R-FCN算法及Caffe代码详解
本篇博客一方面介绍R-FCN算法(NISP2016文章),该算法改进了Faster RCNN,另一方面介绍其Caffe代码,这样对算法的认识会更加深入。
论文:R-FCN:object detection via region-based fully convolutional networks
论文链接:http://papers.nips.cc/paper/6465-r-fcn-object-detection-via-region-based-fully-convolutional-networks.pdf
要解决的问题:
这篇论文提出一种基于region的object detection算法:R-FCN(Region-based Fully Convolutional Network),**R-FCN可以看做是Faster RCNN的改进版,速度上提高了差不多3倍左右,mAP也有一点提升。**另外一类object detection算法像YOLO,SSD等object detection算法是不基于region的。
为什么R-FCN相比Faster RCNN会有明显的提速呢?以主网络为ResNet101为例,在Faster RCNN中,ROI Pooling层的输入是在conv4_x,在做完ROI Pooling后会继续接conv5_x,conv5_x包含9个卷积层,另外在conv5_x后还有几个全连接层,这些层的计算都直接作用在每个roi上,因此存在许多重复计算。如果主网络换成VGG也类似,只不过重复计算的层数会少一些,主要是一些全连接层。而在R-FCN中,所有能共享的层都在ROI Pooling之前做好了,因此在ROI Pooling后基本不会有太多的重复计算。为了要在ROI Pooling之前实现层共享,一方面将conv5_x的计算移到Pooling层之前,但这样依然还存在一些全连接层的重复计算,因此再引入position-sensitive score map和position-sensitive ROI Pooling,使得经过Pooling后简单地执行一些操作就能得到回归和分类结果,而不再像Faster RCNN一样用几个全连接层去得到结果。
基于101层的ResNet网络在VOC 2007数据集上达到mAP 83.6%。测试的时候每张图像所用时间是170ms,比Faster RCNN快2.5到20倍。
代码地址:https://github.com/daijifeng001/r-fcn
算法概要:
首先之所以提出本文的算法,简单讲是为了提高Faster RCNN的速度,因此一方面很直观地想到要尽可能在网络中共享计算,所以就想到对原来ROI Pooling层进行改造和移动;另一方面希望基本网络可以更加强大,因此就想到了用类似Resnet等全卷积网络代替原来的VGG等网络。
这个算法的网络主要是基于ResNet-101,ResNet-101包含100个卷积层、一个均值降采样层和一个1000分类的全连接层。这里作者仅采用前面的100个卷积层来提取特征,其它层不用。ResNet-101的最后一个卷积层输出是2048维,这里作者为了降维,添加了一个1024维的11卷积层(随机初始化)。**最后,一方面添加一个k^2(C+1)维的卷积层用于生成score maps,这些score maps主要是用来生成object的类别;另一方面为了做bounding box regression,作者添加了和Fast RCNN类似的bounding box regression卷积层,维度是4k^2,该层和前面生成score maps的卷积层是并列的。**除了这个主网络以外,该算法还引入RPN网络生成ROI,生成的ROI将和分类的卷积层生成的score maps进行pooling并最终得到每个ROI属于每个类别的概率(一共C+1类)。另外这个ROI还将和回归卷积层的输出进行pooling,得到每个ROI的四个坐标。损失函数方面基本上和Fast RCNN一样。
因此,整个网络主要就是由全卷积网络(ResNet)和RPN网络构成,前者用于提取特征,后者用于生成ROI。
注意:文中的ROI就是region proposal。另外Faster RCNN中的ROI Pooling和本文的ROI Pooling不是一个意思,前者只是简单将每个region feature变换到统一的尺寸的feature,变换过程中采用Max pooling;而后者则是一种position-sensitive的ROI Pooling。
算法详解:
图片分类问题是具有平移不变性的(translation invariance),什么意思呢?就是说一张图像中目标的平移对这张图片的分类结果影响不大,这也是为什么全卷积网络可以在图像分类比赛中成绩更好;目标检测问题则具有平移敏感性(translation variance),也很容易理解,如果一张图像中目标平移了,那么最后预测的框也会变化。
作者指出像VGG或AlexNet网络,一般由卷积层,每个卷积层后面跟降采样(pooling)层,最后叠加几个全连接层构成。但是像GooleNet或ResNet,基本上都是卷积层(很少有降采样层或全连接层),作者将其归为全卷积网络(FCN),同时假设全卷积网络具备平移不变性,所以如果简单地在目标检测问题中用ResNet代替VGG等网络,检测效果并不好,根源就在于前者具有平移不变性,而检测问题对平移敏感。为了解决这个问题,作者在ResNet的卷积层中插入了ROI pooling层,这种region-specific的操作打破了原来的平移不变性(普通网络因为卷积层和pooling层的交替,所以具有平移敏感性,所以如果在全卷积网络中增加ROI Pooling会增加平移敏感性),不过这种设计降低了训练及测试的效率,因为其引入了一些region-wise层。
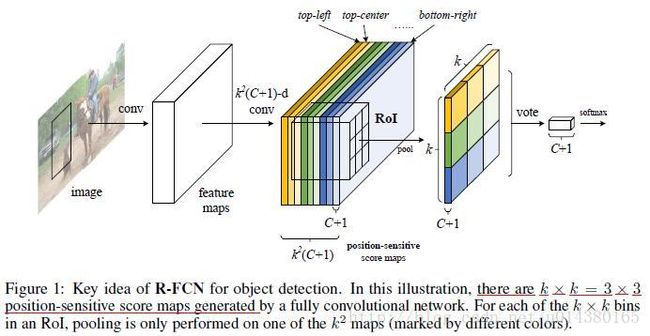
因此为了将平移敏感性引入全卷积网络,作者在全卷积网络的输出位置添加一系列特定的卷积层用于生成position-sensitive的score map,每个score map保存目标的空间位置信息。然后再添加ROI Pooling层,该层后面不再跟卷积层或全连接层。这样整个网络不仅可以end-to-end训练,而且所有层的计算都是在整个图像上共享的。如下图的table1,表示几种算法的共享层数情况。

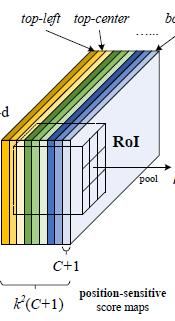
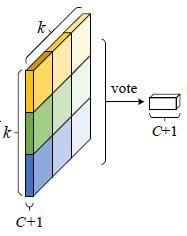
这里讲一个公式:position-sensitive ROI pooling,如下图。作者将每个ROI划分成k*k个bins,即如果一个ROI的大小是wh,那么每个bin的大小就是(w/k)(h/k),对于里面第(i,j)个bin进行pool操作可以得到rc(i,j),c表示类别。zi,j,c表示的是k^2(C+1)个maps中的第(i,j)个且属于c类别的那个map。x,y表示这个bin的像素点范围,累加也是对x,y的不同取值进行累加,最后再除以n取均值。

Figure1以分类支路为例介绍该公式,在Figure1中不同的颜色代表公式1中不同的(i,j)。所以对于分类支路而言,这个公式简单讲就是:对一个ROI中的某个bin(比如是(i,j)这个bin)进行pooling操作就是对卷积层输出的k×k×(C+1)个maps中的第(i,j)个map做均值pooling。所以一个ROI的某个bin进行pooling后会得到1×1×(C+1)大小的输出,换句话说每个ROI进行pooling后会得到k×k×(C+1)大小的输出,这个输出进行vote操作得到C+1维的输出,这个vote操作就是一个均值操作。最后再连接一个softmax层输出每一类的概率。回归支路和分类支路类似,只不过接的卷积层的卷积核数量不是k×k×(C+1)而是4×2×k×k,因此在经过position-sensitive Roi Pooling后得到4×2×k×k维度的输出,再经过vote操作得到4×2×1×1的输出,表示预测的bbox坐标offset。
关于损失函数,原文如下图,这里解释一下。首先本文的损失函数基本上和Fast RCNN的一样,都是分类损失和回归损失的和。分类损失采用的是交叉熵,这也是Caffe里面的softmaxWithLoss层的做法,可能有同学看不懂这个交叉熵里面的Sc代表什么意思,这里再贴一个文中的公式来解释Sc。c>0是用来说明只有存在object的ROI才能参与回归(因为只有object才有四个坐标,才能进行回归,才有loss)。最后一句是介绍训练时候正负样本是怎么选的,和一个ground truth的IOU值大于0.5的ROI就是positive样本。

**这个是介绍Sc的两个公式,Sc其实就是Caffe里面的softmax层的输出,代表的是每一类的概率;其中Sc用到rc,而rc就是网络层输出的每个类别的概率得分,就是上面Fig1的vote后的结果。**具体参看另一篇博文:softmax,softmax-loss,BP的解释
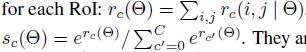
如下图,除了主网络ResNet以外,还有RPN网络用于生成ROI(region proposal),因此在训练的时候,作者采用RPN网络和R-FCN交替训练的方式来共享特征。这里有个细节,假设每个image有N个ROI,那么在前向训练的时候会计算所有N个ROI的loss,然后将这N个ROI(包括positive和negative)按照loss高低进行排序,最后在backpropagation阶段只将loss最高的B个ROI的loss回传。详细可以参考OHEM算法。
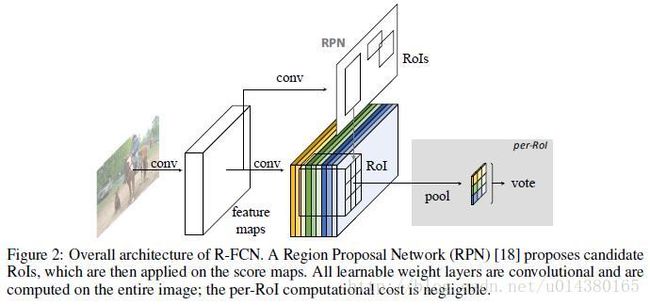
因此再来简单梳理一下网络结构:首先输入图像经过一个全卷积网络(比如ResNet),然后一方面在最后一个卷积层后面添加特殊的卷积层生成position-sensitive的score map,另一方面全卷积网络的某个卷积层(可能是最后一个卷积层)输出作为RPN网络的输入,RPN网络最后生成ROI。最后的POI Pooling层将前面的socre map和ROI作为输入,输出类别信息。另外回归部分和分类部分是并列的,详解看后面的Caffe代码。
Caffe的代码:
首先是数据读入操作,假设输出的data是136001000,im_info是13,gt_boxes是1*4,后面的所有维度都是以这个假设为前提。
然后ResNet,结构如下图。R-FCN主要是采用ResNet和RPN结构来训练。R-FCN的具体结构(以ResNet50为例):conv1,maxpooling,conv2_x(在代码中用res2a_branch2a到res2c_branch2c表示,前面的字母a,b,c表示在conv2_x层需要循环3个大层,后面的a,b,c表示每个大层里面都有三个小层。另外还有res2a_branch1表示用1*1的256个卷积核卷积的结果。每个大层结束的时候都需要用Eltwise层合并,比如res2a_branch1和res2a_branch2c生成res2a,下一个大层则是res2a和res2b_branch2c座Eltwise合并),conv3_x,conv4_x,conv5_x。
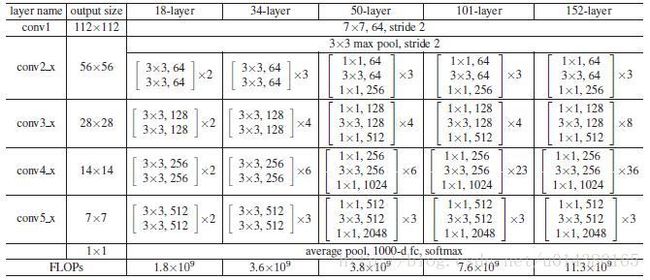
然后是RPN网络,RPN网络以一个33的卷积核,pad=1,stride=1的512个卷积核的卷积层开始,输入是res4f层的输出,res4f层的输出即conv4_x最后的输出。该rpn_conv/33层的输出是151238*63。
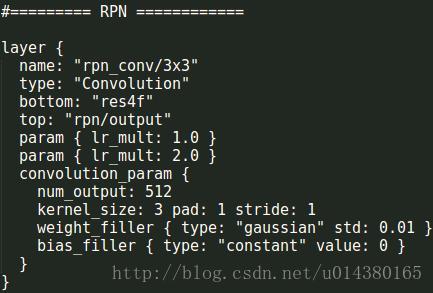
然后是分类层和回归层,分类层采用11的卷积核,pad=0,stride=1的18(2(back ground/fore ground)9(anchors))个卷积核的卷积层,分类层的输出是1183863。回归采用11的卷积核,pad=0,stride=1的36(49(anchors))个卷积核的卷积层,回归层的输出是1363863。
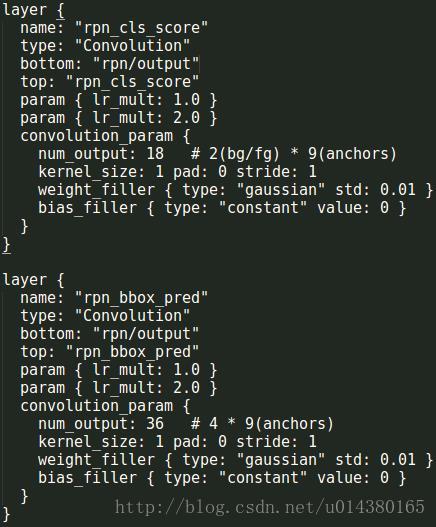
Reshape层对分类层的结果做了一次维度调整,从1183863变成1234263,后面的342*63就代表该层所有anchor的数量。
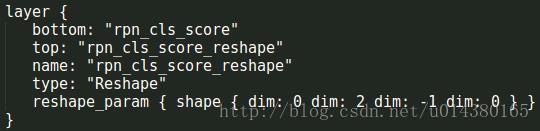
下面这个层是用来从最开始读取的数据得到label和target。这里rpn_cls_score为1134263,rpn_bbox_targets为1363863,rpn_bbox_inside_weights为1363863,rpn_bbox_outside_weights为1363863。
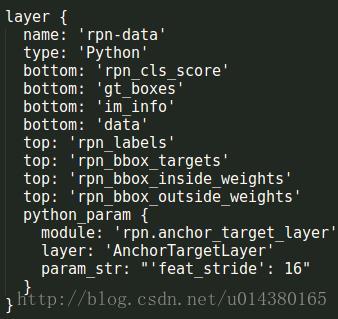
损失函数如下:分类的损失采用SoftmaxWithLoss,输入是reshape后的预测的类别score(1234263)和真实的label(1134263)。回归的损失采用SmoothL1Loss,输入是rpn_bbox_pred(1363863)即所有anchor的坐标相关的预测,rpn_bbox_targets(1363863),rpn_bbox_inside_weights(1363863),rpn_bbox_outside_weights(1363863)。
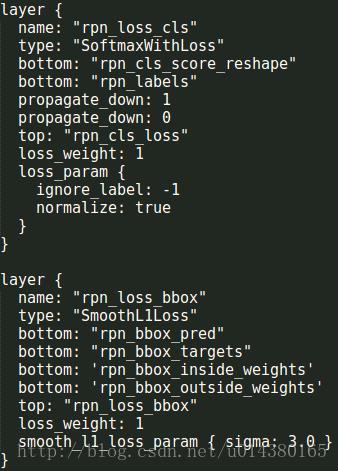
然后是ROI Proposal,先用一个softmax层算出概率(1234263),然后再reshape到1183863。
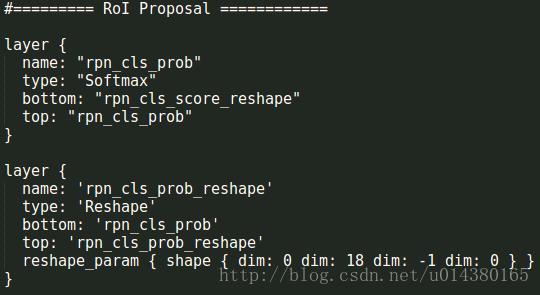
然后是生成proposal,维度是1*5。
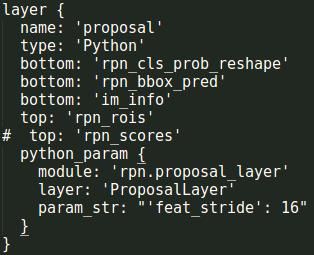
这一层生成rois(1511),labels(1111),bbox_targets(1811),bbox_inside_weights
(1811),bbox_outside_weights(181*1)。
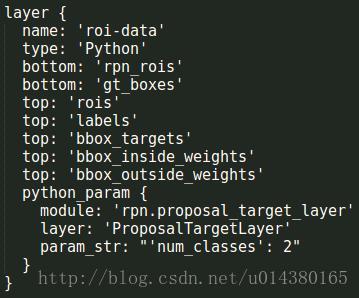
至此RPN网络结束。
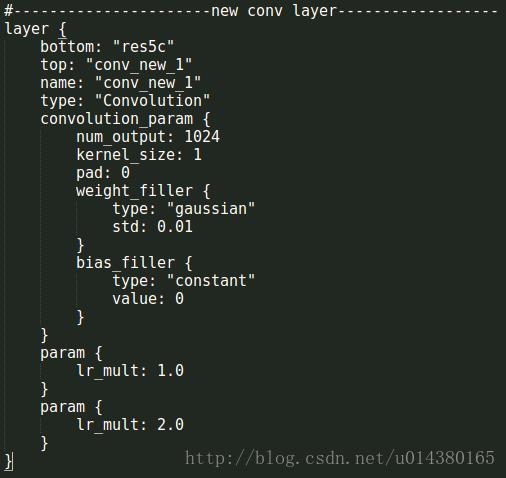
新的卷积层,其实就是在ResNet后面添加的卷积层,以res5c作为输入,用11的卷积核,pad=0的1024个卷积核的卷积层。得到110243863。
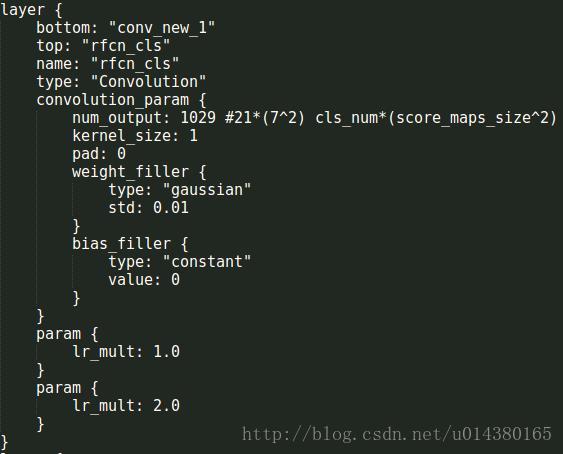
然后再分别跟两个卷积层,卷积核的大小都是1,pad=0,一个用于分类,一个用于回归。分类层如下:110293863,其中1029的含义在下图中也有解释,21是代表类别(VOC的20类加上背景1类),7是和ROI要划分成77的格子对应。
这个分类层的输出结果就是论文中的这个三维矩阵:
然后是回归层的输出:139238*63,与分类层类似。
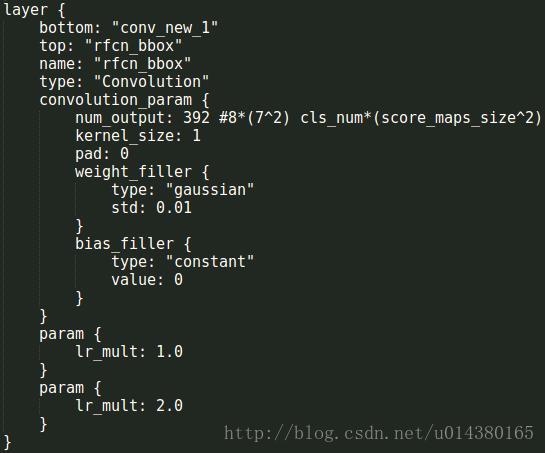
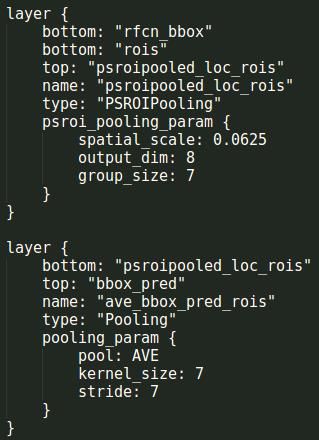
开始进入ROI pooling操作了,上面一层,有两个输入:rfcn_cls(110293863)是预测的结果,rois(1511)是ROI,生成12177的结果。下面一层是均值池化,得到12111(cls_score),就是论文中vote的过程。

所以上面这两个操作就是对应论文中的这个图:
同理,回归也是类似的操作:生成1877和1811(bbox_pred)的结果。
最后就是损失和计算准确率层:
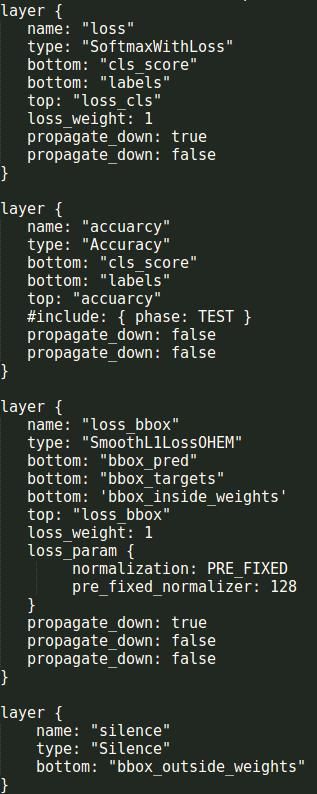
可以看出在ROI Pooling层后就没有卷积层和全连接层了。
总结:
R-FCN作为Faster RCNN的改进版,主要对原有的ROI Pooling层进行改进和移位,使得不会存在众多region proposal都得经过全连接层的情况,这样就加快了速度。另一方面改进是将原来的VGG16类型的主网络换成ResNet系列网络。而算法的另一部分RPN网络则和Faster RCNN基本差不多。总的来讲实验效果还是很不错的。