python简单读取和索引.nc文件(气象小白入门版)
一、总代码
#数据下载,这里下载的是NCEP的气压数据,在命令行运行代码即可
#wget -P /mnt/g/st_touchfish_py/data ftp://ftp.cdc.noaa.gov/Datasets/ncep.reanalysis.derived/pressure/air.mon.mean.nc
import xarray as xr
import pandas as pd
import numpy as np
#用xarray库读入文件
file = xr.open_dataset('/mnt/g/st_touchfish_py/data/air.mon.mean.nc')
#print一下文件看看都有啥
print(file)
#dataarray文件包含四部分~维度DIMS&坐标cord--经度、纬度、高度、时间;值VALUE--气压;属性attributes:文件信息...
#索引的顺序不能颠倒,可通过print(file.air)查看顺序
print(file.air)
air_00_20 = file.air.loc['2000-01-01':'2020-12-31',500,:,:]
print(air_00_20)
#检查格式:若是datatime格式则可以分年、月、日索引
print(air_00_20.time)
air_00_20_sum = air_00_20.loc[air_00_20.time.dt.month.isin([6,7,8])]
print(air_00_20_sum)二、代码解释
(1)NECP气象数据下载
wget -P /mnt/g/st_touchfish_py/data ftp://ftp.cdc.noaa.gov/Datasets/ncep.reanalysis.derived/pressure/air.mon.mean.nc注意:/mnt/g/st_touchfish_py/data是存放文件的路径,改成自己的噢
(2)下载相应库
这里用到了三个库xarray pandas numpy(xarray是基于pandas建立的,两者很相似;numpy很常用,涉及处理数组都会用到)
#导入相应的库
import xarray as xr
import pandas as pd
import numpy as np如果命令行提示“No Model xxx”,就是没有安装对应的库。安装上就好了。
比如缺少xarray和pandas,直接在命令行里面运行:conda install -c conda-forge xarray pandas
(如果上述命令不行,尝试pip install xarray)
(3)读入文件并查看文件内容
#用xarray库读入文件
file = xr.open_dataset('/mnt/g/st_touchfish_py/data/air.mon.mean.nc')
#print一下文件看看都有啥
print(file)
#dataarray文件包含四部分~维度DIMS&坐标cord--经度、纬度、高度、时间;值VALUE--气压;属性attributes:文件信息...
运行结果:
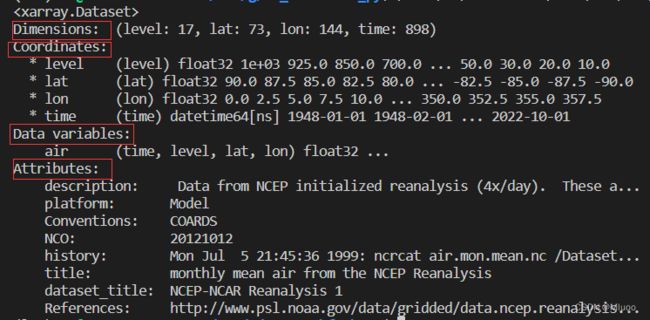
可以看到这是xarray读进来的数据集:
内容就是红框的四部分。
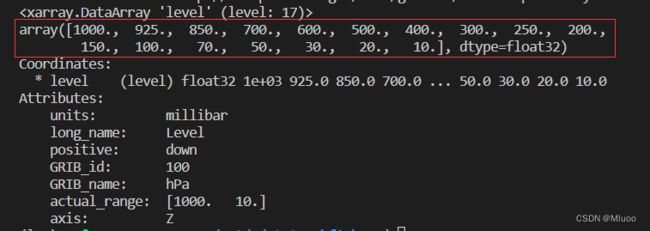
首先是维度,有四个,每个维度的数字就代表有几个值,比如level:17就是有17个高度值,想要具体看看是什么值,可以print一下
print(file.level)如下图红框,17个高度值就存在数组中
(4)索引文件(时间/高度/经纬度)
#索引的顺序不能颠倒,可通过print(file.air)查看顺序
print(file.air)
air_00_20 = file.air.loc['2000-01-01':'2020-12-31',500,:,:]
print(air_00_20)
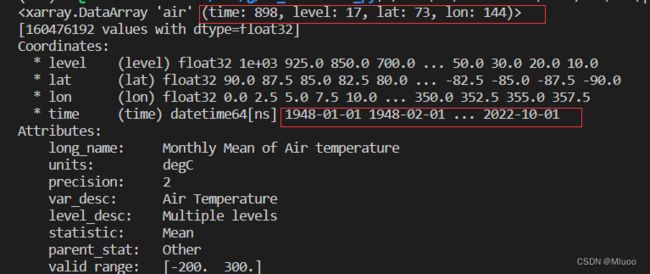
print(file.air)运行结果如下图所示,可以看到属性存放的顺序是:时间-->高度-->纬度-->经度,索引的时候一定要按照这个顺序写约束。
这里的顺序指的是两方面:一个是属性存放的顺序(时间是第一个,高度是第二个...),还有每个属性中的数据存放的顺序(时间属性中,1948排在1949前面)。
这两个顺序在写索引的时候都不能颠倒。
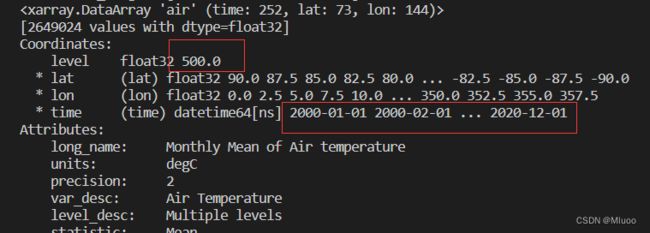
loc函数就是用于索引的,比如要提取2000年到2020年,高度为500的所有气压数据,就可以写成
air_00_20 = file.air.loc['2000-01-01':'2020-12-31',500,:,:](而如果写成 air_00_20 = file.air.loc[500,'2000-01-01':'2020-12-31',:,:]就没遵循不同属性的顺序
写成air_00_20 = file.air.loc['2020-01-01':'2000-12-31',500,:,:]就没遵循某一个属性的具体值的存放顺序)
print一下 air_00_20:可以看到已经把对应的时间范围 和 高度 =500提取出来了
附:如果数据是datetime格式,还可以这么索引
#若是datetime格式则可以分年、月、日索引
#检查格式
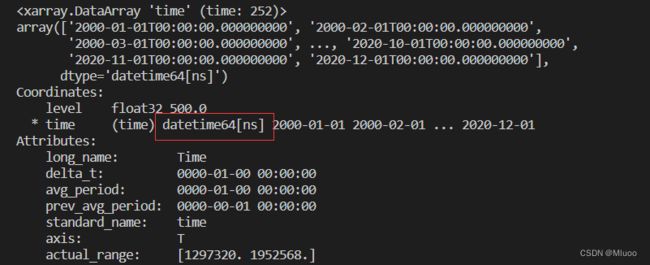
print(air_00_20.time)
air_00_20_sum = air_00_20.loc[air_00_20.time.dt.month.isin([6,7,8])]
print(air_00_20_sum)先看看变量的格式:print(air_00_20.time),下图可以看到是datetime格式,则可以使用dt.month进行月份的索引,写法如上述代码所示。
输出结果:将6/7/8月的值提取了出来。
