【Pytorch笔记-02】完整学习笔记
【Pytorch笔记-02】CNN:卷积神经网络
- 最大池化
- 激活函数
- 线性层及其他层介绍
-
- 正则化
- Recurrent layers
- Transform
- 线性层
- Dropout layers
- Sequential
- 损失函数与反向传播
-
- MSELoss
- 交叉熵
- 继续测试交叉熵
- 梯度下降
- 优化器
- 现有网络模型的使用及修改
- 网络模型的保存与读取
-
- 模型的保存
- 模型的加载
- 完整的模型训练套路
-
- 完整训练套路2:保存模型,查看tensorboard,测试集
- 完整训练套路2:保存模型,查看tensorboard,测试集+计算accuracy
- 利用GPU进行训练
-
- 第一种方法
- 第2种方法
- 神经网络基本迭代:非常好
欢迎关注我们的微信公众号 运小筹

Pytorch的文档网站
https://pytorch.org/docs/stable/nn.html
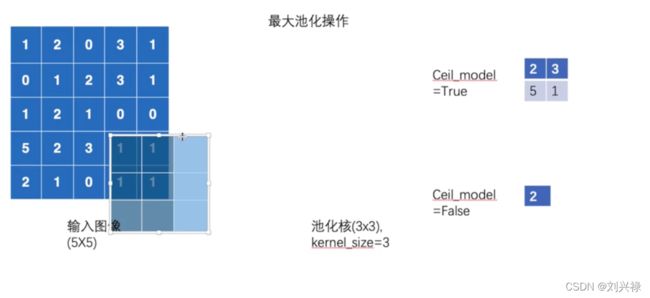
最大池化

import torch
import torchvision
from torch import nn
from torch.nn import MaxPool2d
from torch.utils.tensorboard import SummaryWriter
from torch.utils.data import DataLoader
from torch import nn
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("../data", # 下载到这个路径来
train=False,
transform=torchvision.transforms.ToTensor(),
download=True
)
dataloader = DataLoader(dataset, batch_size=64)
input = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]], dtype=torch.float32)
input = torch.reshape(input, (-1, 1, 5, 5))
print(input.shape)
class My_NN(nn.Module):
def __init__(self):
super(My_NN, self).__init__()
self.maxpool1 = MaxPool2d(kernel_size=3, ceil_mode=True)
def forward(self, input):
output = self.maxpool1(input)
return output
writer = SummaryWriter("logs_maxpool")
step = 0
My_nn = My_NN()
for data in dataloader:
imgs, targets = data
writer.add_images("input", imgs, step)
output = My_nn(imgs)
writer.add_images("output", output, step)
step += 1
# tensorboard --logdir=logs_maxpool
writer.close()
# output = My_nn(input)
# print(output)
激活函数
import torch
import torchvision
from torch.nn import ReLU
from torch.nn import Sigmoid
from torch import nn
from torch.nn import MaxPool2d
from torch.utils.tensorboard import SummaryWriter
from torch.utils.data import DataLoader
from torch import nn
from torch.utils.tensorboard import SummaryWriter
"""
这些数据用来测试ReLU
"""
input = torch.tensor([[1, -0.5],
[-1, 3]])
input = torch.reshape(input, (-1, 1, 2, 2))
print(input.shape)
dataset = torchvision.datasets.CIFAR10("../data", # 下载到这个路径来
train=False,
transform=torchvision.transforms.ToTensor(),
download=True
)
dataloader = DataLoader(dataset, batch_size=64)
class My_NN(nn.Module):
def __init__(self):
super(My_NN, self).__init__()
self.relu1 = ReLU()
self.sigmoid1 = Sigmoid()
def forward(self, input):
# output = self.relu1(input)
output = self.sigmoid1(input)
return output
My_nn = My_NN()
output = My_nn(input)
print(output)
"""
结果为:
tensor([[[[1., 0.],
[0., 3.]]]])
"""
writer = SummaryWriter("logs_ReLU")
step = 0
"""
这里可以debug看看data的内容
imgs, targets = data
这里,imgs就是将图像转化成了tensor
targets是标签,当batch=64的时候,这个就是1*64的一个向量
因为上面已经设置了transform=torchvision.transforms.ToTensor(),转化成了tensor
"""
for data in dataloader:
imgs, targets = data
writer.add_images("input", imgs, step)
output = My_nn(imgs)
writer.add_images("output", output, step)
step += 1
# tensorboard --logdir=logs_ReLU
writer.close()
#
# # output = My_nn(input)
# # print(output)
线性层及其他层介绍
正则化
用的是比较少的


Recurrent layers

Transform

线性层
线性层的说明:
https://pytorch.org/docs/stable/generated/torch.nn.Linear.html#torch.nn.Linear



import torch
import torchvision
from torch import nn
from torch.nn import MaxPool2d
from torch.utils.tensorboard import SummaryWriter
from torch.nn import Linear
from torch.utils.data import DataLoader
from torch import nn
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("../data", # 下载到这个路径来
train=False,
transform=torchvision.transforms.ToTensor(),
download=True
)
dataloader = DataLoader(dataset, batch_size=64)
class My_net(nn.Module):
def __init__(self):
super(My_net, self).__init__()
self.linear1 = Linear(196608, 10) # 10就是输出了
def forward(self, input):
output = self.linear1(input)
return output
my_net = My_net()
for data in dataloader:
imgs, targets = data
print('imgs:', imgs.shape)
output = torch.reshape(imgs, (1, 1, 1, -1))
print('output:', output.shape)
output = torch.flatten(imgs)
print('output:', output.shape)
output = my_net(output) # 这里由于最后一个数据不统一,所以可能会报错
print('output:', output.shape)
Dropout layers
防止过拟合


Sequential
https://pytorch.org/docs/stable/generated/torch.nn.Sequential.html#torch.nn.Sequential
- cifar10


下面就来写这个模型



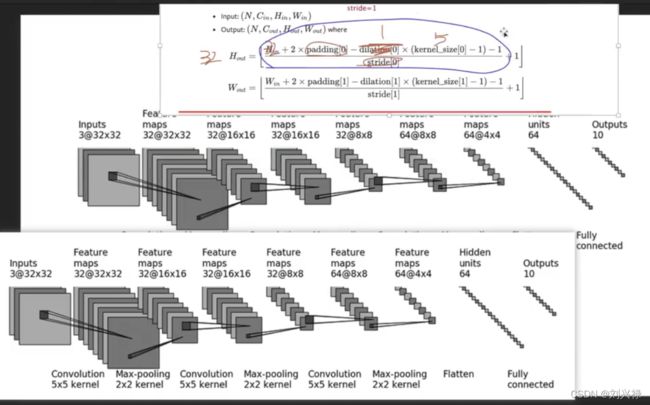
stride = 1
padding=2

import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear
class My_Seq_Net(nn.Module):
def __init__(self):
super(My_Seq_Net, self).__init__()
self.conv1 = Conv2d(in_channels=3, out_channels=32, kernel_size=5, padding=2)
self.maxpool1 = MaxPool2d(kernel_size=2)
self.conv2 = Conv2d(in_channels=32, out_channels=32, kernel_size=5, padding=2)
self.maxpool2 = MaxPool2d(kernel_size=2)
self.conv3 = Conv2d(in_channels=32, out_channels=64, kernel_size=5, padding=2)
self.maxpool3 = MaxPool2d(kernel_size=2)
self.flatten = Flatten()
self.linear1 = Linear(in_features=1024, out_features=64)
self.linear2 = Linear(in_features=64, out_features=10)
def forward(self):
x = self.conv1(x)
x = self.maxpool1(x)
x = self.conv2(x)
x = self.maxpool2(x)
x = self.conv3(x)
x = self.maxpool3(x)
x = self.flatten(x)
x = self.linear1(x)
x = self.linear2(x)
return x
my_seq_net = My_Seq_Net()
print(my_seq_net)
# 下面是对网络结构进行检验
input = torch.ones(64, 3, 32, 32) # batch_size = 64
output = my_seq_net(input)
print(output.shape)
"""
torch.Size([64, 10])
"""
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.tensorboard import SummaryWriter
class My_Seq_Net(nn.Module):
def __init__(self):
super(My_Seq_Net, self).__init__()
# self.conv1 = Conv2d(in_channels=3, out_channels=32, kernel_size=5, padding=2)
# self.maxpool1 = MaxPool2d(kernel_size=2)
# self.conv2 = Conv2d(in_channels=32, out_channels=32, kernel_size=5, padding=2)
# self.maxpool2 = MaxPool2d(kernel_size=2)
# self.conv3 = Conv2d(in_channels=32, out_channels=64, kernel_size=5, padding=2)
# self.maxpool3 = MaxPool2d(kernel_size=2)
# self.flatten = Flatten()
# self.linear1 = Linear(in_features=1024, out_features=64)
# self.linear2 = Linear(in_features=64, out_features=10)
self.model1 = Sequential(
Conv2d(in_channels=3, out_channels=32, kernel_size=5, padding=2),
MaxPool2d(kernel_size=2),
Conv2d(in_channels=32, out_channels=32, kernel_size=5, padding=2),
MaxPool2d(kernel_size=2),
Conv2d(in_channels=32, out_channels=64, kernel_size=5, padding=2),
MaxPool2d(kernel_size=2),
Flatten(),
Linear(in_features=1024, out_features=64),
Linear(in_features=64, out_features=10),
)
def forward(self, x):
x = self.model1(x)
return x
my_seq_net = My_Seq_Net()
print(my_seq_net)
# 下面是对网络结构进行检验
input = torch.ones((64, 3, 32, 32)) # batch_size = 64
output = my_seq_net(input)
print(output.shape)
writer = SummaryWriter("logs_seq")
writer.add_graph(model=my_seq_net, input_to_model=input)
writer.close()
我们打开terminal,输入
tensorboard --logdir=logs_seq
就可以通过tensorboard查看到这些信息。

损失函数与反向传播

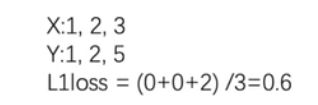
import torch
from torch.nn import L1Loss
inputs = torch.tensor([1, 2, 3], dtype=torch.float32) # 注意这里声明数据类型
targets = torch.tensor([1, 2, 5], dtype=torch.float32)# 注意这里声明数据类型
inputs = torch.reshape(inputs, (1, 1, 1, 3))
targets = torch.reshape(targets, (1, 1, 1, 3))
loss = L1Loss()
results = loss(inputs, targets)
print(results)
loss = L1Loss(reduction="sum")
results = loss(inputs, targets)
print(results)
"""
tensor(0.6667)
tensor(2.)
"""
MSELoss

import torch
from torch.nn import L1Loss, MSELoss
inputs = torch.tensor([1, 2, 3], dtype=torch.float32) # 注意这里声明数据类型
targets = torch.tensor([1, 2, 5], dtype=torch.float32)# 注意这里声明数据类型
inputs = torch.reshape(inputs, (1, 1, 1, 3))
targets = torch.reshape(targets, (1, 1, 1, 3))
loss = L1Loss()
results = loss(inputs, targets)
print(results)
loss = L1Loss(reduction="sum")
results = loss(inputs, targets)
print(results)
lossMSE = MSELoss()
results = lossMSE(inputs, targets)
print(results)
"""
tensor(0.6667)
tensor(2.)
tensor(1.3333)
"""
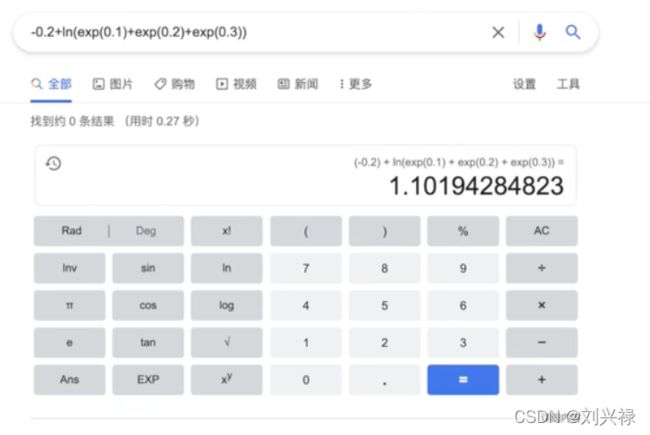
交叉熵
- 这里需要好好看一下交叉熵的部分



- 输入 N N N: batch size
- C C C: 有多少类
- -注意让你输入的形状是什么样和输出的形状是什么样
x = torch.tensor([0.1, 0.2, 0.3])
y = torch.tensor([1])
x = torch.reshape(x, (1, 3))
loss_cross = CrossEntropyLoss()
result_cross = loss_cross(x, y)
print(result_cross)
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("../data", # 下载到这个路径来
train=False,
transform=torchvision.transforms.ToTensor(),
download=True
)
dataloader = DataLoader(dataset, batch_size=1)
class My_Seq_Net(nn.Module):
def __init__(self):
super(My_Seq_Net, self).__init__()
self.model1 = Sequential(
Conv2d(in_channels=3, out_channels=32, kernel_size=5, padding=2),
MaxPool2d(kernel_size=2),
Conv2d(in_channels=32, out_channels=32, kernel_size=5, padding=2),
MaxPool2d(kernel_size=2),
Conv2d(in_channels=32, out_channels=64, kernel_size=5, padding=2),
MaxPool2d(kernel_size=2),
Flatten(),
Linear(in_features=1024, out_features=64),
Linear(in_features=64, out_features=10),
)
def forward(self, x):
x = self.model1(x)
return x
my_seq_net = My_Seq_Net()
print(my_seq_net)
for data in dataloader:
imgs, targets = data
output = my_seq_net(imgs)
print(output)
"""
# 下面是对网络结构进行检验
input = torch.ones((64, 3, 32, 32)) # batch_size = 64
output = my_seq_net(input)
print(output.shape)
writer = SummaryWriter("logs_seq")
writer.add_graph(model=my_seq_net, input_to_model=input)
writer.close()
"""
输出
预测为每一类的概率
tensor([[ 0.0085, -0.0967, -0.0778, 0.1002, 0.0400, -0.0473, 0.0010, -0.0804,
0.0853, -0.0019]], grad_fn=<AddmmBackward>)
tensor([[-0.0113, -0.0779, -0.0602, 0.1093, 0.0531, -0.0586, -0.0177, -0.0609,
0.0479, -0.0034]], grad_fn=<AddmmBackward>)
继续测试交叉熵
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("../data", # 下载到这个路径来
train=False,
transform=torchvision.transforms.ToTensor(),
download=True
)
dataloader = DataLoader(dataset, batch_size=1)
class My_Seq_Net(nn.Module):
def __init__(self):
super(My_Seq_Net, self).__init__()
self.model1 = Sequential(
Conv2d(in_channels=3, out_channels=32, kernel_size=5, padding=2),
MaxPool2d(kernel_size=2),
Conv2d(in_channels=32, out_channels=32, kernel_size=5, padding=2),
MaxPool2d(kernel_size=2),
Conv2d(in_channels=32, out_channels=64, kernel_size=5, padding=2),
MaxPool2d(kernel_size=2),
Flatten(),
Linear(in_features=1024, out_features=64),
Linear(in_features=64, out_features=10),
)
def forward(self, x):
x = self.model1(x)
return x
my_seq_net = My_Seq_Net()
print(my_seq_net)
loss = nn.CrossEntropyLoss()
for data in dataloader:
imgs, targets = data
output = my_seq_net(imgs)
result_loss = loss(output, targets)
print('result_loss: ', result_loss)
"""
# 下面是对网络结构进行检验
input = torch.ones((64, 3, 32, 32)) # batch_size = 64
output = my_seq_net(input)
print(output.shape)
writer = SummaryWriter("logs_seq")
writer.add_graph(model=my_seq_net, input_to_model=input)
writer.close()
"""
result_loss: tensor(2.2773, grad_fn=<NllLossBackward>)
result_loss: tensor(2.3406, grad_fn=<NllLossBackward>)
result_loss: tensor(2.2644, grad_fn=<NllLossBackward>)
result_loss: tensor(2.2502, grad_fn=<NllLossBackward>)
result_loss: tensor(2.2637, grad_fn=<NllLossBackward>)
result_loss: tensor(2.2817, grad_fn=<NllLossBackward>)
result_loss: tensor(2.3695, grad_fn=<NllLossBackward>)
result_loss: tensor(2.2308, grad_fn=<NllLossBackward>)
result_loss: tensor(2.2217, grad_fn=<NllLossBackward>)
result_loss: tensor(2.3519, grad_fn=<NllLossBackward>)

梯度下降
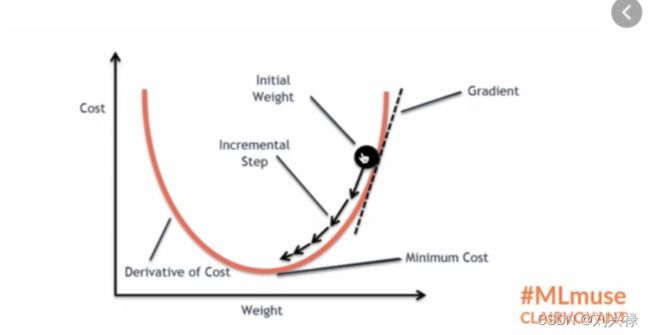

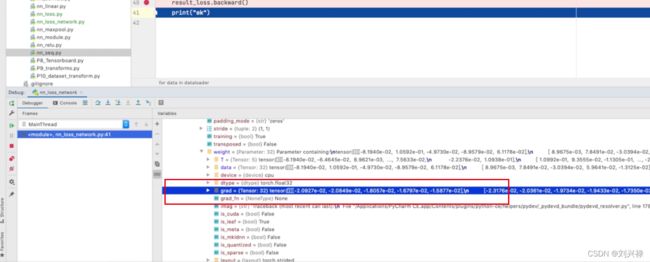
- 注意: backward会自动求导
优化器
反向传播,更新参数
https://pytorch.org/docs/stable/optim.html

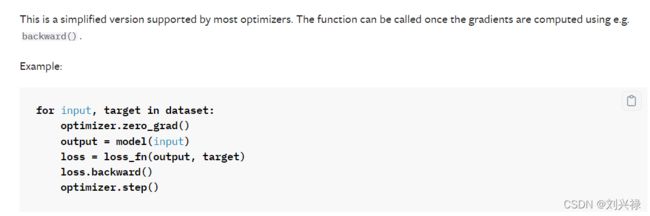
for input, target in dataset:
optimizer.zero_grad() # 需要把梯度清零,把上一步的梯度清零,否则会出问题
output = model(input)
loss = loss_fn(output, target)
loss.backward() # 这一步其实是自动求导
optimizer.step() # 这一步其实就是更新参数
我们写一个比较完整的代码
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("../data", # 下载到这个路径来
train=False,
transform=torchvision.transforms.ToTensor(),
download=True
)
dataloader = DataLoader(dataset, batch_size=1)
class My_Seq_Net(nn.Module):
def __init__(self):
super(My_Seq_Net, self).__init__()
self.model1 = Sequential(
Conv2d(in_channels=3, out_channels=32, kernel_size=5, padding=2),
MaxPool2d(kernel_size=2),
Conv2d(in_channels=32, out_channels=32, kernel_size=5, padding=2),
MaxPool2d(kernel_size=2),
Conv2d(in_channels=32, out_channels=64, kernel_size=5, padding=2),
MaxPool2d(kernel_size=2),
Flatten(),
Linear(in_features=1024, out_features=64),
Linear(in_features=64, out_features=10),
)
def forward(self, x):
x = self.model1(x)
return x
my_seq_net = My_Seq_Net()
print(my_seq_net)
loss = nn.CrossEntropyLoss()
optim = torch.optim.SGD(params=my_seq_net.parameters(), lr=0.01) # 定义一个优化器实例
for data in dataloader:
imgs, targets = data
output = my_seq_net(imgs)
result_loss = loss(output, targets)
optim.zero_grad() # 将梯度清零
result_loss.backward() # 反向传播求导
optim.step() # 更新网络参数
"""
# 下面是对网络结构进行检验
input = torch.ones((64, 3, 32, 32)) # batch_size = 64
output = my_seq_net(input)
print(output.shape)
writer = SummaryWriter("logs_seq")
writer.add_graph(model=my_seq_net, input_to_model=input)
writer.close()
"""
下面可以debug看一下参数的更新


接下来我们循环20个epoch来看看
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("../data", # 下载到这个路径来
train=False,
transform=torchvision.transforms.ToTensor(),
download=True
)
dataloader = DataLoader(dataset, batch_size=1)
class My_Seq_Net(nn.Module):
def __init__(self):
super(My_Seq_Net, self).__init__()
self.model1 = Sequential(
Conv2d(in_channels=3, out_channels=32, kernel_size=5, padding=2),
MaxPool2d(kernel_size=2),
Conv2d(in_channels=32, out_channels=32, kernel_size=5, padding=2),
MaxPool2d(kernel_size=2),
Conv2d(in_channels=32, out_channels=64, kernel_size=5, padding=2),
MaxPool2d(kernel_size=2),
Flatten(),
Linear(in_features=1024, out_features=64),
Linear(in_features=64, out_features=10),
)
def forward(self, x):
x = self.model1(x)
return x
my_seq_net = My_Seq_Net()
print(my_seq_net)
loss = nn.CrossEntropyLoss()
optim = torch.optim.SGD(params=my_seq_net.parameters(), lr=0.01) # 定义一个优化器实例
for epoch in range(20):
running_loss = 0.0
for data in dataloader: # 这样只是学习了一论的数据而已
imgs, targets = data
output = my_seq_net(imgs)
result_loss = loss(output, targets)
optim.zero_grad() # 将梯度清零
result_loss.backward() # 反向传播求导
optim.step() # 更新网络参数
# print('result_loss:', result_loss)
running_loss = running_loss + result_loss
print('epoch: {}, running_loss: {}'.format(epoch, running_loss))
"""
# 下面是对网络结构进行检验
input = torch.ones((64, 3, 32, 32)) # batch_size = 64
output = my_seq_net(input)
print(output.shape)
writer = SummaryWriter("logs_seq")
writer.add_graph(model=my_seq_net, input_to_model=input)
writer.close()
"""
现有网络模型的使用及修改
- pretrained = true
- 网络模型已经是训练好的

- pretrained = false

D:\Develop\anaconda\python.exe F:/PycharmProjects/Reinforcement_Learning/model_pretrained.py
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
课件vgg16可以分出1000种类别
我们吧vgg16适用于分10类
import torchvision
from torch import nn
# train_data = torchvision.datasets.ImageNet("../data_image_net",
# split='train',
# download=True,
# transform=torchvision.transforms.ToTensor())
# RuntimeError: The dataset is no longer publicly accessible. You need to download the archives externally and place them in the root directory.
# 这个数据集需要自己下载,也太大了,弃用
vgg16_false = torchvision.models.vgg16(pretrained=False)
vgg16_true = torchvision.models.vgg16(pretrained=True) # 要从网络中去下载网络模型,包括是已经训练好的参数
print(vgg16_true)
dataset = torchvision.datasets.CIFAR10("../data", # 下载到这个路径来
train=False,
transform=torchvision.transforms.ToTensor(),
download=True
)
vgg16_true.classifier.add_module(name='add_linear', module=nn.Linear(1000, 10))
print(vgg16_true)
另外一种修改的方法
import torchvision
from torch import nn
# train_data = torchvision.datasets.ImageNet("../data_image_net",
# split='train',
# download=True,
# transform=torchvision.transforms.ToTensor())
# RuntimeError: The dataset is no longer publicly accessible. You need to download the archives externally and place them in the root directory.
# 这个数据集需要自己下载,也太大了,弃用
vgg16_false = torchvision.models.vgg16(pretrained=False)
vgg16_true = torchvision.models.vgg16(pretrained=True) # 要从网络中去下载网络模型,包括是已经训练好的参数
print(vgg16_true)
dataset = torchvision.datasets.CIFAR10("../data", # 下载到这个路径来
train=False,
transform=torchvision.transforms.ToTensor(),
download=True
)
vgg16_true.classifier.add_module(name='add_linear', module=nn.Linear(1000, 10))
print(vgg16_true)
print(vgg16_false)
vgg16_false.classifier[6] = nn.Linear(4096, 10)
print(vgg16_false)
"""
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=10, bias=True)
)
)
"""
网络模型的保存与读取

模型的保存
import torchvision
import torch
# 模型保存方式1:保存的模型的结构+模型的参数
vgg16 = torchvision.models.vgg16(pretrained=False)
torch.save(vgg16, "vgg16_method1.pth")
# 模型保存方式2:保存模型的参数:相当于把网络模型的参数保存成Python中的字典形式
# 推荐这种,所用的空间更小
torch.save(vgg16.state_dict(), "vgg16_method2.pth")
模型的加载
import torchvision
import torch
# 加载模型:对应模型保存方式1:
# model = torch.load("vgg16_method1.pth")
# print(model)
# 加载模型:对应模型保存方式2:
model = torch.load("vgg16_method2.pth")
print(model)
# 此时如果要恢复成模型,则需要下面的代码
vgg16 = torchvision.models.vgg16(pretrained=False)
vgg16.load_state_dict(torch.load("vgg16_method2.pth"))
print(vgg16)
完整的模型训练套路

# 准备数据集
import model
import torchvision
from torch.utils.data import DataLoader
from torch import nn
from torch import nn
import torch
'''
定义神经网络的类
'''
class My_Seq_Net(nn.Module):
def __init__(self):
super(My_Seq_Net, self).__init__()
self.model1 = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=32, kernel_size=5, padding=2),
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(in_channels=32, out_channels=32, kernel_size=5, padding=2),
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=5, padding=2),
nn.MaxPool2d(kernel_size=2),
nn.Flatten(),
nn.Linear(in_features=1024, out_features=64),
nn.Linear(in_features=64, out_features=10),
)
def forward(self, x):
x = self.model1(x)
return x
if __name__ == '__main__':
my_net = My_Seq_Net()
input = torch.ones((64, 3, 32, 32)) # batch_size = 64
output = my_net(input)
print(output.shape)
train_data = torchvision.datasets.CIFAR10(root = "../data", # 下载到这个路径来
train=True,
transform=torchvision.transforms.ToTensor(),
download=True
)
test_data = torchvision.datasets.CIFAR10(root = "../data", # 下载到这个路径来
train=False,
transform=torchvision.transforms.ToTensor(),
download=True
)
train_data_size = len(train_data)
test_data_size = len(test_data)
print('train_data_size: {}'.format(train_data_size))
print('test_data_size: {}'.format(test_data_size))
# 利用DataLoader来加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 创建神经网络
my_net = My_Seq_Net()
# 构造损失函数
loss_fun = nn.CrossEntropyLoss()
# 创建优化器
learning_rate = 0.01
optimizer = torch.optim.SGD(params=my_net.parameters(), lr=learning_rate)
# 设置训练网络的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 训练的轮数
epoch = 10
for i in range(epoch):
print(" ------- 第 {} 轮训练开始了-----".format(i))
# 训练开始
for data in train_dataloader:
imgs, targets = data
outputs = my_net(imgs)
loss = loss_fun(outputs, targets)
# 优化器优化模型
optimizer.zero_grad() # 梯度清零
loss.backward()
optimizer.step()
total_train_step += 1
# print('number of train step: {}, loss: {}'.format(total_train_step, loss))
print('number of train step: {}, loss: {}'.format(total_train_step, loss.item()))
完整训练套路2:保存模型,查看tensorboard,测试集
'''
这是一个完整的训练套路
'''
# 准备数据集
import torchvision
from torch.utils.data import DataLoader
from torch import nn
from torch import nn
import torch
from torch.utils.tensorboard import SummaryWriter
'''
定义神经网络的类
'''
class My_Seq_Net(nn.Module):
def __init__(self):
super(My_Seq_Net, self).__init__()
self.model1 = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=32, kernel_size=5, padding=2),
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(in_channels=32, out_channels=32, kernel_size=5, padding=2),
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=5, padding=2),
nn.MaxPool2d(kernel_size=2),
nn.Flatten(),
nn.Linear(in_features=1024, out_features=64),
nn.Linear(in_features=64, out_features=10),
)
def forward(self, x):
x = self.model1(x)
return x
if __name__ == '__main__':
my_net = My_Seq_Net()
input = torch.ones((64, 3, 32, 32)) # batch_size = 64
output = my_net(input)
print(output.shape)
train_data = torchvision.datasets.CIFAR10(root = "../data", # 下载到这个路径来
train=True,
transform=torchvision.transforms.ToTensor(),
download=True
)
test_data = torchvision.datasets.CIFAR10(root = "../data", # 下载到这个路径来
train=False,
transform=torchvision.transforms.ToTensor(),
download=True
)
train_data_size = len(train_data)
test_data_size = len(test_data)
print('train_data_size: {}'.format(train_data_size))
print('test_data_size: {}'.format(test_data_size))
# 利用DataLoader来加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 创建神经网络
my_net = My_Seq_Net()
# 构造损失函数
loss_fun = nn.CrossEntropyLoss()
# 创建优化器
learning_rate = 0.01
optimizer = torch.optim.SGD(params=my_net.parameters(), lr=learning_rate)
# 设置训练网络的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 训练的轮数
epoch = 10
# 添加tensprbpard查看loss的变化
writer = SummaryWriter("../logs_train")
"""
这里一定要注意目录,这里是保存到上次目录去了,在生成tensorboard的时候需要
注意目录一定需要对应
"""
for i in range(epoch):
print(" ------- 第 {} 轮训练开始了-----".format(i))
""" 训练步骤开始 """
for data in train_dataloader:
imgs, targets = data
outputs = my_net(imgs)
loss = loss_fun(outputs, targets)
# 优化器优化模型
optimizer.zero_grad() # 梯度清零
loss.backward()
optimizer.step()
total_train_step += 1
# print('number of train step: {}, loss: {}'.format(total_train_step, loss))
if(total_train_step % 100 == 0):
print('number of train step: {}, loss: {}'.format(total_train_step, loss.item()))
writer.add_scalar(tag="train_loss", scalar_value=loss.item(), global_step=total_train_step)
""" 测试步骤开始: 该步骤就不需要调优 """
total_test_loss = 0
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
outputs = my_net(imgs)
loss = loss_fun(outputs, targets)
total_test_loss += loss
print('整体测试集上的loss: {}'.format(total_test_loss))
writer.add_scalar(tag="test_loss", scalar_value=total_test_loss, global_step=total_test_step)
total_test_step += 1
""" 保存模型 """
torch.save(my_net, "my_net_{}.pth".format(i)) # 区分第i轮的模型
print('模型已经保存')
writer.close()
完整训练套路2:保存模型,查看tensorboard,测试集+计算accuracy

'''
这是一个完整的训练套路
'''
# 准备数据集
import torchvision
from torch.utils.data import DataLoader
from torch import nn
from torch import nn
import torch
from torch.utils.tensorboard import SummaryWriter
"""
这是一个测试例子
outputs = torch.tensor([[0.1, 0.2],
[0.3, 0.4]])
print(outputs.argmax(dim=0))
preds = outputs.argmax(dim=1)
targets = torch.tensor([0,1])
print((preds == targets).sum())
"""
'''
定义神经网络的类
'''
class My_Seq_Net(nn.Module):
def __init__(self):
super(My_Seq_Net, self).__init__()
self.model1 = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=32, kernel_size=5, padding=2),
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(in_channels=32, out_channels=32, kernel_size=5, padding=2),
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=5, padding=2),
nn.MaxPool2d(kernel_size=2),
nn.Flatten(),
nn.Linear(in_features=1024, out_features=64),
nn.Linear(in_features=64, out_features=10),
)
def forward(self, x):
x = self.model1(x)
return x
if __name__ == '__main__':
my_net = My_Seq_Net()
input = torch.ones((64, 3, 32, 32)) # batch_size = 64
output = my_net(input)
print(output.shape)
train_data = torchvision.datasets.CIFAR10(root = "../data", # 下载到这个路径来
train=True,
transform=torchvision.transforms.ToTensor(),
download=True
)
test_data = torchvision.datasets.CIFAR10(root = "../data", # 下载到这个路径来
train=False,
transform=torchvision.transforms.ToTensor(),
download=True
)
train_data_size = len(train_data)
test_data_size = len(test_data)
print('train_data_size: {}'.format(train_data_size))
print('test_data_size: {}'.format(test_data_size))
# 利用DataLoader来加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 创建神经网络
my_net = My_Seq_Net()
# 构造损失函数
loss_fun = nn.CrossEntropyLoss()
# 创建优化器
learning_rate = 0.01
optimizer = torch.optim.SGD(params=my_net.parameters(), lr=learning_rate)
# 设置训练网络的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 训练的轮数
epoch = 10
# 添加tensprbpard查看loss的变化
writer = SummaryWriter("../logs_train")
"""
这里一定要注意目录,这里是保存到上次目录去了,在生成tensorboard的时候需要
注意目录一定需要对应
"""
for i in range(epoch):
print(" ------- 第 {} 轮训练开始了-----".format(i))
""" 训练步骤开始 """
my_net.train() # 这个可以不设置
for data in train_dataloader:
imgs, targets = data
outputs = my_net(imgs)
loss = loss_fun(outputs, targets)
# 优化器优化模型
optimizer.zero_grad() # 梯度清零
loss.backward()
optimizer.step()
total_train_step += 1
# print('number of train step: {}, loss: {}'.format(total_train_step, loss))
if(total_train_step % 100 == 0):
print('number of train step: {}, loss: {}'.format(total_train_step, loss.item()))
writer.add_scalar(tag="train_loss", scalar_value=loss.item(), global_step=total_train_step)
""" 测试步骤开始: 该步骤就不需要调优 """
my_net.eval() # 这个可以不设置
total_test_loss = 0
total_accurate_num = 0
with torch.no_grad(): # 此时只是需要测试,因此不需要更新梯度,可以把梯度清零
for data in test_dataloader:
imgs, targets = data
outputs = my_net(imgs)
loss = loss_fun(outputs, targets)
total_test_loss += loss
accurate_num = (outputs.argmax(dim=1) == targets).sum()
total_accurate_num += accurate_num
print('整体测试集上的loss: {}'.format(total_test_loss))
print('整体测试集上的accuracy: {}'.format(total_accurate_num/test_data_size))
writer.add_scalar(tag="test_loss", scalar_value=total_test_loss, global_step=total_test_step)
writer.add_scalar(tag="test_accuracy", scalar_value=total_accurate_num/test_data_size, global_step=total_test_step)
total_test_step += 1
""" 保存模型 """
torch.save(my_net, "my_net_{}.pth".format(i)) # 区分第i轮的模型
print('模型已经保存')
writer.close()
利用GPU进行训练
第一种方法

'''
这是一个完整的训练套路
'''
# 准备数据集
import torchvision
from torch.utils.data import DataLoader
from torch import nn
from torch import nn
import torch
from torch.utils.tensorboard import SummaryWriter
"""
这是一个测试例子
outputs = torch.tensor([[0.1, 0.2],
[0.3, 0.4]])
print(outputs.argmax(dim=0))
preds = outputs.argmax(dim=1)
targets = torch.tensor([0,1])
print((preds == targets).sum())
"""
'''
定义神经网络的类
'''
class My_Seq_Net(nn.Module):
def __init__(self):
super(My_Seq_Net, self).__init__()
self.model1 = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=32, kernel_size=5, padding=2),
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(in_channels=32, out_channels=32, kernel_size=5, padding=2),
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=5, padding=2),
nn.MaxPool2d(kernel_size=2),
nn.Flatten(),
nn.Linear(in_features=1024, out_features=64),
nn.Linear(in_features=64, out_features=10),
)
def forward(self, x):
x = self.model1(x)
return x
if __name__ == '__main__':
my_net = My_Seq_Net()
input = torch.ones((64, 3, 32, 32)) # batch_size = 64
output = my_net(input)
print(output.shape)
train_data = torchvision.datasets.CIFAR10(root = "../data", # 下载到这个路径来
train=True,
transform=torchvision.transforms.ToTensor(),
download=True
)
test_data = torchvision.datasets.CIFAR10(root = "../data", # 下载到这个路径来
train=False,
transform=torchvision.transforms.ToTensor(),
download=True
)
train_data_size = len(train_data)
test_data_size = len(test_data)
print('train_data_size: {}'.format(train_data_size))
print('test_data_size: {}'.format(test_data_size))
# 利用DataLoader来加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 创建神经网络
my_net = My_Seq_Net()
if torch.cuda.is_available():
my_net = my_net.cuda() # 调用GPU
# 构造损失函数
loss_fun = nn.CrossEntropyLoss()
if torch.cuda.is_available():
loss_fun = loss_fun.cuda() # 调用GPU
# 创建优化器 -- 也是没有cuda方法
learning_rate = 0.01
optimizer = torch.optim.SGD(params=my_net.parameters(), lr=learning_rate)
# 设置训练网络的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 训练的轮数
epoch = 10
# 添加tensprbpard查看loss的变化
writer = SummaryWriter("../logs_train")
"""
这里一定要注意目录,这里是保存到上次目录去了,在生成tensorboard的时候需要
注意目录一定需要对应
"""
for i in range(epoch):
print(" ------- 第 {} 轮训练开始了-----".format(i))
""" 训练步骤开始 """
my_net.train() # 这个可以不设置
for data in train_dataloader:
imgs, targets = data
if torch.cuda.is_available():
imgs = imgs.cuda() # 使用GPU
targets = targets.cuda() # 使用GPU
outputs = my_net(imgs)
loss = loss_fun(outputs, targets)
# 优化器优化模型
optimizer.zero_grad() # 梯度清零
loss.backward()
optimizer.step()
total_train_step += 1
# print('number of train step: {}, loss: {}'.format(total_train_step, loss))
if(total_train_step % 100 == 0):
print('number of train step: {}, loss: {}'.format(total_train_step, loss.item()))
writer.add_scalar(tag="train_loss", scalar_value=loss.item(), global_step=total_train_step)
""" 测试步骤开始: 该步骤就不需要调优 """
my_net.eval() # 这个可以不设置
total_test_loss = 0
total_accurate_num = 0
with torch.no_grad(): # 此时只是需要测试,因此不需要更新梯度,可以把梯度清零
for data in test_dataloader:
imgs, targets = data
if torch.cuda.is_available():
imgs = imgs.cuda() # 使用GPU
targets = targets.cuda() # 使用GPU
outputs = my_net(imgs)
loss = loss_fun(outputs, targets)
total_test_loss += loss
accurate_num = (outputs.argmax(dim=1) == targets).sum()
total_accurate_num += accurate_num
print('整体测试集上的loss: {}'.format(total_test_loss))
print('整体测试集上的accuracy: {}'.format(total_accurate_num/test_data_size))
writer.add_scalar(tag="test_loss", scalar_value=total_test_loss, global_step=total_test_step)
writer.add_scalar(tag="test_accuracy", scalar_value=total_accurate_num/test_data_size, global_step=total_test_step)
total_test_step += 1
""" 保存模型 """
torch.save(my_net, "my_net_{}.pth".format(i)) # 区分第i轮的模型
print('模型已经保存')
writer.close()
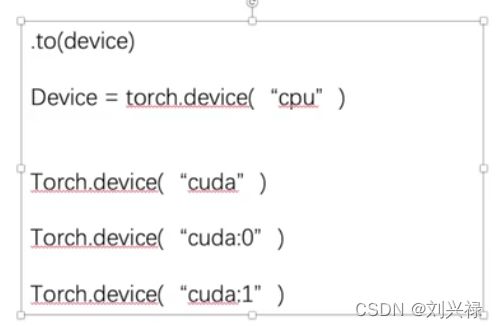
第2种方法
'''
这是一个完整的训练套路
'''
# 准备数据集
import torchvision
from torch.utils.data import DataLoader
from torch import nn
from torch import nn
import torch
from torch.utils.tensorboard import SummaryWriter
"""
这是一个测试例子
outputs = torch.tensor([[0.1, 0.2],
[0.3, 0.4]])
print(outputs.argmax(dim=0))
preds = outputs.argmax(dim=1)
targets = torch.tensor([0,1])
print((preds == targets).sum())
"""
'''
定义神经网络的类
'''
class My_Seq_Net(nn.Module):
def __init__(self):
super(My_Seq_Net, self).__init__()
self.model1 = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=32, kernel_size=5, padding=2),
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(in_channels=32, out_channels=32, kernel_size=5, padding=2),
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=5, padding=2),
nn.MaxPool2d(kernel_size=2),
nn.Flatten(),
nn.Linear(in_features=1024, out_features=64),
nn.Linear(in_features=64, out_features=10),
)
def forward(self, x):
x = self.model1(x)
return x
if __name__ == '__main__':
my_net = My_Seq_Net()
input = torch.ones((64, 3, 32, 32)) # batch_size = 64
output = my_net(input)
print(output.shape)
"""
定义训练的设备
"""
# device = torch.device("cpu") # 使用cpu
device = torch.device("cuda") # 使用gpu
# device = torch.device("cuda:0") # 使用gpu: 设置用第几块gpu
# device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 这种也可以
train_data = torchvision.datasets.CIFAR10(root = "../data", # 下载到这个路径来
train=True,
transform=torchvision.transforms.ToTensor(),
download=True
)
test_data = torchvision.datasets.CIFAR10(root = "../data", # 下载到这个路径来
train=False,
transform=torchvision.transforms.ToTensor(),
download=True
)
train_data_size = len(train_data)
test_data_size = len(test_data)
print('train_data_size: {}'.format(train_data_size))
print('test_data_size: {}'.format(test_data_size))
# 利用DataLoader来加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 创建神经网络
my_net = My_Seq_Net()
my_net = my_net.to(device=device)
# 构造损失函数
loss_fun = nn.CrossEntropyLoss()
loss_fun = loss_fun.to(device=device) # 调用GPU
# 创建优化器 -- 也是没有cuda方法
learning_rate = 0.01
optimizer = torch.optim.SGD(params=my_net.parameters(), lr=learning_rate)
# 设置训练网络的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 训练的轮数
epoch = 10
# 添加tensprbpard查看loss的变化
writer = SummaryWriter("../logs_train")
"""
这里一定要注意目录,这里是保存到上次目录去了,在生成tensorboard的时候需要
注意目录一定需要对应
"""
for i in range(epoch):
print(" ------- 第 {} 轮训练开始了-----".format(i))
""" 训练步骤开始 """
my_net.train() # 这个可以不设置
for data in train_dataloader:
imgs, targets = data
imgs = imgs.to(device=device) # 调用GPU
targets = targets.to(device=device) # 调用GPU
outputs = my_net(imgs)
loss = loss_fun(outputs, targets)
# 优化器优化模型
optimizer.zero_grad() # 梯度清零
loss.backward()
optimizer.step()
total_train_step += 1
# print('number of train step: {}, loss: {}'.format(total_train_step, loss))
if(total_train_step % 100 == 0):
print('number of train step: {}, loss: {}'.format(total_train_step, loss.item()))
writer.add_scalar(tag="train_loss", scalar_value=loss.item(), global_step=total_train_step)
""" 测试步骤开始: 该步骤就不需要调优 """
my_net.eval() # 这个可以不设置
total_test_loss = 0
total_accurate_num = 0
with torch.no_grad(): # 此时只是需要测试,因此不需要更新梯度,可以把梯度清零
for data in test_dataloader:
imgs, targets = data
imgs = imgs.to(device=device) # 调用GPU
targets = targets.to(device=device) # 调用GPU
outputs = my_net(imgs)
loss = loss_fun(outputs, targets)
total_test_loss += loss
accurate_num = (outputs.argmax(dim=1) == targets).sum()
total_accurate_num += accurate_num
print('整体测试集上的loss: {}'.format(total_test_loss))
print('整体测试集上的accuracy: {}'.format(total_accurate_num/test_data_size))
writer.add_scalar(tag="test_loss", scalar_value=total_test_loss, global_step=total_test_step)
writer.add_scalar(tag="test_accuracy", scalar_value=total_accurate_num/test_data_size, global_step=total_test_step)
total_test_step += 1
""" 保存模型 """
torch.save(my_net, "my_net_{}.pth".format(i)) # 区分第i轮的模型
print('模型已经保存')
writer.close()
神经网络基本迭代:非常好





欢迎关注我们的微信公众号 运小筹
公众号往期推文如下



