【大数据项目学习】第九章:HBase数据库
第九章:HBase数据库
一个初学者的大数据学习过程
文章目录
- 第九章:HBase数据库
-
- 1. HBase简介
-
- 1.1 是什么
- 1.2 生态圈中的位置
- 1.3 特点
- 1.4 数据模型
- 1.5 物理模型
- 2. HBase系统架构
-
- 2.1 Zookeeper
- 2.2 Master
- 2.3 RegionServer
- 3. HBase实际应用案例
1. HBase简介
1.1 是什么
HBase是构建在HDFS之上的分布式列存储数据库,是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可以在廉价PC Server上搭建起大规模结构化存储集群。
HBase 是Google Bigtable的开源实现,类似Google Bigtable利用GFS作为其文件存储系统,Google运行MapReduce来处理Bigtable中的海量数据,HBase同样利用Hadoop ,MapReduce来处理HBase中的海量数据;Google Bigtable利用 Chubby作为协同服务,HBase利用Zookeeper作为对应。
1.2 生态圈中的位置

1.3 特点
与传统数据库相比,HBase具有如下特点:
- 大:单表可以数十亿行,数百万列
- 无模式:同一个表的不同行可以有截然不同的列
- 面向列:存储、权限控制、检索均面向列
- 稀疏:空列不占用存储,表是稀疏的
- 多版本:每个单元中的数据可以有多个版本,默认情况下版本号自动分配,是单元格插入时的时间戳
- 数据类型单一:数据都是字符串,没有类型
1.4 数据模型

-
表(table)
在HBase中数据是以表的形式存储的,通过表可以将某些列放在一起访问,同一个表中的数据通常是相关的,可以通过列簇进一步把列放在一起进行访问。用户可以通过命令行或者Java API来创建表,创建表时只需要指定表名和至少一个列簇。HBase的列式存储结构允许用户存储海量的数据到相同的表中,而在传统数据库中,海量数据需要被切分成多个表进行存储。 -
行健(Row Key)
Rowkey既是HBase表的行键,也是HBase表的主键。HBase表中的记录是按照Rowkey的字典顺序进行存储的。在HBase中,为了高效地检索数据,需要设计良好的Rowkey来提高查询性能。首先Rowkey被冗余存储,所以长度不宜过长,Rowkey过长将会占用大量的存储空间同时会降低检索效率;其次Rowkey应该尽量均匀分布,避免产生热点问题;另外需要保证Rowkey的唯一性。 -
列簇(ColumnFamily)
HBase表中的每个列都归属于某个列簇,一个列簇中的所有列成员有着相同的前缀。比如,列url和host都是列簇URI的成员。列簇是表的schema的一部分,必须在使用表之前定义列簇,但列却不是必须的,写数据的时候可以动态加入。一般将经常一起查询的列放在一个列簇中,合理划分列簇将减少查询时加载到缓存的数据,提高查询效率,但也不能有太多的列簇,因为跨列簇访问是非常低效的。 -
单元格
HBase 中通过 Row 和 Column 确定的一个存储单元称为单元格(Cell)。每个单元格都保存着同一份数据的多个版本,不同时间版本的数据按照时间顺序倒序排序,最新时间的数据排在最前面。为了避免数据存在过多版本造成的管理(包括存储和索引)负担,HBase 提供了两种
数据版本回收方式。 一是保存数据的最后 n 个版本;二是保存最近一段时间内的数据版本,比如最近七天。用户可以针对每个列族进行设置。
1.5 物理模型
每个column family存储在HDFS上的一个单独的文件里。
Rowkey和version在每个column family里均有一份。
空值不保存,占位符都没有。


Table中的所有行都按照row key的字典序排列。
Table 在行的方向上分割为多个Region。
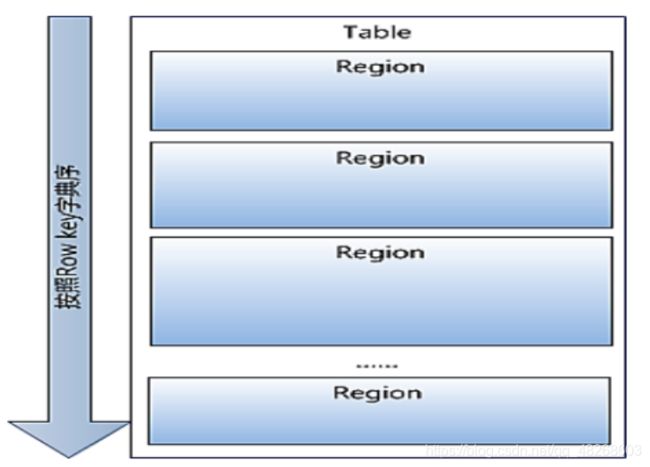
Table默认最初只有一个Region,随着记录数不断增加而变大后,会逐渐分裂成多个region,一个region由[startkey,endkey]表示,不同的region会被Master分配给相应的RegionServer进行管理.Region是HBase中分布式存储和负载均衡的最小单元。不同Region分布到不同RegionServer上。

Region虽然是分布式存储的最小单元,但并不是存储的最小单元。
Region由一个或者多个Store组成,每个store保存一个columns family。
每个Strore又由一个memStore和0至多个StoreFile组成。
memStore存储在内存中,StoreFile存储在HDFS上。

2. HBase系统架构
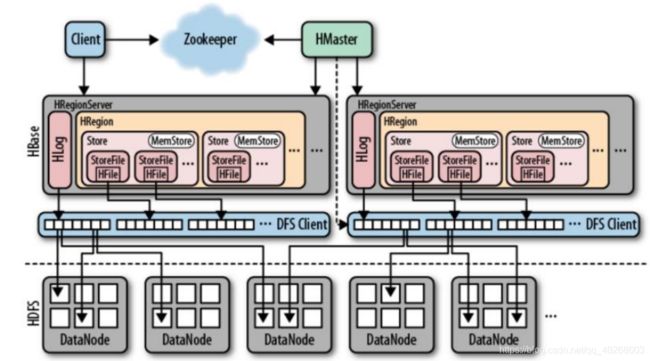
HBase采用Master/Slave架构搭建集群,由HMaster节点、HRegionServer节点、ZooKeeper集群组成,而在底层它将数据存储于HDFS中,因而涉及到HDFS的NameNode、DataNode等,每个DataNode上面最好启动一个HRegionServer, 这样在一定程度上保持数据的本地性。

2.1 Zookeeper
ZooKeeper协调集群所有节点的共享信息,在HMaster和HRegionServer连接到ZooKeeper后创建Ephemeral节点,并使用Heartbeat机制维持这个节点的存活状态,如果某个Ephemeral节点实效,则HMaster会收到通知,并做相应的处理。HMaster通过监听ZooKeeper中的Ephemeral节点(默认:/hbase/rs/*)来监控HRegionServer的加入和宕机。在第一个HMaster连接到ZooKeeper时会创建Ephemeral节 点(默认:/hbasae/master)来表示Active的HMaster,其后加进来的HMaster则监听该Ephemeral节点,如果当前Active的HMaster宕机,则该节点消失,因而其他HMaster得到通知,而将自身转换成Active的HMaster,在变为Active的HMaster之前,它会创建在/hbase/back-masters/下创建自己的Ephemeral节点。
2.2 Master
- 管理HRegionServer,实现其region负载均衡。
- 管理和分配HRegion,在HRegion split时分配新的HRegion;在HRegionServer退出时迁移其内的HRegion到其他HRegionServer上。
- 监控集群中所有HRegionServer的状态。
- 实现DDL操作(Data Definition Language,namespace和table的增删改,columnfamiliy的增删改等)。
- 管理namespace和table的元数据(实际存储在HDFS上)。

2.3 RegionServer
- Region server维护Master分配给它的region,处理对这些region的IO请求。
- Region server负责切分在运行过程中变得过大的region。
- HRegionServer一般和DN在同一台机器上运行,实现数据的本地性。
- HRegionServer包含多个HRegion,由WAL(HLog)、BlockCache、MemStore、HFile组成。

3. HBase实际应用案例
需对数据进行随机读操作或者随机写操作。
大数据上高并发操作,比如每秒对PB级数据进行上千次操作。
读写访问均是非常简单的操作。

某移动上网日志查询系统
建设目标
实现客户上网消费账单透明化,即可针对客户投诉或流量质疑等诸多相关数据流量问题实现流量账单明细级查询
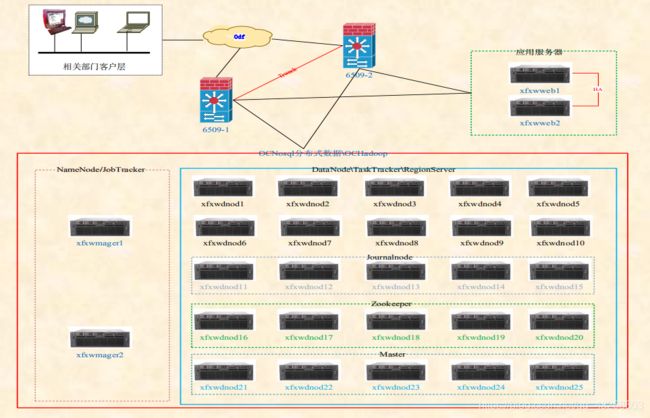
集群介绍
集群规模:2台namenode,25台datanode,2台web查询服务
存储周期:3 + 1,3个月历史数据,1个月实时数据
每月存储量:45T GPRS上网清单日志
查询响应时间:平均在300ms左右

Rowkey设计:
MD5(手机号码)取前三位 + 手机号码 + 开始时间(到秒) + 唯一标识,如:
f9a1860113421020140624234531f059b84aba2e6095,唯一标识是对整条记录取md5值,防止rowkey重复。
建表原则:
每月定期建表,表名为GPRS_yyyyMM,如:GPRS_201407
预建分区:
提前对表进行分区,防止region分裂,北京移动生产环境每张表800个分区
建表方式:
通过crontab定期建未来三个月表,包括hbase表、phoenix表
压缩方式:
采用SNAPPY + PefixTree的压缩方式,HFile文件压缩采用SNAPPY,dataBlock压缩采用PrefixTree,压缩比大概为1:1.6