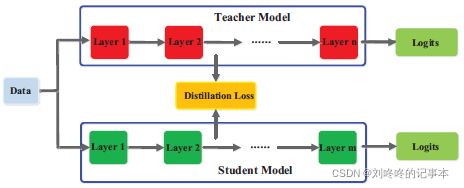
知识蒸馏 (一) 综述
一、综述
*《Knowledge Distillation: A Survey》2021 IJCV
《Knowledge Distillation and Student-Teacher Learning for Visual Intelligence: A Review and New》 2021 TPAMI
1、Knowledge:
1) Response-Based Knowledge


![]()
LR: Kullback-Leibler divergence loss
2) Feature-Based Knowledge
![]()
![]() : The transformation functions, applied when the feature maps of teacher and student models are not in the same shape
: The transformation functions, applied when the feature maps of teacher and student models are not in the same shape
![]() : the similarity function used to match the feature maps of teacher and student models
: the similarity function used to match the feature maps of teacher and student models
l2-norm distance, l1-norm distance, cross-entropy loss, maximum mean discrepancy loss
Maximum Mean Discrepancy(MMD):衡量两个分布的相似性
3) Relation-Based Knowledge
based on the relations of feature maps:![]()
LR1:the correlation function between the teacher and student feature maps.
based on the instance relations:![]()
LR2: the correlation function between the teacher and student feature representations
Earth Mover distance, Huber loss, Angle-wise loss, Frobenius norm
2、Schemes:
1)Offline Distillation
2)Online Distillation
-
Deep Mutual Learning(dml)提出让多个网络以合作的方式进行学习,任何一个网络可以作为学生网络,其他的网络可以作为教师网络。
-
Online Knowledge Distillation via Collaborative Learning提出使用soft logits继承的方式来提升dml的泛化性能。
-
Oneline Knowledge distillation with diverse peers进一步引入了辅助peers和一个group leader来引导互学习过程。
-
为了降低计算代价,Knowledge Distillation by on-the-fly native ensemble通过提出一个多分支的架构,每个分支可以作为一个学生网络,不同的分支共享相同的的backbone。
-
Feature fusion for online mutual knowledge distillation提出了一种特征融合模块来构建教师分类器。
-
Training convolutional neural networks with cheap convolutions and online distillation提出使用cheap convolutioin来取代原先的conv层构建学生网络。
-
Large scale distributed neural network training throgh online distillation采用在线蒸馏训练大规模分布式网络模型,提出了一种在线蒸馏的变体-co-distillation。co-distillation同时训练多个相同架构的模型,每一个模型都是经由其他模型训练得到的。
-
Feature-map-level online adversarial knowledge distillation提出了一种在线对抗知识蒸馏方法,利用类别概率和特征图的知识,由判别器同时训练多个网络
3)Self-Distillation
在自蒸馏中,教师和学生模型使用相同的网络。自蒸馏可以看作是在线蒸馏的一种特殊情况,因为教师网络和学生网络使用的是相同的模型。
-
Be your own teacher: Improve the performance of convolutional neural networks via self distillation 提出了一种新的自蒸馏方法,将网络较深部分的知识蒸馏到网络较浅部分。
-
Snapshot distillation:Teacher-student optimization in one generation 是自蒸馏的一种特殊变体,它将网络早期阶段(教师)的知识转移到后期阶段(学生),以支持同一网络内有监督的培训过程。
-
为了进一步减少推断的时间,Distillation based training for multi-exit architectures提出了基于蒸馏的训练方案,即浅层exit layer在训练过程中试图模拟深层 exit layer的输出。
-
最近,自蒸馏已经在Self-distillation amplifies regularization in hilbert space进行了理论分析,并在Self-Distillation as Instance-Specific Label Smoothing中通过实验证明了其改进的性能。
-
Revisit knowledge distillation: a teacher-free framework 提出了一种基于标签平滑化的无教师知识蒸馏方法。
-
Regularizing Class-wise Predictions via Self-knowledge Distillation提出了一种基于类间(class-wise)的自我知识蒸馏,以与相同的模型在同一源中,在同一源内的训练模型的输出分布相匹配。
-
Rethinking data augmentation: Self-supervision and self-distillation提出的自蒸馏是为数据增强所采用的,并对知识进行增强,以此提升模型本身的性能。
3、structure:
(1)教师网络的简化版本,具有更少的层和每层更少的通道
(2)保留网络结构的教师网络的量化版本
(3)具有高效基本操作的小型网络
(4)具有全局优化过网络结构的小型网络
(5)和教师一样的网络
主要难点:
(1)解决模型容量差距造成的知识转移性能的降低
-
Improved knowledge distillation via teacher assistant引入教师助理,缓解教师模式和学生模式之间的训练gap。
-
Residual Error Based Knowledge Distillation提出使用残差学习来降低训练gap,辅助的结构主要用于学习残差错误。
(2)最小化学生模型和教师模型结构上差异 。
-
Model compression via distillation and quantization将网络量化与知识蒸馏相结合,即学生模型是教师模型的量化版本。
-
Deep net triage: Analyzing the importance of network layers via structural compression.提出了一种结构压缩方法,将多个层学到的知识转移到单个层。
-
Progressive blockwise knowledge distillation for neural network acceleration在保留感受野的同时,从教师网络向学生网络逐步进行block-wise的知识转移。
4、Cross-Modal Distillation
需配对样本
5、Multi-Teacher Distillation
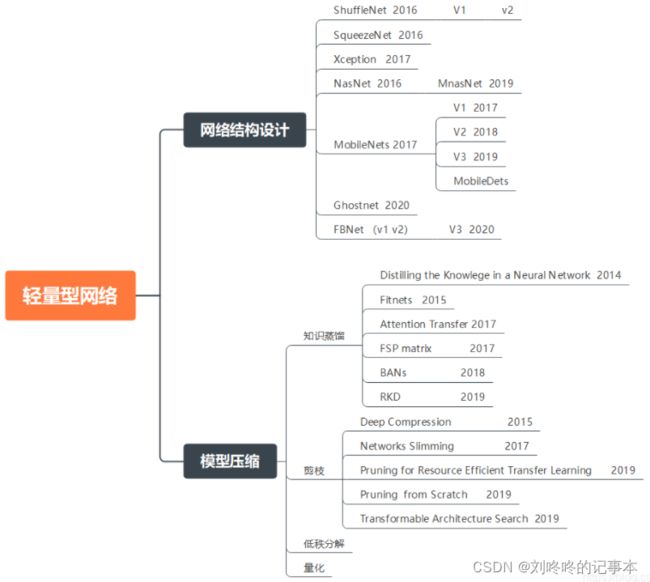
6、其他资料
知识蒸馏(Knowledge Distillation)_Law-Yao的博客-CSDN博客_知识蒸馏
4、
GitHub - dkozlov/awesome-knowledge-distillation: Awesome Knowledge Distillation
https://github.com/FLHonker/Awesome-Knowledge-Distillation
5、
「知识蒸馏」最新2022研究综述 - 云+社区 - 腾讯云
知识蒸馏paper分类整理(2014-2020)_frankliu624的博客-CSDN博客
https://www.cnblogs.com/pprp/p/15682787.html