logistic模型matlab代码_机器学习实战个人学习分享(四):Logistic回归
 点击上方蓝字 关注我们
点击上方蓝字 关注我们  这次的学习是有关Logistic回归的内容,简单的分类,算法不难,但是涉及到算法的优化,其中的梯度上升算法在许多课程里都有涉及,也比较经典,所以这次学习可以系统的归纳,算是基础,老样子,这里用到了Jack Cui 博客和黄海安的视频讲解,内容得到了二位的授权,相关链接如下: Python3《机器学习实战》学习笔记(六):Logistic回归基础篇之梯度上升算法:https://blog.csdn.net/c406495762/article/details/77723333
这次的学习是有关Logistic回归的内容,简单的分类,算法不难,但是涉及到算法的优化,其中的梯度上升算法在许多课程里都有涉及,也比较经典,所以这次学习可以系统的归纳,算是基础,老样子,这里用到了Jack Cui 博客和黄海安的视频讲解,内容得到了二位的授权,相关链接如下: Python3《机器学习实战》学习笔记(六):Logistic回归基础篇之梯度上升算法:https://blog.csdn.net/c406495762/article/details/77723333
Python3《机器学习实战》学习笔记(七):Logistic回归实战篇之预测病马死亡率:https://blog.csdn.net/c406495762/article/details/77851973
【机器学习实战】【python3版本】【代码讲解】:https://www.bilibili.com/video/BV16t411Q7TM
相关的运行平台和环境
运行平台: win10
python: 3.7.6
Anaconda: 4.8.3
IDE: pycharm community
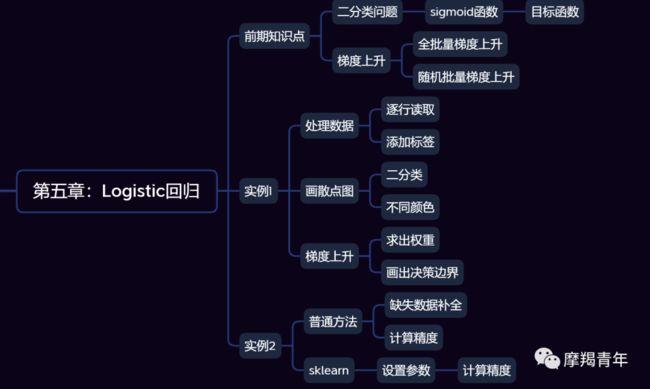
01 前期知识点Logistic回归一般处理的是二分类问题。Logistic回归进行分类的主要思想是:根据现有数据对分类边界线建立回归公式,以此进行分类。其实,Logistic本质上是一个基于条件概率的判别模型(Discriminative Model)。所以要想了解Logistic回归,我们必须先看一看Sigmoid函数 ,我们也可以称它为Logistic函数。它的公式如下:![]()
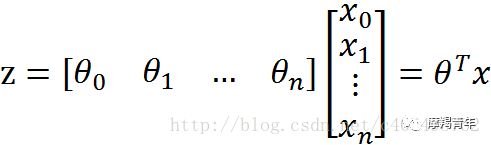
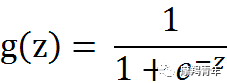
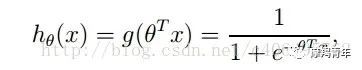
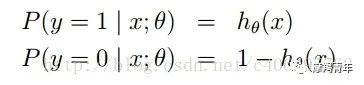
![]()
![]()
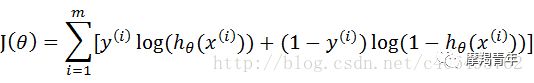
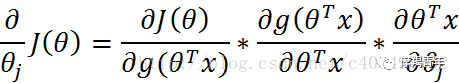
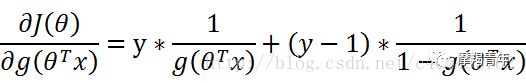
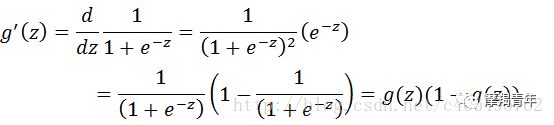
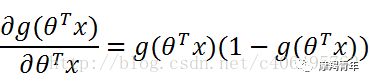
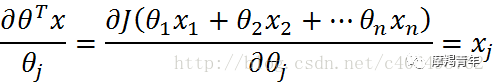
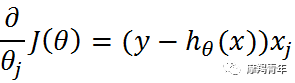
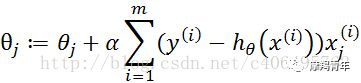
def Gradient_Ascent_test(): def f_prime(x_old): # f(x)的导数 return -2 * x_old + 4 x_old = -1 # 初始值,给一个小于x_new的值 x_new = 0 # 梯度上升算法初始值,即从(0,0)开始 alpha = 0.01 # 步长,也就是学习速率,控制更新的幅度 presision = 0.00000001 # 精度,也就是更新阈值 while abs(x_new - x_old) > presision: x_old = x_new x_new = x_old + alpha * f_prime(x_old) # 上面提到的公式 print(x_new) # 打印最终求解的极值近似值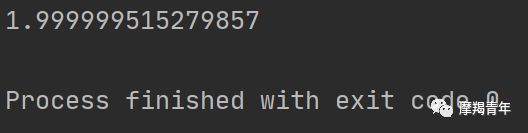
def loadDataSet(): dataMat = [] # 创建数据列表 labelMat = [] # 创建标签列表 fr = open('testSet.txt') # 打开文件 for line in fr.readlines(): # 逐行读取 lineArr = line.strip().split() # 去回车,放入列表 dataMat.append([1.0, float(lineArr[0]), float(lineArr[1])]) # 添加数据 labelMat.append(int(lineArr[2])) # 添加标签 fr.close() # 关闭文件 return dataMat, labelMat # 返回![]()
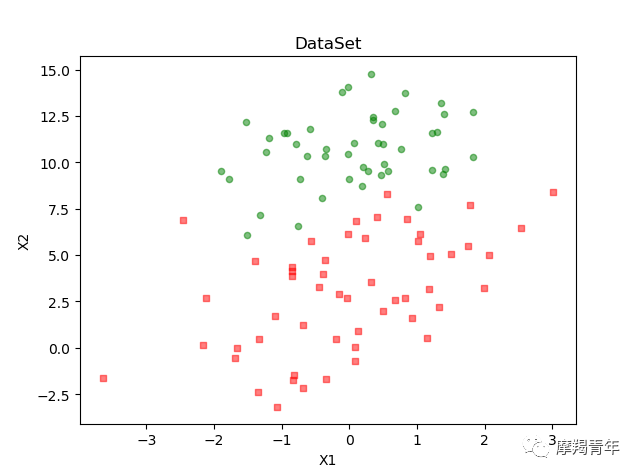
def plotDataSet(): dataMat, labelMat = loadDataSet() # 加载数据集 dataArr = np.array(dataMat) # 转换成numpy的array数组 n = np.shape(dataMat)[0] # 数据个数 xcord1 = [] ycord1 = [] # 正样本 xcord2 = [] ycord2 = [] # 负样本 for i in range(n): # 根据数据集标签进行分类 if int(labelMat[i]) == 1: xcord1.append(dataArr[i, 1]) ycord1.append(dataArr[i, 2]) # 1为正样本 else: xcord2.append(dataArr[i, 1]) ycord2.append(dataArr[i, 2]) # 0为负样本 fig = plt.figure() ax = fig.add_subplot(111) # 添加subplot ax.scatter(xcord1, ycord1, s=20, c='red', marker='s', alpha=.5) # 绘制正样本 ax.scatter(xcord2, ycord2, s=20, c='green', alpha=.5) # 绘制负样本 plt.title('DataSet') # 绘制title plt.xlabel('X1') plt.ylabel('X2') # 绘制label plt.show() # 显示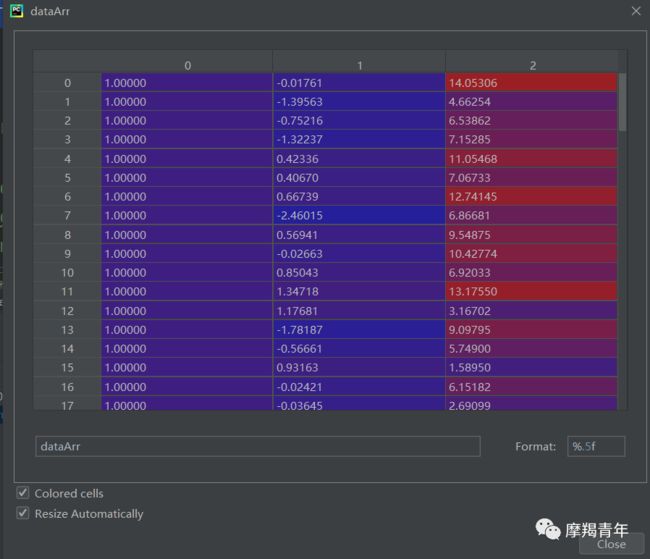
def gradAscent(dataMatIn, classLabels): dataMatrix = np.mat(dataMatIn) # 转换成numpy的mat labelMat = np.mat(classLabels).transpose() # 转换成numpy的mat,并进行转置 m, n = np.shape(dataMatrix) # 返回dataMatrix的大小。m为行数,n为列数。 alpha = 0.001 # 移动步长,也就是学习速率,控制更新的幅度。 maxCycles = 500 # 最大迭代次数 weights = np.ones((n, 1)) for k in range(maxCycles): h = sigmoid(dataMatrix * weights) # 梯度上升矢量化公式 error = labelMat - h weights = weights + alpha * dataMatrix.transpose() * error return weights.getA() # 将矩阵转换为数组,返回权重数组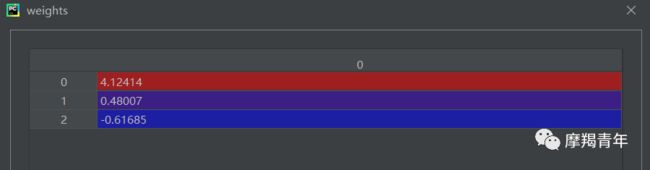
def plotBestFit(weights): dataMat, labelMat = loadDataSet() # 加载数据集 dataArr = np.array(dataMat) # 转换成numpy的array数组 n = np.shape(dataMat)[0] # 数据个数 xcord1 = [] ycord1 = [] # 正样本 xcord2 = [] ycord2 = [] # 负样本 for i in range(n): # 根据数据集标签进行分类 if int(labelMat[i]) == 1: xcord1.append(dataArr[i, 1]) ycord1.append(dataArr[i, 2]) # 1为正样本 else: xcord2.append(dataArr[i, 1]) ycord2.append(dataArr[i, 2]) # 0为负样本 fig = plt.figure() ax = fig.add_subplot(111) # 添加subplot ax.scatter(xcord1, ycord1, s=20, c='red', marker='s', alpha=.5) # 绘制正样本 ax.scatter(xcord2, ycord2, s=20, c='green', alpha=.5) # 绘制负样本 x = np.arange(-3.0, 3.0, 0.1) y = (-weights[0] - weights[1] * x) / weights[2] ax.plot(x, y) plt.title('BestFit') # 绘制title plt.xlabel('X1') plt.ylabel('X2') # 绘制label plt.show()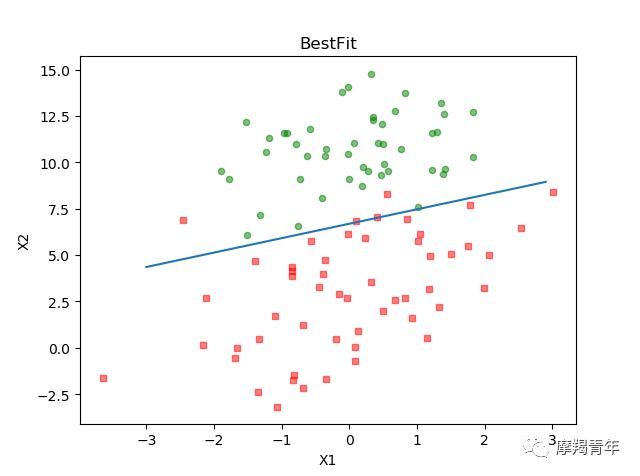
# 全批量梯度上升法-每次全部使用样本计算,计算量非常大def gradAscent(dataMatIn, classLabels): dataMatrix = np.mat(dataMatIn) # 转换成numpy的mat labelMat = np.mat(classLabels).transpose() # 转换成numpy的mat,并进行转置 m, n = np.shape(dataMatrix) # 返回dataMatrix的大小。m为行数,n为列数。 alpha = 0.01 # 移动步长,也就是学习速率,控制更新的幅度。 maxCycles = 500 # 最大迭代次数 weights = np.ones((n, 1)) weights_array = np.array([]) for k in range(maxCycles): h = sigmoid(dataMatrix * weights) # 梯度上升矢量化公式 error = labelMat - h weights = weights + alpha * dataMatrix.transpose() * error weights_array = np.append(weights_array, weights) weights_array = weights_array.reshape(maxCycles, n) return weights.getA(), weights_array # 将矩阵转换为数组,并返回# 随机梯度上升法-每次随机取一个不同的样本进行更新回归系数def stocGradAscent1(dataMatrix, classLabels, numIter=150): m, n = np.shape(dataMatrix) # 返回dataMatrix的大小。m为行数,n为列数。 weights = np.ones(n) # 参数初始化 weights_array = np.array([]) # 存储每次更新的回归系数 for j in range(numIter): dataIndex = list(range(m)) for i in range(m): alpha = 4 / (1.0 + j + i) + 0.01 # 降低alpha的大小,每次减小1/(j+i)。 randIndex = int(random.uniform(0, len(dataIndex))) # 随机选取样本 h = sigmoid(sum(dataMatrix[randIndex] * weights)) # 选择随机选取的一个样本,计算h error = classLabels[randIndex] - h # 计算误差 weights = weights + alpha * error * dataMatrix[randIndex] # 更新回归系数 weights_array = np.append(weights_array, weights, axis=0) # 添加回归系数到数组中 del (dataIndex[randIndex]) # 删除已经使用的样本 weights_array = weights_array.reshape(numIter * m, n) # 改变维度 return weights, weights_array # 返回def plotWeights(weights_array1, weights_array2): # 设置汉字格式 font = FontProperties(fname=r"c:\windows\fonts\simsun.ttc", size=14) # 将fig画布分隔成1行1列,不共享x轴和y轴,fig画布的大小为(13,8) # 当nrow=3,nclos=2时,代表fig画布被分为六个区域,axs[0][0]表示第一行第一列 fig, axs = plt.subplots(nrows=3, ncols=2, sharex=False, sharey=False, figsize=(20, 10)) x1 = np.arange(0, len(weights_array1), 1) # 绘制w0与迭代次数的关系 axs[0][0].plot(x1, weights_array1[:, 0]) axs0_title_text = axs[0][0].set_title(u'改进的随机梯度上升算法:回归系数与迭代次数关系', FontProperties=font) axs0_ylabel_text = axs[0][0].set_ylabel(u'W0', FontProperties=font) plt.setp(axs0_title_text, size=20, weight='bold', color='black') plt.setp(axs0_ylabel_text, size=20, weight='bold', color='black') # 绘制w1与迭代次数的关系 axs[1][0].plot(x1, weights_array1[:, 1]) axs1_ylabel_text = axs[1][0].set_ylabel(u'W1', FontProperties=font) plt.setp(axs1_ylabel_text, size=20, weight='bold', color='black') # 绘制w2与迭代次数的关系 axs[2][0].plot(x1, weights_array1[:, 2]) axs2_xlabel_text = axs[2][0].set_xlabel(u'迭代次数', FontProperties=font) axs2_ylabel_text = axs[2][0].set_ylabel(u'W1', FontProperties=font) plt.setp(axs2_xlabel_text, size=20, weight='bold', color='black') plt.setp(axs2_ylabel_text, size=20, weight='bold', color='black') x2 = np.arange(0, len(weights_array2), 1) # 绘制w0与迭代次数的关系 axs[0][1].plot(x2, weights_array2[:, 0]) axs0_title_text = axs[0][1].set_title(u'梯度上升算法:回归系数与迭代次数关系', FontProperties=font) axs0_ylabel_text = axs[0][1].set_ylabel(u'W0', FontProperties=font) plt.setp(axs0_title_text, size=20, weight='bold', color='black') plt.setp(axs0_ylabel_text, size=20, weight='bold', color='black') # 绘制w1与迭代次数的关系 axs[1][1].plot(x2, weights_array2[:, 1]) axs1_ylabel_text = axs[1][1].set_ylabel(u'W1', FontProperties=font) plt.setp(axs1_ylabel_text, size=20, weight='bold', color='black') # 绘制w2与迭代次数的关系 axs[2][1].plot(x2, weights_array2[:, 2]) axs2_xlabel_text = axs[2][1].set_xlabel(u'迭代次数', FontProperties=font) axs2_ylabel_text = axs[2][1].set_ylabel(u'W1', FontProperties=font) plt.setp(axs2_xlabel_text, size=20, weight='bold', color='black') plt.setp(axs2_ylabel_text, size=20, weight='bold', color='black') plt.show()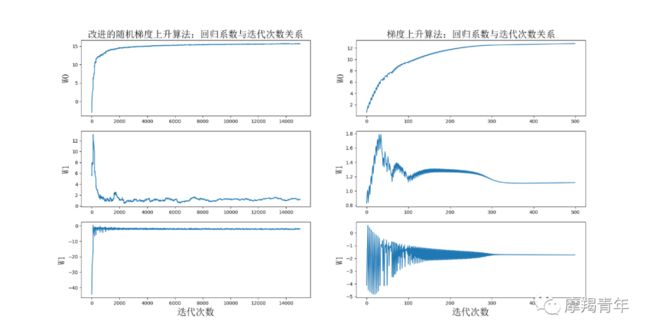
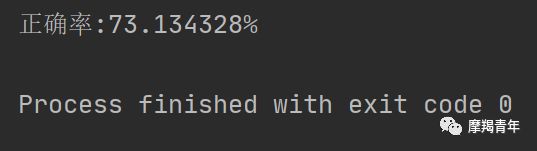
def colicTest(): frTrain = open('horseColicTraining.txt') # 打开训练集 frTest = open('horseColicTest.txt') # 打开测试集 trainingSet = [] trainingLabels = [] for line in frTrain.readlines(): currLine = line.strip().split('\t') lineArr = [] for i in range(len(currLine) - 1): lineArr.append(float(currLine[i])) trainingSet.append(lineArr) trainingLabels.append(float(currLine[-1])) trainWeights = stocGradAscent1(np.array(trainingSet), trainingLabels, 500) # 使用改进的随即上升梯度训练 errorCount = 0 numTestVec = 0.0 for line in frTest.readlines(): numTestVec += 1.0 currLine = line.strip().split('\t') lineArr = [] for i in range(len(currLine) - 1): lineArr.append(float(currLine[i])) if int(classifyVector(np.array(lineArr), trainWeights)) != int(currLine[-1]): errorCount += 1 errorRate = (float(errorCount) / numTestVec) * 100 # 错误率计算 print("测试集错误率为: %.2f%%" % errorRate)使用可用特征的均值来填补缺失值;
使用特殊值来填补缺失值,如-1;
忽略有缺失值的样本;
使用相似样本的均值添补缺失值;
使用另外的机器学习算法预测缺失值。
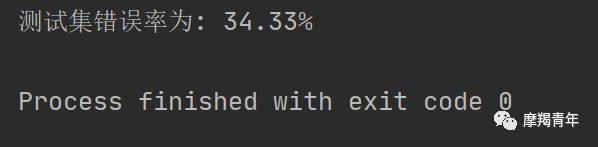
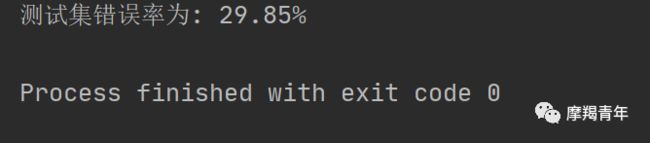
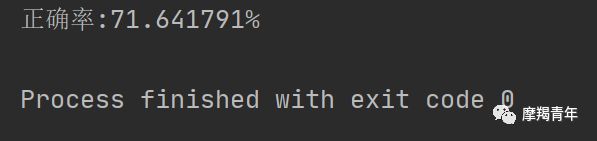
def colicSklearn(): frTrain = open('horseColicTraining.txt') # 打开训练集 frTest = open('horseColicTest.txt') # 打开测试集 trainingSet = [] trainingLabels = [] testSet = [] testLabels = [] for line in frTrain.readlines(): currLine = line.strip().split('\t') lineArr = [] for i in range(len(currLine) - 1): lineArr.append(float(currLine[i])) trainingSet.append(lineArr) trainingLabels.append(float(currLine[-1])) for line in frTest.readlines(): currLine = line.strip().split('\t') lineArr = [] for i in range(len(currLine) - 1): lineArr.append(float(currLine[i])) testSet.append(lineArr) testLabels.append(float(currLine[-1])) classifier = LogisticRegression(solver='sag', max_iter=5000).fit(trainingSet, trainingLabels) test_accurcy = classifier.score(testSet, testLabels) * 100 print('正确率:%f%%' % test_accurcy) classifier = LogisticRegression(solver='sag', max_iter=5000).fit(trainingSet, trainingLabels) test_accurcy = classifier.score(testSet, testLabels) * 100liblinear:使用了开源的liblinear库实现,内部使用了坐标轴下降法来迭代优化损失函数。
lbfgs:拟牛顿法的一种,利用损失函数二阶导数矩阵即海森矩阵来迭代优化损失函数。
newton-cg:也是牛顿法家族的一种,利用损失函数二阶导数矩阵即海森矩阵来迭代优化损失函数。
sag:即随机平均梯度下降,是梯度下降法的变种,和普通梯度下降法的区别是每次迭代仅仅用一部分的样本来计算梯度,适合于样本数据多的时候。
saga:线性收敛的随机优化算法的的变重。
ending
点击在看,了解更多精彩内容微信公众号:share_mojie摩羯青年
 点击在看,了解更多精彩内容
点击在看,了解更多精彩内容