Python数据挖掘实战篇:利用KNN进行电影分类
题目
下面数据集中序号1-12为已知的电影分类,分为喜剧片、动作片、爱情片三个种类,使用的特征值分别为搞笑镜头、打斗镜头、拥抱镜头的数量。那么来了一部新电影《万里归途》,它属于上述3个电影分类中的哪个类型?用KNN是怎么做的呢?
已知万里归途的搞笑镜头是23个,拥抱镜头是3个,打斗镜头是17个。
运行代码
import numpy as np
import math
def createDataset():
# 数据集
movie_data = {"宝贝当家": [45, 2, 9, "喜剧片"],
"美人鱼": [21, 17, 5, "喜剧片"],
"澳门风云3": [54, 9, 11, "喜剧片"],
"功夫熊猫3": [39, 0, 31, "喜剧片"],
"谍影重重": [5, 2, 57, "动作片"],
"叶问3": [3, 2, 65, "动作片"],
"伦敦陷落": [2, 3, 55, "动作片"],
"我的特工爷爷": [6, 4, 21, "动作片"],
"奔爱": [7, 46, 4, "爱情片"],
"夜孔雀": [9, 39, 8, "爱情片"],
"代理情人": [9, 38, 2, "爱情片"],
"新步步惊心": [8, 34, 17, "爱情片"]}
return movie_data
def kNN(movie_data, dataPoint, k):
x=[23,3,17]
# 1:计算一个新样本与数据集中所有数据的距离
disList = []
for key, v in movie_data.items():
# 对距离进行平方和开根号
# d = np.linalg.norm(np.array(v[:3]) - np.array(dataPoint))
d=math.sqrt((v[0]-x[0])**2+(v[1]-x[1])**2+(v[2]-x[2])**2)
#四舍五入保留两位小数添加到集合中
disList.append([key, round(d, 2)])
# 2:按照距离大小进行递增排序
disList.sort(key=lambda dis: dis[1]) # 常规排序方法,熟悉key的作用
# 3:选取距离最小的k个样本
disList = disList[:k]
# 4:确定前k个样本所在类别出现的频率,并输出出现频率最高的类别
labels = {"喜剧片": 0, "动作片": 0, "爱情片": 0}
# 从k个中进行统计哪个类别标签最多
for s in disList:
# 取出对应标签
label = movie_data[s[0]]
labels[label[len(label) - 1]] += 1
labels = sorted(labels.items(), key=lambda asd: asd[1], reverse=True)
return labels, labels[0][0]
if __name__ == '__main__':
movie_data = createDataset()
testData = {"万里归途": [23, 3, 17, "?片"]}
dataPoint = list(testData.values())[0][0:3]
k = 5
labels, result = kNN(movie_data, dataPoint, k)
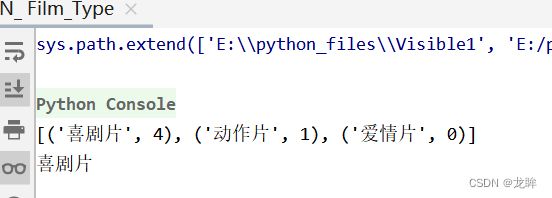
print(labels, result, sep='\n')
运行结果