了SQL和Impala查询语言之间的一些关键差异。
| Impala |
关系型数据库 |
|
| Impala使用类似于HiveQL的类似SQL的查询语言。 |
关系数据库使用SQL语言。 |
|
| 在Impala中,您无法更新或删除单个记录。 |
在关系数据库中,可以更新或删除单个记录。 |
|
| Impala不支持事务。 |
关系数据库支持事务。 |
|
| Impala不支持索引。 |
关系数据库支持索引。 |
|
| Impala存储和管理大量数据(PB)。 |
与Impala相比,关系数据库处理的数据量较少(TB)。 |
六、 Hive、Hbase、Impala
虽然Cloudera Impala使用与Hive相同的查询语言,元数据和用户界面,但在某些方面它与Hive和HBase不同。 下表介绍了HBase,Hive和Impala之间的比较分析。
| HBase |
Hive |
Impala |
| HBase是基于Apache Hadoop的宽列存储数据库。 它使用BigTable的概念。 |
Hive是一个数据仓库软件。 使用它,我们可以访问和管理基于Hadoop的大型分布式数据集。 |
Impala是一个管理,分析存储在Hadoop上的数据的工具。 |
| HBase的数据模型是宽列存储。 |
Hive遵循关系模型。 |
Impala遵循关系模型。 |
| HBase是使用Java语言开发的。 |
Hive是使用Java语言开发的。 |
Impala是使用C ++开发的。 |
| HBase的数据模型是无模式的。 |
Hive的数据模型是基于模式的。 |
Impala的数据模型是基于模式的。 |
| HBase提供Java,RESTful和Thrift API。 |
Hive提供JDBC,ODBC,Thrift API。 |
Impala提供JDBC和ODBC API。 |
| 支持C,C#,C ++,Groovy,Java PHP,Python和Scala等编程语言。 |
支持C ++,Java,PHP和Python等编程语言。 |
Impala支持所有支持JDBC / ODBC的语言。 |
| HBase提供对触发器的支持。 |
Hive不提供任何触发器支持。 |
Impala不提供对触发器的任何支持。 |
七、impala presto SparkSql性能测试对比
mpala与presto性能相当,SparkSql逊色不少。
测试过程比较简单,分为四个场景sql查询:
| 查询id | 查询语句 | 数据量(压缩前) |
| query1 | select sum(pv) from d_op_behavior_host_text_snappy | 35G |
| query2 | select siteid,sum(pv) as pv1 from d_op_behavior_host_text_snappy where pv>0 group by siteid order by pv1 desc limit 11; |
35G |
| query3 | select count(*) from dwd.d_ad_3rd_party_fancy_all_data where thisdate='2015-11-10' and hour='17'; |
200G |
| query4 | select count(*) from dwd.d_ad_impression where thisdate>='2015-09-01' and thisdate<='2015-10-31' |
-
测试结果对比如下:
查询 工具 第一次执行时间 第二次执行时间 query1 impala 4.82s 5.56s presto 6s 5s sparkSql 13s 9s query2 impala 12.79s 12s presto 15s 13s sparkSql 20s 23s query3 impala 挂掉 挂掉 presto 63s 58s sparkSql 88s 77s query4 impala 131s 148s presto 136s 128s sparkSql 187s 188s
二、impala实践
1、impala-shell操作hive数据实例
[root@hadoop06 ~]# impala-shell -h
下面是Impala的外部Shell的一些参数:
-h : (--help) 帮助
-v : (--version) 查询版本信息
-p : 显示执行计划
-k : (--kerberos) 使用kerberos安全加密方式运行impala-shell
-l : 启用LDAP认证
-u : 启用LDAP时,指定用户名-i : hostname (--impalad=hostname) 指定连接主机格式hostname:port 默认端口21000,
impalad shell 默认连接本机impalad
-q : query 指定查询的sql语句 从命令行执行查询,不进入impala-shell
-d : default_db (--database=default_db) 指定数据库
-B :(--delimited)去格式化输出,格式化输出* 大量数据加入格式化,性能受到影响
--output_delimiter=character (指定分隔符与其他命令整合,默认是\t分割)
--print_header 打印列名(去格式化,但是显示列名字,默认不打印)
-f : query_file后跟查询文件(--query_file=query_file)执行查询文件,以分号分隔
建议sql 语句写到一行,因为shell 会读取文件一行一行的命令
-o : filename (--output_file filename) 结果输出到指定文件
-c : 查询执行失败时继续执行
-r : 刷新所有元数据(当hive创建表的时候,你需要刷新到,才能看到hive元数据的改变)
整体刷新,全量刷新,万不得已才能用;
不建议定时去刷新hive源数据,数据量太大时候,一个刷新,很有可能会挂掉;
- 在OpenLDAP服务未启用TLS加密时,impala-shell访问Impala Daemon需要在增加参数--auth_creds_ok_in_clear,否则会报错“LDAP credentials may not besent over insecure connections. Enable SSL or set --auth_creds_ok_in_clear”
hive> select * from weather.weather_everydate_detail limit 10;
OK
WOCE_P10 1993 279.479 -16.442 172.219 24.9544 34.8887 1.0035 363.551 2
WOCE_P10 1993 279.48 -16.44 172.214 24.9554 34.8873 1.0035 363.736 2
WOCE_P10 1993 279.48 -16.439 172.213 24.9564 34.8868 1.0033 363.585 2
WOCE_P10 1993 279.481 -16.438 172.209 24.9583 34.8859 1.0035 363.459 2
WOCE_P10 1993 279.481 -16.437 172.207 24.9594 34.8859 1.0033 363.543 2
WOCE_P10 1993 279.481 -16.436 172.205 24.9604 34.8858 1.0035 363.432 2
WOCE_P10 1993 279.489 -16.417 172.164 24.9743 34.8867 1.0036 362.967 2
WOCE_P10 1993 279.49 -16.414 172.158 24.9742 34.8859 1.0035 362.96 2
WOCE_P10 1993 279.491 -16.412 172.153 24.9747 34.8864 1.0033 362.998 2
WOCE_P10 1993 279.492 -16.411 172.148 24.9734 34.8868 1.0031 363.022 2
Time taken: 0.815 seconds, Fetched: 10 row(s)
hive> select count(*) from weather.weather_everydate_detail;
Query ID = root_20171214185454_c783708d-ad4b-46cc-9341-885c16a286fe
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=
In order to set a constant number of reducers:
set mapreduce.job.reduces=
Starting Job = job_1512525269046_0001, Tracking URL = http://quickstart.cloudera:8088/proxy/application_1512525269046_0001/
Kill Command = /usr/lib/hadoop/bin/hadoop job -kill job_1512525269046_0001
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2017-12-14 18:55:27,386 Stage-1 map = 0%, reduce = 0%
2017-12-14 18:56:11,337 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 39.36 sec
2017-12-14 18:56:18,711 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 41.88 sec
MapReduce Total cumulative CPU time: 41 seconds 880 msec
Ended Job = job_1512525269046_0001
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 41.88 sec HDFS Read: 288541 HDFS Write: 5 SUCCESS
Total MapReduce CPU Time Spent: 41 seconds 880 msec
OK
4018
Time taken: 101.82 seconds, Fetched: 1 row(s) 1、启动Impala CLI
[root@quickstart cloudera] # impala-shell
Starting Impala Shell……2、在Impala中同步元数据 invalidate metadata; #同步hive元数据
[quickstart.cloudera:21000] > INVALIDATE METADATA;
Query: invalidate METADATA
Query submitted at: 2017-12-14 19:01:12 (Coordinator: http://quickstart.cloudera:25000)
Query progress can be monitored at: http://quickstart.cloudera:25000/query_plan?query_id=43460ace5d3a9971:9a50f46600000000
Fetched 0 row(s) in 3.25s
INVALIDATE METADATA TABLENAME;
REFRESH TABLENAME;
3、在Impala中查看Hive中表的结构
[quickstart.cloudera:21000] > use weather;
Query: use weather
[quickstart.cloudera:21000] > desc weather.weather_everydate_detail;
Query: describe weather.weather_everydate_detail
+---------+--------+---------+
| name | type | comment |
+---------+--------+---------+
| section | string | |
| year | bigint | |
| date | double | |
| latim | double | |
| longit | double | |
| sur_tmp | double | |
| sur_sal | double | |
| atm_per | double | |
| xco2a | double | |
| qf | bigint | |
+---------+--------+---------+
Fetched 10 row(s) in 3.70s4、查询记录数量
[quickstart.cloudera:21000] > select count(*) from weather.weather_everydate_detail;
Query: select count(*) from weather.weather_everydate_detail
Query submitted at: 2017-12-14 19:03:11 (Coordinator: http://quickstart.cloudera:25000)
Query progress can be monitored at: http://quickstart.cloudera:25000/query_plan?query_id=5542894eeb80e509:1f9ce37f00000000
+----------+
| count(*) |
+----------+
| 4018 |
+----------+
Fetched 1 row(s) in 2.51s说明:对比Impala与Hive中的count查询,2.15 VS 101.82,Impala的优势还是相当明显的
5、执行一个普通查询
[quickstart.cloudera:21000] > select * from weather_everydate_detail where sur_sal=34.8105;
Query: select * from weather_everydate_detail where sur_sal=34.8105
Query submitted at: 2017-12-14 19:20:27 (Coordinator: http://quickstart.cloudera:25000)
Query progress can be monitored at: http://quickstart.cloudera:25000/query_plan?query_id=c14660ed0bda471f:d92fcf0e00000000
+----------+------+---------+--------+---------+---------+---------+---------+---------+----+
| section | year | date | latim | longit | sur_tmp | sur_sal | atm_per | xco2a | qf |
+----------+------+---------+--------+---------+---------+---------+---------+---------+----+
| WOCE_P10 | 1993 | 312.148 | 34.602 | 141.951 | 24.0804 | 34.8105 | 1.0081 | 361.29 | 2 |
| WOCE_P10 | 1993 | 312.155 | 34.602 | 141.954 | 24.0638 | 34.8105 | 1.0079 | 360.386 | 2 |
+----------+------+---------+--------+---------+---------+---------+---------+---------+----+
Fetched 2 row(s) in 0.25s[quickstart.cloudera:21000] > select * from weather_everydate_detail where sur_tmp=24.0804;
Query: select * from weather_everydate_detail where sur_tmp=24.0804
Query submitted at: 2017-12-14 23:15:32 (Coordinator: http://quickstart.cloudera:25000)
Query progress can be monitored at: http://quickstart.cloudera:25000/query_plan?query_id=774e2b3b81f4eed7:8952b5b400000000
+----------+------+---------+--------+---------+---------+---------+---------+--------+----+
| section | year | date | latim | longit | sur_tmp | sur_sal | atm_per | xco2a | qf |
+----------+------+---------+--------+---------+---------+---------+---------+--------+----+
| WOCE_P10 | 1993 | 312.148 | 34.602 | 141.951 | 24.0804 | 34.8105 | 1.0081 | 361.29 | 2 |
+----------+------+---------+--------+---------+---------+---------+---------+--------+----+
Fetched 1 row(s) in 3.86s6.结论
对于Hive中需要编译为mapreduce执行的SQL,在Impala中执行是有明显的速度优势的,但是Hive也不是所有的查询都要编译为mapreduce,此类型的查询,impala相比于Hive就没啥优势了。
2、java通过jdbc连接impala
public class test_jdbc {
public static void test(){
Connection con = null;
ResultSet rs = null;
PreparedStatement ps = null;
String JDBC_DRIVER = "com.cloudera.impala.jdbc41.Driver";
String CONNECTION_URL = "jdbc:impala://192.168.2.20:21050";
try
{
Class.forName(JDBC_DRIVER);
con = (Connection) DriverManager.getConnection(CONNECTION_URL);
ps = con.prepareStatement("select count(*) from billdetail;");
rs = ps.executeQuery();
while (rs.next())
{
System.out.println(rs.getString(1) );
}
} catch (Exception e)
{
e.printStackTrace();
} finally
{
try {
rs.close();
ps.close();
con.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) {
test();
}
}3、BI通过impala连接hadoop
1.tableau 通过impala连接hadoop
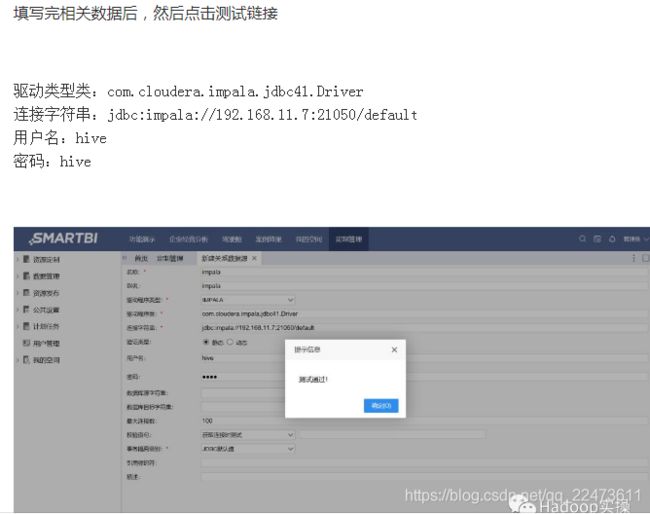
- 1.1 下载BI工具,impala驱动(https://www.cloudera.com/downloads/connectors/impala/odbc/2-6-5.html),下载安装完成后直接按图连接即可。
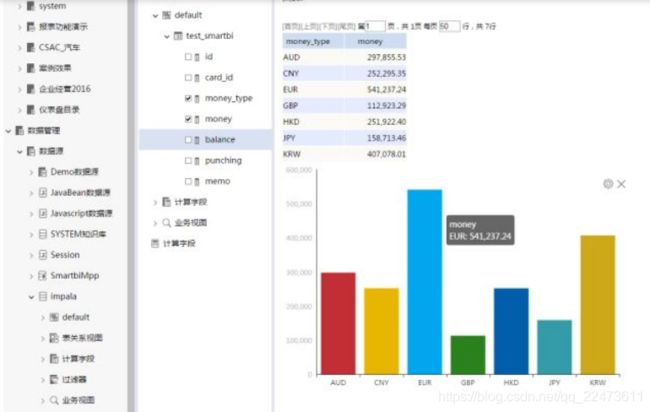
- 1.2 选择要操作的数据库
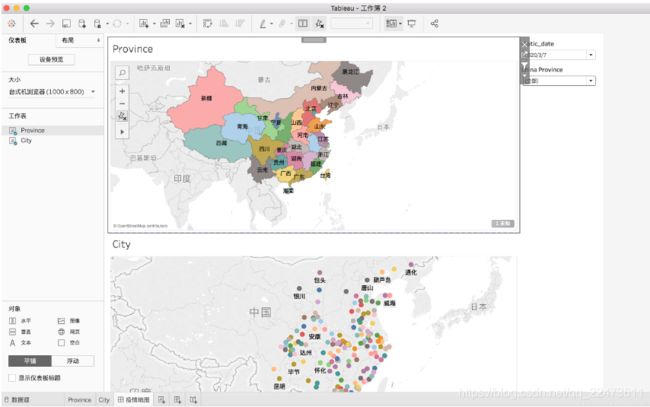
地图展示,省市联动地图
可以通过选择日期看不同时期疫情情况,当鼠标点击某个省份时,城市地图就显示那个省城市的疫情情况。
四、神奇指令 COMPUTE STATS
COMPUTE STATS 是统计表的结构以及数据信息(表、分区、列的数据量和数据分布信息)并存储在到数据库中,集群根据统计信息优化数据分析操作。
看似只是Impala中一条获取表的统计信息的简单语句,但在整个分析任务调度过程中却起着相当重要的作用。该语句获取的统计信息不仅在Impala对JOIN、GROUP BY、ORDER BY、UNION、DISTINCT等资源高消耗的查询进行优化时会使用到,而且对HBase的表也同样起作用。
语法:
COMPUTE STATS [db_name.]table_name ;
COMPUTE INCREMENTAL STATS [db_name.]table_name [PARTITION (partition_spec)] ;
--查看统计结果
SHOW TABLE STATS [table_name](PARTITION)只允许分区子句与增量子句组合使用。对于计算增量统计,它是可选的,对于删除增量统计,它是必需的。当您在COMPUTE INCREMENTAL STATS或DROP INCREMENTAL STATS语句中通过PARTITION (partition_spec)子句指定分区时,必须在规范中包含所有分区列,并为所有分区键列指定常量值。
如果一个基本的COMPUTE STATS语句对于一个分区表花费了很长时间,那么可以考虑切换到COMPUTE INCREMENTAL STATS语法,以便每次只分析新添加的分区。
最初,Impala依赖于用户来运行Hive分析表语句,但是这种收集统计数据的方法被证明是不可靠且难以使用的。Impala COMPUTE STATS语句从头开始构建,以提高该操作的可靠性和用户友好性。COMPUTE STATS不需要任何设置步骤或特殊配置。您只运行一个Impala COMPUTE STATS语句来收集表和列的统计信息,而不是针对每种统计信息分别运行Hive ANALYZE表语句。
COMPUTE INCREMENTAL STATS变体是分区表的快捷方式,它只在分区的一个子集上工作,而不是整个表。增量特性使它适合于具有许多分区的大型表,在这些表中,每次添加或删除一个分区时,完整的COMPUTE STATS操作都要花费很长时间。有关详细使用情况,请参见增量统计的概述。
计算增量统计仅适用于分区表。如果对未分区表使用INCREMENTAL子句,Impala会自动使用原始的COMPUTE STATS语句。这样的表在显示表stats输出的Incremental stats列下显示false。
由于许多性能最关键、资源最密集的操作都依赖于表和列统计信息来构建准确、高效的计划,因此计算统计信息是ETL过程最后的一个重要步骤。
在慢速查询的性能调优期间,或在内存不足的情况下进行故障排除时,
第一步是在所有表上运行COMPUTE STATS:
准确的统计数据有助于Impala为连接查询构建高效的查询计划,提高性能并减少内存使用。
准确的统计数据有助于Impala有效地将插入操作分配到拼花表中,提高性能并减少内存使用。
准确的统计数据可以帮助Impala估计每个查询所需的内存,这在使用资源管理特性(如许可控制和纱线资源管理框架)时非常重要。统计数据帮助Impala实现高并发性,充分利用可用内存,避免与其他Hadoop组件的工作负载争用。
目前,COMPUTE STATS语句创建的统计信息不包括关于复杂类型列的信息。复杂列的列统计指标总是显示为-1。对于涉及复杂类型列的查询,Impala使用启发式方法来估计这些列中的数据分布。
HBase注意事项:
COMPUTE STATS也适用于HBase表。为HBase表收集的统计信息与为hdfs支持的表收集的统计信息有所不同,但是在连接查询中涉及到HBase表时,仍然使用元数据进行优化。
1、场景一
drop table if exists sjqy.small_ofr_asset_inst_attr;
create table sjqy.small_ofr_asset_inst_attr as
select a.asset_exi_row_id
,a.asset_row_id
,a.attr_id
,a.char_val
,a.date_val
,a.num_val
,a.create_dt
,a.last_upd_dt
,a.val_type_name
,a.etl_dt
,a.etl_time
from sjqy.ofr_asset_inst_attr_impala a
left semi join sjqy.small_bak_inf_ofr_asset_exi_hist b
on a.asset_exi_row_id = b.set_exi_row_id ;
--报错内存不够
request memory estimate 889.71 GB is greater than pool limit 586.67 GB. 使用 :COMPUTE sjqy.small_bak_inf_ofr_asset_exi_hist
再次执行sql成功
2、场景二
select count(a.sn)
from usermodel_inter_total_label a
join usermodel_inter_total_info b
on a.sn = b.sn where a.label = ‘porn’ and a.heat > 0.1 and b.platform = ‘android’Returned 1 row(s) in 36.86s
explain一下发现了一个很隐蔽的warning:
WARNING: The following tables are missing relevant table and/or column statistics. default.usermodel_inter_total_info, default.usermodel_inter_total_label
这种waring,不是处(pian)女(zhi)座(kuang)发现不了!
先不忙,记下来,网上找那坑爹的Tuning Impala Performance文档看看(插个题外话,Impala的中文资料太寒酸了,做数据的矿工们已经全部投奔Spark阵营了么?),眼神掠过Column Statistics和Table Statistics的时候心里一凉,矿工的直觉告诉我「秘密就在这」!
大体意思就是通过预先分析表和列(对联表特别重要)的结构,并把这些信息保存到MetaStore,Impala查询时会利用这些信息优化查询的策略。
哟,这是个自动挡!,然后坑爹的文档就把我指到Hive的「ANALYZE TABLE」去了,试了半天Impala没反应啊,果然不是亲生兄弟~
神奇指令
COMPUTE STATS usermodel_inter_total_info;
COMPUTE STATS usermodel_inter_total_label;
优化后
select count(a.sn)
from usermodel_inter_total_label a
join usermodel_inter_total_info b
on a.sn = b.sn where a.label = ‘porn’ and a.heat > 0.1 and b.platform = ‘android’Returned 1 row(s) in 3.15s
Cool!10倍的提升,相对Hive20倍的提升,和单表查询一样的迅速!
2、「COMPUTE STATS
「COMPUTE STATS」前
指令:
show table stats usermodel_inter_total_label;
| log_date | #Rows | #Files | Size | Bytes Cached | Format |
|---|---|---|---|---|---|
| 2014-12-13 | -1 | 15 | 1.18GB | NOT CACHED | TEXT |
| 2014-12-14 | -1 | 3 | 1.80GB | NOT CACHED | TEXT |
| 2014-12-15 | -1 | 4 | 2.96GB | NOT CACHED | TEXT |
| Total | -1 | 22 | 5.93GB | 0B | - |
show column stats usermodel_inter_total_label;
| Column | Type | #Distinct Values | #Nulls | Max Size | Avg Size |
|---|---|---|---|---|---|
| sn | STRING | -1 | -1 | -1 | -1 |
| label | STRING | -1 | -1 | -1 | -1 |
| heat | DOUBLE | -1 | -1 | -1 | -1 |
| active_record | STRING | -1 | -1 | -1 | -1 |
| log_date | STRING | 3 | 0 | -1 | -1 |
「COMPUTE STATS」后
show table stats usermodel_inter_total_label;
| log_date | #Rows | #Files | Size | Bytes Cached | Format |
|---|---|---|---|---|---|
| 2014-12-13 | 9498438 | 2 | 469.76MB | NOT CACHED | TEXT |
| 2014-12-14 | 17891595 | 1 | 893.44MB | NOT CACHED | TEXT |
| 2014-12-15 | 27885473 | 2 | 1.37GB | NOT CACHED | TEXT |
| Total | 55275506 | 5 | 2.71GB | 0B | - |
show column stats usermodel_inter_total_label;
| Column | Type | #Distinct Values | #Nulls | Max Size | Avg Size |
|---|---|---|---|---|---|
| sn | STRING | 13984716 | -1 | 30 | 24.0039005279541 |
| label | STRING | 36 | -1 | 13 | 4.26140022277832 |
| heat | DOUBLE | 382126 | -1 | 8 | 8 |
| active_record | STRING | 7 | -1 | 3 | 1.667400002479553 |
| log_date | STRING | 3 | 0 | -1 | -1 |
看来「COMPUTE STATS」的作用就是得出Impala原先不知道的值(-1)。
分析:
出最简单的方式是通过执行COMPUTE STATS来收集涉及到的所有表的统计信息,
并让 Impala 基于每一个表的大小、每一个列不同值的个数、等等信息自动的优化查询
2.执行计划 (Explain)
通过在SQL语句前面加上 explain 执行,并就可以查看到该SQL的具体执行计划情况(实际上并未真正执行)
执行计划是从底层显示Impala如何读取数据,如何在各节点之间协调工作,组合并传输中间结果,并获得最终结果集的全过程。
执行计划可以提供给我们的帮助:
(1)通过读取的数据量,我们可以判断分区策略是否有效,并结合集群大小预估读取这些数据需要的实际等。
(2)可以看到执行过程中聚合、排序、统计函数、交互的顺序及具体执行细节,可以从更高级别看到中间结果在不同节点间的流向。
(3)我们可以看到操作是否被Impala不同的节点并行执行,以及各节点所需内存预估值。
(4)通过配置EXPLAIN_LEVEL参数,可以了解到更详细的输出信息。取值从0~3,对应的执行计划信息越来越详细。
今日头条https://www.toutiao.com/article/7116383896794595840/?app=news_article×tamp=1661532941&use_new_style=1&req_id=20220827005540010131056052221CC7F4&group_id=7116383896794595840&wxshare_count=1&tt_from=weixin&utm_source=weixin&utm_medium=toutiao_android&utm_campaign=client_share&share_token=37a05967-9793-43b3-acd5-ea67423f40b5&source=m_redirect