百度BaikalDB在同程艺龙的成功应用实践剖析

导读:文章主要介绍 BaikalDB在同程艺龙的完整落地实践,文章把BaikalDB总结为六个核心特性,分别是《BaikalDB高可用与HTAP特性实践》、《BaikalDB 高性能与扩展性实践》、《BaikalDB 低成本的思考》,希望对大家有帮助。
全文14032字,预计阅读时间 19分钟。
一、BaikalDB高可用与HTAP特性实践
我们从2019年开始调研开源NewSQL数据库BaikalDB,尝试解决工作中遇到的一些实际问题,例如OLAP业务跑在行存数据库上查询速度慢,数据库跨中心部署高可用方案待完善,在近6个月的研究与实践中,我们向社区提交了列存特性,并使用BaikalDB分别部署了基于列存的OLAP类业务,基于行存的OLTP类业务,及基于双中心的高可用部署方案,有效的解决了相关问题,在这里做一个相关使用经验的分享,希望可以给遇到类似问题的同学提供参考。
1、BaikalDB选型考虑
1.1业界纷纷布局NewSQL
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RBCgkuB1-1628562967350)(https://p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/5207a0b1736442c6b4e9342c0be88b48~tplv-k3u1fbpfcp-zoom-1.image “业界布局”)]
1.2 NewSQL数据库核心技术对比
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GI51mYtA-1628562967351)(https://p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/98f230590169431b8de02d9043703ad0~tplv-k3u1fbpfcp-zoom-1.image “数据库产品比较”)]
-
注1:ShardingSphere基于MySQL MGR的Paxos复制协议尚未发布。
-
注2:TiDB 3.0起已同时支持乐观事务与悲观事务。
-
注3:由于笔者精力所限,尚有很多NewSQL未参与对比:Amazon Aurora,Aliyun PolarDB, AnalyticDB,Apple FoundationDB, CockroachDB, 华为GaussDB, Yandex ClickHouse等。
1.3 NewSQL技术选型
路径选择:
-
纯自研:能力有限,投入有限
-
纯开源:无法及时满足定制化需求
-
云服务:安全与成本考虑,短期内核心业务自建IDC,k8s化
-
半自研:我们的选择,不重复造轮子,主体功能交由社区完成,集中有限力量满足公司需求,可供选择的NewSQL有:TiDB,BaikalDB,CockRoachDB等。
从以上几款开源DB中,最终选择BaikalDB的原因有:
-
背景相似:BaikalDB来源于百度凤巢广告业务团队,由于广告业务的增长走过了从单机到分库分表到分布式的全过程,而我们面临类似的问题。
-
经受考验:已经有百度广告平台多个业务实际使用经验,千级别集群节点,PB级数据规模,我们跟进使用,风险可控。
-
技术栈匹配:BaikalDB(c++实现, 10万行代码精炼),依赖少而精(brpc,braft,rocksdb),社区友好,部署简单,技术栈匹配。
-
特性比较完善:基本满足我们需求,我们可以专注于满足公司需求。
1.4 BaikalDB简介
BaikalDB是一款百度开源(github.com/baidu/BaikalDB )分布式关系型HTAP数据库。支持PB级结构化数据的随机实时读写。
架构如下:
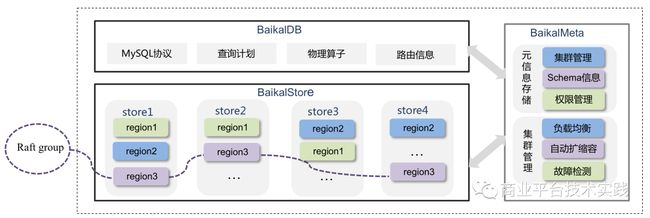
其中:
-
BaikalStore 负责数据存储,用 region 组织,三个 Store 的 三个region形成一个 Raft group 实现三副本,多实例部署,Store实例宕机可以自动迁移 Region数据。
-
BaikalMeta 负责元信息管理,包括分区,容量,权限,均衡等,Raft保障的3副本部署,Meta 宕机只影响数据无法扩容迁移,不影响数据读写。
-
BaikalDB 负责前端SQL解析,查询计划生成执行,无状态全同构多实例部署,宕机实例数不超过 qps 承载极限即可。
核心特性:
-
强一致:实现Read Committed 级别的分布式事务,保证数据库的ACID 特性
-
高可用:Multi Raft协议保证数据多副本一致性,少数节点故障自愈, 支持跨机房部署,异地多活,可用性>99.99%, RTO=0, RPO<30s
-
高扩展:Share-nothing架构,存储与计算分离, 在线缩扩容不停服 5分钟内完成,动态变更schema 30s生效
-
高性能:表1000张,单表:10亿行,1千列情况下:QPS >1W 点查 P95 < 100ms
-
易用性:兼容MySQL 5.6协议
2、BaikalDB线上迁移过程
我们在线上已部署了50个存储节点百亿行数据规模的BaikalDB集群,本章将重点讲述业务迁移到BaikalDB的步骤以确保上线过程平稳与业务无缝迁移。整体的上线过程可分为如下几个阶段:
2.1 列存特性开发
由于我们上线的首个业务是分析类业务,适合列式存储,在社区的帮助与指导下,我们开发并提交了列存特性,原理见列式存储引擎
2.2 配套运维工具
-
部署工具:线上暂以自研部署脚本为主,未来会对接公司k8s;
-
监控工具:Prometheus,BaikalDB对接Prometheus非常简单,参见监控指标导出到Prometheus
-
数据同步工具:Canal + 数据同步平台,原理类似不再展开;
-
物理备份工具:SSTBackup,使用说明见基于SST的备份与恢复 ,可以实现全量+增量的物理备份,内部数据格式,仅适用于BaikalDB;
-
逻辑备份工具:BaikalDumper,模拟MySQLDumper,导出的是SQL语句,可以导入到其他数据库,目前只支持全量导出;
-
测试工具:Sysbench 使用说明见BaikalDB Sysbench
-
欠缺的工具:基于MySQL binlog的数据订阅工具,开发中。
2.3 数据迁移
数据同步采用全量+增量同步方式,全量采用批量插入,增量原理类似于MySQL binlog订阅,采用Replace模式同步。共计80亿条数据全量同步约3天,增量同步稳定在10ms以内。
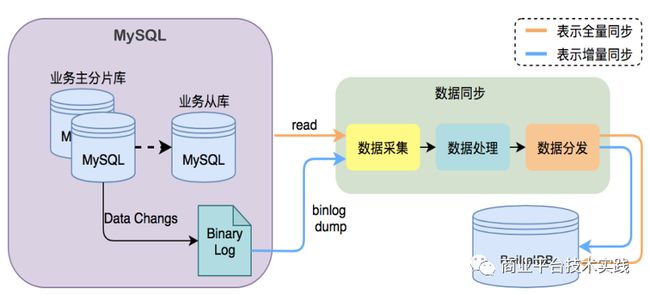
2.4 业务测试
经过数据同步环节,BaikalDB已经具备与线上等价数据集,业务测试阶段重点在于对待上线系统真实SQL的支持能力,我们采用全流量回放的方式进行。
如下图:
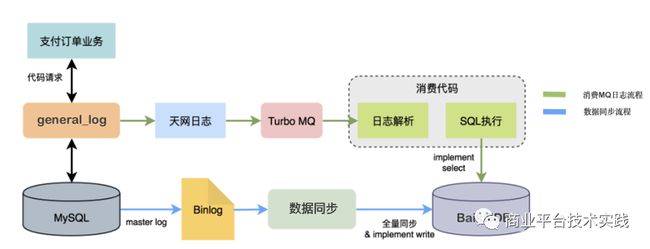
通过实时回放线上真实流量我们主要验证了:
-
业务使用SQL的100%兼容性
-
业务峰值的性能承载能力
-
7*24小时的稳定性
2.5 业务上线
经过以上环节,业务上线需要的唯一操作就是更改数据库连接配置。
2.6 运维与监控
下图是上线后部分指标Prometheus监控截图,可以看到从qps,响应时间,环比变化看均十分平稳。



2.7 注意事项
BaikalDB尚在完善的功能:
-
子查询:开发中
-
information_schema:图形化工具支持与系统变量支持不全,开发中
-
行列并存:一张表可选择行存或列存,但不能并存,开发中
-
分布式时钟:影响事务隔离级别,与Follower一致性读,开发中
-
视图:排期中
-
触发器,存储过程等传统关系型数据库功能,暂无规划
使用BaikalDB需要注意的事项:
-
数据建模:DB并不能取代数据库使用者的角色,好的数据模型,表结构的设计,主键与索引的使用,SQL语句,在我们实际测试中比坏的用法会有10倍以上的提升;
-
写放大:与RocksDB层数有关,建议单store数据大小控制在1T以内;
-
参数调优:默认配置已非常合理,仅有少量参数建议根据实际情况修改:
export TCMALLOC_SAMPLE_PARAMETER=524288 #512kexport TCMALLOC_MAX_TOTAL_THREAD_CACHE_BYTES=209715200 #200M,当大value时,调大可以避免线程竞争,提高性能-bthread_concurrency=200 # 建议(cpu核数- 4)* 10-low_query_timeout_s=60 # 慢查询阈值,建议根据需求设置-peer_balance_by_ip=false # 默认为false,单机多实例时建议开启-max_background_jobs = 24 #建议(cpu核数- 4)-cache_size = 64M #建议不超过单实例内存空间40%
-
大事务限制:行锁限制:per_txn_max_num_locks 默认100w;DB与Store RPC 包的大小限制:max_body_size默认256M;消息体限制:max protobuf size =2G,此为protobuf限制不可修改。一般建议事务影响行数不超过10M;
-
双机房资源预留Buffer:资源使用率建议40%左右,容灾时单机房需要承载double的压力,分配副本时disk_used_percent 超过80%的store将被剔除。
3、高可用与HTAP部署方案
我们的BaikalDB一套集群部署在两个城市4个IDC机房,同时支撑基于行存的OLTP业务与基于列存的OLAP业务,本章将说明我们是如何通过设计部署方案来发挥BaikalDB高可用与HTAP能力的。
双中心HTAP部署示意图:
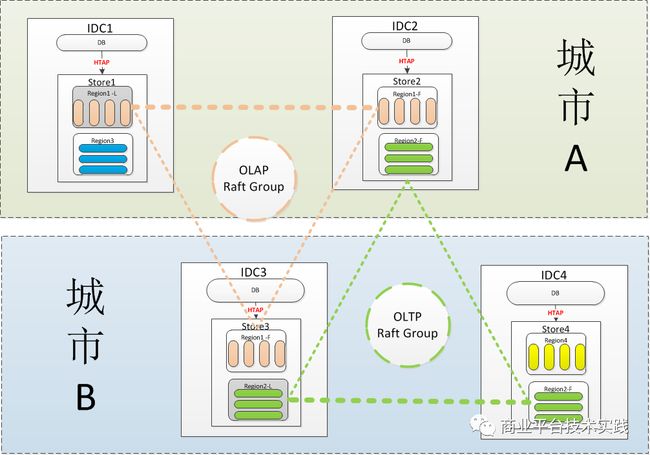
-
注1:图中省去了meta节点部署
-
注2:每个IDC会实际部署了多个store与db节点。
如上图城市 A与城市 B双中心采用完全对称的部署结构,在BaikalDB里Region是存储的基本单位,每张表至少有一个Region组成,每个Region有若干个peer合在一起构成了一组Raft Group。每个store即可创建行存表也可以创建列存表,业务建表时可以根据场景的不同进行选择,另外业务也可以根据地域的不同选择副本的分布,例如城市 A的业务可以选择城市 A 2副本+城市 B 1副本,城市 B的业务可以选择城市 A 1副本+城市 B 2副本。
假设有2家业务在使用BaikalDB集群,业务A是一个部署在城市 A的OLAP类业务创建了表ctable用Region1代表。业务B是一个部署在城市 B的OLTP类业务创建了表rtable用Region2代表。则相关的配置过程如下:
- 初始化meta机房信息
echo -e "场景:添加逻辑机房bj sz\n"curl -d '{"op_type": "OP_ADD_LOGICAL","logical_rooms": {"logical_rooms" : ["bj", "sz"]}}' http://$1/MetaService/meta_managerecho -e "插入bj物理机房\n"curl -d '{"op_type": "OP_ADD_PHYSICAL","physical_rooms": {"logical_room" : "bj","physical_rooms" : ["bj1","bj2"]}}' http://$1/MetaService/meta_managerecho -e "\n"echo -e "插入sz物理机房\n"curl -d '{"op_type": "OP_ADD_PHYSICAL","physical_rooms": {"logical_room" : "sz","physical_rooms" : ["sz1","sz2"]}}' http://$1/MetaService/meta_manager
- 设置每个baikalstore的物理机房信息
#IDC1 store的机房信息配置#vim store/conf/gflag-default_physical_room=bj1
- 设置每个baikaldb的物理机房信息
#IDC1 db的机房信息配置#vim db/conf/gflag-default_physical_room=bj1
- 创建表时根据需要指定副本策略与存储类型
--业务A是一家部署在城市 A的OLAP类型请求采用列存表,建表语句如下:CREATE TABLE `TestDB`.`ctable` (`N_NATIONKEY` INTEGER NOT NULL,`N_NAME` CHAR(25) NOT NULL,`N_REGIONKEY` INTEGER NOT NULL,`N_COMMENT` VARCHAR(152),PRIMARY KEY (`N_NATIONKEY`))ENGINE=Rocksdb_cstore COMMENT='{"comment":"这是一张列存表", "resource_tag":"bizA", "namespace":"TEST_NAMESPACE","dists": [ {"logical_room":"bj", "count":2}, {"logical_room":"sz", "count":1}] }';--业务B是一家部署在城市 B的OLTP类型请求采用行存表,建表语句如下:CREATE TABLE `TestDB`.`rtable` (`N_NATIONKEY` INTEGER NOT NULL,`N_NAME` CHAR(25) NOT NULL,`N_REGIONKEY` INTEGER NOT NULL,`N_COMMENT` VARCHAR(152),PRIMARY KEY (`N_NATIONKEY`))ENGINE=Rocksdb COMMENT='{"comment":"这是一张行存表", "resource_tag":"bizB", "namespace":"TEST_NAMESPACE","dists": [ {"logical_room":"bj", "count":1}, {"logical_room":"sz", "count":2}] }';
优点:
-
容灾能力:任何少数节点故障,无论是机器级,机房级还是城市级故障,均可做到RPO(数据丢失时长) = 0s,RTO(数据恢复时长)< 30s。
-
Async Write:由于Raft多数Peer写成功即可返回,虽然3peer会有1个peer分布在另一个城市存在延迟,但写操作一般写完同城的2个peer即可,异地的peer在进行异步写,写性能接近同城写性能。
-
Follower Read:由于每个城市至少有一个副本,对于读业务需要分别部署在两个城市的场景,BaikalDB提供了就近读功能,路由选择时会优先选择与DB同在一个逻辑机房的Region进行读操作,所以读性能可以在两地均得到保证。
-
HTAP能力:业务可以根据业务场景分别选择行存表与列存表,每个store可以同时支持这两种表。
-
资源隔离:如果担心HTAP的业务workload会互相影响,业务可以通过resource_tag字段对store进行分组,例如store1的resource_tag = bizA, 那么store1只会给建表时指定resource_tag = bizA的表分配Region。
待完善:
-
容灾能力:多数节点故障RPO最大可到3s,BaikalDB副本的分配策略后续可以增加降级策略,如果多数机房故障,降级到在少数机房分配副本,从而保证RPO依旧为0。
-
Async Write:当写发生在少数城市时依旧会存在延迟,但这种情况实际业务很少发生;如确有需要例如两地业务均需对同一张表发生写操作,必然有一个处于异地写状态,这种情况建议写时拆成两张表,读时用Union或视图。
-
Follower Read:可以增强为Follower一致性读。就是对Follower可能落后与Leader的请求进行补偿,需要分布式时钟特性(开发中)的支持。
二、BaikalDB 高性能和扩展性实践
 核心特性
核心特性
这也是我们在业务推广中的关注次序,即
-
首先必须(Must to)业务场景匹配精 准(1一致性)和运行平稳(2高可用)
-
其次最好(Had better)是数据多(3扩展性)与跑的快(4高性能)
-
最后应该是(Should)使用友好(5高兼容性)与 成本节省(6低成本)
简称:稳准多快好省。
本文将会通过介绍业务落地前的两个实际测试案例,来分享总结BaikalDB在性能与扩展性方面的数据。
1、基于行存OLTP场景的基准测试
1.1测试目标
如果把BaikalDB看成一款产品,基准测试的目的就是加上一份产品规格说明书,在性能测试同学的参与下,我们进行了为期2个月的基准测试,并给BaikalDB这款产品的外包装上写下如下关于规格的信息:
-
设计的集群最大规模,在 1000 个节点情况下,能支持 18 种数据类型,单节点 1T 数据容量,集群整体1P容量。
-
在基准数据测试下,集群单点性能达到,write不低于2000 QPS,单次write不超过 50 ms, read性能达到不低于4000 QPS,单次read不超过 20 ms。
-
对外接口基本兼容MySQL 5.6版本协议。
-
基于Multi Raft 协议保障数据副本一致性,少数节点故障不影响正常使用。
-
Share-Nothing架构,存储与计算分离,在线缩扩容对性能影响仅限于内部的数据自动均衡,而对外部透明,新增字段30s生效对集群无影响。
1.2测试范围
-
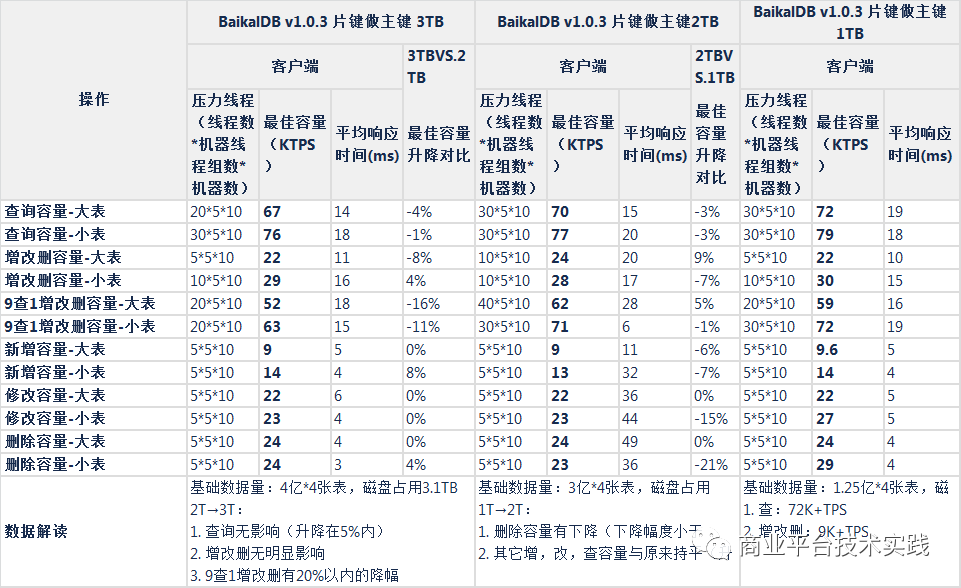
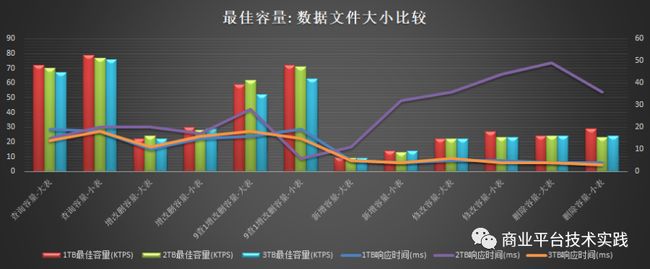
性能测试(行式存储,大表104字段,小表63字段,集群总基础数据1TB,2TB,3TB)
-
与mysql基准对比测试
-
表结构字段个数影响(大表104字段,小表63字段)
-
集群总基础数据大小影响(1TB,2TB,3TB)
-
表结构影响(“自增主键”,“片键做全局索引”,“片键做主键”)
-
带压力的扩展性测试
-
加节点(store)
-
减节点(store)
-
动态加列
1.3测试环境
五台机器混合部署3 meta, 5 db, 5 store获取基准,另有一台机器作为增减节点机动(centos 7.4 32核 2.4GHZ,128G内存 1.5TSSD硬盘)
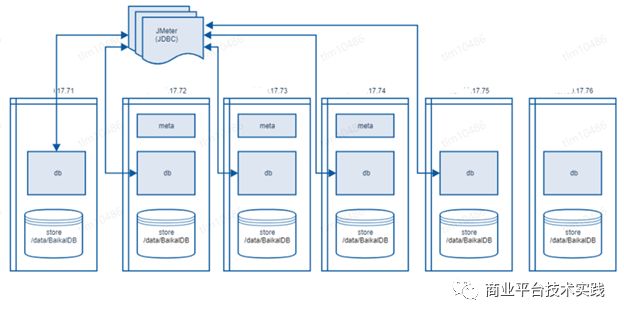
测试部署
1.4主要指标说明
-
最佳容量(KTPS):
-
5台机器配置的集群(3 meta, 5 db, 5 store)
-
连续两分钟可以稳定支撑的最大吞吐能力
-
平均读响应时间小于20ms,平均写响应时间小于50ms
-
系统最大吞吐能力: 每秒dml操作请求数
-
单位为KTPS(千次操作请求/秒)
-
定义
-
前置条件:
-
响应时间:dml操作从发送到收到返回结果所经过的时间,单位为毫秒
-
diskIOUtil 磁盘使用率: 一秒中有百分之多少的时间用于 I/O 操作,或者说一秒中有多少时间 I/O 队列是非空的
-
如果接近 100%,说明产生的I/O请求太多,I/O系统已经满负荷,该磁盘可能存在瓶颈。
-
大于30%说明I/O压力就较大了,读写会有较多的wait
-
最佳容量判定方法
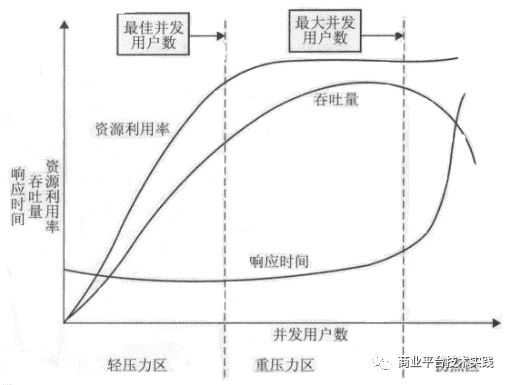
绘制系统的性能指标随着并发用户数增加而出现下降趋势的曲线,分析并识别性能区间和拐点并确定性能阈值。
1.5测试结论
-
性能测试
-
读:片键做主键模式,5节点读容量为72K+TPS,性能比mysql高85%+,瓶颈为CPU
-
写:片键做主键模式,5节点写性能为9.6K+TPS,与mysql相当,为mysql的85%~120%之间,瓶颈为DiskIO
-
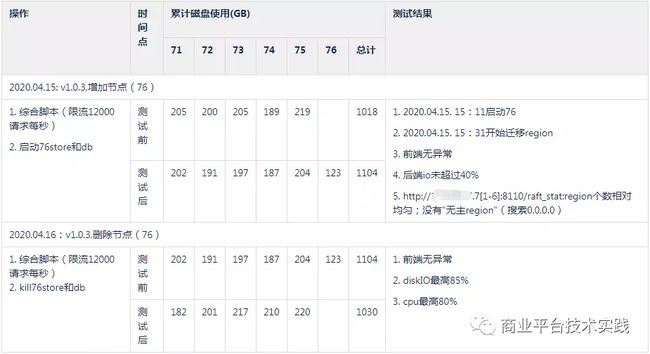
扩展性测试
-
加节点:前端吞吐平稳
-
减节点:减节点操作需要确保集群能力有足够的余量,能承载被减掉节点转移的压力
-
加列:22秒新列生效(1.25亿基础数据)
1.6性能测试详情
与mysql基准对比测试:
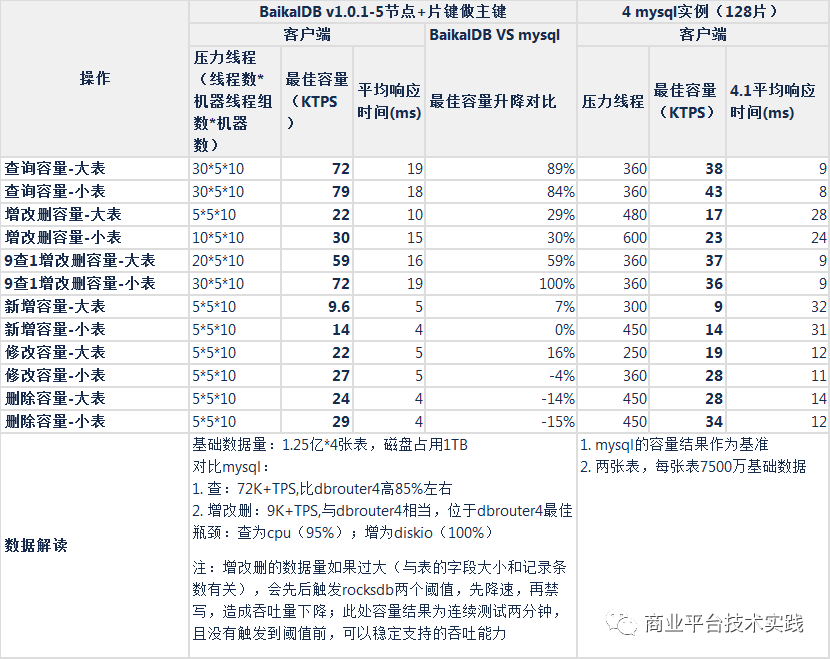
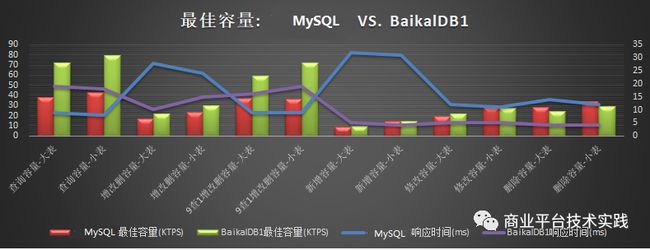
表结构字段个数影响:
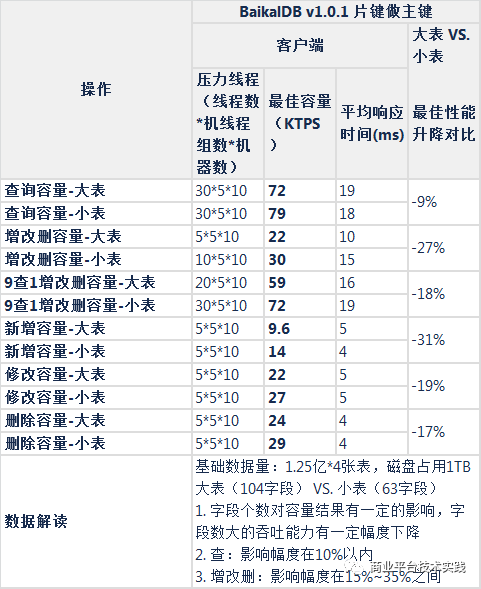
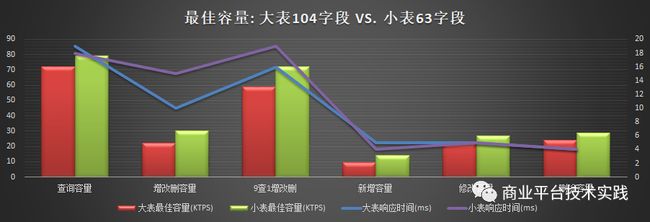
集群总基础数据大小的影响:
表结构影响:
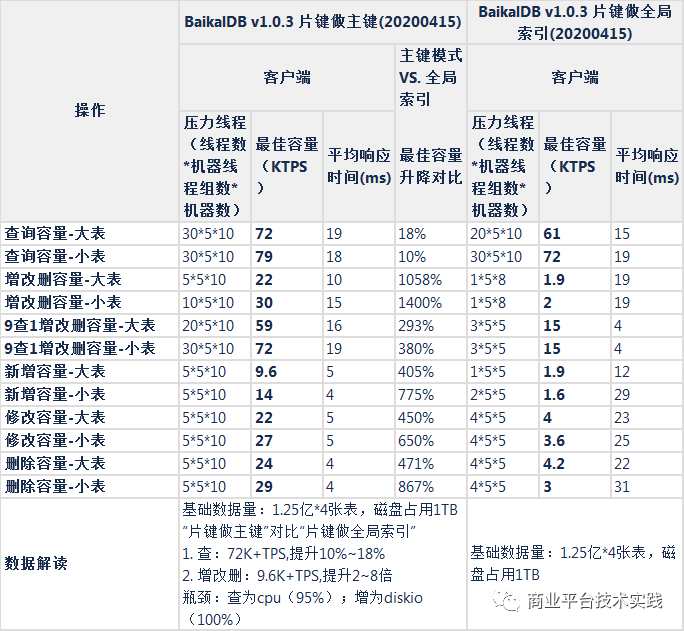
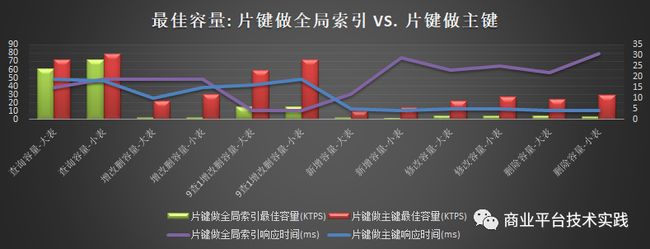
扩展性测试详情
不停服增减节点:
不停服增加列:
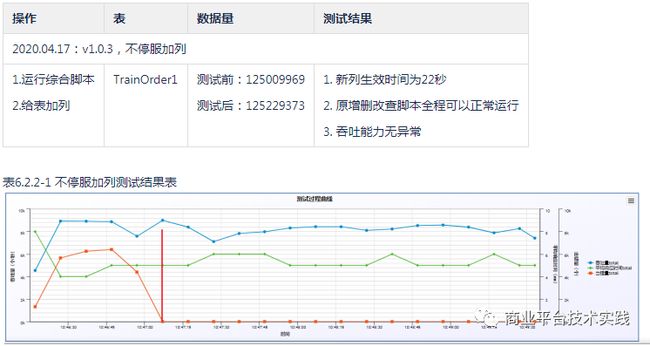
不停服加列测试过程曲线图(22秒后所有的带新列的insert语句全部成功,红色曲线代表失败数降为0)
2、基于列存OLAP场景测试
2.1测试背景
指标监控系统用于实时(定时)监控线上某实时业务数据,生成关于健康状态的相关指标,如果指标超出阈值,则触发报警功能。数据表约50列20亿行,查询sql10余种均为聚合类查询,检索列数不超过4列,查询条件为一定时间区间的范围查询,之前是跑在一款行存的分布式数据库之上,这是一个典型的olap类场景,我们采用baikaldb的列存模式与线上进行了对比测试,测试对象均为线上真实数据,两款DB集群配置相当,测试查询性能的同时,均承担等同的写负载。
2.2测试结果:
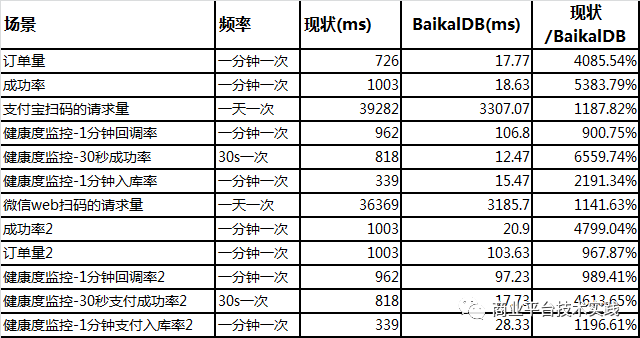
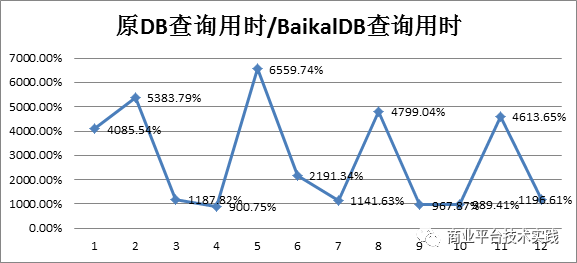
从测试结果可以看出,在宽表少列与聚合查询的sql查询,使用baikaldb的列式存储,可以有效减少磁盘IO,提高扫表及计算速度,进而提高查询性能,这类查询也是olap场景sql的常见写法。
3、性能与扩展性总结与思考
3.1性能分析的几个角度
-
资源瓶颈视角
-
查询及事务大小建议控制在10M以内,数据量过大会触发事务及RPC包大小限制;
-
若需全量导出,用
/*{"full_export":true}*/ select * from tb where id > x limit 1000;语法。 -
io.util满可导致rocksdb的L0层文件压缩不过来,出现快速的空间放大,进而导致磁盘快速被写满。相关参数:
max_background_jobs=24 -
rocksdb数据文件不建议超过1T,按照默认配置,超过1T后rocksdb将增加1层,写放大增大10,写放大会导致io.util出现瓶颈。若服务器磁盘远大于1T,建议单机多实例部署。
-
io.util满可导致内存刷盘不及时进而引起内存满(store);
-
慢查询过多时,会导致查询积压于store,进而引起内存满(store);相关参数db:
slow_query_timeout_s=60s; -
store内存建议配置为所在实例的40%以上,因为内存直接影响cache命中率,cache miss过多的话,会增大io.util及sql用时;相关参数:
cache_size=64M -
export TCMALLOC_MAX_TOTAL_THREAD_CACHE_BYTES=209715200 #200M,当大value时,调大可以避免线程竞争,提高性能 。 -
CPU : 多发生在读qps过大时(db,store),可监控vars/bthread_count指标
-
IO:多发生在写qps过大时(store),可监控io.util指标,及store/rocksdb/LOG日志。
-
Mem:
-
Disk:
-
NetWork:
3.1.1用户视角
-
联合主键 vs 自增主键
-
BaikalDB是按主键进行分片的,主键的选择影响了数据的物理分布,好的做法是把查询条件落在尽量少的分片上,查询时基于前缀匹配,一般建议按范围从左到右建立联合主键,例如:
class表主键可设置为schoolid,collegeid,classid # 学校,学院,班级; -
BaikalDB实现自增主键主要是为了与MySQL兼容,由于全局自增是通过meta单raft group完成,会存在rpc开销及扩展性问题;另外全局自增主键也容易导致数据批量插入时请求集中于最后一个Region节点,容易出现瓶颈。
-
全局索引 vs 局部索引
-
全局索引与主表不在一起,有自己的分片规则,好处是有路由发现功能,坏处是多了与全局索引的RPC开销,局部索引与主表一起,需要通过主键确定分片,否则需要广播,好处是RPC开销。
-
小表建议用局部索引;
-
大表(1亿以上),查询条件带主键前缀,用局部索引,否则用全局索引。
-
行存 vs 列存
-
宽表少列(查询列/总列数 小于 20%), 聚合查询的olap请求用列存
-
其他情况用行存
3.1.2实现视角
-
Balance:BaikalDB会周期性的进行Leader均衡与Peer均衡,负载均衡过程中若数据迁移量较大,可能是影响性能,一般发生在:
-
增删节点时
-
批量导入数据时
-
机器故障时
-
SQL Optimizer:目前主要基于RBO,实现了部分CBO,若性能与执行计划有关,可以使用explain,及 index hint功能调优。
3.1.3****扩展性考虑因素
-
稳定性
-
meta,尤其是主meta挂了情况下,将不能提供ddl, 主auto incr 挂了情况下,将不能提供自增主键表的insert功能。
-
store读正常,但瞬间一半store leader挂了情况下,写功能需要等到所有leader迁移至健康中心为止。
-
扩容:从实测情况看,扩容情况下比较平稳
-
缩容:缩容较少发生,但在双中心单中心故障的情况下,相当于缩容一半,此时稳定性还是值得注意与优化的,主要包括:
-
极限容量:
-
计算逻辑如下
-
理论上Meta 20G, Store 1T磁盘情况下,预计可管理 10k个store节点, 10P大小数据。
-
实际上百度最大的集群管理了1000个store节点,每store 1T磁盘, 共计约1P的集群总空间。
-
Region元数据=0.2k, Meta20G内存共计可管理的 Region总数 = 20G/0.2k = 100M
-
Region数据量 = 100M,Store 1T磁盘共可管理的 Region个数每store = 1T/100M = 10k
-
共计可以管理的数据量 = Region总数 * Region数据量 = 100M * 100M = 10P
-
共计可以管理的store个数 = Region总数 / Region个数每store = 100M/10k = 10k
-
线性
-
固定范围:O(1)
-
可以下推store全量:O(n/db并发度)
-
不可下推store全量:O(n)
-
JOIN查询:O(n^2)
4、后记
-
本文的性能与扩展性分析数据均来源于实际项目,而非TPCC,TPCH标准化测试,但测试项目具有一定的代表性。
-
BaikalDB测试数据基于V1.0.1版,最新发布的V1.1.2版又有了较多优化:
-
优化seek性能,实测range scan速度提高1倍;
-
rocksdb升级6.8.1,使用Partitioned Index Filters,进一步提高了内存使用效率;
-
增加利用统计信息计算代价选择索引功能(部分);
-
事务多语句Raft复制拆分执行,提高了Follower的并发度。
三、BaikalDB 低成本思考
这也是我们在业务推广中的关注次序,即
1、首先必须(Must to)业务场景匹配精 准(1一致性)和运行平稳(2高可用);
2、其次最好(had better)是数据多(3扩展性)与跑的快(4高性能);
3、最后应该是(should)使用友好(5高兼容性)与 成本节省(6低成本)。
简称:稳准多快好省。
作为系列文章的最后一篇,是关于成本的思考,如果说强一致与高可用是用户关心的在功能上是否满足需求,扩展性与高性能是老板关心的在规格上是否值得投入,那么兼容性与成本则是项目实施者应该关心的问题,因为它关系到项目推进难度。
如果你认可NewSQL的发展趋势,也发现了公司的实际业务场景需求,本文将会讨论在项目实施中需要克服的问题,并建议用成本的角度进行评估,这样有助于对项目的工作量进行计算。例如如果调研发现公司的潜在目标用户均跑在mysql数据库上,那么是否兼容mysql协议直接决定了用户的意愿,用户的学习成本,业务代码的改造成本,生态的配套成本,如果潜在用户超过10个以上则成本将会放大10倍;如果大部分潜在业务使用的是PostgreSQL,那么最好在选型时选择兼容pg的NewSQL。这也是本文将兼容性归类到低成本一并讨论的原因。
1、成本的分类
**狭义的成本:指数据库软件的开发,授权,运维及硬件成本,特点是可量化,**例如:1、开发投入:24人月
2、License授权:10万/年
3、运维投入:DBA 2人
4、硬件成本:服务器10台
**广义的成本:泛指在组织实施数据库应用工程实践过程中,所产生费用总和,**特点是与项目管理与实施有关,包括:
1、学习开发成本
2、测试验证成本
3、业务迁移成本
4、用户习惯
5、运维配套工具
6、软件成熟度
7、技术前瞻性
狭义的成本可以理解为这件事值不值得做,广义的成本可以理解为把事情做成需要做的工作,截止到本文发表为止,BaikalDB已在公司10余家业务上进行了落地应用,这些应用实际产生的成本与收益如何评估(狭义)?项目落地过程中需要落实哪些工作(广义)?下面将就这两个问题展开讨论。
2、狭义的成本理论上可减低100倍
由于BaikalDB是开源的,开发成本可以忽略,部署简单,其狭义成本主要集中在硬件成本上。结合公司的双中心建设与Kubernetes云原生平台战略,我们给出了BaikalDB两地四中心三副本行列混存的方案,理论上有望使硬件成本降低100倍,方案如下图:
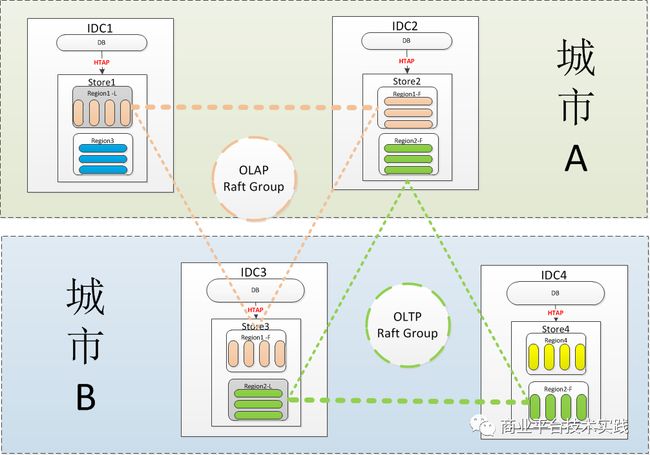
1、注1:图中省去了meta节点部署
2、注2:每个IDC会实际部署了多个store与db节点。
3、注3:行列混存的特性还在开发中
上图采用了完全对称的双中心部署方案,每个数据中心又存在2个对等IDC机房,基于BaikalDB的逻辑机房与物理机房概念,可以完成以上部署,并提供城市级别的容灾能力,通过Raft Group层面的行列混存技术实现仅需3副本即可提供HTAP的能力,配置细节已经在第一篇文章HTAP部署有所描述,本文在之前基础上增加了行列混存(功能尚未实现)的方式,进一步合并了应用场景,减少副本个数,从而达到节约成本的目的。以上方案具体成本节约主要体现在三个方面:
2.1 HTAP带来的成本降低为5倍
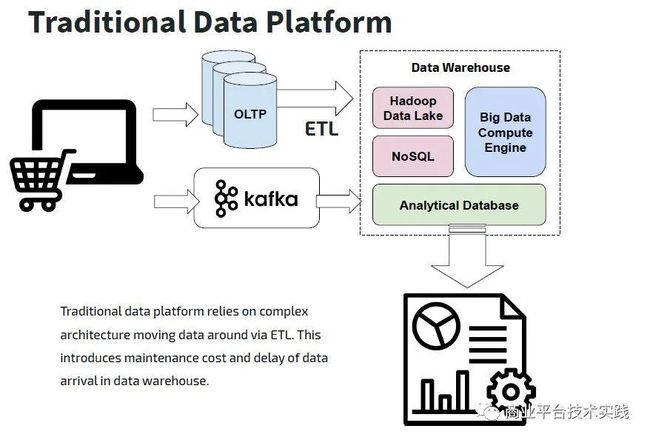
为了满足不同的应用场景,通过同步工具,数据会被分发到ETL,ES,HBASE,kafka,TiDB等不同数据组件中去,核心业务的存储资源存在5倍以上的放大。依据数据库使用现状情况,核心业务一般1套OLTP主库+数据同步平台+5套OLAP数据库,采用此方案后能同时满足以上全部场景,并且省去了异构数据源之间数据同步延迟问题,因为异构数据源超过了5个,合并为1个后,预计收益增大5倍。
2.2 单位资源效能带来的成本减低为4倍
- 行存OLTP类场景性能提升85%
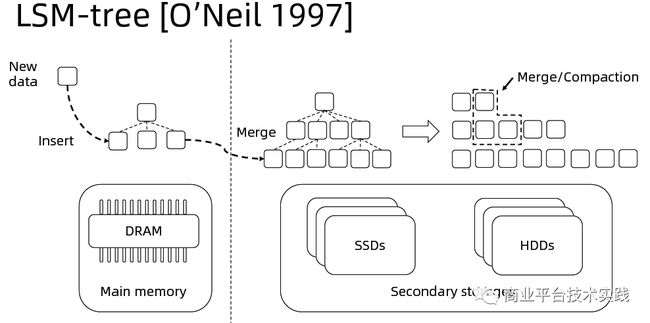
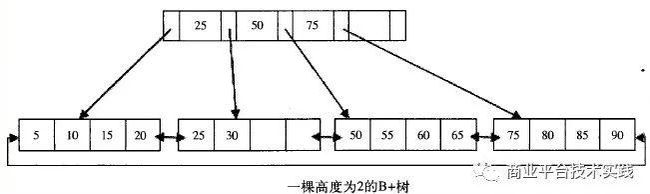
BaikalDB存储层使用RocksDB的LSM-Tree存储,相较于innodb的B+树,通过平衡读,写,空间放大使得读写性能更加均衡,通过out-of-place update及一定的空间放大来优化写性能(对比innodb相当于牺牲全局有序性及存储空间换取写性能),能充分发挥SSD硬盘的随机读优势及利用高效缓存来加速点查询,对于范围查则主要通过data reorganization(merge/compaction)及SSD的并发读来优化速度。参考第二篇性能测试文章的基准性能测试结果,适用于OLTP场景的行存BaikalDB综合性能可提升85%。
- 列存OLAP类场景性能提升10倍
OLAP类场景下的SQL查询语句一般是宽表少列,以聚合函数为主,数据比较适合按列存放在一起,一个例子如下:
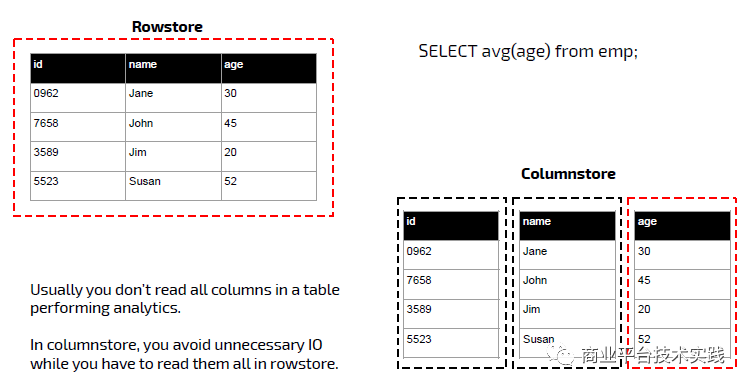
cstore vs rstore
Demo
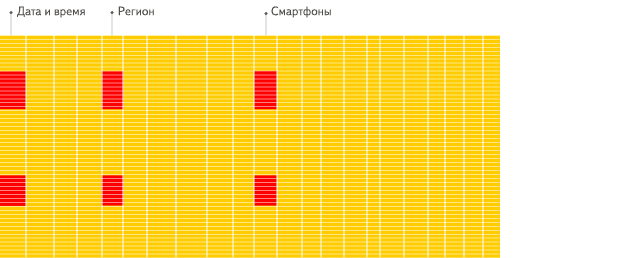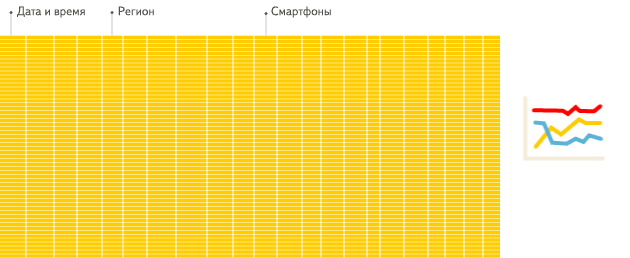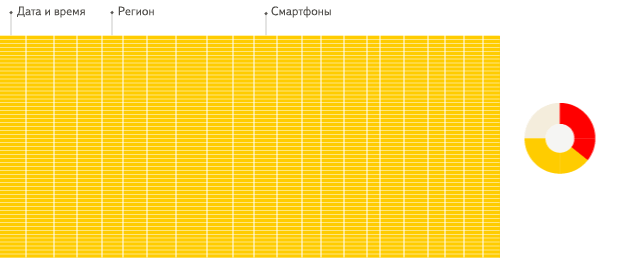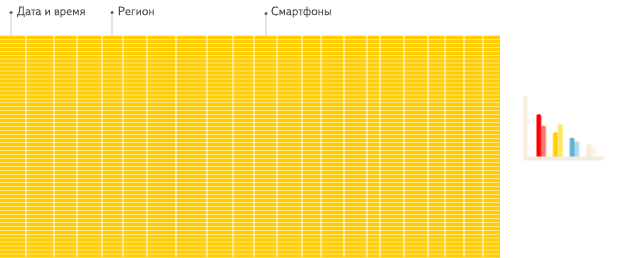
#统计每个广告平台的记录数量SELECT CounterID, count() FROM hits GROUP BY CounterID ORDER BY count() DESC LIMIT 20;
行式
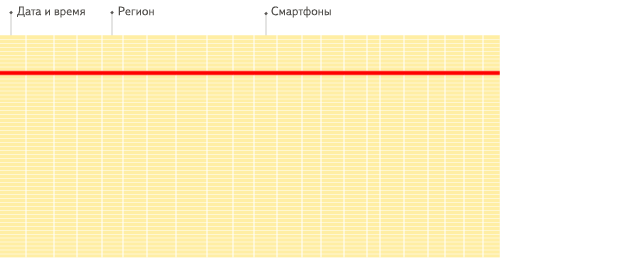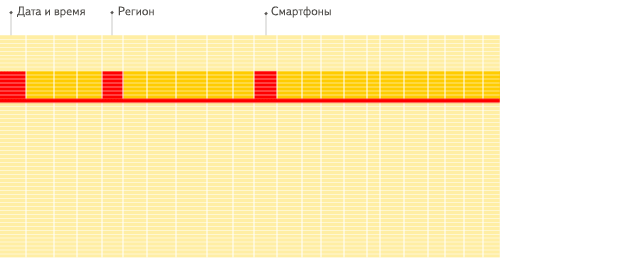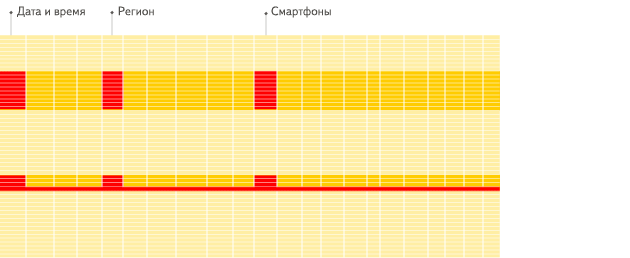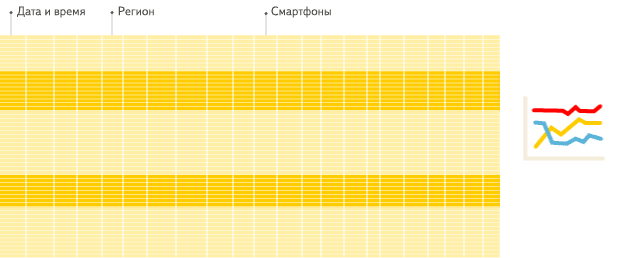
列式
使用BaikalDB的列存引擎,使我们第一家接入OLAP业务(约100亿数据量的聚合查询)查询速度提升10倍。
业务一般会有1个OLTP场景加n个OLAP场景组成,平均来看BaikalDB可以使单位资源效能提升4倍左右。
2.3 云原生弹性能力带来的成本减低为5倍
以mysql为例,由于缩扩容升降配困难,为了应对少数发生的业务高峰时段(例如双11一年只有一次)而不得不一直留够Buffer,导致硬件资源的投入不能随着流量的变化而动态变化,弹性不足,资源利用率普遍较低约8%的水平。公司也意识到相关问题,在积极构建基于kubernetes云原生平台(见下图),具体文章参见同程艺龙云原生 K8s 落地实践[4] 。
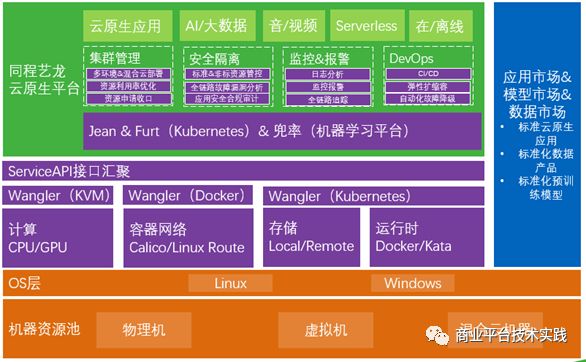
BaikalDB的share –nothing云原生特性能完美的k8s的调度能力进行结合,预计可以把资源利用率提升到40%,因此弹性收益为5倍。之所以没有提升到80%以上是为了满足双中心容灾互备的需要,以应对城市级故障带来的单中心双倍压力。
综上所述,总收益 = HTAP收益 * 单位资源能效收益 * 资源利用率收益 = 5 * 4 * 5 = 100倍
3、实际上广义的成本难以量化但不能有短板
在狭义成本评估值得做的情况下,需要从项目管理或项目实施的角度思考如何把项目顺利推进,由于每家公司每个项目的实际情况均不一样,项目的评估很难统一量化,但我们在进行项目实施时必须要慎重考虑这些因素,并且任何一个环节不达标均可能导致项目的失败,在这里把项目推进中要完成的工作量称为广义的成本,以我们实践经验进行总结评分,满分为10分,分值越高越好,评价不同于以往的性能测试,具有很强的主观性,仅供参考。
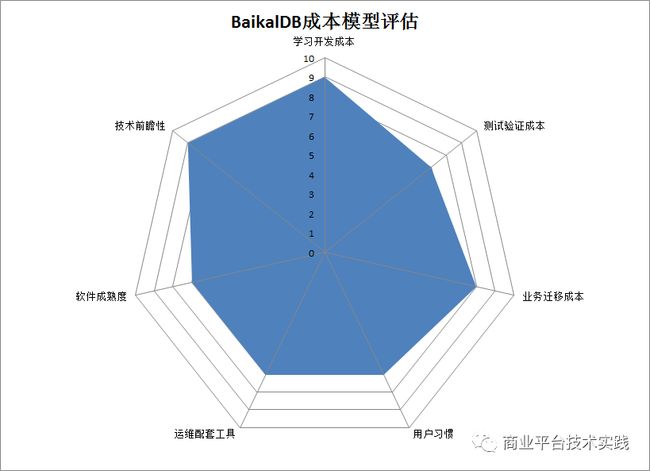
3.1 学习开发成本:9分
BaikalDB的学习主要包括依赖与BaikalDB代码本身。
BaikalDB的依赖少而精,主要有三个:
1、brpc:Apache项目,百度内最常使用的工业级RPC框架;
2、braft:百度开源的Raft一致性与复制状态机工业级实现库;
3、RocksDB:kv存储引擎,集成了Google与Facebook双方大牛的力作;
以上三款开源项目,社区都比较成熟,每一款都值得好好学习。
BaikalDB本身作为一款纯开源的分布式数据库,代码10万行,以C++语言为主,代码架构简洁,组织清晰。虽然目前文档不是很多还在完善中,但项目保持了良好编码风格,代码可读性强,大部分实现原理可以通过直接阅读代码掌握,少部分需要结合数据库及分布式领域的理论知识与论文学习。在模块化抽象与分层上保持清晰保持简洁,在一些核心对象例如逻辑计划:LogicalPlanner,表达式:ExprNode,执行算子:ExecNode 仅有一层继承关系,具有薄胶合层显著特点,有效的减低了软件的学习成本,体现了Unix开源文化的KISS原则(Keep It Simple, Stupid!)
总之,BaikalDB是一款非常值得学习的DB,给9分。
3.2 测试验证成本:7分
BaikalDB的测试验证工作量与其它DB差不多,中规中矩给7分。
3.3 业务迁移成本:8分
业务的迁移成本主要包括数据迁移与SQL改写两个部分,由于BaikalDB兼容MySQL协议,公司已研发了基于MySQL生态的数据同步平台,数据迁移成本不大。使用MySQL开发的业务代码,大部分情况不需要改写SQL,改写主要发生在BaikalDB尚未支持的MySQL语法例如(子查询,一些系统函数上)和慢查询改写上面,业务迁移成本给8分。
3.4 用户习惯:7分
1、图像化工具:能使用Navicat, IDEA自带MySQL UI, DataGrip进行简单的表浏览,SQL执行功能,不能进行复杂管理操作;
2、公司已有系统对接(例如工单,权限,一站式查询等):尚未打通;
3、对新概念的接受过程(例如新的数据文件,部署方式,资源隔离,多租户等)。
3.5 运维配套工具:7分
- 备份工具:
热备:基于SST的备份恢复
冷备:通过SQL语句逻辑备份。
/{“full_export”:true}/ select * from tb where id > x limit 1000;
-
监控工具:Prometheus
-
运维脚本:script[5]
-
部署工具:Ansible
-
压测工具:sysbench
-
订阅工具:Binlog功能开发中
-
同步工具:Canal
3.6 软件成熟度:7分
3.7 技术前瞻性:9分
BaikalDB提供的PB级分布式扩展能力,动态变更Schema能力,分布式事务,异地多活,资源隔离,云原生K8s,HTAP能力均与公司未来的需求或规划匹配,因此给9分。
4、后记
至此BaikalDB在同程艺龙的应用实践系列文章就结束了,BaikalDB作为一款开源两岁的NewSQL数据库还非常年轻,存在很大完善空间。同时作为后浪也借鉴很多前浪的设计思想,有一定的后发优势。BaikalDB实现简洁,功能强大,社区专业友好,无论是用来代码学习还是业务应用均有很大成长空间,欢迎感兴趣的朋友一起参与。由于笔者水平有限,文中如有不妥之处,还望理解指正。
招聘信息:
百度商业平台研发部主要负责百度商业产品的平台建设,包括广告投放、落地页托管、全域数据洞察等核心业务方向,致力于用平台化的技术服务让客户及生态伙伴持续成长,成为客户最为依赖的商业服务平台。
无论你是后端,前端,还是算法,这里有若干职位在等你,欢迎投递简历, 百度商业平台研发部期待你的加入!
简历投递邮箱:[email protected] (投递备注【百度商业】)
推荐阅读:
|面向大规模商业系统的数据库设计和实践
|百度爱番番移动端网页秒开实践
|解密百TB数据分析如何跑进45秒
---------- END ----------
百度Geek说
百度官方技术公众号上线啦!
技术干货 · 行业资讯 · 线上沙龙 · 行业大会
招聘信息 · 内推信息 · 技术书籍 · 百度周边
欢迎各位同学关注