前后端分离之JWT用户认证
在前后端分离开发时为什么需要用户认证呢?原因是由于 HTTP 协定是不储存状态的(stateless),这意味着当我们透过帐号密码验证一个使用者时,当下一个 request 请求时它就把刚刚的资料忘了。于是我们的程序就不知道谁是谁,就要再验证一次。所以为了保证系统安全,我们就需要验证用户否处于登录状态。
传统方式
前后端分离通过 Restful API 进行数据交互时,如何验证用户的登录信息及权限。在原来的项目中,使用的是最传统也是最简单的方式,前端登录,后端根据用户信息生成一个token,并保存这个 token 和对应的用户 id 到数据库或 Session 中,接着把 token 传给用户,存入浏览器 cookie,之后浏览器请求带上这个 cookie,后端根据这个 cookie 值来查询用户,验证是否过期。
但这样做问题就很多,如果我们的页面出现了 XSS 漏洞,由于 cookie 可以被 JavaScript 读取,XSS 漏洞会导致用户 token 泄露,而作为后端识别用户的标识,cookie 的泄露意味着用户信息不再安全。尽管我们通过转义输出内容,使用 CDN 等可以尽量避免 XSS 注入,但谁也不能保证在大型的项目中不会出现这个问题。
在设置 cookie 的时候,其实你还可以设置 httpOnly 以及 secure 项。设置 httpOnly 后 cookie 将不能被 JS 读取,浏览器会自动的把它加在请求的 header 当中,设置 secure 的话,cookie 就只允许通过 HTTPS 传输。secure 选项可以过滤掉一些使用 HTTP 协议的 XSS 注入,但并不能完全阻止。
httpOnly 选项使得 JS 不能读取到 cookie,那么 XSS 注入的问题也基本不用担心了。但设置 httpOnly 就带来了另一个问题,就是很容易的被 XSRF,即跨站请求伪造。当你浏览器开着这个页面的时候,另一个页面可以很容易的跨站请求这个页面的内容。因为 cookie 默认被发了出去。
另外,如果将验证信息保存在数据库中,后端每次都需要根据token查出用户id,这就增加了数据库的查询和存储开销。若把验证信息保存在 session 中,有加大了服务器端的存储压力。那我们可不可以不要服务器去查询呢?如果我们生成token遵循一定的规律,比如我们使用对称加密算法来加密用户id形成token,那么服务端以后其实只要解密该token就可以知道用户的id是什么了。不过呢,我只是举个例子而已,要是真这么做,只要你的对称加密算法泄露了,其他人可以通过这种加密方式进行伪造token,那么所有用户信息都不再安全了。恩,那用非对称加密算法来做呢,其实现在有个规范就是这样做的,就是我们接下来要介绍的 JWT。
Json Web Token(JWT)
JWT 是一个开放标准(RFC 7519),它定义了一种用于简洁,自包含的用于通信双方之间以 JSON 对象的形式安全传递信息的方法。JWT 可以使用 HMAC 算法或者是 RSA 的公钥密钥对进行签名。它具备两个特点:
- 简洁(Compact):可以通过 URL, POST 参数或者在 HTTP header 发送,因为数据量小,传输速度快
- 自包含(Self-contained):负载中包含了所有用户所需要的信息,避免了多次查询数据库
JWT 组成

Header 头部
头部包含了两部分,token 类型和采用的加密算法
{
"alg": "HS256",
"typ": "JWT"
}
它会使用 Base64 编码组成 JWT 结构的第一部分,如果你使用 Node.js,可以用 Node.js 的包 base64url 来得到这个字符串。
Base64 是一种编码,也就是说,它是可以被翻译回原来的样子来的。它并不是一种加密过程。
Payload 负载
这部分就是我们存放信息的地方了,你可以把用户 ID 等信息放在这里,JWT 规范里面对这部分有进行了比较详细的介绍,常用的由 iss(签发者),exp(过期时间),sub(面向的用户),aud(接收方),iat(签发时间)。
{
"iss": "lion1ou JWT",
"iat": 1441593502,
"exp": 1441594722,
"aud": "www.example.com",
"sub": "[email protected]"
}
同样的,它会使用 Base64 编码组成 JWT 结构的第二部分
Signature 签名
前面两部分都是使用 Base64 进行编码的,即前端可以解开知道里面的信息。Signature 需要使用编码后的 header 和 payload 以及我们提供的一个密钥,然后使用 header 中指定的签名算法(HS256)进行签名。签名的作用是保证 JWT 没有被篡改过。
三个部分通过.连接在一起就是我们的 JWT 了,它可能长这个样子,长度貌似和你的加密算法和私钥有关系。
eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJpZCI6IjU3ZmVmMTY0ZTU0YWY2NGZmYzUzZGJkNSIsInhzcmYiOiI0ZWE1YzUwOGE2NTY2ZTc2MjQwNTQzZjhmZWIwNmZkNDU3Nzc3YmUzOTU0OWM0MDE2NDM2YWZkYTY1ZDIzMzBlIiwiaWF0IjoxNDc2NDI3OTMzfQ.PA3QjeyZSUh7H0GfE0vJaKW4LjKJuC3dVLQiY4hii8s
其实到这一步可能就有人会想了,HTTP 请求总会带上 token,这样这个 token 传来传去占用不必要的带宽啊。如果你这么想了,那你可以去了解下 HTTP2,HTTP2 对头部进行了压缩,相信也解决了这个问题。
签名的目的
最后一步签名的过程,实际上是对头部以及负载内容进行签名,防止内容被窜改。如果有人对头部以及负载的内容解码之后进行修改,再进行编码,最后加上之前的签名组合形成新的 JWT 的话,那么服务器端会判断出新的头部和负载形成的签名和 JWT 附带上的签名是不一样的。如果要对新的头部和负载进行签名,在不知道服务器加密时用的密钥的话,得出来的签名也是不一样的。
信息暴露
在这里大家一定会问一个问题:Base64 是一种编码,是可逆的,那么我的信息不就被暴露了吗?
是的。所以,在 JWT 中,不应该在负载里面加入任何敏感的数据。在上面的例子中,我们传输的是用户的 User ID。这个值实际上不是什么敏感内容,一般情况下被知道也是安全的。但是像密码这样的内容就不能被放在 JWT 中了。如果将用户的密码放在了 JWT 中,那么怀有恶意的第三方通过 Base64 解码就能很快地知道你的密码了。
因此 JWT 适合用于向 Web 应用传递一些非敏感信息。JWT 还经常用于设计用户认证和授权系统,甚至实现 Web 应用的单点登录。
JWT 使用
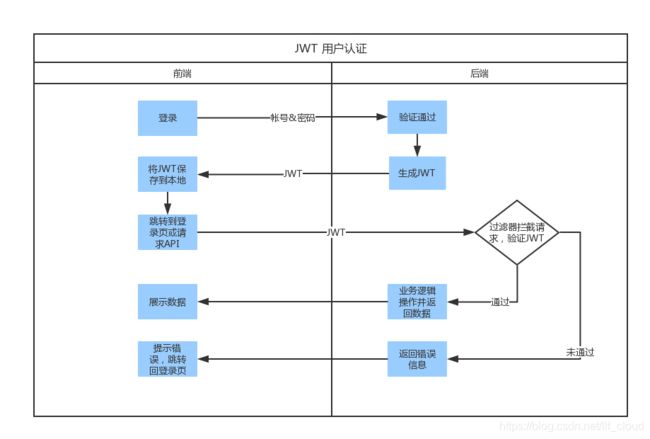
- 首先,前端通过 Web 表单将自己的用户名和密码发送到后端的接口。这一过程一般是一个 HTTP POST 请求。建议的方式是通过 SSL 加密的传输(https 协议),从而避免敏感信息被嗅探。
- 后端核对用户名和密码成功后,将用户的 id 等其他信息作为 JWT Payload(负载),将其与头部分别进行 Base64 编码拼接后签名,形成一个 JWT。形成的 JWT 就是一个形同 lll.zzz.xxx 的字符串。
- 后端将 JWT 字符串作为登录成功的返回结果返回给前端。前端可以将返回的结果保存在 localStorage 或 sessionStorage 上,退出登录时前端删除保存的 JWT 即可。
- 前端在每次请求时将 JWT 放入 HTTP Header 中的 Authorization 位。(解决 XSS 和 XSRF 问题)
- 后端检查是否存在,如存在验证 JWT 的有效性。例如,检查签名是否正确;检查 Token 是否过期;检查 Token 的接收方是否是自己(可选)。
- 验证通过后后端使用 JWT 中包含的用户信息进行其他逻辑操作,返回相应结果。
和 Session 方式存储 id 的差异
Session 方式存储用户 id 的最大弊病在于 Session 是存储在服务器端的,所以需要占用大量服务器内存,对于较大型应用而言可能还要保存许多的状态。一般而言,大型应用还需要借助一些 KV 数据库和一系列缓存机制来实现 Session 的存储。
而 JWT 方式将用户状态分散到了客户端中,可以明显减轻服务端的内存压力。除了用户 id 之外,还可以存储其他的和用户相关的信息,例如该用户是否是管理员、用户所在的分组等。虽说 JWT 方式让服务器有一些计算压力(例如加密、编码和解码),但是这些压力相比磁盘存储而言可能就不算什么了。具体是否采用,需要在不同场景下用数据说话。
单点登录
Session 方式来存储用户 id,一开始用户的 Session 只会存储在一台服务器上。对于有多个子域名的站点,每个子域名至少会对应一台不同的服务器,例如:www.taobao.com,nv.taobao.com,nz.taobao.com,login.taobao.com。所以如果要实现在login.taobao.com登录后,在其他的子域名下依然可以取到 Session,这要求我们在多台服务器上同步 Session。使用 JWT 的方式则没有这个问题的存在,因为用户的状态已经被传送到了客户端。
总结
JWT 的主要作用在于(一)可附带用户信息,后端直接通过 JWT 获取相关信息。(二)使用本地保存,通过 HTTP Header 中的 Authorization 位提交验证。但其实关于 JWT 存放到哪里一直有很多讨论,有人说存放到本地存储,有人说存 cookie。个人偏向于放在本地存储,如果你有什么意见和看法欢迎提出。
nodejs 使用示例
在 node 中需要需要引入两个库
- jsonwebtoken
- koa-jwt
使用jsonwebtoken来加密生成返回给客户端的 token
const jwt = require("jsonwebtoken");
const secret = "aaa"; // 私钥,用于加密时混淆
//jwt生成token
const token = jwt.sign(
{
name: 123,
},
secret,
{
expiresIn: 60, //秒到期时间
}
);
console.log(token);
//解密token
jwt.verify(token, secret, function (err, decoded) {
if (!err) {
console.log(decoded.name); //会输出123,如果过了60秒,则有错误。
}
});
我们看看 jwt.sign 生成的 token:
eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJuYW1lIjoxMjMsImlhdCI6MTQ5MTQ3NTQyNCwiZXhwIjoxNDkxNDc1NDg0fQ.hYNC4qFAyhZClmPaLixfN137d41R2CFk1xPlfLK10JU
我们仔细看这字符串,分为三段。分别被 “.” 隔开。我们对:eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9 由 base64 解密得到
{“alg”:“HS256”,“typ”:“JWT”} alg 是加密算法名字,typ 是类型
这段: eyJuYW1lIjoxMjMsImlhdCI6MTQ5MTQ3NTQyNCwiZXhwIjoxNDkxNDc1NDg0fQ 由 base64 解密得到: {“name”:123,“iat”:1491475424,“exp”:1491475484} name 是我们储存的内容,但是多了 iat(创建的时间戳),exp(到期时间戳)。
最后一段是hYNC4qFAyhZClmPaLixfN137d41R2CFk1xPlfLK10JU,是由前面俩段字符串 HS256 加密后得到。 所以前面的任何一个字段修改,都会导致加密后的字符串不匹配。
参考:
- Node 實作 jwt 驗證 API
- JWT 在前后端分离中的应用与实践
关于前后端分离鉴权的思考
drf
Django==1.x
Django>=2.x