K1 PowerLinux使能K8s管理GPU容器
K1 PowerLinux使能K8s管理GPU容器
本篇文档内容包含K8S开源容器管理平台结合Docker容器,结合免费的在Power上优化的深度学习和机器学习的docker镜像WMLCE,给客户提供Jupyter的环境,提供持续持续开发持续集成的不间断服务。并且能按照单个GPU卡的量级来分配资源。与通常的x86通用2u服务器不同的是,这里采用的是K1 PowerLinux服务器,使用Power9 CPU。最后引用一个实际的客户使用例子容器化的方式配合Power的独特硬件特性获得的独特价值。由于偏操作类,这里主要突出的是K8s使能GPU容器,其他详细内容可以参考之前文章。
背景
os rhel-alt-server-7.6-ppc64le-dvd.iso
s822lc-05 (minksy)4P100 GPU
在K1 PowerLinux上配置 GPU环境
参考链接(非本篇文章重点):
https://www.ibm.com/support/knowledgecenter/SS5SF7_1.6.2/navigation/wmlce_setupRHEL.html
主要内容摘录如下:
安装操作系统 rhel-alt-server-7.6-ppc64le-dvd.iso
升级内核,安装依赖包。
yum update kernel kernel-devel kernel-tools kernel-tools-libs kernel-bootwrapper
yum -y install dkms-2.7.1-1.el7.noarch.rpm
更改内存显示规则(只针对rhel7 Power9的服务器)
cp /lib/udev/rules.d/40-redhat.rules /etc/udev/rules.d/
更改内存显示规则(只针对rhel7 Power9的服务器)
vi /etc/udev/rules.d/40-redhat.rules
# Memory hotadd request
#SUBSYSTEM!="memory", ACTION!="add", GOTO="memory_hotplug_end"
#PROGRAM="/bin/uname -p", RESULT=="s390*",GOTO="memory_hotplug_end"
#ENV{.state}="online"
#PROGRAM="/bin/systemd-detect-virt", RESULT=="none", ENV{.state}="online_movable"
#ATTR{state}=="offline", ATTR{state}="$env{.state}"
#LABEL="memory_hotplug_end"
下载nvidia驱动,注意选择ppc64le rhel7的版本

rpm -ivh nvidia-driver-local-repo-rhel7-418.*.rpm
yum install nvidia-driver-latest-dkms
systemctl enable nvidia-persistenced
reboot
在K1 PowerLinux上配置K8S环境
这部分内容具体请参照K8S离线安装方法,请参照本博客其他文章。
部署 kubernetes-dashboard
为了便于K8s管理,部署dashboard,非此篇文章的重点,如果查看详细部署过程请参照本博客其他文章。
创建 docker 私有仓库
yum install -y docker-distribution docker
mkdir -p /data/history/
cat > /etc/docker-distribution/registry/config.yml <<- 'EOF'
version: 0.1
log:
fields:
service: registry
storage:
cache:
layerinfo: inmemory
filesystem:
rootdirectory: /data/history
delete:
enabled: true
http:
addr: :5000
EOF
在/usr/lib/systemd/system/docker.service 中添加 docker 启动参数cn01:5000, cn01就是docker仓库节点的hostname:
cat /usr/lib/systemd/system/docker.service
[Unit]
Description=Docker Application Container Engine
Documentation=https://docs.docker.com
After=network-online.target firewalld.service
Wants=network-online.target
[Service]
Type=notify
# the default is not to use systemd for cgroups because the
delegate issues still
# exists and systemd currently does not support the cgroup
feature set required
# for containers run by docker
ExecStart=/usr/bin/dockerd --insecure-registry cn01:5000
ExecReload=/bin/kill -s HUP $MAINPID
# Having non-zero Limit*s causes performance problems due to
accounting overhead
# in the kernel. We recommend using cgroups to do container-local
accounting.
LimitNOFILE=infinity
LimitNPROC=infinity
LimitCORE=infinity
# Uncomment TasksMax if your systemd version supports it.
# Only systemd 226 and above support this version.
#TasksMax=infinity
TimeoutStartSec=0
# set delegate yes so that systemd does not reset the cgroups of
docker containers
Delegate=yes
# kill only the docker process, not all processes in the cgroup
KillMode=process
# restart the docker process if it exits prematurely
Restart=on-failure
StartLimitBurst=3
StartLimitInterval=60s
[Install]
WantedBy=multi-user.target
重启docker服务
systemctl daemon-reload
systemctl restart docker
systemctl restart docker-distribution
systemctl enable docker-distribution
测试验证
docker load -i load –I nginx.tar
docker tag nginx cn01:5000/nginx
curl cn01:5000/v2/_catalog
 如果是其他k8s的节点,请修改docker的配置文件指向私有镜像仓库。
如果是其他k8s的节点,请修改docker的配置文件指向私有镜像仓库。
关于获得WMLCE的docker 镜像
将WMLCE下载好的tar文件导入到私有仓库中。(1次下载多次使用)
docker load -i wmlce162.tar
K1 PowerLinux 部署GPU容器云平台框架
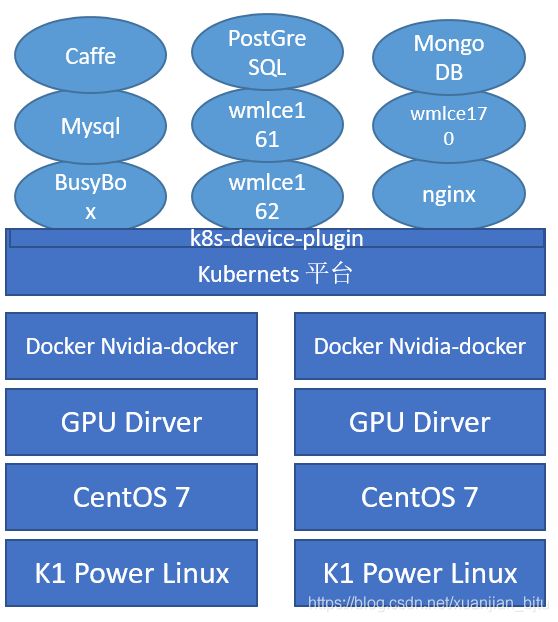
使用全开源的软件方式部署GPU容器云平台,底层是K1 Power的硬件服务器,上层安装CentOS操作系统。在系统中安装GPU驱动,设备成功识别,并可被使用。之上再安装docker和Nvidia docker,CentOS中Nvidia-docker不能直接通过yum安装,可以安装container-tools container-runtime和container-runtime-hook软件包。在之上为了让K8s管理GPU容器,需要在K8s容器云管理平台安装后创建k8s-devce-plugin容器。之后可通过Doker网上仓库或者私有仓库部署所需容器,包括不同CUDA版本、不同框架版本的GPU容器。
K8s enable GPU docker images
要想在K8s中使用含有GPU资源的镜像,如下图中所示的逻辑,我们需要打通几个关键步骤。Host上要有Nvidia驱动、docker、nvidia-docker(红帽不能直接安装,需要修改runtime)。同时需要一个nvidia plugin的容器。

安装nvidia-docker2
yum -y install libnvidia-container-tools-1.0.0-1.ppc64le.rpm libnvidia-container1-1.0.0-1.ppc64le.rpm nvidia-container-runtime-2.0.0-1.docker18.03.1.ppc64le.rpm nvidia-container-runtime-hook-1.4.0-2.ppc64le.rpm
更改runtime为nvidia-runc
[root@cn01 ~]# cat /etc/docker/daemon.json
{
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
},
"storage-driver": "overlay2",
"storage-opts": [
"overlay2.override_kernel_check=true"
],
"default-runtime":"nvidia",
"runtimes":{
"nvidia":{
"path":"/usr/bin/nvidia-container-runtime",
"runtimeArgs":[]
}
}
}
验证nvidia-runtime

部署k8s-device-plugin
下载k8s-device-plugin的容器,并通过kubectl创建Damonset
docker pull nvidia/k8s-device-plugin:1.11-ubuntu16.04
docker save nvidia/k8s-device-plugin:1.11-ubuntu16.04 -o k8s-device-plugin-1.11.tar
docker load -i k8s-device-plugin-1.11.tar
docker tag nvidia/k8s-device-plugin:1.11-ubuntu16.04 cn01:5000/k8s-device-plugin
docker push nvidia/k8s-device-plugin:1.11-ubuntu16.04
kubectl create -f nvidia-device-plugin.yml
nvidia-device-plugin.yml 在https://github.com/NVIDIA/k8s-device-plugin/blob/master/nvidia-device-plugin.yml
nvidia plugin images https://hub.docker.com/r/nvidia/k8s-device-plugin/tags?page=1

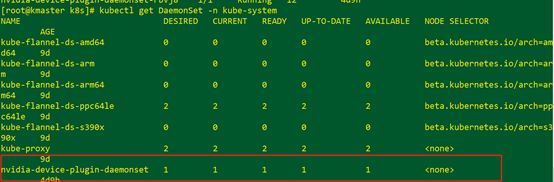
K8s创建WMLCE容器
kubectl create -f powerai162.yml
[root@kmaster k8s]# cat powerai162.yml
apiVersion: v1
kind: Pod
metadata:
name: powerai162-gpu
spec:
containers:
- name: powerai162-test
image: cn01:5000/powerai
command: ['sh','-c','while true;do sleep 2;done;']
resources:
limits:
nvidia.com/gpu: 1 # requesting 1 GPUs
volumeMounts:
- name: powerai
mountPath: /powerai
env:
- name: LICENSE
value: "yes"
volumes:
- name: powerai
hostPath:
path: /root/powerai
验证
Dashboard中可以看到Powerai162的进行已经起来,并被监控。

验证WMLCE镜像
[root@kmaster k8s]# kubectl exec -it powerai162-gpu -- bash
进入容器操作
[root@kmaster k8s]# git clone https://github.com/IBM/powerai/powerai/examples/tensorflow_large_model_support/v2
[root@kmaster k8s]# python Keras_ResNet50.py --image_size 2500
报OOM的错误,超过GPU显存,激活Power上的LMS特性,这样可以在训练过程中,将一部分内存当做显存使用。又由于Power上CPU到GPU之间是NVLink链接,非x86上的PCIe的总线。具体数据可以参考其他文章。
[root@kmaster k8s]# python Keras_ResNet50.py --show_tensors_on_oom --image_size 2500 --lms
可以顺利运行,可以运行python Keras_ResNet50.py --help查看可以加的参数
K8s调度生效,目前容器中只能看到2个GPU。

配置jupyter Notebook
在容器中,有可能上面安装的时候已经安装完了
conda install jupyter notebook
要想远程登录jupyter notebook需要生成配置文件
jupyter notebook --generate-config
用ipython或者其他生成一个密文的密码
In [1]: from notebook.auth import passwd
In [2]: passwd()
Enter password:
Verify password:
Out[2]: 'sha1:ce23d945972f:34769685a7ccd3d08c84a18c63968a41f1140274'
把生成的密文‘sha:ce....’复制下来
In [3]:quit()
修改默认的配置文件
vim ~/.jupyter/jupyter_notebook_config.py
进行如下修改:
c.NotebookApp.ip='*'
c.NotebookApp.password = u'sha:ce...刚才复制的那个密文'
c.NotebookApp.open_browser = False
c.NotebookApp.port =8888 #随便指定一个端口
jupyter notebook --ip=0.0.0.0 --allow-root
此时应该可以直接从本地浏览器直接访问http://address_of_remote:8888就可以看到jupyter的登陆界面。
建立ssh通道
如果登陆失败,则有可能是服务器防火墙设置的问题,此时最简单的方法是在本地建立一个ssh通道:
在本地终端中输入ssh username@address_of_remote -L127.0.0.1127.0.0.1:8888
便可以在localhost:1234直接访问远程的jupyter了。
K1PowerLinux容器中客户使用实例
实例准备
已实现单机多卡多实例分配资源,可动态分配公网链路和端口,自动化启动在线调试和远程访问服务,支持jupyter ,pycharm调试。
实例开启截图:
实例运行截图1:

实例运行截图2:
客户在实例中使用LMS的工具库,配合Power硬件CPU到GPU、GPU到GPU之间的全NVlink,在其他条件一致的情况下可以设置更大的batch_size,或者是在其他信息一致的情况下放置更高分辨率的图像在训练中,使得科研人员能够获得更多特征,得到更准确的模型。
下例子中,客户在没有LMS情况下,B_S=96,128就会出现OOM的错误。
实例
- 数据集HMDB51 (已处理,不需要做任何修改)
- 网络训练:root/P3D/network_train.py (只测试的话不需要修改)
- 网络测试:root/P3D/network_test.py (只测试的话不需要修改)
- 网络参数:root/P3D/utils.py (可以修改Batch_Size等参数)
- 运行环境:经测试可以直接运行。
- Tips: 默认情况不调用LMS服务,需要的话修改network_train中main函数里的enable=True。
关于显卡使用情况: - Video frame (16,160,160)
- 单块GPU
- 模型:P3D,数据集:HMDB51
- B_S=8:6060MB/32510MB
- B_S=64: 30496MB/32510MB,能放下1024(64*16)张图
- B_S= 96,128 , out of memory。
- 单卡最多可以放下1024160160的图像数据。
参考链接:
http://docs.kubernetes.org.cn/429.html
https://www.cnblogs.com/nmap/p/9384398.html
https://blog.csdn.net/wenwst/article/details/54913311
https://www.cnblogs.com/yangxiaolan/p/5778305.html
https://mirrors.tripadvisor.com/centos-vault/altarch/7.6.1810/isos/power9/