R-CNN网络基础
目录
- R-CNN网络基础
-
- Overfeat模型
- RCNN模型
-
- 算法流程
-
- 候选区域生成
- CNN网络提取特征
- 目标分类(SVM)
- 目标定位
- 预测过程
- 算法总结
- Fast RCNN模型
-
- 算法流程
-
- ROI Pooling
- 目标分类和回归
- 模型训练
- 模型预测
- 模型总结
- 总结
R-CNN网络基础
学习目标
- 了解Overfeat模型的移动窗口方法
- 了解RCNN目标检测的思想
- 了解fastRCNN目标检测的思想
- 知道多任务损失

Overfeat模型
Overfeat方法使用滑动窗口进行目标检测,也就是使用滑动窗口和神经网络来检测目标。滑动窗口使用固定宽度和高度的矩形区域,在图像上“滑动”,并将扫描结果送入到神经网络中进行分类和回归。
例如要检测汽车,就使用下图中红色滑动窗口进行扫描,将所有的扫描结果送入网络中进行分类和回归,得到最终的汽车的检测结果。
这种方法类似一种暴力穷举的方式,会消耗大量的计算力,并且由于窗口大小问题可能会造成效果不准确。
RCNN模型
2014年提出R-CNN网络,该网络不再使用暴力穷举的方法,而是使用候选区域方法(region proposal method)创建目标检测的区域来完成目标检测的任务,R-CNN是以深度神经网络为基础的目标检测的模型 ,以R-CNN为基点,后续的Fast R-CNN、Faster R-CNN模型都延续了这种目标检测思路。
算法流程
RCNN的流程如下图所示:
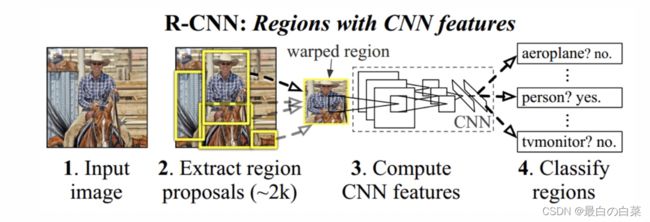
步骤是:
- 候选区域生成:使用选择性搜索(Selective Search)的方法找出图片中可能存在目标的侯选区域
- CNN网络提取特征:选取预训练卷积神经网网络(AlexNet或VGG)用于进行特征提取。
- 目标分类:训练支持向量机(SVM)来辨别目标物体和背景,对每个类别,都要训练一个二元SVM。
- 目标定位:训练一个线性回归模型,为每个辨识到的物体生成更精确的边界框。
候选区域生成
在选择性搜索(SelectiveSearch,SS)中,使用语义分割的方法,它将颜色、边界、纹理等信息作为合并条件,采用多尺度的综合方法,将图像在像素级上划分出一系列的区域,这些区域要远远少于传统的滑动窗口的穷举法产生的候选区域。

SelectiveSearch在一张图片上提取出来约2000个侯选区域,需要注意的是这些候选区域的长宽不固定。 而使用CNN提取候选区域的特征向量,需要接受固定长度的输入,所以需要对候选区域做一些尺寸上的修改。
CNN网络提取特征
采用预训练模型(AlexNet或VGG)在生成的候选区域上进行特征提取,将提取好的特征保存在磁盘中,用于后续步骤的分类和回归。

-
全连接层的输入数据的尺寸是固定的,因此在将候选区域送入CNN网络中时,需进行裁剪或变形为固定的尺寸,在进行特征提取。
-
预训练模型在ImageNet数据集上获得,最后的全连接层是1000,在这里我们需要将其改为N+1(N为目标类别的数目,例如VOC数据集中N=20,coco数据集中N=80,1是加一个背景)后,进行微调即可。

- 利用微调后的CNN网络,提取每一个候选区域的特征,获取一个4096维的特征,一幅图像就是2000x4096维特征存储到磁盘中。
目标分类(SVM)
假设我们要检测猫狗两个类别,那我们需要训练猫和狗两个不同类别的SVM分类器,然后使用训练好的分类器对一幅图像中2000个候选区域的特征向量分别判断一次,这样得出[2000, 2]的得分矩阵,如下图所示:
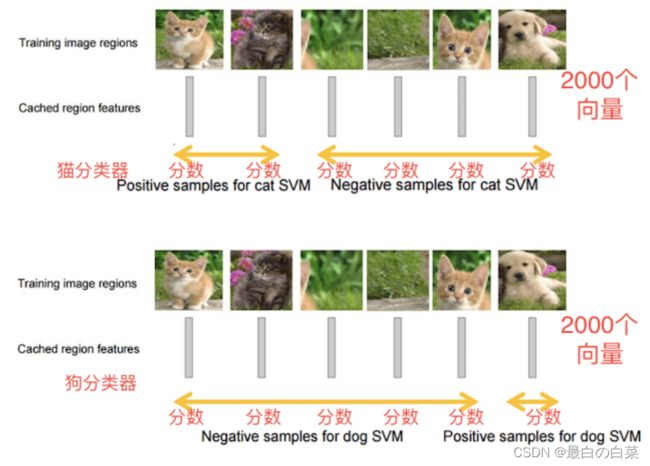
对于N个类别的检测任务,需要训练N(目标类别数目)个SVM分类器,对候选区域的特征向量(4096维)进行二分类,判断其是某一类别的目标,还是背景来完成目标分类。
目标定位
通过选择性搜索获取的目标位置不是非常的准确,实验证明,训练一个线性回归模型在给定的候选区域的结果上去预测一个新的检测窗口,能够获得更精确的位置。修正过程如下图所示:

通过训练一个回归器来对候选区域的范围进行一个调整,这些候选区域最开始只是用选择性搜索的方法粗略得到的,通过调整之后得到更精确的位置,如下所示:

预测过程
使用选择性搜索的方法从一张图片中提取2000个候选区域,将每个区域送入CNN网络中进行特征提取,然后送入到SVM中进行分类,并使用候选框回归器,计算出每个候选区域的位置。 候选区域较多,有2000个,需要剔除掉部分检测结果。 针对每个类,通过计算IOU,采取非最大值抑制NMS的方法,保留比较好的检测结果。
算法总结
1、训练阶段多,训练耗时: 微调CNN网络+训练SVM+训练边框回归器。
2、预测速度慢: 使用GPU, VGG16模型处理一张图像需要47s。
3、占用磁盘空间大:5000张图像产生几百G的特征文件。
4、数据的形状变化:候选区域要经过缩放来固定大小,无法保证目标的不变形
Fast RCNN模型
考虑到R-CNN存在的问题,2015年提出了一个改善模型:Fast R-CNN。 相比于R-CNN, Fast R-CNN主要在以下三个方面进行了改进:
1、提高训练和预测的速度
R-CNN首先从测试图中提取2000个候选区域,然后将这2000个候选区域分别输入到预训练好的CNN中提取特征。由于候选区域有大量的重叠,这种提取特征的方法,就会重复的计算重叠区域的特征。在Fast-RCNN中,将整张图输入到CNN中提取特征,将候选区域映射到特征图上,这样就避免了对图像区域进行重复处理,提高效率减少时间。
2、不需要额外的空间保存CNN网络提取的特征向量
RCNN中需要将提取到的特征保存下来,用于为每个类训练单独的SVM分类器和边框回归器。在Fast-RCNN中,将类别判断和边框回归统一使用CNN实现,不需要在额外的空间存储特征。
3、不在直接对候选区域进行缩放
RCNN中需要对候选区域进行缩放送入CNN中进行特征提取,在Fast-RCNN中使用ROIpooling的方法进行尺寸的调整。
算法流程
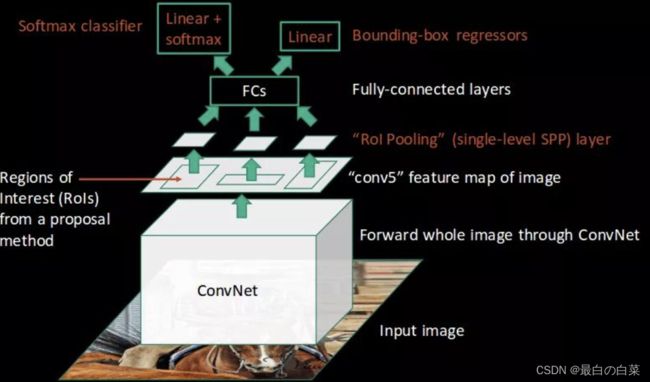
Fast_RCNN的流程如下图所示:
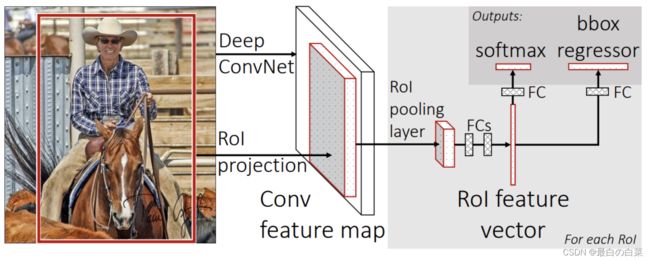
步骤是:
1、候选区域生成:使用选择性搜索(Selective Search)的方法找出图片中可能存在目标的侯选区域,只需要候选区域的位置信息
2、CNN网络特征提取:将整张图像输入到CNN网络中,得到整副图的特征图,并将上一步获取的候选区域位置从原图映射到该特征图上
3、ROIPooling: 对于每个特征图上候选框,RoI pooling层从特征图中提取固定长度的特征向量每个特征向量被送入一系列全连接(fc)层中。
4、目标检测:分两部分完成,一个输出各类别加上1个背景类别的Softmax概率估计,另一个为各类别的每一个类别输出四个实数值,来确定目标的位置信息。
候选区域生成、CNN网络特征提取都与RCNN中一样。
ROI Pooling
候选区域从原图映射到特征图中后,进行ROIpooling的计算,如下图所示:
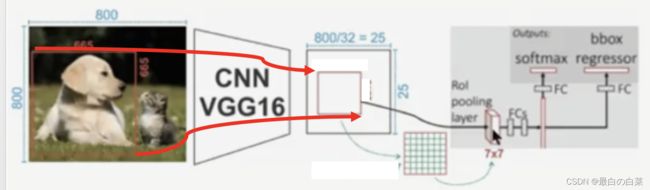
ROI Pooling层使用最大池化将输入的特征图中的任意区域(候选区域对应的区域)内的特征转化为固定的×的特征图,其中和是超参数。 对于任意输入的ℎ×的候选区域,将其分割为×的子网格,每个子网格的大小为:(h/H) x (w/W),取每个子网格中的最大值,送入后续网络中进行处理。

使用ROI Pooling层替换预训练网络中最后的池化层,并将并将超参,设置为和网络第一个全连接兼容的值,例如VGG16,设==7。
目标分类和回归
原网络的最后一个全连接层替换为两个同级层:K+1个类别的SoftMax分类层和边框的回归层。
模型训练
R-CNN中的特征提取和检测部分是分开进行的,Fast R-CNN提出一个高效的训练方法:多任务训练
Fast R-CNN有两种输出:
- 一部分输出在K+1个类别上的离散概率分布(每个候选区域),p=(p0,p1,…,pk)。通常,通过全连接层的K+1个输出上的Softmax来计算概率值。
- 另一部分输出对于由K个类别中的每一个检测框回归偏移, t k = ( t x k , t y k , t w k , t h k ) \mathrm{t}^{\mathrm{k}}=\left(\mathrm{t}_{\mathrm{x}}^{\mathrm{k}}, \mathrm{t}_{\mathrm{y}}^{\mathrm{k}}, \mathrm{t}_{\mathrm{w}}^{\mathrm{k}}, \mathrm{t}_{\mathrm{h}}^{\mathrm{k}}\right) tk=(txk,tyk,twk,thk)。其中$t_{k} $指定相对于候选框的尺度不变转换和对数空间高度/宽度移位。
将上面的两个任务的损失函数放在一起:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-omKZeWaG-1646040791042)(笔记图片/image-20201229120908741.png)]](http://img.e-com-net.com/image/info8/6dabe5591f494872be36174b925ad57f.jpg)
联合训练fast-RCNN网络。
模型预测
fastRCNN的工作流程描述如下:
- 输入图像:

- 图像被送入到卷积网络进行特征提取,将通过选择性搜索获取的候选区域映射到特征图中:

- 在特征图上Rol中应用RoIPooling,获取尺寸相同的特征向量

- 将这些区域传递到全连接的网络中进行分类和回归,得到目标检测的结果。
模型总结
Fast R-CNN是对R-CNN模型的一种改进:
- CNN网络不再对每个候选区域进行特征提取,而是直接对整张图像进行处理,这样减少了很多重复计算。
- 用ROI pooling进行特征的尺寸变换,来满足FC全连接层对输入数据尺度的要求。
- 将目标的回归和分类统一在一个网络中,使用FC+softmax进行目标分类,使用FC Layer进行目标框的回归。
在Fast R-CNN中使用的目标检测识别网络,在速度和精度上都有了不错的结果。不足的是,其候选区域提取方法耗时较长,而且和目标检测网络是分离的,并不是端到端的,在2016年又提出了Faster-RCNN模型用于目标检测。
总结
- 了解Overfeat模型的移动窗口方法
滑动窗口使用固定宽度和高度的矩形区域,可以在图像上“滑动”,并将扫描送入到神经网络中进行分类和回归。
- 了解RCNN目标检测的思想
R-CNN网络使用候选区域方法(region proposal method),利用CNN网络提取特征,SVM完成分类,线性回归进行bbox的修正
- 了解fastRCNN目标检测的思想
利用CNN网络进行特征提取,利用SS生成候选区域,进行映射,并使用ROIpooling进行维度调整,最后进行分类和回归
- 知道Fast-RCNN中提出的多任务损失:将分类和回归的损失函数联合训练网络