迁移学习
简介
好的机器学习模型需要大量数据和许多GPU或TPU进行训练。大多数时候,他们只能执行特定的任务。
大学和大公司有时会发布他们的模型。但很可能你希望开发一个机器学习应用程序,但没有适合你的任务的可用模型。
但别担心,你不必收集大量数据,也不必花费大量资金来开发自己的模型。你可以用迁移学习代替。这减少了训练时间,并且可以用更少的数据获得良好的性能。
什么是迁移学习?
在迁移学习中,我们使用模型在特定任务上收集的知识来解决不同但相关的任务。模型可以从上一个任务中学到的东西中获益,从而更快地学习新任务。
让我们在这里举个例子,假设你想在图像上检测狗。在互联网上,你可以找到一种可以检测猫的模型。由于这是一项非常类似的任务,你需要拍摄几张你的狗的照片,并重新训练模型以检测狗。
也许模型已经学会了通过猫的皮毛或它们有眼睛的事实来识别猫,这对识别狗也会很有帮助。
实际上有两种类型的迁移学习,特征提取和微调。
通常,这两种方法遵循相同的程序:
初始化预训练的模型(我们要学习的模型)
重塑最终层的形状,使其输出数量与新数据集中分类的数量相同
定义要更新的层
训练新数据集
特征提取
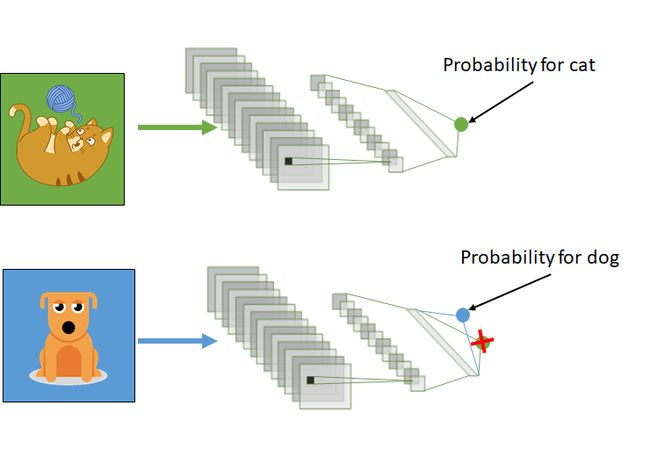
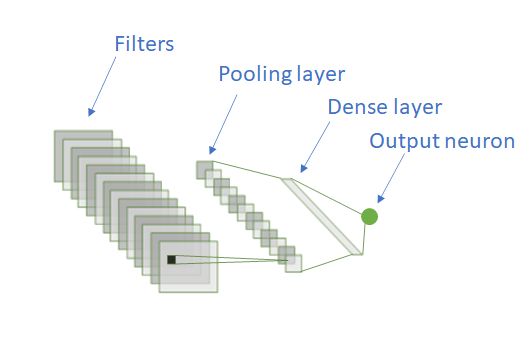
让我们考虑一个卷积神经网络结构,滤波器是一个密集层和一个输出神经元。
该网络经过训练,可以预测图像上有猫的概率。我们需要一个大数据集(有猫和没有猫的图像),而且训练时间很长。此步骤称为“预训练”。

然后是有趣的部分。我们再次训练网络,但这次是用一个包含狗的小图像数据集。
在训练过程中,除输出层外的所有层都被“冻结”。这意味着我们不会在训练期间更新它们。
训练后,网络输出狗在图像上可见的概率。此训练程序所需时间将少于之前的预训练。

我们还可以选择“解冻”最后两层,即输出层和密集层。这取决于我们拥有的数据量。如果我们有更少的数据,我们可以考虑只训练最后一层。
微调
在微调中,我们从预训练的模型开始,但更新所有权重。
pytorch中的迁移学习示例
将使用kaggle的猫与狗数据集。数据集可以在这里找到。你始终可以使用不同的数据集。
https://www.microsoft.com/en-us/download/details.aspx?id=54765
这里的任务与上面的示例略有不同。该模型用于识别哪些图像上有狗,哪些图像上有猫。要使代码正常工作,你必须按以下结构组织数据:
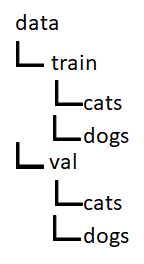
你可以在这里找到更详细的猫与狗的对比。
https://medium.com/predict/using-pytorch-for-kaggles-famous-dogs-vs-cats-challenge-part-1-preprocessing-and-training-407017e1a10c
安装程序
我们首先导入所需的库。
from __future__ import print_function
from __future__ import division
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import torchvision
from torchvision import datasets, models, transforms
import matplotlib.pyplot as plt
import time
import os
import copy
print("PyTorch Version: ",torch.__version__) # PyTorch Version: 1.7.1
print("Torchvision Version: ",torchvision.__version__) # Torchvision Version: 0.8.0a0我们检查是否有与CUDA兼容的CPU,否则将使用该CPU。

然后我们从torch vision加载预训练的ResNet50。
model_conv = torchvision.models.resnet50(pretrained=True)数据扩充是通过对图像应用不同的变换来完成的,从而防止过拟合。
# 训练数据的增强和标准化
# 只是为了验证而进行标准化
data_transforms = {
'train': transforms.Compose([
transforms.RandomRotation(5),
transforms.RandomHorizontalFlip(),
transforms.RandomResizedCrop(224, scale=(0.96, 1.0), ratio=(0.95, 1.05)),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'val': transforms.Compose([
transforms.Resize([224,224]),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}我们创建数据加载器,它将从内存中加载图像。
data_dir = 'data' #数据集目录
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x),
data_transforms[x])
for x in ['train', 'val']}
dataloaders = {x: torch.utils.data.DataLoader(image_datasets[x], batch_size=4,
shuffle=True, num_workers=4)
for x in ['train', 'val']}
dataset_sizes = {x: len(image_datasets[x]) for x in ['train', 'val']}
class_names = image_datasets['train'].classes
print(class_names) # => ['cats', 'dogs']
print(f'Train image size: {dataset_sizes["train"]}')
print(f'Validation image size: {dataset_sizes["val"]}')创建学习率调度器,调度器将在训练期间修改学习率。或者,你可以使用ADAM优化器,它可以自动调整学习速率,并且不需要调度器。
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_conv, step_size=7, gamma=0.1)特征提取优化器
这里只计算最后一层的梯度,因此只训练最后一层。
for param in model_conv.parameters():
param.requires_grad = False# 新构造模块的参数默认为require_grad =True
num_ftrs = model_conv.fc.in_features
model_conv.fc = nn.Linear(num_ftrs, 2)
model_conv = model_conv.to(device)
criterion = nn.CrossEntropyLoss()# 观察到只有最后一层的参数被优化
optimizer_feature_extraction = optim.SGD(model_conv.fc.parameters(), lr=0.001, momentum=0.9)# 衰减因子用于微调的优化器
在这里,将对所有层进行训练。

训练
让我们定义训练循环。
def train_model(model, criterion, optimizer, scheduler, num_epochs=2, checkpoint = None):
model.train() # 将model设置为训练模式
for i, (inputs, labels) in enumerate(dataloaders['train']):
inputs = inputs.to(device)
labels = labels.to(device)# 传送到设备
optimizer.zero_grad()
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)# 只有在训练阶段才backward + optimize
loss.backward()
optimizer.step()# 统计数据
scheduler.step()
return model最后,我们可以训练我们的模型。
使用特征提取:

或使用微调:
trained_model = train_model(model_conv, criterion, optimizer_fine_tuning, exp_lr_scheduler )迁移学习的优点
当我向人们推荐他们可以在ML项目中使用迁移学习时,他们有时会拒绝,宁愿自己训练一个模型,也不愿使用迁移学习。但是迁移学习也有很多优点:
训练神经网络使用能源,从而增加全球碳排放。迁移学习通过减少训练时间拯救了世界。
当训练数据不足时,迁移学习可能是让模型表现良好的唯一选择。在计算机视觉中,常常缺少训练数据。
结论
迁移学习对于现代数据科学家来说是一个方便的工具。为了节省时间、计算机资源和减少训练所需的数据量,你可以使用其他人预训练过的模型并对其执行迁移学习。
数据集集合
猫与狗数据集
数据集可在下找到。
https://www.tensorflow.org/datasets/catalog/cats_vs_dogs
感谢阅读!
☆ END ☆
如果看到这里,说明你喜欢这篇文章,请转发、点赞。微信搜索「uncle_pn」,欢迎添加小编微信「 woshicver」,每日朋友圈更新一篇高质量博文。
↓扫描二维码添加小编↓
