商品3D建模的视觉定位和前景分割方法

2021年10月,大淘宝技术发布了基于神经渲染的3D建模产品object drawer ,用户只需要环拍一圈商品的视频,就可以生成3D模型。
在物体重建算法流程中,需要先计算出每一帧图像的相机位姿(平移和旋转)。之后需要对图像中前/背景进行像素级的分割,重建时只需考虑前景而忽略背景像素。准确的相机位姿和前景分割结果是保证高质量重建的前提。
重建的乐高打字机,可在手淘预览
单视频视觉定位
视觉定位任务的学术名词叫SfM(Structure from Motion),它的定义是:输入多个视角的图片,通过算法得到相机的内参、相机的位姿(6DoF)和场景的稀疏结构(稀疏点云)。目前业界比较成熟的视觉方案是COLMAP。在实际使用中我们发现,COLMAP的成功率只有80%,尤其在弱纹理、重复纹理、相机运动快时,精度严重下降;或者部分帧pose丢失甚至软件直接崩溃。对此,我们做出了改进。
SfM的算法环节可以分为两部分:特征匹配和几何模型。影响SfM精度和稳定性的主要是图像特征匹配的精度。所以,只要能提供准确的图像特征匹配方式,就可以恢复出准确的相机姿态和稀疏点云。
▐ 通用场景
为了提供更加鲁棒的特征和匹配方式,我们用神经网络特征(SuperPoint & SuperGlue)去替代COLMAP中的SIFT特征和BF(brute force)匹配方式,基本可以解决大部分的弱纹理和重复问题场景,如下图在虚拟渲染场景上的测试例子所示:

改进后的相机位姿对于重建的清晰度和质量有了很大提升,如下图所示:
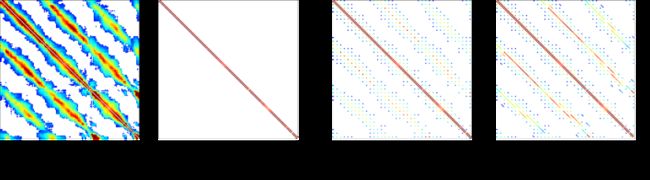
但是由于SuperGlue的匹配很耗时(2张图匹配约50毫秒)且无法并行化,如果采用图像之间两两穷尽匹配的话,一个400张图的图片集需要匹配约8万次,耗时1小时以上。因此,我们修改了匹配策略,减少了无效匹配。如下图所示,热量矩阵代表不同图像直接的相似度。白色、蓝色、红色表示相似程度递增。我们使用了稀疏采样+回环增强的模式,在不降低精度的情况下,匹配时间提升了15倍,400张图的匹配时间约为4分钟。
▐ 对称物体场景
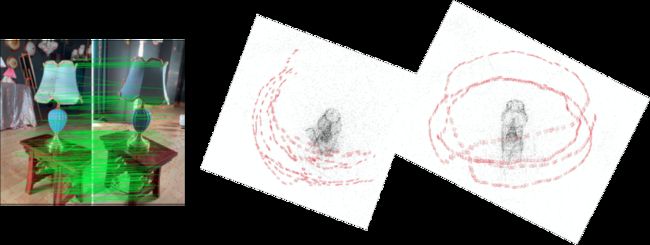
在实际的环拍数据中,容易出现对称的物体和背景。即某些物体从不同视角呈现了差不多的图像特征,会造成一个错误的回环信号。如下图图1所示,两个完全不同的视角有着相似的图像特征。错误的闭环检测会造成错误的位姿,如下图图2所示。因此我们采用coarse-to-fine的SfM策略。
先不考虑闭环,计算出初步相机姿态(不够准)。基于第一步的相机位置作为先验,再考虑闭环,计算出准确的相机姿态。
▐ 模糊图像场景
相机运动过快时容易采集到模糊图像。针对模糊图像SfM需要添加跳帧匹配策略。

▐ 转台场景
转台可以降低环拍难度。相机固定,转台运动的情况下,需要过滤掉转台外的像素点。我们采用了平面跟踪技术,能够准确跟踪转台平面的区域。转台外的特征点需要在匹配时过滤掉。
▐ 总结
经过上述一系列改进,视觉定位的成功率得到的大幅度提升,在实际业务中,视觉定位成功率由开源方案的80%提升到了99.3%。
多视频联合视觉定位
▐ 两个视频位姿对齐
如果我们要实现商品的全方位重建(比如重建鞋子、手办底部),我们需要将商品侧翻一下,再拍摄一个视频。前后拍摄的2个视频,如下图所示。由于个视单频下的相机姿态独立计算,需要将两个视频的位姿对齐到统一的坐标系。

拍摄的2个视频
一种比较简单的方法是用图像分割直接提取前景物体,将2个视频的图像混合在一起,直接在白底图上做SfM。实验发现这种情况位姿精度下降非常严重,因为前景特征非常少。
还有一种方法就是我们使用点云配准算法,又叫点云注册(Point Cloud Registration)。通过计算3D点云的特征(又分为局部特征和全局特征),计算出两堆点云的空间变换。但是在我们这个业务场景也无法适用。第一,单目SfM是缺乏尺度的,稀疏点云之间的尺度大小不一致,目前的点云配准方法并不支持。第二,由于正面摆放和侧面摆放,点云的overlap比较少,用业界的点云配准算法也很难得到变换结果。如下图是用ECCV2020的DeepGMR的的点云配准结果,发现匹配误差非常大,2个稀疏点云无法对齐。

所以我们提出了:在“2D上匹配,3D上求解”的算法框架,用来对齐2个拍摄视频的位姿。以下是设计的系统框图:

将点云投影到图像上提取特征,匹配,统计2D匹配的数量,得到3D点和3D点的对应关系,最后求解7个自由度:尺度s,旋转R,平移T:
![]()
可以成功将两个点云对齐,如下图蓝色和红色点云所示。

用对齐后的位姿去重建,效果如下图所示,无论正面还是底面都很清晰,说明点云配准所求出的变换精度较高。

▐ 多个视频位姿对齐
如果只拍2个视频,仍然会存在一定的拍摄盲区(会有一个比较小的区域没办法拍到),那么重建出来这个区域仍然比较脏、不干净(如下图的第二行,第三列的图,会有一小块白色随机颜色值)。对此,我们将拍摄视频扩展到3个,也将算法提高到了3视频对齐。3个视频可以实现商品的无死角覆盖拍摄。
以下分别是,拍1个视频、2个视频、3个视频的对齐位姿和底部重建效果。

更多全方位重建模型预览如下图所示:
▐ 淘宝应用
我们借用手淘上的720展示链路,将建模的结果离线渲染成图像序列,上传到了手淘,并在主图第二帧展示。

主体分割
▐ 问题定义
要想重建一个物体,首先要在图像上将物体分割出来,将前景保留、背景去除,重建出来的模型才能干净、完整。目前业界的重建方法(如NeRF、IDRNet)都对分割结果非常敏感,基本需要绝对准确的结果,一旦有1张出现了分割不准的情况,都会影响最终的重建结果。现有的图像/视频分割算法很难满足这个要求。
▐ 解决方法
对此,我们提出了图像分割和神经渲染端到端联合优化网络。将分割网络输出的结果作为初值,通过神经渲染的方式融合各个视角下的结果。
▐ 结果对比
如下图所示,最左边图片是输入RGB图,中间图片是用SOTA分割算法得到的抠图结果,右边图像是我们的算法结果。我们的分割结果非常精细(可达1个像素的细腻度,如右下角图所示),且不惧复杂背景。

总结
如果您想了解更多关于商品AI建模的信息,欢迎访问Object Drawer的官网:https://tech.taobao.org/objectdrawer。
团队介绍
大淘宝技术部3D算法团队,发布了业内首个基于神经渲染的商品三维重建产品描物坊Object Drawer,探索了NeRF神经渲染从建模到应用的全链路,在建模鲁棒性、纹理细节、模型大小、推理速度、重光照等方面保持业内领先。同时在应用方面,基于算法的智能出图、视频结果可以媲美设计师的作品,在视频分割、AI搭配、AI布局、户型表示、光影和谐等方面达到业内一流水平。团队在学术方面积极贡献,在ICCV、NeurIPS、KDD、CVPR等顶级学术会议上发表多篇论文,为研究者开放3D-FRONT数据集,获ChinaGraph首届数据奖。为了打造团队的全栈研发能力,我们不断吸引视觉/图形算法、3D/XR引擎等领域的优秀专业人才加入,一起奔向3D新时代。
如果您有兴趣可将简历发至[email protected],期待您的加入!
✿ 拓展阅读


作者|罗鸿城(伯玉)
编辑|橙子君
出品|阿里巴巴新零售淘系技术

