Python仿真及应用结课大作业—基于CNN的手写数字识别与涂鸦识别
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言
- 一、结课文档目录
- 二、涂鸦识别(篇幅问题只展示其一)
- 涂鸦识别
-
- 引入必要的库函数
- 导入数据
- 为各个数据文件添加标签
- 数据处理
- CNN模型构建
- 模型训练
- 绘制损失图与准确率图
- 模型预测--从测试集中抽取数据预测
- 模型预测--自己绘制图预测
- 总结
前言
提示:这里可以添加本文要记录的大概内容:
这是一篇基于python语言编写,使用tensorflow库实现CNN来进行分类识别图像。这份代码基于python语言书写用到的函数库有tensorflow,numpy,pandas,matplotlib. 此压缩包下有包含(CNN手写数字识别.ipynb,CNN涂鸦识别.ipynb,两个数据集分别是minist手写字符集和Google涂鸦集,因占用空间超过1G,采用蓝奏云盘的格式分享,附加一份结课文档可参考)。手写数字识别采用卷积神经网路识别minist手写数字集,涂鸦识别采用卷积神经网络识别涂鸦集,经实验效果良好,准确率达到98%以上。并且使用绘图软件自己绘图识别,测试图片为自己绘制。经实验,效果良好
以下网址附上了所有文件
https://download.csdn.net/download/loulita/86734631
提示:以下是本篇文章正文内容,下面案例可供参考
一、结课文档目录

二、涂鸦识别(篇幅问题只展示其一)

涂鸦识别
引入必要的库函数
从Google网站中精选10个涂鸦数据npy文件,用CNN识别图片
%matplotlib inline
import tensorflow as tf
import numpy as np
import os
import pandas as pd
import matplotlib.pyplot as plt
import keras
from keras.models import Sequential,load_model
from keras.layers import Dense,Dropout,Flatten
from keras.layers.convolutional import Conv2D,MaxPooling2D
from keras.utils import np_utils
from keras.callbacks import ModelCheckpoint
from keras import backend as K
K.set_image_data_format("channels_last")
Using TensorFlow backend.
导入数据
ant=np.load('data/ant.npy')
basketball=np.load('data/basketball.npy')
bear=np.load('data/bear.npy')
bed=np.load('data/bed.npy')
bicycle=np.load('data/bicycle.npy')
bird=np.load('data/bird.npy')
birthday_cake=np.load('data/birthday_cake.npy')
book=np.load('data/book.npy')
car=np.load('data/car.npy')
cat=np.load('data/cat.npy')
# The_Great_Wall_of_China=np.load('data/The_Great_Wall_of_China.npy')
dataname=['ant','basketball','bear','bed','bicycle','bird','birthday_cake','book','car','cat']
npdata=[ant,basketball,bear,bed,bicycle,bird,birthday_cake,book,car,cat]
for i in range(10):
print(npdata[i].shape)
(124612, 784)
(133793, 784)
(134762, 784)
(113862, 784)
(126527, 784)
(133572, 784)
(144982, 784)
(119364, 784)
(182764, 784)
(123202, 784)
为各个数据文件添加标签
此处因为原文件只包含了图数据,如上面shape所展示,每张图都是28*28的单通道图
在每张图的最后添加一个标签来表明它属于哪一类
#增加标签列0 ant,1 basketball 2bear...........
ant=np.c_[ant,0*np.ones(len(ant))]
basketball=np.c_[basketball,1*np.ones(len(basketball))]
bear=np.c_[bear,2*np.ones(len(bear))]
bed=np.c_[bed,3*np.ones(len(bed))]
bicycle=np.c_[bicycle,4*np.ones(len(bicycle))]
bird=np.c_[bird,5*np.ones(len(bird))]
birthday_cake=np.c_[birthday_cake,6*np.ones(len(birthday_cake))]
book=np.c_[book,7*np.ones(len(book))]
car=np.c_[car,8*np.ones(len(car))]
cat=np.c_[cat,9*np.ones(len(cat))]
# The_Great_Wall_of_China=np.c_[The_Great_Wall_of_China,10*np.ones(len(The_Great_Wall_of_China))]
可以看出每一行的最后添加了一个值,代表这张图的类别
car[0,784] #比如car属于8
8.0
显示函数,显示图片
#显示函数
def plot_samples(input_array,rows=1,cols=10,title=''):
fig,ax=plt.subplots(figsize=(cols,rows))
ax.axis('off')
plt.title(title,fontsize='20')
for i in list(range(0,min(len(input_array),(rows*cols)))):
a=fig.add_subplot(rows,cols,i+1)
imgpolt=plt.imshow(input_array[i,:784].reshape(28,28),cmap='gray_r',interpolation='nearest')
plt.xticks([])
plt.yticks([])
fig.tight_layout() # 调整间距
plt.style.use('seaborn')
for i in range(10):
plot_samples(npdata[i],title=str(i)+':'+dataname[i])








数据处理
把特征和标签分开,取1:1为训练集和测试集
#把10个数据集中的数据整合在一起,前784列数据作为特征X,最后一列为标签Y
from sklearn.model_selection import train_test_split ,GridSearchCV
npdata=[ant,basketball,bear,bed,bicycle,bird,birthday_cake,book,car,cat]
X=np.concatenate((npdata[0][:8000,:-1],npdata[1][:8000,:-1],npdata[2][:8000,:-1],npdata[3][:8000,:-1],npdata[4][:8000,:-1],
npdata[5][:8000,:-1],npdata[6][:8000,:-1],npdata[7][:8000,:-1],npdata[8][:8000,:-1],npdata[9][:8000,:-1]))
y=np.concatenate((npdata[0][:8000,-1],npdata[1][:8000,-1],npdata[2][:8000,-1],npdata[3][:8000,-1],npdata[4][:8000,-1],
npdata[5][:8000,-1],npdata[6][:8000,-1],npdata[7][:8000,-1],npdata[8][:8000,-1],npdata[9][:8000,-1]))
#分离训练集和测试机(除以255归一化)
#训练集和测试集的比例是1:1
X_train,X_test,y_train,y_test=train_test_split(X/255.,y,test_size=0.5,random_state=0)
将处理好的训练集与测试集的标签转化为独热编码,num_classes为类别数。
之后将训练集与测试集的特征reshape成需要的类型(28,28,1),代表28*28的单通道图像。
#转化为独热编码
y_train_cnn=np_utils.to_categorical(y_train)
y_test_cnn=np_utils.to_categorical(y_test)
num_classes=y_test_cnn.shape[1]
#重构为(图数量,通道数,宽,高)
X_train_cnn=X_train.reshape(X_train.shape[0],28,28,1).astype('float32')
X_test_cnn=X_test.reshape(X_test.shape[0],28,28,1).astype('float32')
print(X_train_cnn.shape,num_classes)
(40000, 28, 28, 1) 10
CNN模型构建
# filepath = 'checkpoint/trained_best_weights.h5'
# checkpoint=ModelCheckpoint(filepath,monitor='val_loss',save_weights_only=True,verbose=1,save_best_only=True,period=1)
def cnn_model():
model=Sequential()
model.add(Conv2D(30,(5,5),input_shape=(28,28,1),activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(15,(3,3),activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Dropout(0.2))
model.add(Flatten())
model.add(Dense(128,activation='relu'))
model.add(Dense(50,activation='relu'))
model.add(Dense(num_classes,activation='softmax'))
model.compile(loss='categorical_crossentropy',optimizer='adam',metrics=['accuracy'])
return model
模型:可以从下面看出,使用了两层卷积,两层池化,另外使用dropout随机丢弃一些神经单元降低过拟合,展平后,使用两次rule激活函数,最后用softmax做十分类。下面看模型训练。
#导入模型
model=cnn_model()
model.summary()
WARNING:tensorflow:From D:\ProgramData\Anaconda3\envs\tf1gpu\lib\site-packages\tensorflow_core\python\ops\resource_variable_ops.py:1630: calling BaseResourceVariable.__init__ (from tensorflow.python.ops.resource_variable_ops) with constraint is deprecated and will be removed in a future version.
Instructions for updating:
If using Keras pass *_constraint arguments to layers.
WARNING:tensorflow:From D:\ProgramData\Anaconda3\envs\tf1gpu\lib\site-packages\keras\backend\tensorflow_backend.py:4070: The name tf.nn.max_pool is deprecated. Please use tf.nn.max_pool2d instead.
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_1 (Conv2D) (None, 24, 24, 30) 780
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 12, 12, 30) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 10, 10, 15) 4065
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 5, 5, 15) 0
_________________________________________________________________
dropout_1 (Dropout) (None, 5, 5, 15) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 375) 0
_________________________________________________________________
dense_1 (Dense) (None, 128) 48128
_________________________________________________________________
dense_2 (Dense) (None, 50) 6450
_________________________________________________________________
dense_3 (Dense) (None, 10) 510
=================================================================
Total params: 59,933
Trainable params: 59,933
Non-trainable params: 0
_________________________________________________________________
模型训练
训练30轮,每批50
#断点续传
# if os.path.exists(filepath):
# model.load_weights(filepath)
# print('checkpoint loaded')
#拟合模型
history=model.fit(X_train_cnn,y_train_cnn,validation_data=(X_test_cnn,y_test_cnn),epochs=30,batch_size=50)
#最终结果
scores=model.evaluate(X_test_cnn,y_test_cnn,verbose=0)
print('最终准确率:',scores[1]*100,'%')
#保存权重
# model.save_weights('quickdraw_neuralnet.h5')
# model.save('quickdraw.model')
# print('模型已保存!')
WARNING:tensorflow:From D:\ProgramData\Anaconda3\envs\tf1gpu\lib\site-packages\keras\backend\tensorflow_backend.py:422: The name tf.global_variables is deprecated. Please use tf.compat.v1.global_variables instead.
Train on 40000 samples, validate on 40000 samples
Epoch 1/30
40000/40000 [==============================] - 8s 209us/step - loss: 0.9518 - accuracy: 0.6886 - val_loss: 0.6067 - val_accuracy: 0.8102
Epoch 2/30
40000/40000 [==============================] - 5s 132us/step - loss: 0.5642 - accuracy: 0.8199 - val_loss: 0.4635 - val_accuracy: 0.8566
Epoch 3/30
40000/40000 [==============================] - 5s 130us/step - loss: 0.4703 - accuracy: 0.8494 - val_loss: 0.4353 - val_accuracy: 0.8621
Epoch 4/30
40000/40000 [==============================] - 5s 120us/step - loss: 0.4161 - accuracy: 0.8662 - val_loss: 0.3844 - val_accuracy: 0.8799
Epoch 5/30
40000/40000 [==============================] - 5s 120us/step - loss: 0.3831 - accuracy: 0.8760 - val_loss: 0.3677 - val_accuracy: 0.8831
Epoch 6/30
40000/40000 [==============================] - 5s 119us/step - loss: 0.3573 - accuracy: 0.8836 - val_loss: 0.3530 - val_accuracy: 0.8887
Epoch 7/30
40000/40000 [==============================] - 5s 120us/step - loss: 0.3323 - accuracy: 0.8923 - val_loss: 0.3543 - val_accuracy: 0.8882
Epoch 8/30
40000/40000 [==============================] - 5s 119us/step - loss: 0.3153 - accuracy: 0.8964 - val_loss: 0.3378 - val_accuracy: 0.8933
Epoch 9/30
40000/40000 [==============================] - 5s 118us/step - loss: 0.2952 - accuracy: 0.9020 - val_loss: 0.3293 - val_accuracy: 0.8963
Epoch 10/30
40000/40000 [==============================] - 5s 130us/step - loss: 0.2793 - accuracy: 0.9066 - val_loss: 0.3259 - val_accuracy: 0.8975
Epoch 11/30
40000/40000 [==============================] - 5s 130us/step - loss: 0.2637 - accuracy: 0.9134 - val_loss: 0.3471 - val_accuracy: 0.8938
Epoch 12/30
40000/40000 [==============================] - 5s 125us/step - loss: 0.2591 - accuracy: 0.9128 - val_loss: 0.3257 - val_accuracy: 0.8985
Epoch 13/30
40000/40000 [==============================] - 5s 124us/step - loss: 0.2460 - accuracy: 0.9164 - val_loss: 0.3244 - val_accuracy: 0.9014
Epoch 14/30
40000/40000 [==============================] - 5s 121us/step - loss: 0.2352 - accuracy: 0.9217 - val_loss: 0.3422 - val_accuracy: 0.8970
Epoch 15/30
40000/40000 [==============================] - 5s 127us/step - loss: 0.2283 - accuracy: 0.9227 - val_loss: 0.3364 - val_accuracy: 0.8976
Epoch 16/30
40000/40000 [==============================] - 5s 121us/step - loss: 0.2205 - accuracy: 0.9243 - val_loss: 0.3303 - val_accuracy: 0.8997
Epoch 17/30
40000/40000 [==============================] - 5s 123us/step - loss: 0.2078 - accuracy: 0.9309 - val_loss: 0.3443 - val_accuracy: 0.8986
Epoch 18/30
40000/40000 [==============================] - 5s 120us/step - loss: 0.2027 - accuracy: 0.9298 - val_loss: 0.3442 - val_accuracy: 0.9004
Epoch 19/30
40000/40000 [==============================] - 5s 126us/step - loss: 0.1969 - accuracy: 0.9330 - val_loss: 0.3397 - val_accuracy: 0.9004
Epoch 20/30
40000/40000 [==============================] - 5s 122us/step - loss: 0.1883 - accuracy: 0.9362 - val_loss: 0.3438 - val_accuracy: 0.8975
Epoch 21/30
40000/40000 [==============================] - 5s 120us/step - loss: 0.1820 - accuracy: 0.9377 - val_loss: 0.3412 - val_accuracy: 0.9002
Epoch 22/30
40000/40000 [==============================] - 5s 117us/step - loss: 0.1801 - accuracy: 0.9387 - val_loss: 0.3542 - val_accuracy: 0.8990
Epoch 23/30
40000/40000 [==============================] - 5s 120us/step - loss: 0.1767 - accuracy: 0.9391 - val_loss: 0.3445 - val_accuracy: 0.9028
Epoch 24/30
40000/40000 [==============================] - 5s 121us/step - loss: 0.1692 - accuracy: 0.9410 - val_loss: 0.3515 - val_accuracy: 0.8996
Epoch 25/30
40000/40000 [==============================] - 5s 118us/step - loss: 0.1682 - accuracy: 0.9420 - val_loss: 0.3718 - val_accuracy: 0.8965
Epoch 26/30
40000/40000 [==============================] - 5s 120us/step - loss: 0.1641 - accuracy: 0.9428 - val_loss: 0.3686 - val_accuracy: 0.8975
Epoch 27/30
40000/40000 [==============================] - 5s 121us/step - loss: 0.1575 - accuracy: 0.9453 - val_loss: 0.3719 - val_accuracy: 0.8966
Epoch 28/30
40000/40000 [==============================] - 5s 134us/step - loss: 0.1541 - accuracy: 0.9469 - val_loss: 0.3755 - val_accuracy: 0.8988
Epoch 29/30
40000/40000 [==============================] - 6s 141us/step - loss: 0.1536 - accuracy: 0.9480 - val_loss: 0.3771 - val_accuracy: 0.8959
Epoch 30/30
40000/40000 [==============================] - 6s 144us/step - loss: 0.1499 - accuracy: 0.9477 - val_loss: 0.3805 - val_accuracy: 0.8995
最终准确率: 89.94500041007996 %
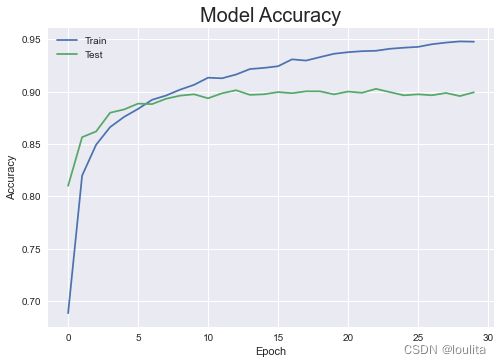
从上可看出,训练准确率达到90%左右,训练结果良好。
绘制损失图与准确率图
#输出准确率变化
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title('Model Accuracy',fontsize='20')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['Train','Test'],loc='upper left')
plt.show()
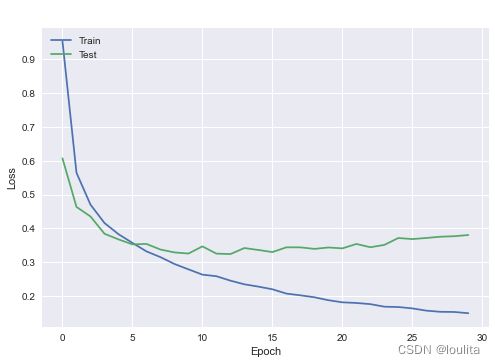
#损失值变化
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model Loss',fontsize='20',color='white')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train','Test'],loc='upper left')
plt.show()
# model=load_model('quickdraw.model')
# model.summary()
img_width=28
img_heigth=28
模型预测–从测试集中抽取数据预测
#将标签保存在字典中
label_dict={0:'蚂蚁',1:'篮球',2:'熊',3:'床',4:'自行车',5:'小鸟',6:'生日蛋糕',7:'书',8:'车',9:'猫'}
dataname=['ant','basketball','bear','bed','bicycle','bird','birthday_cake','book','car','cat']
label_dict_EN={0:'ant',1:'basketball',2:'bear',3:'bed',4:'bicycle',5:'bird',6:'birthday_cake',7:'book',8:'car',9:'cat'}
#预测值
cnn_probab=model.predict(X_test_cnn,batch_size=32,verbose=0)
fig,ax=plt.subplots(figsize=(15,25))
for i in list(range(5)):
print('这幅涂鸦是-->',label_dict[y_test[i]],'<--的可能性为',max(cnn_probab[i]*100))
#可能性表
ax=plt.subplot2grid((5,5),(i,0),colspan=4)
plt.bar(np.arange(10),cnn_probab[i],0.35,align='center')
plt.xticks(np.arange(10),dataname,fontsize='15')
plt.tick_params(axis='x',bottom='off',top='off')
plt.ylabel('Probability',fontsize='15')
plt.ylim(0,1)
plt.subplots_adjust(hspace=0.5)
#数据集中的照片
ax=plt.subplot2grid((5,5),(i,4),colspan=1)
plt.imshow(X_test[i].reshape(28,28),cmap='gray_r',interpolation='nearest')
plt.xlabel(label_dict_EN[y_test[i]],fontsize='15')
plt.xticks([])
plt.yticks([])
fig.tight_layout() # 调整间距
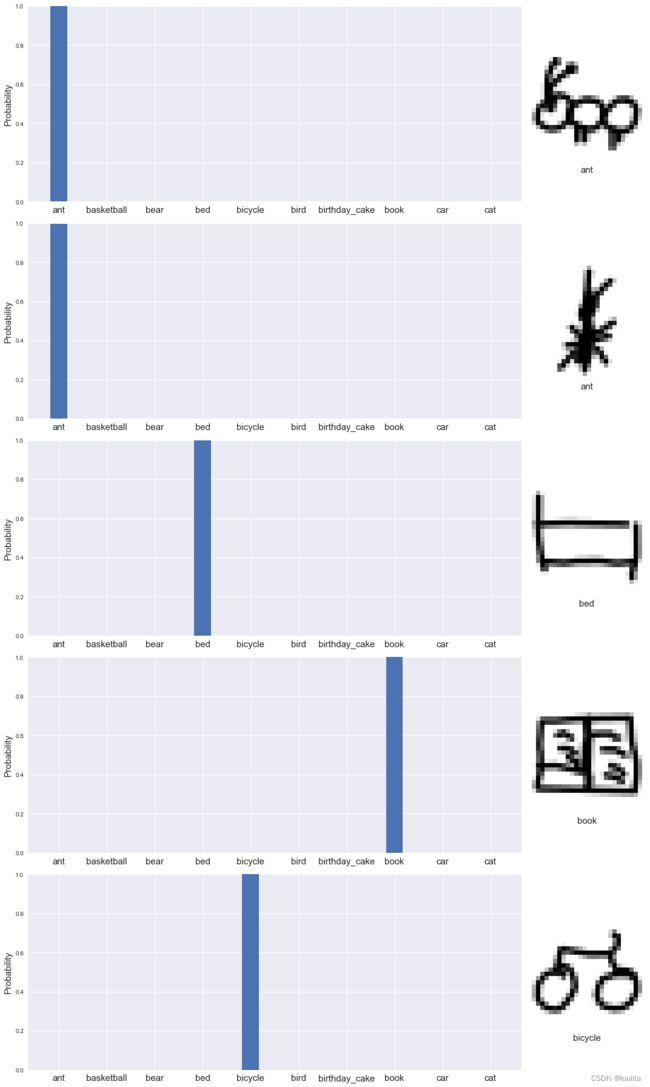
这幅涂鸦是--> 蚂蚁 <--的可能性为 99.905876
这幅涂鸦是--> 蚂蚁 <--的可能性为 99.75111
这幅涂鸦是--> 床 <--的可能性为 99.977425
这幅涂鸦是--> 书 <--的可能性为 100.0
这幅涂鸦是--> 自行车 <--的可能性为 100.0
模型预测–自己绘制图预测
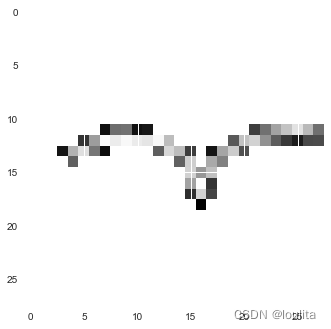
首先,绘制图片并保存到工作目录下,将图片更改尺寸,变为单通道,转化为model.predict()能识别的形式。
import cv2
img=cv2.imread('test.png',0)
ret,thresh1=cv2.threshold(img,127,255,cv2.THRESH_BINARY)
img=cv2.resize(img,(28,28))
plt.imshow(img.reshape(28,28),cmap='gray_r')
arr=np.array(img-255)
arr=np.array(arr/255.)
new_test_cnn=arr.reshape(1,28,28,1).astype('float32')
print(new_test_cnn.shape)
plt.imshow(arr.reshape(28,28),cmap='gray_r')
(1, 28, 28, 1)
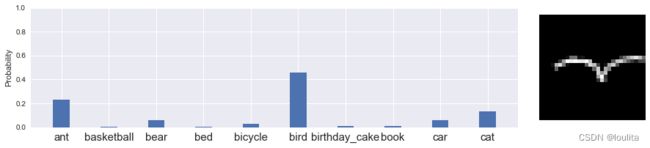
从预测向量new_cnn_predict中找出最大值及其索引,其对应的值便是所预测的对象。
import operator
#cnn预测
new_cnn_predict=model.predict(new_test_cnn,batch_size=32,verbose=0)
print(new_cnn_predict.shape)
print(new_cnn_predict)
max_index,max_value=max(enumerate(new_cnn_predict[0]),key=operator.itemgetter(1))
print(max_index)
print(max_value)
(1, 10)
[[0.23165826 0.00453422 0.05984405 0.00499108 0.0295788 0.45546314
0.01262143 0.01191937 0.05922865 0.13016103]]
5
0.45546314
可以发现这幅图像鸟的可能性在这十个分类中最大,所以给出的预测结果为鸟。
fig,ax=plt.subplots(figsize=(15,3))
print('这副涂鸦是-->',label_dict[max_index],'<--的可能性为',max_value*100)
for i in list(range(1)):
#可能性表
ax=plt.subplot2grid((1,5),(i,0),colspan=4)
plt.bar(np.arange(10),new_cnn_predict[i],0.35,align='center')
plt.xticks(np.arange(10),dataname,fontsize='15')
plt.tick_params(axis='x',bottom='off',top='off')
plt.ylabel('Probability')
plt.ylim(0,1)
plt.subplots_adjust(hspace=0.5)
#数据集中的照片
ax=plt.subplot2grid((1,5),(i,4),colspan=1)
plt.imshow(img.reshape(28,28),cmap='gray_r',interpolation='nearest')
plt.xticks([])
plt.yticks([])
这副涂鸦是--> 小鸟 <--的可能性为 45.546314120292664
本实验通过卷积神经网络识别十种不同图像,以达到多分类的效果。
总结

此篇博客展示内容为涂鸦识别,令附有手写数字识别大致与此篇内容相仿,故不在展示。
https://download.csdn.net/download/loulita/86734631
目录展示如上图所示,详细内容还请参照以上网址,如果觉得有用,请点个赞哦!!!