Attentional Feature Fusion论文阅读
论文地址:https://arxiv.org/pdf/2009.14082.pdf
代码地址:https://github.com/YimianDai/open-aff
一.摘要
论文提出了一个特征融合的通用方案,叫做注意力特征融合,这个方案可以使用在大多数常见的场景中,这种方案可以应用在短的和长的跨层连接特征融合场景中,也可以应用在Inception层中.为了更好的将不同语义或尺度的特征进行融合,本文提出了一个多尺度通道注意力模块,它可以解决由于不同尺度特征融合所带来的问题.本文还证明了初始的特征融合可能使得模型表现达到一个瓶颈,想要突破这个瓶颈可以通过多增加一级注意力,论文称之为迭代注意力特征融合.
二.局部以及全局通道信息融合
当抽取到网络中某层的输出特征后,如何对其通过某种计算来进行局部和全局的信息融合呢?这部分就对提出的多尺度通道注意力模块(MS-CAM)进行详细描述.主要的想法就是通过使用不同的空间池化尺寸获得的多尺度特征,并在不同尺度特征上可以实施通道注意力操作.为了维持轻量模型,文章仅在注意力模块中将局部信息融入全局信息.文章选择使用1*1卷积或称之为point-wise卷积(PWConv)作为局部通道信息整合器,其仅仅利用了不同channel的对应像素点做信息交互.为了不增加参数量,在计算局部通道信息![]() 时使用了一个瓶颈结构.局部通道信息计算如下图所示:
时使用了一个瓶颈结构.局部通道信息计算如下图所示:

![]() 通过1 * 1卷积将输入的特征
通过1 * 1卷积将输入的特征 通道书减少为原先的
通道书减少为原先的![]() ,
, 表示BatchNorm层,
表示BatchNorm层, 表示ReLU激活函数,
表示ReLU激活函数,![]() 又通过1 * 1的卷积将通道数目恢复成与原输入通道数目相同,因此局部通道信息
又通过1 * 1的卷积将通道数目恢复成与原输入通道数目相同,因此局部通道信息![]() 的形状和输入的形状保持一致.如下图中最右侧路径即为局部通道信息的计算.
的形状和输入的形状保持一致.如下图中最右侧路径即为局部通道信息的计算.

之后通过上图中内部蓝色框中的左侧分支可以计算得到全局通道信息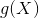 ,因为他这里使用了全局平均池化因此得到的特征包含了全局信息.最终通过MS-CAM模块将全局通道信息与局部通道信息
,因为他这里使用了全局平均池化因此得到的特征包含了全局信息.最终通过MS-CAM模块将全局通道信息与局部通道信息![]() 想融合,并输出一个权重值用来对输入特征做注意力操作后得到输出
想融合,并输出一个权重值用来对输入特征做注意力操作后得到输出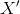 ,具体操作如下图所示:
,具体操作如下图所示:

上图中⊕ 表示广播加法操作,这里是因为全局通道信息使用了全局平均池化操作,因此得到的特征高宽形状为1*1,而局部通道信息与输入特征保持有相同的高宽尺寸,因此两者相加需要采取广播操作. ⊗ 表示两个feature map对应元素相乘.注意图中![]() 表示的是MS-CAM模块操作,对应流程图中内测蓝色框部分.
表示的是MS-CAM模块操作,对应流程图中内测蓝色框部分.
以上部分介绍了MS-CAM模块,注意这个模块主要做了一件事情就是产生了一个用于注意力操作的权重.
三.注意力特征融合
-
特征融合场景的统一应用
给定两个feature map分别为![]() ,也就是说有着相同的形状.并且假设
,也就是说有着相同的形状.并且假设 的感受野更大.基于上文提出的多尺度注意力模块MS-CAM这里简写为M,注意力特征融合(AFF)用数学描述如下左图所示,整体流程如下右图:
的感受野更大.基于上文提出的多尺度注意力模块MS-CAM这里简写为M,注意力特征融合(AFF)用数学描述如下左图所示,整体流程如下右图:


上左图式子中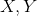 为注意力特征融合的输入,
为注意力特征融合的输入, 为注意力特征融合后的输出.
为注意力特征融合后的输出.![]() 表示输入特征的初始融合,这里采用对应元素相加的方式.上式子可以简写为
表示输入特征的初始融合,这里采用对应元素相加的方式.上式子可以简写为![]() ,其中
,其中![]() ,
, 也就是上右图中MS-CAM实线箭头的输出在0到1之间,因此
也就是上右图中MS-CAM实线箭头的输出在0到1之间,因此![]() 也就是上右图中MS-CAM虚线部分的输出也在0到1之间,相当于对两个输入特征做了加权平均,即通过训练的方式来让网络自己确定各自的权重.
也就是上右图中MS-CAM虚线部分的输出也在0到1之间,相当于对两个输入特征做了加权平均,即通过训练的方式来让网络自己确定各自的权重.
-
迭代注意力特征融合
在注意力特征融合模块中,初始特征的融合质量也许会严重影响最终特征融合的权重,因为这依旧是一个特征融合的问题.在上文中,初始特征融合![]() 只采用了简单的对应元素相加操作如上文中绿色字体描述,论文认为这样是不够的,论文将初始特征融合也采用了上文提出的注意力特征融合的方式,相当于双层注意力特征融合,文中称这种方式叫做双阶段方式迭代注意力特征融合(iAFF).初始特征融合数学描述如下所示:
只采用了简单的对应元素相加操作如上文中绿色字体描述,论文认为这样是不够的,论文将初始特征融合也采用了上文提出的注意力特征融合的方式,相当于双层注意力特征融合,文中称这种方式叫做双阶段方式迭代注意力特征融合(iAFF).初始特征融合数学描述如下所示:

迭代注意力特征融合整体流程如下图所示:

四.实验部分
实验部分这里就不细说了,可以自己看看原论文.这里要说的一点是,这篇论文提出的iAFF模块还算比较简单,自己实现起来也比较方便,我在一个分类任务中使用resnet作为基础网络,加入这个模块后确实能够带来效果上的提升,准确率大概可以提升不到1个百分点,因此大家可以尝试使用.这里贴几张原论文中的实验效果图以供参考: